
我是怎么用MySQL的
第零篇简单介绍了austin项目做什么用的,这两个月我重点会实现哪一块内容。
第一篇用Maven+SpringBoot搭好了项目的架子,以及聊了下我对SpringBoot和Maven的看法。
第二篇聊了下很容易被大家忽略的日志(这在项目中是非常重要的)
第三篇推荐了些经常用到的工具包(简化我们的开发也能提高代码的可读性)
第四篇实现了短信发送的最基本功能
番外篇 #01保姆级教如何使用austin
这是austin项目系列的第五篇了,要进入整体开始完善项目的各种功能的阶段啦,就从数据库开始入手吧。
今天想跟大家聊聊数据库层面上的事
(注:今天聊的数据库都特指关系型数据库)
01、数据库选择
之前发了一张我可能要在austin项目上引入哪些技术栈的图,好多人问我分布式配置中心为什么不选择Nacos,而是用Apollo。却没人问我为什么数据库选择MySQL。
说起来MySQL,在网上看到的各类Java教程,几乎都是使用MySQL作为数据库。日常在群里聊各种数据库上的问题,也差不多都是MySQL,只有个别的可能用PostgreSQL和Oracle或其他
就连我在面试的时候,我也没被面试官问过:“你的数据库为什么选择MySQL啊?这块技术选型是怎么样的”
看到这里,是不是觉得我有答案了?其实我也没有。写到一半的时候发现我也说不出啥比较好的理由...既然我不知道,于是我就去看看人家是怎么说的。
https://www.zhihu.com/question/21793412/answer/32127410
总结原因可能是:
前期MySQL免费开源易用,从众多厂商中硬生生搞出了生态。有了生态,很难就被干掉了。(最主要的) 互联网用MySQL就是用来存数据“低成本快速的数据存储插入方案”,要求也相对没那么高(这条我后面会详细聊聊) 很多时候对某技术选型并非是技术原因

而我,我只会MySQL。我在生产环境下只用过MySQL,当年我还是小白的时候接触过Oracle,但现在也基本忘得差不多了。
很多时候对某技术选型并非是技术原因(我是懒狗,我承认了)。近几年PostgreSQL很火,听说很多地方都比MySQL要好,感兴趣的小伙伴可以把austin项目的MySQL替换为PostgreSQL
对数据库选型感兴趣的大哥们也可以找点资料继续查阅资料,也很欢迎在评论区输出下自己的经验,这种话题讨论我觉得还是蛮有意思的。
跟着我一起做austin项目的小伙伴应该对关系型数据库都有所了解了,这里的基础我就不展开讲述了。对MySQL感兴趣或者准备要面试的同学,可以看看我《对线面试官》系列的MySQL章节(在各大博客平台中受到了不错的反馈)
02、ORM框架选择
记得几年前我刚接触数据库和Java的时候,那时候要用JDBC连接数据库来操作数据,我就很不解:明明我可以通过各种的数据库客户端就能对数据进行操作,为啥我要用JDBC,好麻烦啊!
至于为什么会有这种疑问,我也不理解我当时是怎么想的(哈哈哈哈)。后来想通了以后,也学习了很多在程序上“简化JDBC模板”的姿势(DBUtils/Hibernate/Spring JDBC/Mybatis/SpringData JPA)

我在生产环境中接触过的都是Mybatis,但这一次我在asutin项目中决定使用SpringData JPA作为ORM框架。
03、使用数据库的经验
这两年我是呆在互联网公司上班的,我就来聊下我个人所接触到的东西,分享下我的看法。
一般来说,每个业务团队维护着自己的数据库(一个业务团队可能就有好几个库),当我们需要某一个团队的相关数据时,团队会提供对应的RPC接口给公司内部业务使用。
这意味着数据逻辑对调用业务方而言,是透明的(调用业务方不需要关注其他团队数据库的任何信息,无论是数据库表设计还是具体的字段)。

