
技术分享 | Python逆向:修改Pycdc源码绕过花指令

Pycdc Windows 环境准备
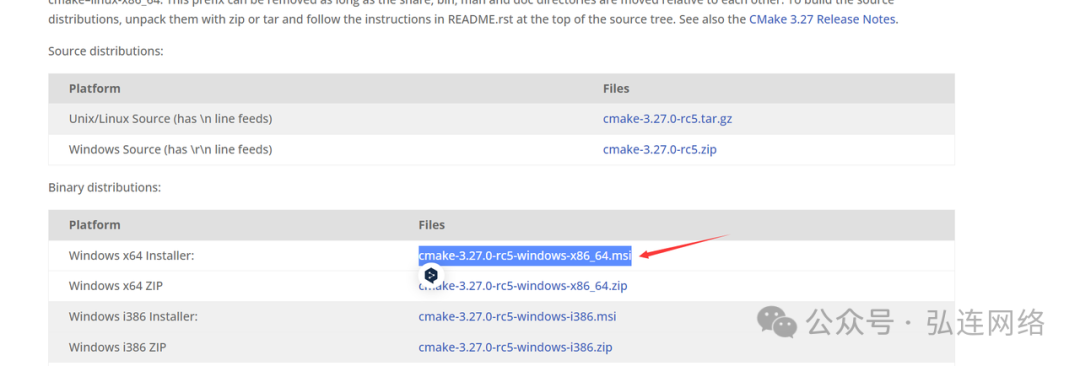
图 1
2. Pycdc项目的下载链接:https://github.com/zrax/pycdc
4.提前准备好Visual Studio,并双击打开sln文件(图 2),然后生成解决方案即可。

图 2
Pyc花指令简介
花指令(也称为反汇编花指令或反编译花指令)是一种常见的技术手段,用于增加反编译过程的复杂度和困难度。其目的是为了阻碍逆向工程师或反编译工具对程序的逆向分析,使得程序的源代码或逻辑难以被还原或理解。
在pycdc和其他工具的反编译过程中,它们会按照正常的顺序去读取每一条汇编指令(包括操作码和操作数),也就是常说的线性解析。
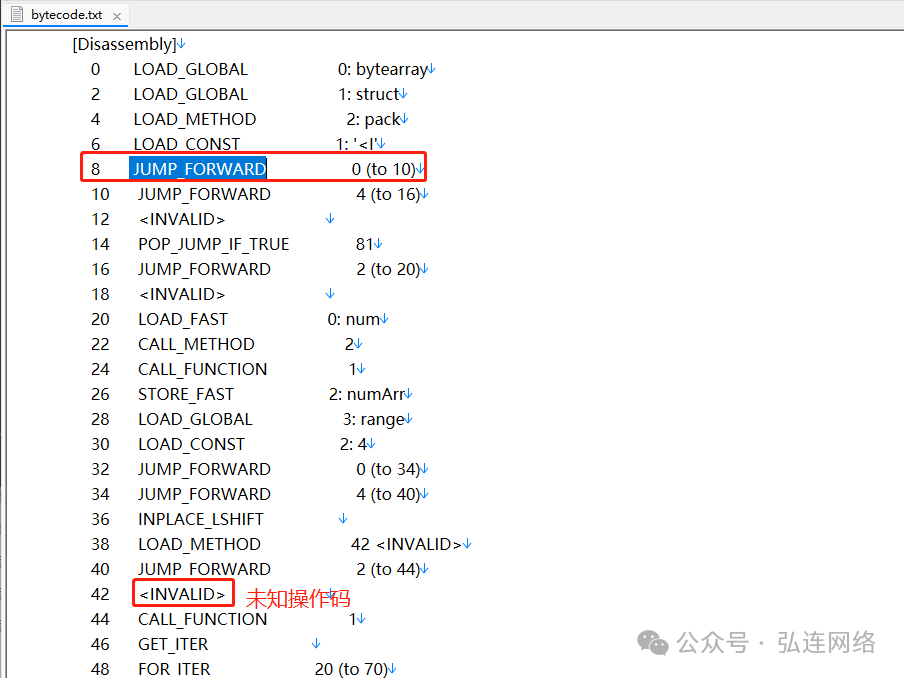
图3
本文以WMCTF的RightBack赛题为例。使用pycdc项目中的pycdas程序对pyc文件进行字节码提取。
在正常情况下,pycdc在分析字节码时会先解析JUMP_FORWARD操作码和操作数。而在程序运行时,实际上会直接跳转到指定位置,而不会执行跳转位置之间的代码。
然而,pycdc会继续解析每一条操作码和操作数,包括跳转位置之间的代码。
因而解析到如图 3非正常的操作码或者不正常的操作数 <INVALID>,并导致程序崩溃。
Pycdc程序基本逻辑初探
该项目主要包含3个代码文件ASTNode.cpp ASTree.cpp pycdc.cpp,见图 4。
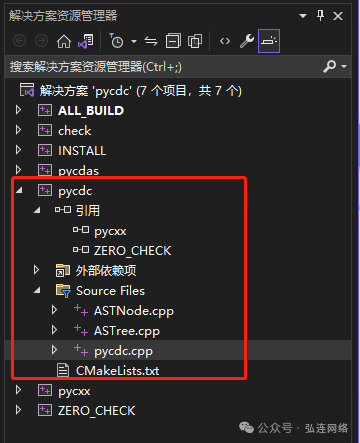
图4
1.main函数会识别pyc文件的Python版本,然后将反汇编的数据传递给decompyle函数。
2.decompyle函数中
a.buildfromcode函数的主要工作是解析反汇编数据
b.print_src函数则用于处理解析后的数据并进行输出。
本文的重点在于buildfromcode函数的功能和作用。
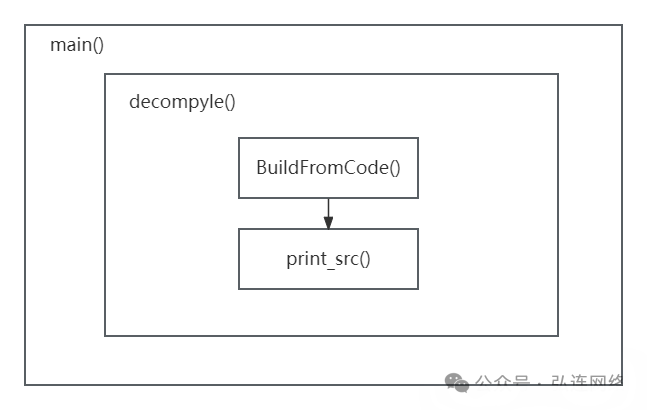
图5
BuildFromCode初探
根据代码第一行的source(code->code()->value(), code->code()->length()),从code中提取出值和长度,作为下文解析的基础,即将python字节码的数据存放在缓存结构体Pycbuffer中。
while循环条件(source.atEof()),每次循环会解析每一行的字节码数据(包括操作码和操作数)。根据下方的switch代码,可以确定每个case对应一个操作码的解析,处理相应的操作数,并最终返回解析后的数据。
while的循环之中。
代码如下:
