
「正则表达式」的奇幻漂流之旅
之前小帅b写了下关于正则表达式的文章,有朋友表示看完后除了想打人之外,还是觉得有点懵逼,感觉不够循序渐进,所以今天小帅b就来好好写一波,尽量写的易懂一些,希望这次你看完这篇能够舒舒服服,一点打人冲动没有,还会忍不住点赞转发收藏哈哈哈,主要是希望你还能够了解到其中的使用方式。
那么:
什么是正则表达式呢?
想象一下这样的场景:
1
你应该经常使用 「CTRL + F」在文本文件中搜索关键词,定位到自己想要看的地方。不过,有时候你可能并不一定记得你要搜索的具体内容。比如你只知道关键词的开头是「马」,结尾是「梅」,但就是不知道是「马什么梅」,如何快速搜索替换?
2
你在爬取页面的时候,得到的一堆 HTML 标签,但是你只是想拿到其中的关键文本信息,怎么快速剔除掉 HTML 标签,把自己想要的文本从里面提取出来呢?
3
如果你开发了一个网站,允许用户注册,但你要求用户注册的密码需要含有大小写字母和数字,怎么验证呢?又,如何屏蔽用户的违规言论呢?
4
你在使用命令行的时候,如何一步到位的管理相关的文件呢?比如 rm -rf * (咋这个目录下的文件都被删除了?)
...
你看,在这些场景中,我们都需要一个「东西」来「占位」,表达关键的信息,比如在场景 1 中,我们不知道具体叫 「马什么梅」,但是知道它中间一定是个字,那么我们可以制定一个规则,说:「以后这玩意【😊】就代表一个任意的中文字」。
😊 = 任意一个中文字
如果你的编辑器遵循了这一规则,知道【😊】就代表一个任意的中文字,那么我们接下来就可以根据这个规则,使用「马😊梅」进行快速匹配了。
所以其实,这个「东西」就是用来描述我们想要的规则的,对吧?
