
大数据平台 | 网易大数据平台运维实战

各位SACC观众,大家好,感谢各位参加本次智能运维实践会场的最后一场分享会。算是压轴出场吧,也希望本次的分享能给大家带来一些实用的干货,特别是对于有重构服务平台需求的朋友。
简单自我介绍一下,我叫金川,来自网易杭州研究院,目前所在的部门是大数据基础设施组,负责大数据平台SRE的相关工作。如果在分享过程中有任何问题,大家可以先在评论栏中留言,在事后的QA环节会为大家统一做解答。

我本次的分享的内容包括以下几个部分:
首先,介绍网易的大数据应用现状;
其次,说明下网易大数据管控平台的现状,内部暂定的名称是EasyOps。取使用方便灵活之意;
再者,介绍通用的大数据服务运维框架;
然后,说明基于Prometheus套件的通用的大数据监控报警实现;
最后,大数据平台运维实战经验分享。

这里列举了目前我们的大数据平台支撑的互联网产品矩阵,大头主要是云音乐、严选这2个,同时内部还有其他待孵化的产品线,这里就不做举例了。

平台使用的技术栈底层是Hadoop生态系统,大概有22多个组件;中台是网易自研的有数,大概27个组件。我们离线集群分为6个,此外实时集群也有2个主要是运行sparkstreaming或flink作业。

这里是我们有数中台的一些功能模块,具体的使用的介绍这里不做展开,有兴趣的朋友请关注网易有数公众号,针对各个模块都有详细的文章介绍。

接下来,介绍下我们使用的大数据管控平台EasyOps。之所以要重新做一套管控工具,是因为我们在使用开源的Ambari系统来部署和管理大数据平台时,遇到了的各类问题。新的管控平台就是要解决这些问题,当然这也是一个逐渐迭代的过程,不会是一蹴而就的事情。

这页是EasyOps管控平台关于HDFS服务的一个实例的详情页面,这里包括了该实例所属的各类组件和节点。左侧是所有的服务列表,右侧是服务详情,上方是关于服务的一个概要报表。

接下来是管控平台的主机页面,我们可以看到接入的所有主机,然后是主机支持的若干操作。

这个是主机的详情页,这里可以看到这台主机上安装的所有服务和组件,包括主机本身的一些报表。细心的同学可能会看出右图的监控报表和NodeExporter很像,是的,我们监控主机状态用的就是Node Exporter,关于监控的实现,我们在后面会进行介绍,这里暂且不表。
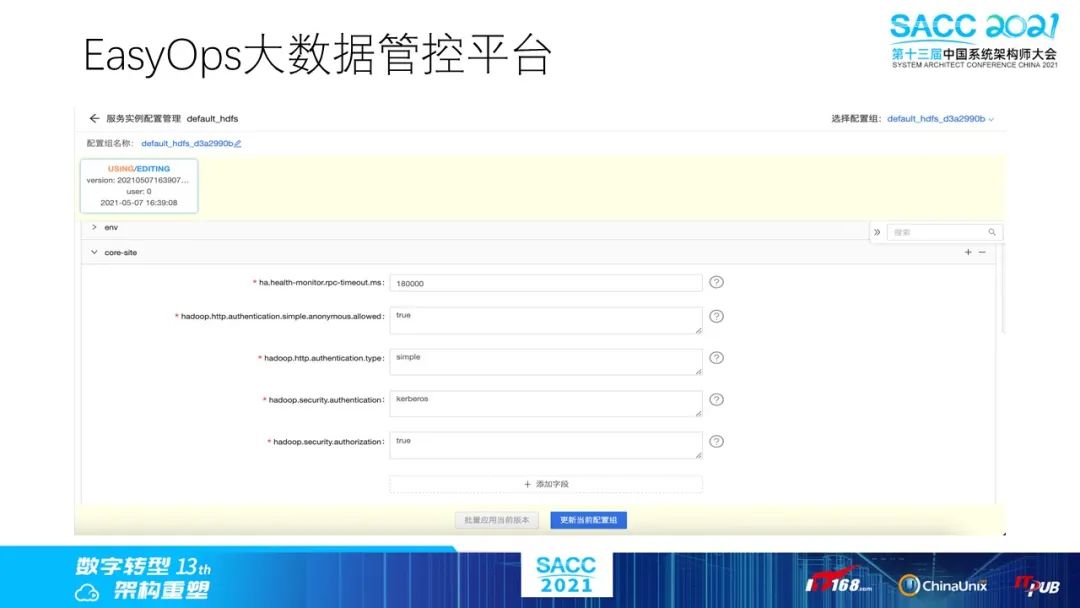
这里是我们的服务配置页面,可以支持常规的配置组、变更历史切换和任意的配置下发功能。