这个好处是显然地:要某团队的业务数据,只要找到他们提供的接口就完事了。作为需求方,只需要调个接口就能拿到自己想要的数据。
回到数据库内部存储本身,我们会尽可能将表结构设计得更简单:在很多情况下,都会放弃数据库三大范式来设计表。
举个很简单又可能不太恰当的场景:一个作者可能会写多篇文章(意味着多篇文章会属于同一个作者) author:content(1:N)
那在初学的时候,可能有的教程会这样设计:author表、content表、autor_content_mapping表
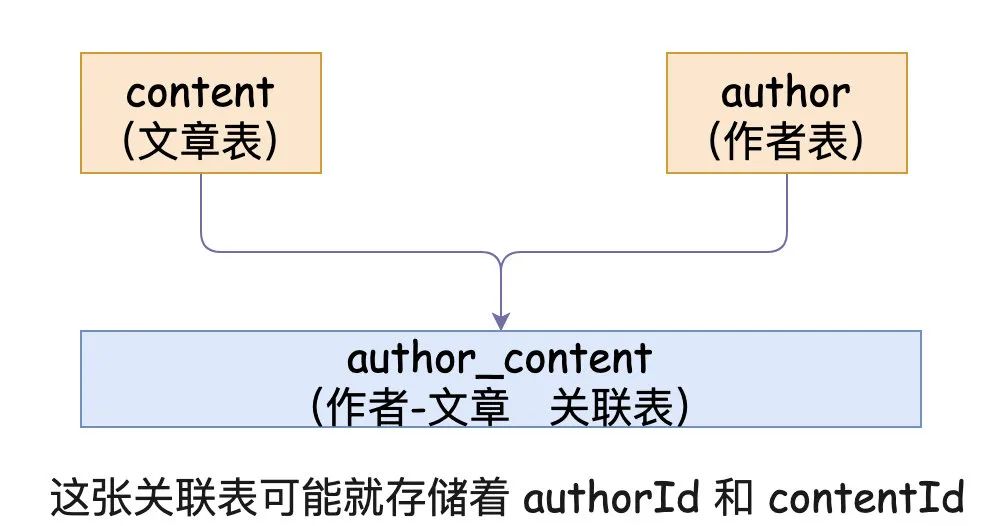
但是,我们在实际中生产环境中很有可能是不设计这种关联表,而是直接把相关字段冗余在一张表里。这样在查询的时候,就能直接通过一张表查到对应的信息了,不用进行多层关联
如果按上面的结构进行查询:比如我要查到某一篇文章的作者基本信息,那我此时的动作是:
关联 author_content表查到文章的authorId通过 authorId去author表查到作者的基本信息
如果我把authorId直接存到content表中,那就意味着少了去author_content表查询了。
注:这里我不是说让你们把所有的信息都存在一张表里,一张表里有上百个字段,千万不要误会我的意思!

说起关联,又有一个能聊的话题:是否join(这个话题我曾经在我的交流群中聊过,不过也是各抒所见吧)。我在以前公司接触到的项目,在mapper.xml中都看不到join的身影,我写join只在hive写统计脚本的时候用到。
【强制】超过三个表禁止 join。需要 join 的字段,数据类型必须绝对一致;多表关联查询时,保证被关联的字段需要有索引。
说明:即使双表 join 也要注意表索引、SQL 性能。
喜欢用join的会告诉你:我写join会让代码变得更简单。查数据太麻烦了,要查的数据会存到多张表里,直接在用join的开发效率是最快的!

而我,我是支持在代码里写业务逻辑的。所有都是单表查询,在程序代码中对数据进行关联(数据库的JOIN能干到的事,在程序上一定能干得到)。这样的好处就在于:SQL简单,SQL易复用,SQL易优化
在绝大数情况下,我们的接口瓶颈都是来源于「数据库」,而非应用服务器。多JOIN且复杂的SQL是不好优化的,而简单的SQL是比较好优化的,并且我认为程序逻辑往往都要比SQL更容易维护。

在我这两年在互联网公司中,关系型数据库在我的认知里,它就是作为一个支持事务的存储。如果我们存储的数据对事务没有要求的,可能压根就不需要存储至关系型数据库中。
现在数据源可选择的太多了,我们可以把数据存储到Redis(内存数据库)、Elasticsearch(搜索引擎)、HBase(分布式、可伸缩的大数据存储)、HDFS(分布式文件系统)、clickhouse(OLAP存储系统)等等等