PycRef<ASTNode> BuildFromCode(PycRef<PycCode> code, PycModule* mod){//python字节码的数据存放在缓存结构PycBuffer source(code->code()->value(), code->code()->length());//pycdc的栈虚拟机技术初始化 解析字节码FastStack stack((mod->majorVer() == 1) ? 20 : code->stackSize());stackhist_t stack_hist;std::stack<PycRef<ASTBlock> > blocks;PycRef<ASTBlock> defblock = new ASTBlock(ASTBlock::BLK_MAIN);defblock->init();PycRef<ASTBlock> curblock = defblock;blocks.push(defblock);int opcode, operand;int curpos = 0;int pos = 0;int unpack = 0;bool else_pop = false;bool need_try = false;bool variable_annotations = false;//每次循环会解析每一行的字节码数据while (!source.atEof()) {...curpos = pos;//移动每行的字节码的指针(重点!)bc_next(source, mod, opcode, operand, pos);if (need_try && opcode != Pyc::SETUP_EXCEPT_A) {need_try = false;.....}//每个case对应一个操作码的解析,处理相应的操作数,并最终返回解析后的数据switch (opcode) {case Pyc::BINARY_OP_A:{ASTBinary::BinOp op = ASTBinary::from_binary_op(operand);if (op == ASTBinary::BIN_INVALID)fprintf(stderr, "Unsupported `BINARY_OP` operand value: %d\n", operand);PycRef<ASTNode> right = stack.top();stack.pop();PycRef<ASTNode> left = stack.top();stack.pop();stack.push(new ASTBinary(left, right, op));}break;case Pyc::BINARY_ADD:case Pyc::BINARY_AND:case Pyc::BINARY_DIVIDE:case