这是我们基于Grafana的Dashboard大盘,汇总了所有相关服务的监控仪表盘。

接下来为大家介绍下通用的大数据服务运维框架,具备一些开发资源的团队可以在短时间内完成一个可用的服务运维平台,这里我们会分这么几个区块来给大家介绍。

一个通用的服务运维平台往往会包括以下操作:
其他服务的特异性操作,譬如HDFS数据迁移,HDFS数据均衡,YARN的队列或任务操作等等
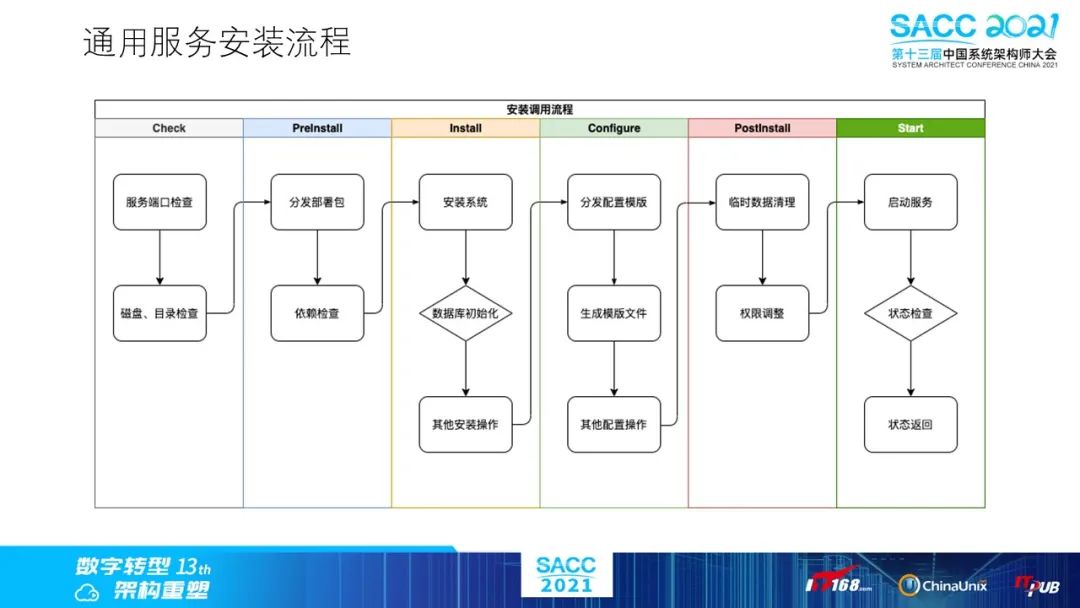
以服务安装流程为例,说明一下整个流程……

这个通用的运维框架是以Ansible技术栈为基础,包括以上三个主要的功能模块。
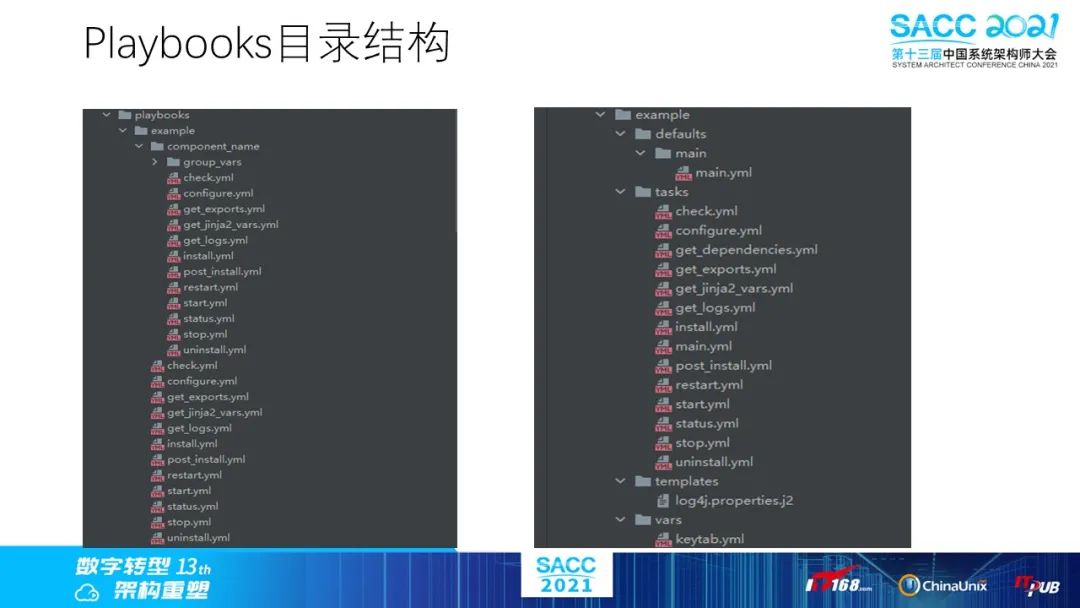
我们使用Ansible Runner目录结构来组织Playbooks,基本的结构见上图,在playbook目录下面是各个组件或服务的运维操作的入口。
在roles下以服务名创建目录,目录下创建defaults,tasks,templates,vars目录。
defaults:用于存放默认的变量值,必须创建main.yml文件,调用role时会自动加载
tasks: 所有的任务脚本存放的目录,必须创建main.yml,当调用role时,会调用main.yml
templates: 用于存放templates模板,生成配置文件
vars: 用于存放动态的变量值,需要include对应的变量文件才会加载

