
FAIR最新无监督研究:视频的无监督时空表征学习
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
近期,FAIR的Kaiming He组发布了关于视频的无监督学习研究:A Large-Scale Study on Unsupervised Spatiotemporal Representation Learning,这篇论文被CVPR2021收录。论文的核心是将近期图像中的无监督学习方法应用在视频的无监督训练中。这个工作实验非常充分,也只有Facebook和Google 这样的大厂才有足够的资源来做这样的大规模实验。
论文中共选取了四种无监督学习方法:MoCo,BYOL,SimCLR,SwAV。其中MoCo和SimCLR是需要负样本的对比学习方法,而BYOL和SwAV是只依赖正样本的无监督学习方法。从另外一个角度看,MoCo和BYOL都采用了momentum encoder,而SimCLR和SwAV并没有。这里的四种方法有两类是Facebook提出的(MoCo和SwAV),另外的两类SimCLR和BYOL则是Google提出的 。
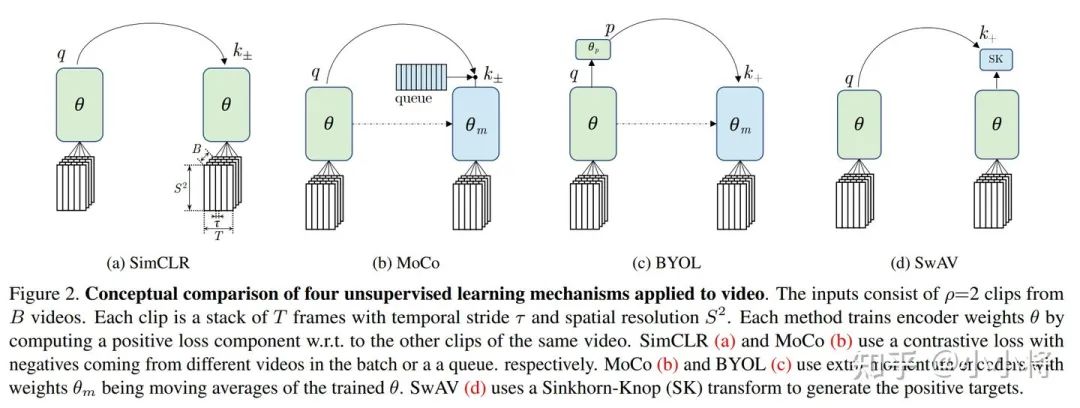
这四种方法原本都是用于图像的无监督训练,视频相比图像只是多了一个时间维度,这些方法可以非常容易地扩展到视频的无监督学习中。无论是图像分类还是视频分类,无监督就是要学习到特征不变量。具体到图像上,上述方法其实都是要同一个图像做不同的augmentation送入一个encoder网络来学习到不变的特征。那么对于视频分类来说,除了图像本身的变换外,还增加了时序维度。论文的做法是从同一个视频中sample不同的视频片段clips来做无监督学习(这其实可看成video独有的augmentation),这其实是希望学习到temporally-persistent features。论文中选择的是SlowFast R-50来最为encoder。下图展示了从一个视频中抽取3个不同的clips:

如果只抽取一个clips,那么学习就其实只依赖图像本身的变换,这对于视频分类显然不够。论文实验也证明了:more clips are beneficial。从下表可以看出,随着clips的增加,四类方法的性能均会提升,这说明对视频的无监督学习来说:learning space-time persistence within a video is important。

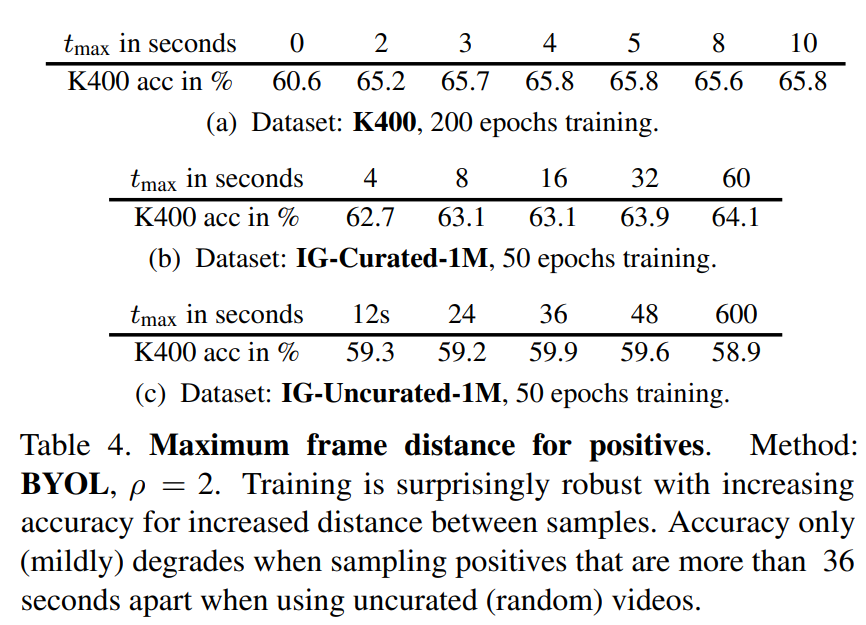
另外一点是在采样时timespan between positives越大越有效,这点也不难理解,因为图像中也是越hard augmentation越好。不同clips时间差越大,将会产生hard positive,对于学习反而是有利的。不过如果是长视频,那么时间差比较大的clips可能会发生语义变化,从论文实验结果来看,对效果影响反而很小(图像分类的random crop其实也会改变语义,比如crop到了背景区域,不过看起来训练是能够容许noise的)。如下表所示,对于IG-Curated-1M数据集,当timespan大于60s时,性能还有提升;而对于IG-Uncurated-1M数据集,当timespan大于600s时,性能也只是有稍微下降。
具体到四种方法上,从实验结果来看,虽然4种方法性能没有太明显的差距,但是MoCo和BYOL的效果要稍高于SimCLR和SwAV,前面已经说话前者都采用了momentum encoder,momentum encoder的作用是尽量保持模型输出的一致性,可能视频分类这个问题上影响更大。论文里面也没有给出具体的解释。对于视频分类来说,由于训练所需资源更多,会不会无法采用较大的batch sizes(论文中是64*8=512),导致SimCLR效果稍差?这里面的变量较多,可能还需要进一步的研究。
当无监督用于下游任务时,无监督训练方法在某些数据集上甚至可以超过有监督训练的方法,如基于BYOL在K400-240K无监督训练后应用在AVA和SSv2数据集上性能可以超过直接基于K400-240K的有监督训练后再在两个数据集上finetune。

论文还有更多的实验,更多可以详见论文:https://arxiv.org/pdf/2104.14558.pdf
这篇论文通过大量的实验证明了无监督学习在视频分类问题上的有效性,正如论文结尾所述,未来还有继续提高的空间:
We observed that linear readout on Kinetics is a good indicator of the performance on other datasets and that unsupervised pre-training can compete with the supervised counterpart on several datasets, but there is room for improvement. We hope that our baselines will foster research and provide common ground for future comparisons.
推荐阅读
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