Pyc::BINARY_FLOOR_DIVIDE:case Pyc::BINARY_LSHIFT:case Pyc::BINARY_MODULO:case Pyc::BINARY_MULTIPLY:...default:fprintf(stderr, "Unsupported opcode: %s\n", Pyc::OpcodeName(opcode & 0xFF));cleanBuild = false;return new ASTNodeList(defblock->nodes());}else_pop = ( (curblock->blktype() == ASTBlock::BLK_ELSE)|| (curblock->blktype() == ASTBlock::BLK_IF)|| (curblock->blktype() == ASTBlock::BLK_ELIF) )&& (curblock->end() == pos);}cleanBuild = true;return new ASTNodeList(defblock->nodes());
在我们所熟知的解决方案中,如IDA(一种反汇编工具),绕过花指令通常采用递归解析的方法。
在pycdc中,为了绕过这个花指令,我们可以采取类似的方法,即让pycdc不解析跳转位置之间的代码。这样可以避免误解析和解释这些无关的指令,从而减少对程序逻辑的干扰,使分析结果更加准确和可靠。
解决方案
在pycdc的解析之中,JUMP_FORWARD是一条无条件跳转指令,其操作码(opcode)为132。正常情况下,JUMP_FORWARD指令后应当跟随对应的逻辑结构如IF/ELSE/EXCEPT等,用于实现条件和异常跳转。
最终代码表现为在ASTree.cpp的159行增加以下代码,如图 6所示
if (opcode == 132 && curblock->blktype() == 0) {int pp = pos;int ope = operand;for (int i = 0; i < ope / 2; i++) {bc_next(source, mod, opcode, operand, pos);}continue;}
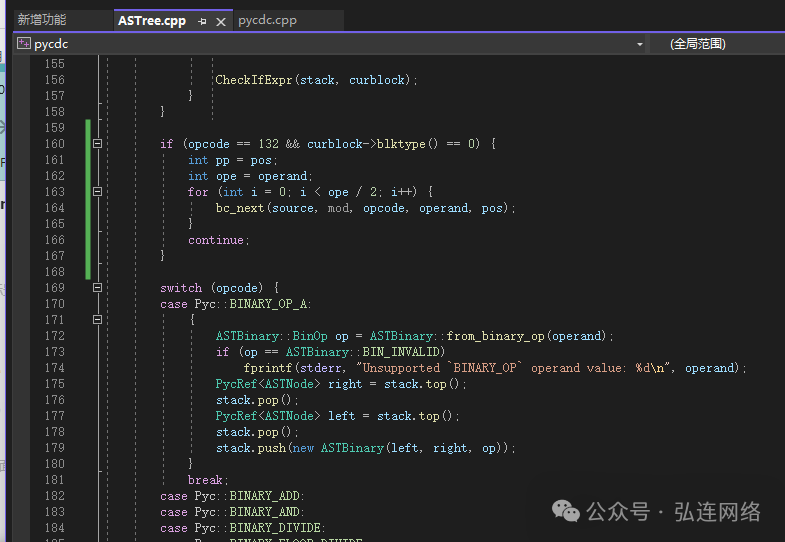
图6
取证启示
最近,我们在办理案件的过程中,也遇到了一些Python3.9的程序,使用pycdc逆向过程中也发现部分的字节码无法识别导致反编译处理报错,需要手动添加相关字节码至源代码中,也是在本文介绍的buildfromcode函数中switch (opcode) {case 下增加对应的case字节码分支即可,感兴趣的同学也可以对该部分栈虚拟机技术做进一步研究。
供稿:K3
编辑排版:Yvonne
审核:Spartan117