平台的前端我们使用的技术方案是……

平台后端的技术栈是……
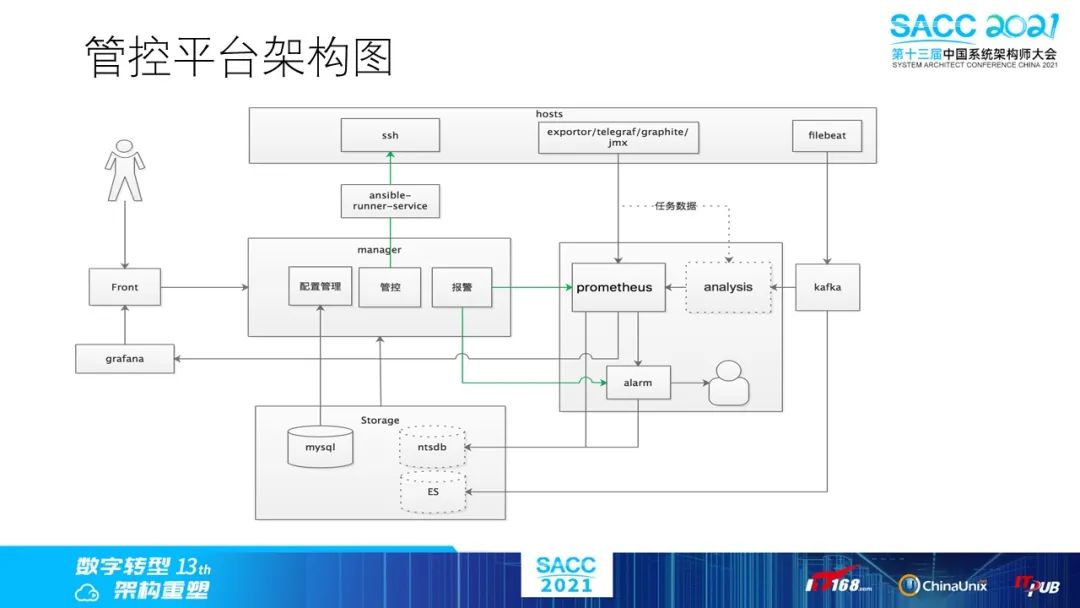
整个平台的架构图如上……
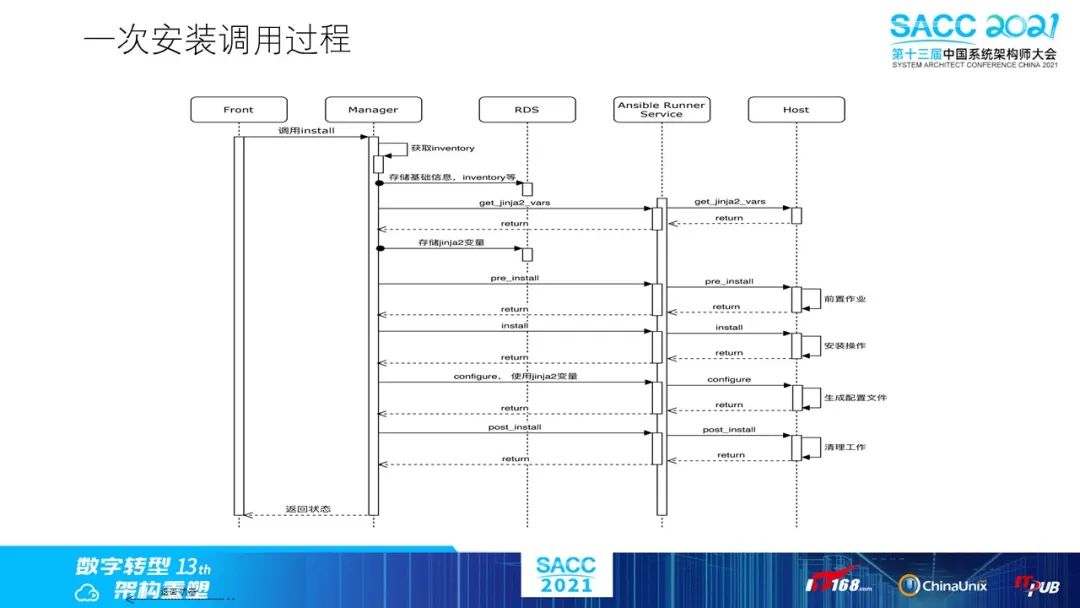
以之前提到的Ansible的服务安装调用逻辑为例,说明下整个调用流程……