当然,你也知道,我们自己制定的「东西」,编辑器是不会听我们的,如果我们能够知道那些已经被大多数遵循了的「东西」,不就可以做到快速匹配我们想要的内容了吗?
这些被遵循的「东西」,就是正则表达式的元字符。
找到那些被遵循的「东西」
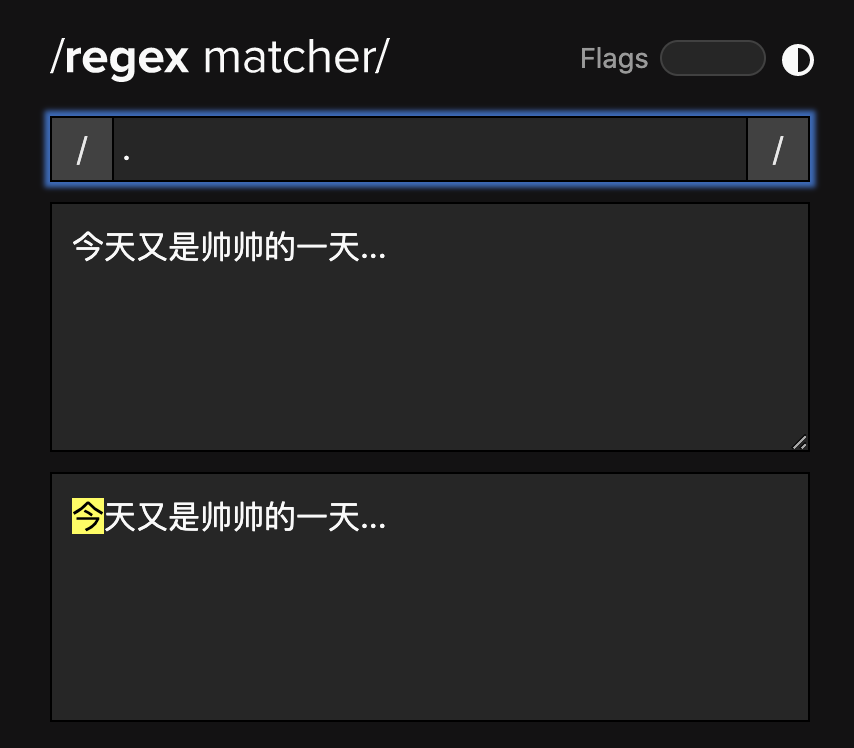
先认识「.」 和 「*」
这两玩意也许是我们最常用到的「东西」了,其中每个「.」用来表达的是「除了换行符以外的任何字符」,像这样:
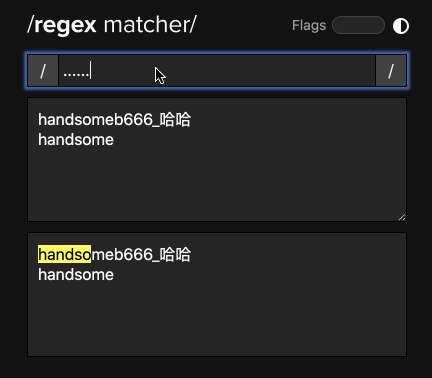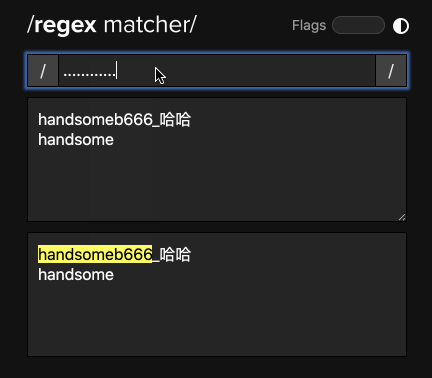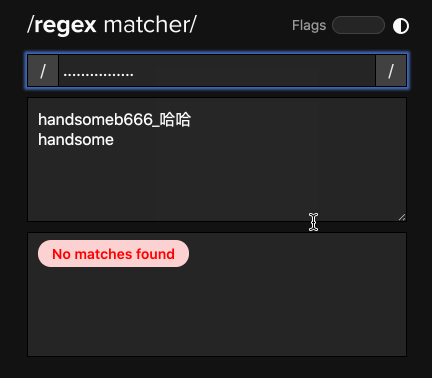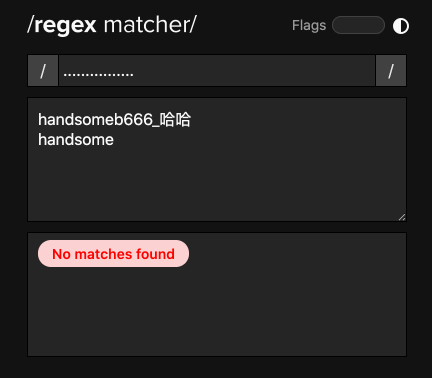