基于上面这些背景下,我的查询SQL就不会复杂,那么Spring Data JPA不就很适合我了么?
04、开发之外的数据库
去到有一定规模的公司,都会有数据库相关的基础建设,下面提下常见的基础建设吧
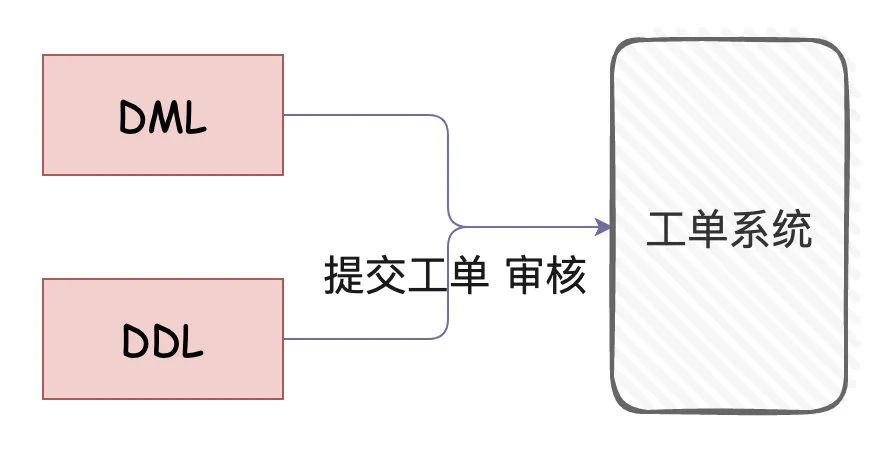
一、DDL和DML都需要走工单
生产环境的数据库理论都不能通过自己编写接口在程序中修改(高危动作),需要修数据或者建表都需要经过工单系统审核(一般是数据库负责人+DBA)
比如你提交建表申请,DBA会看你的表设计是否合理(是否有加索引等等)
二、DQL查询线上数据需要权限
我们要查询线上的数据,一般都得申请库的权限,有了权限之后在公司内网特定的页面进行数据查询(我们一般只需要查团队内的数据,所以其实也还好,其他团队的数据库权限是不开放的,要数据一般只能通过接口获取)

三、程序上一般不直连数据库(会有代理层)
一般只有线下数据库可以通过ip直连,线上数据库都会经过代理层(代理层可以做很多东西,包括监控鉴权分库分表等等)

四、完备的监控告警
数据库作为一个很重要的存储之一(如果挂了是真的影响很大),会有完备的监控和告警。比如说执行SQL失败的告警、执行慢SQL的告警等等,对数据库的各种指标进行实时监控