服务的配置管理分为以上几个部分:

上图是YARN服务的配置管理,可以看到变更的历史记录。
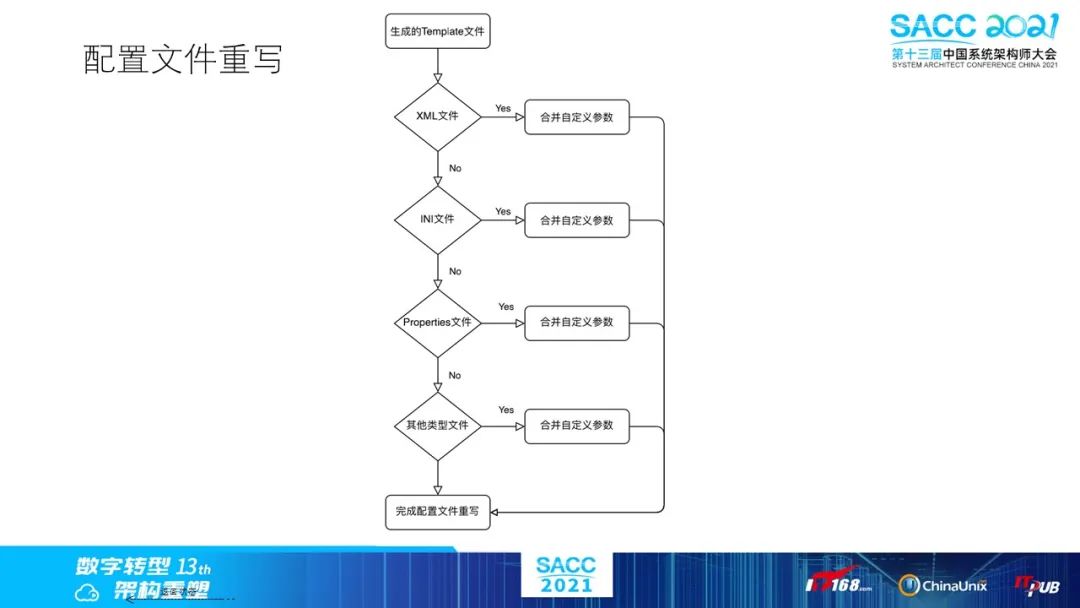
关于配置文件的参数变更,我们有这么一个场景,需要能支持任意参数的配置透传。我们定义了一套流程来解决上述问题,上面就是一个调用图例。
为什么要有配置透传?很简单,因为开发懒,不想每次服务版本变更增加配置参数后,还需要进行一次适配。而是按照规范,为特定的配置文件实现动态配置添加策略。