标高亮的表示被匹配到的字符
一个「.」只能表达一个字符,那如果很多岂不是得点点点点点到天荒地老?所以其实我们不必要这样去用那么多点来匹配,我们可以在「.」后面使用 「*」,这样编辑器就知道:「哦,你要找的是0个或者多个『.』」:
所以,「.」是用来描述相关字符,而「*」用来描述匹配次数的。
和「.」一样
虽然这两玩意已经可以代表大多数内容了,但是对于一些具体的内容,比如数字,换行等,也有已经被遵循的「东西」,和「.」一样,常用到的有:

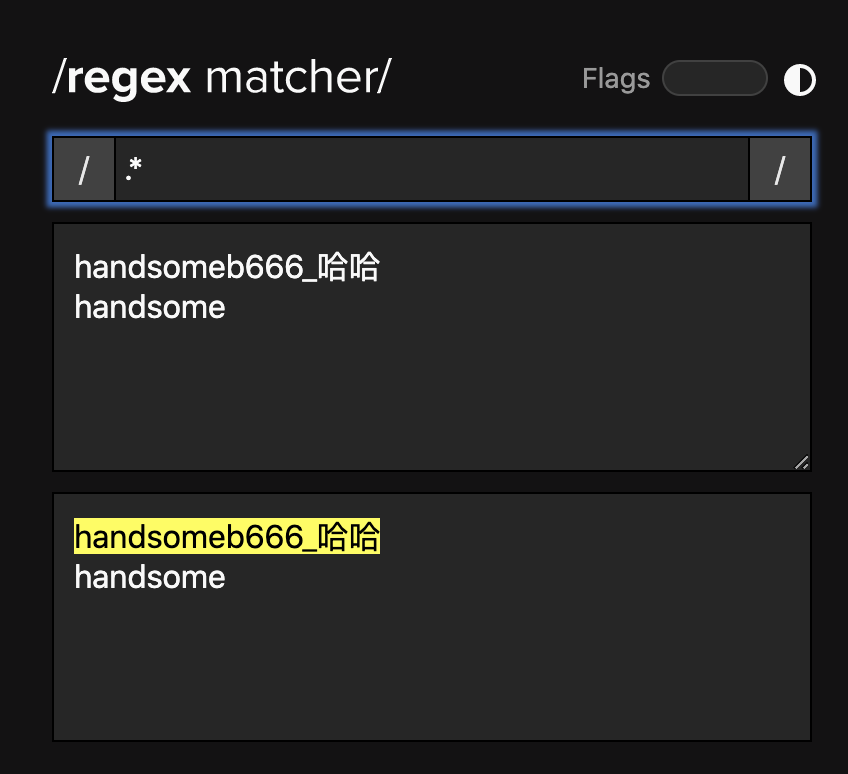
把这个看熟,你基本可以匹配大部分你需要的内容了,比如你要在这里只找到「handsome」这个词就可以这样:
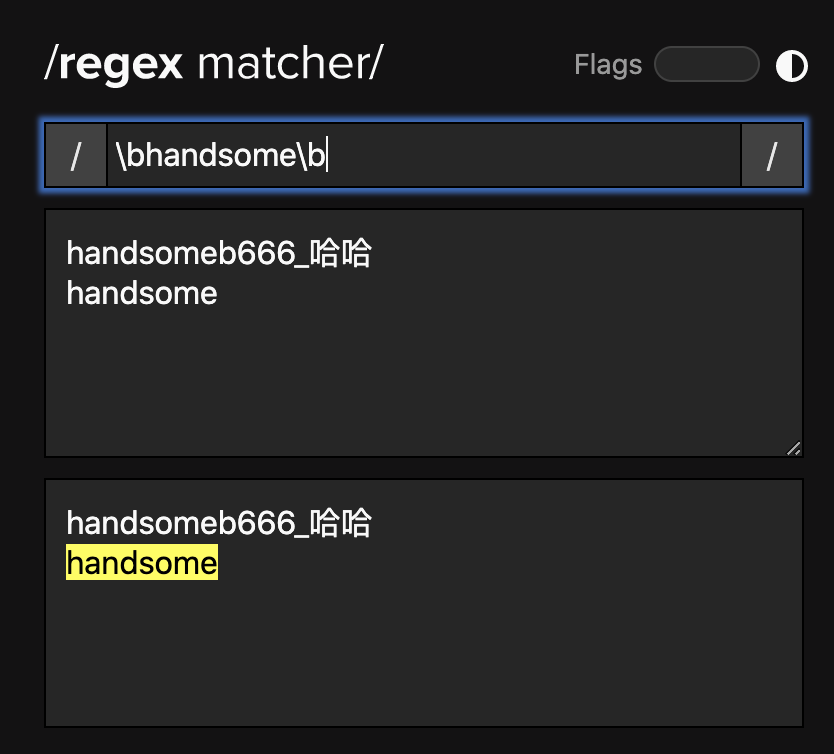