05、austin建表DDL
如果有提前预习的同学,应该就知道在austin.sql下我放了两张表的DDL。为了让大家理解我在做什么,我来解释下这两张表的DDL具体是什么含义(为什么我要建这两张表)
从message_template这张表开始解释吧,所有的字段我都添加了注释,应该还是比较容易看得懂的。
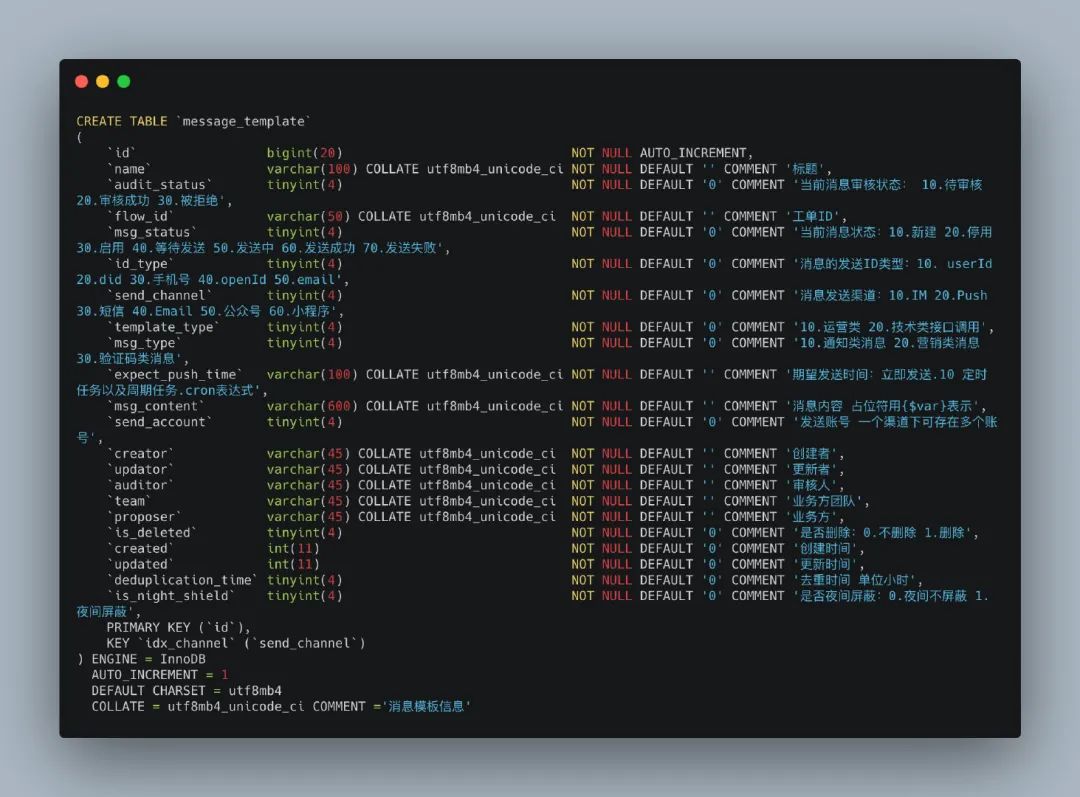
注:如果程序由于扩展导致数据库注释有落后,还是有必要更新下(造福后人)
我们需要让所有的消息都有一个「载体」,这个载体说白了就是模板,模板是austin系统的基石(有了模板,才能做业务处理,才能溯源,才能数据统计,才能扩展出一整套的建设...)
下面聊下几个可能大家有疑问的几个字段吧:
audit_status和flow_id:模板在发送之前需要经过审核(这在发送消息里非常重要,这会很大程度上能防止对消息的误发(相信大家也能看到各大公司都有过发错消息的报道)msg_type消息类型:分隔不同的消息类型,可以在下发时让不同的类型走不同的通道进行实现消息隔离(营销类的消息即便堵住了,也不会影响到通知类的消息)send_account发送账号:一个渠道内可能会有多个账号发送(比如,邮件渠道可以选择不同的邮件组进行发送、短信渠道可以选择不同的短信类型账号进行发送)deduplication_time和is_ngiht_shield平台规则:作为发送类型的组件(平台),需要有通用的规则。而去重和夜间屏蔽下发这种就很适合在平台内做msg_conteng:这个字段是作为消息内容发送的核心,不同的渠道对应下发的格式都不一样,我后面会直接将JSON存储进去。支持占位符的方式进行替换...
有可能后续还会扩展字段(毕竟在初期考虑设计表的时候,不会尽全尽美)。这种作为模板或者理解为配置的表,从使用上就注定它不会有很大的数据量。
下面来看下sms_record表吧,其实这表能说的不多(就是要把短信发送的记录以及短信的回执存储进去)。它的作用一方面是能追踪到为何发送给某个用户的短信失败了,另一方面是将这些记录进行关联做对账使用。

06、总结
这篇文章其实想我聊的是:数据库是一个很重要的角色,如果它挂了会影响很大很大。但同时,我们很多时候都是“轻量级”地去使用它(通过简单的SQL),它的存在很多时候是因它能很好地支持事务(数据强一致性)。
我们最能够信任的数据就是存储在数据库的,其他的存储我们可能担心会丢、会多、会不实时等等(这是数据库比其他存储的最大的优势)
我说得不对一定,不要以我的为准,我们可以在评论区聊

《对线面试官》公众号还在持续分享面试题,没关注的同学可以关注一波!这是austin项目的上一个系列,质量杆杆的。持续的创作离不开你的点赞和转发分享!