接下来我们介绍下通用的大数据服务监控报警框架,它基于Prometheus/Grafana等组件实现;内部使用的TSDB是基于InfluxDB改造后的NTSDB。
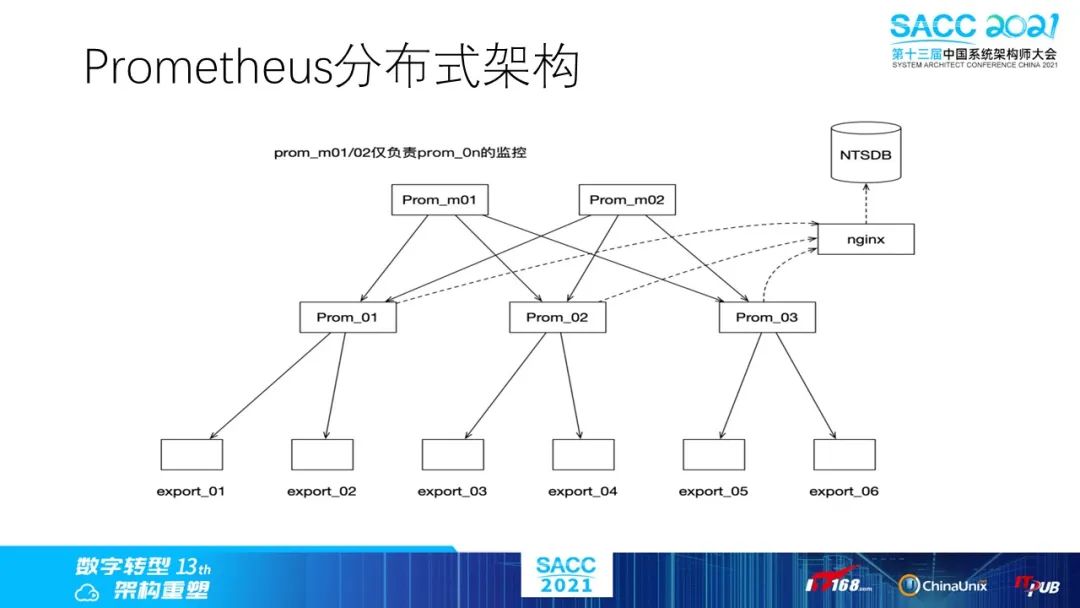
所以很明显,在集群模式下Prometheus服务是我们监控的核心模块,为此我们针对分布式和高可用问题,定制了一套架构,下面是分布式读写实现。

这里是Prometheus的高可用架构,所有采集端的prometheus均由prometheusMonitor进行监控。当一个prometheus无法提供服务时,会先由watchdog进行重启;如果依旧无法提供服务,alarmManager会进行报警,调用Ansible的相关接口,拉取无法提供服务的prometheus的完整配置文件,然后在合适的主机上创建新的实例。

上图是我们的度量采集方案,有些服务自己就暴露了prometheus的度量接口,譬如Neo4j,Grafana,Prometheus等,这类服务我们直接通过prometheus抓取相关监控数据即可。JVM服务我们使用的是micrometer插件(https://micrometer.io/)。
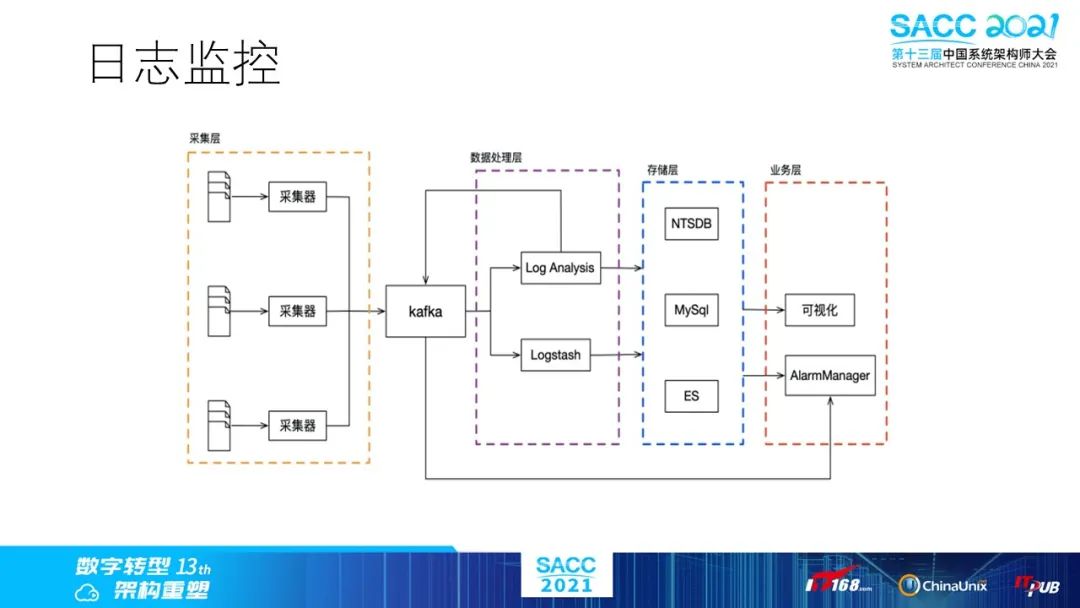
接下来是我们自定义的日志监控流程,日志采集可以使用filebeat,logstash等已有的组件,但我们有内部的一个DSAgent方案。通过日志采集,流入到kafka,然后我们会有定制的日志分析逻辑,譬如分析异常日志,聚合度量等,消费后的数据会分流至ES,NTSDB或者MySQL等存储,用于可视化或者报警平台逻辑。
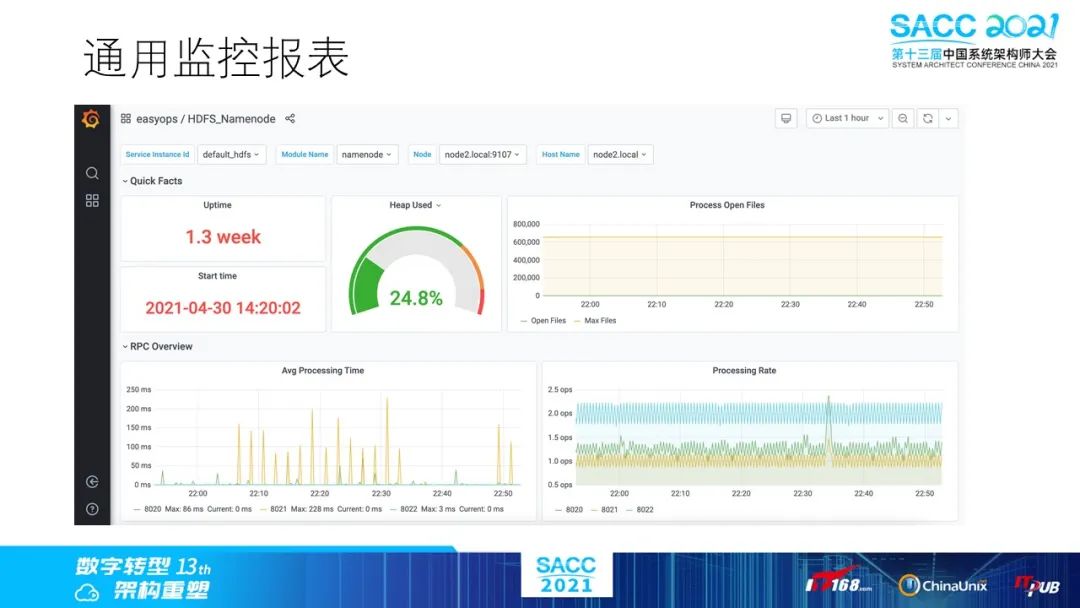
我们的报表系统基于Grafana定制而成。