匹配多个字母,数字,下划线:
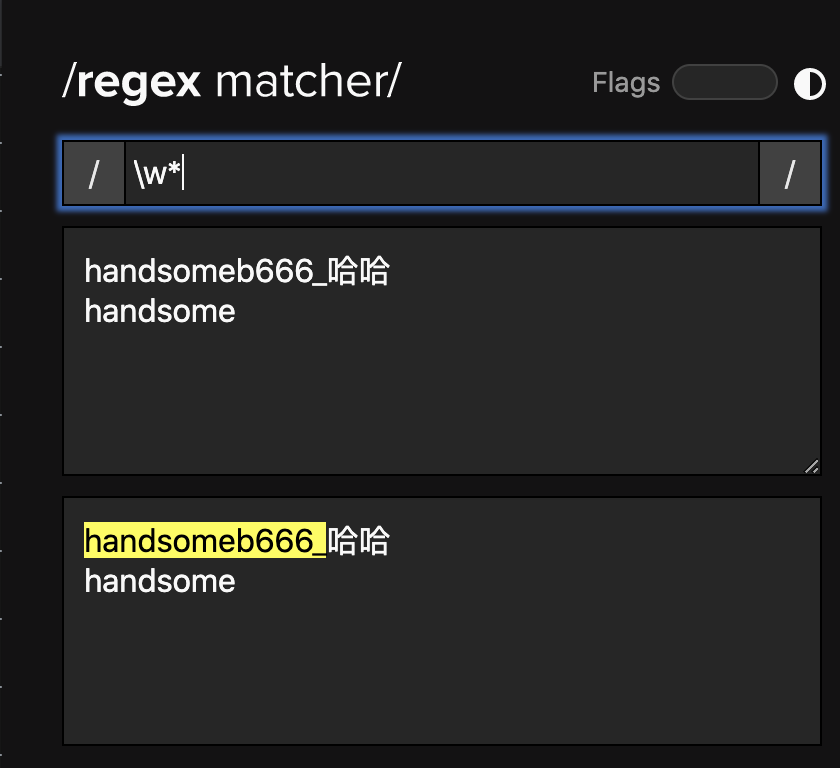
只匹配字母:
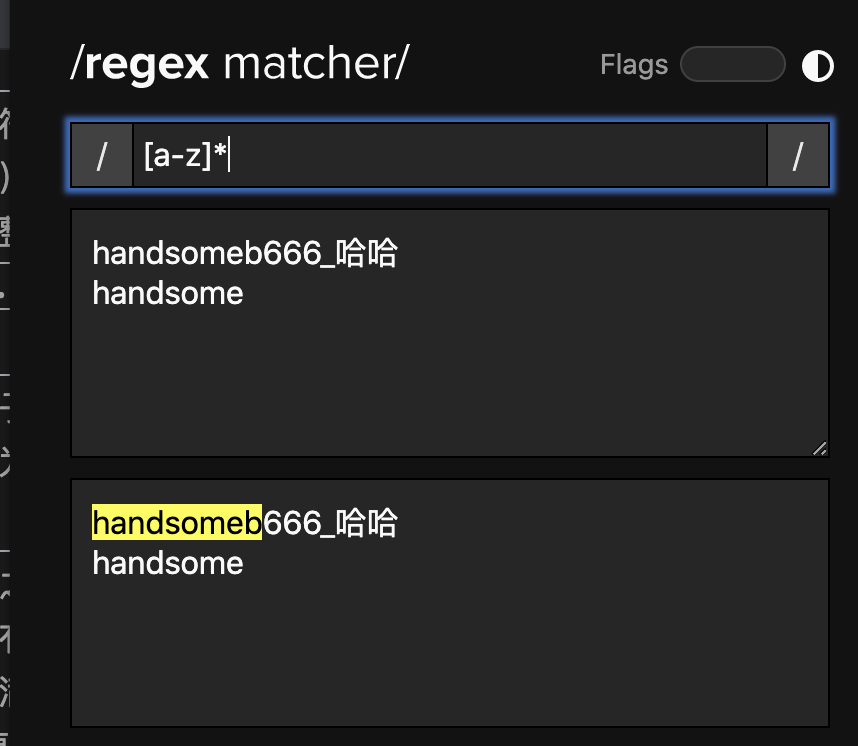
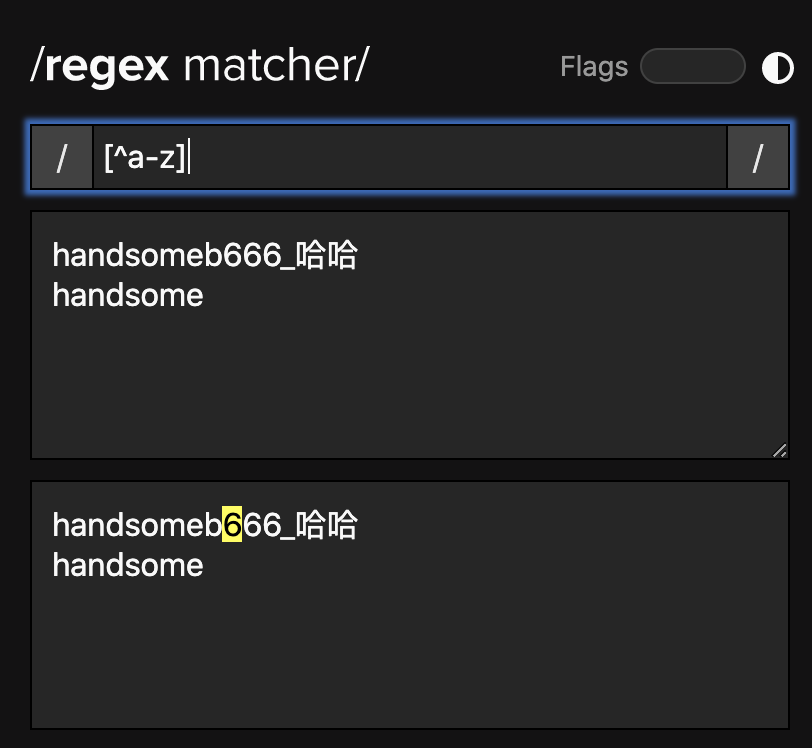
反向匹配:
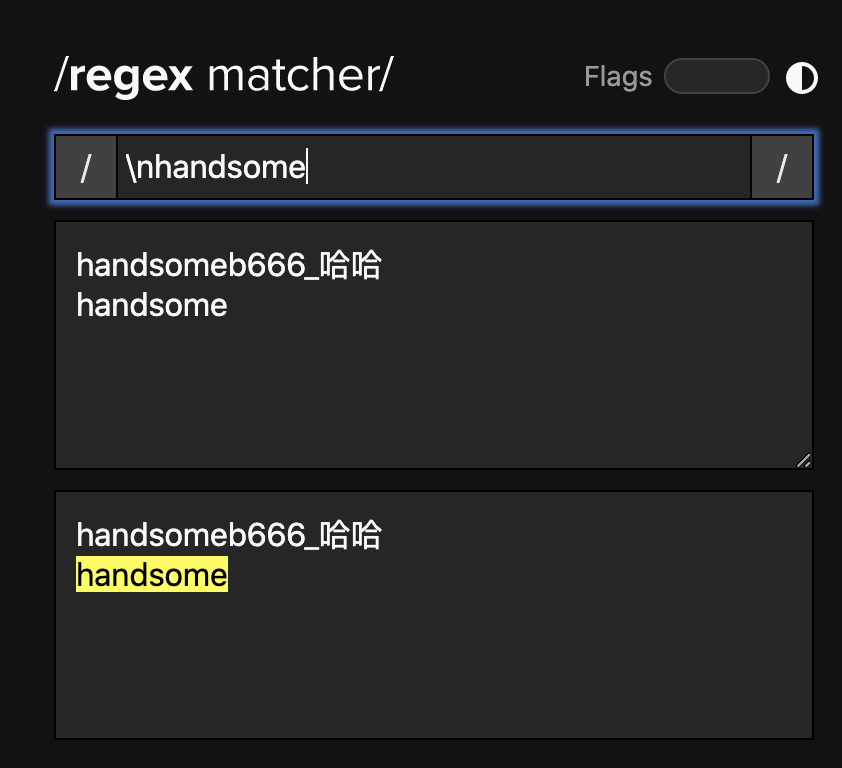
匹配回车:
你去玩几下就都熟悉了。
和 「*」 一样
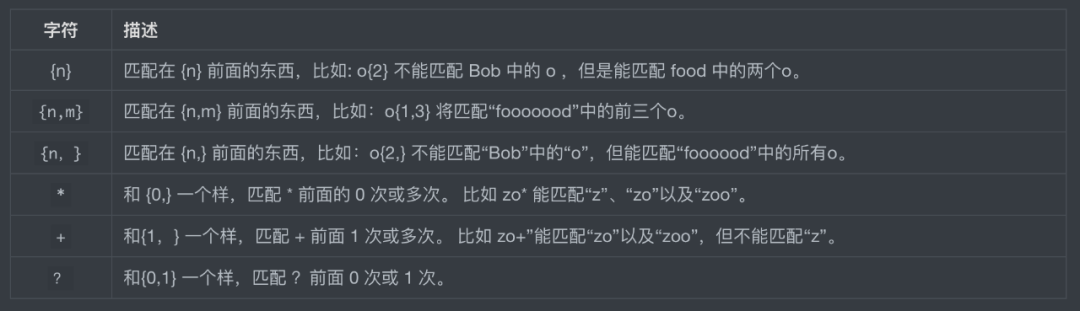
我们知道 「*」代表的是匹配0次或多次。和 「*」 一样也有表示次数的,比如具体多少次,0次或一次:
转义
现在,你已经知道了常用的「东西」,它们都代表着一定的规则,但如果有时候文本出现了和「东西」一样的字符,怎么去匹配呢?