报警我们可以直接使用Grafana的Alert模块来实现,通过导入定制的Alert规则,可以方便对集群的通用性指标统一添加监控报警。
简单,易用,方便移植。使用Grafana更加通用
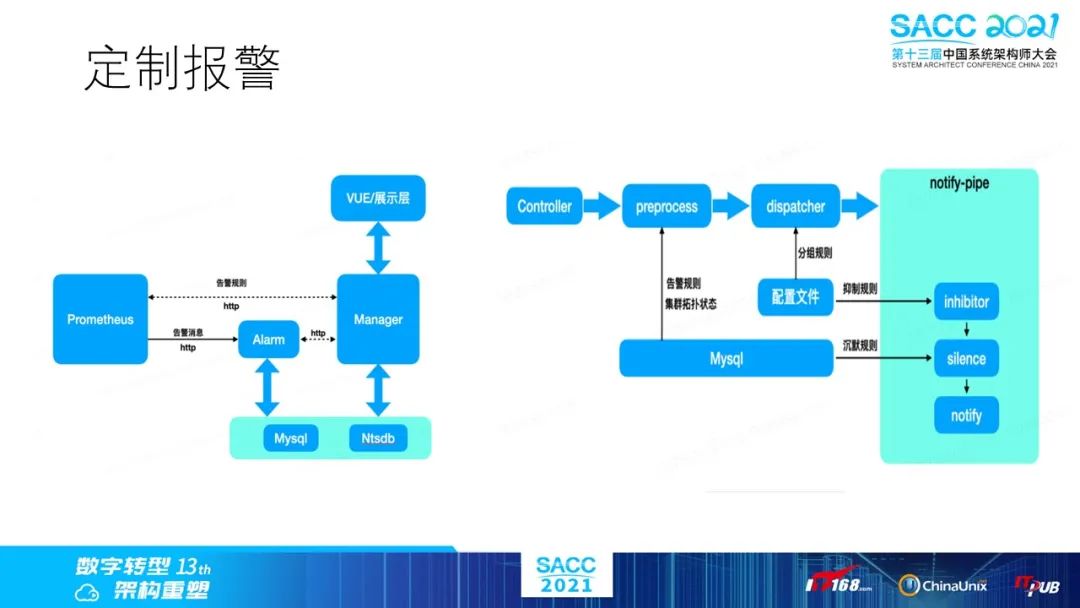
除此之外我们参考Prometheus的AlertManger组件,改造了Prometheus,用它来实现更灵活的自定义报警逻辑。

接下来我们进入最后一个环节,运维经验的交流。我这边会以这么几块内容来说明我们的平台在演进过程中的问题和思路。
从网络架构、存算分离、服务上云等方面来介绍平台的演进过程,这些方面的演进最终目标还是达成成本优化。最后从系统、服务等方面介绍一些性能优化的改进点
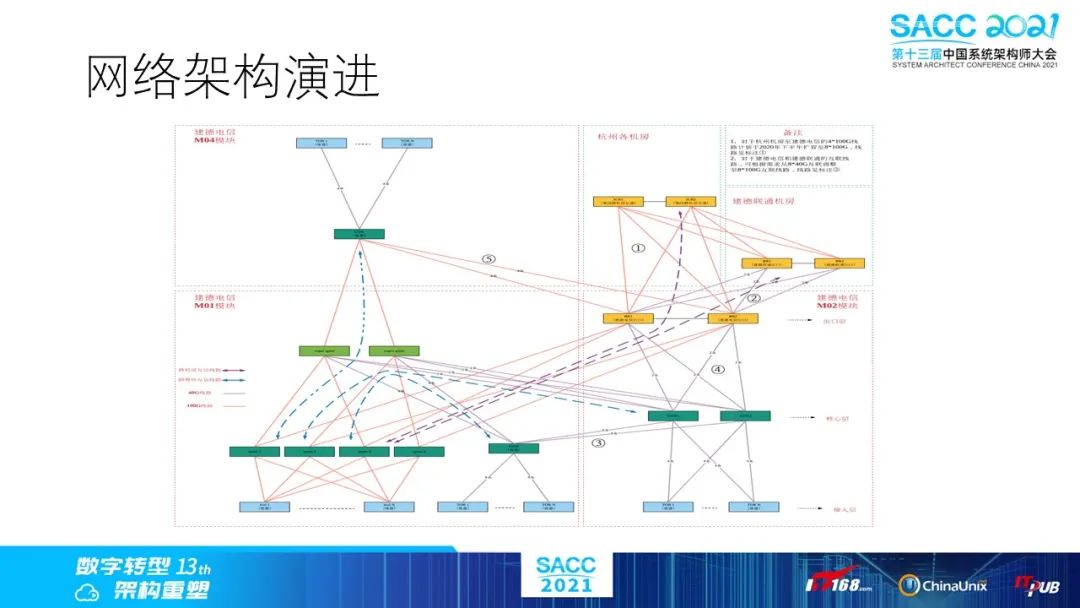
大数据HADOOP业务相较于常规业务在流量方面有很大的区别,hadoop业务因数据分析、离线计算等需求会对东西向的流量有非常大的需求,但是又因其数据存储功能同时也会存在大量其他业务的数据存储到hadoop服务器中导致南北向的流量也非常大。要满足这样的流量模型的需求就需要有一个大收敛比的网络架构,spine leaf架构恰好能满足这点。(使用老架构,解决ARP的广播问题,而且隔离性好)
Spine类似三层架构中的核心交换机,但形态有所变化:高端口密度高吞吐量的三层交换机替代了大型框式核心交换机,4台spine设备为一个pod节点,结合ARP转路由使用将网络的压力从集中式负载于核心交换机,变成给许多的leaf交换机来均衡分担。
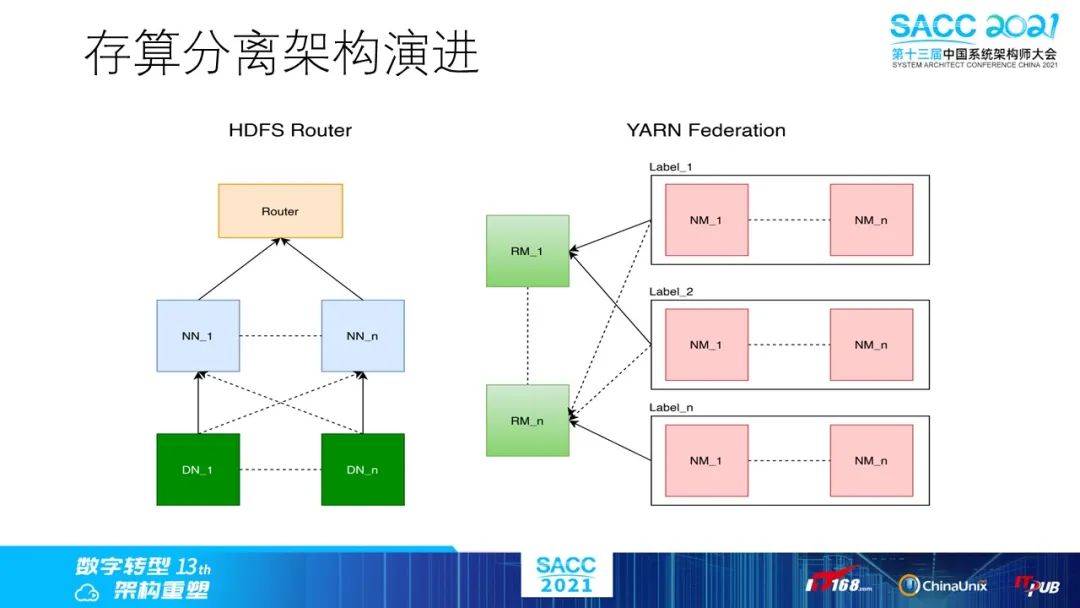
存储分离在上云过程中一直有提高,这个对于整体的成本优化有明显的好处,我们自己内部的评估就是同等存储和计算规格条件下,使用存储分离可以节省至少20%的成本,同时任务的性能也能得到较大提升。
这里我们主要使用HDFS Router/Federation架构,以及Yarn的Node Label等特性来实现。
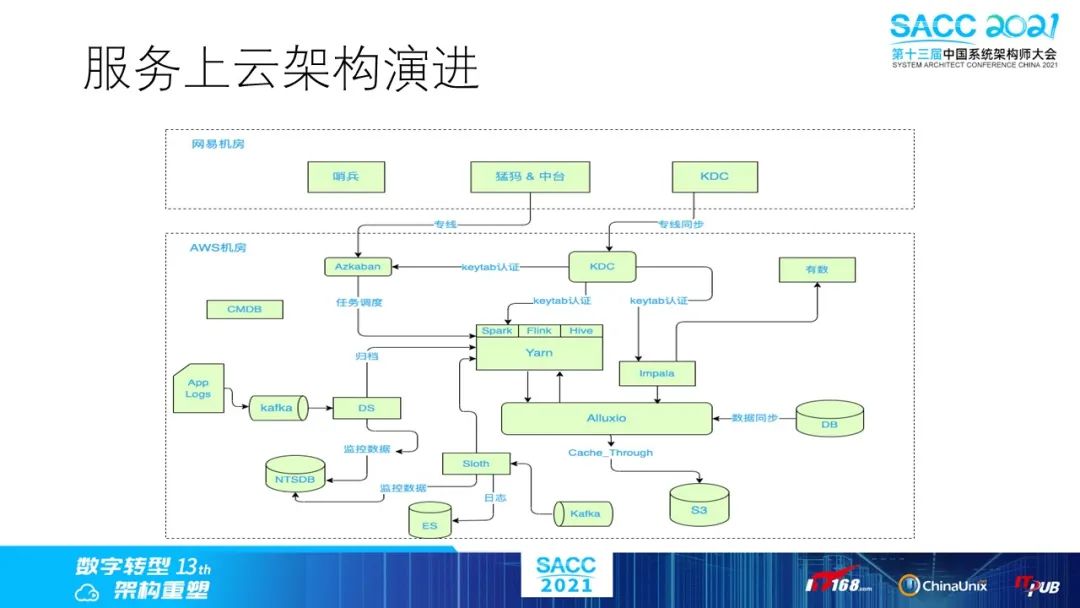
最后说到服务上云的实践,这里是我们云上实践的部署架构图。大数据上云一般来说最大的困难还是存储接口的问题,主流的云存储方案,包括s3,obs,oss等等。
为了提供统一的底层接入环境,我们引入Alluxio来作为中间层来屏蔽底层的存储细节,从而上层的计算框架和平台只需要做稍微的参数适配来实现通用的云上部署逻辑。

最后说到性能优化,我这里不会说到一些具体的细节,概要的来说,我们可以参考以上的几个原则来进行优化。
最后是本次的QA环节,大家有没有问题?上面的二维码是网易有数的公众号,我们会定期发布网易大数据的相关技术文章和产品介绍,感兴趣的朋友可以关注一下。
今天的分享就到这里,非常感谢大家的聆听。谢谢大家!