比如说,我们知道「.」是匹配除了换行外的所有字符,但如果文本就出现了「.」,我们只要匹配这个「.」,咋整?
我们可以使用转义字符,也就是在 「.」前面加一个 「\」,就说明我们是真的要找的是「.」:
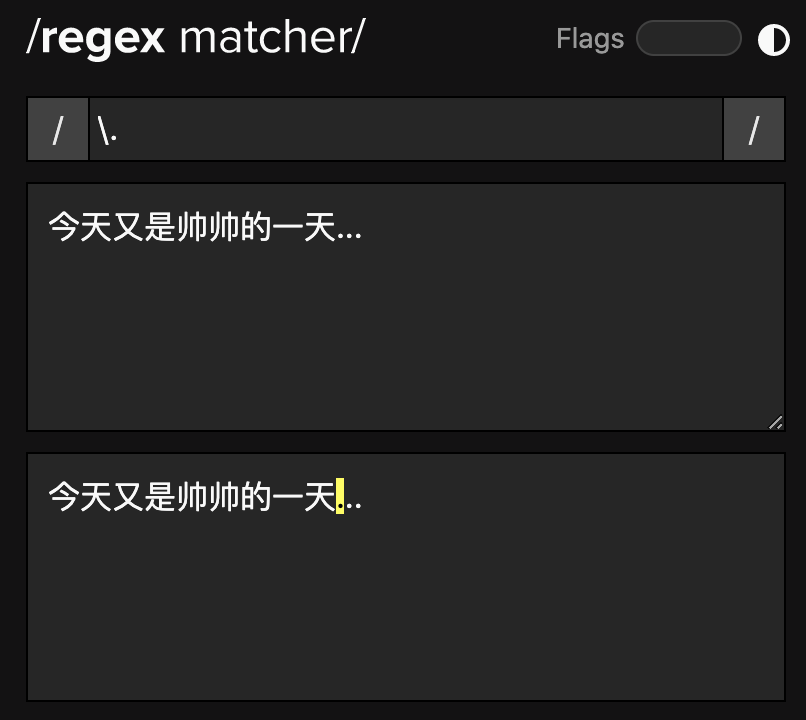
当你在 「东西」前面加一个「\」,它就失去了功效,变回了原来的模样。
还会常用到这玩意「|」
这个你应该很熟悉,就是「或」的意思,在 「|」的两边,满足其一即可。
a|b 匹配 a 或者 b。
比如判断文件是不是图片类型,就可以这样:
^.*?.(gif|png|jpg)$
小试牛刀
现在,找到了这些「东西」,也知道了转义....现在我们来写一个正则表达式,匹配邮箱的规则吧。
我们知道,邮箱的格式是这样的:
xxxx@xxxx.xxx
我们可以发现,邮箱有两很明显的特征点:「@」和「.」,而在「@」和 「.」前面和后面可以是一个或多个「大小写字母或数字或下划线」。
我们可以从开始到结束的特征点写出来:
^[大小写字母或数字或下划线]+@[大小写字母或数字或下划线]+\.[大小写字母或数字或下划线]+$
替换成我们知道的「东西」:
^[a-zA-Z0-9_]+@[a-zA-Z0-9_]+\.[a-zA-Z0-9_]+$
好用的 ()
在这些「东西」里,()能够进行分组,这对于我们在提取匹配我们关心的内容很有帮助,比如我们要提取这样的内容:
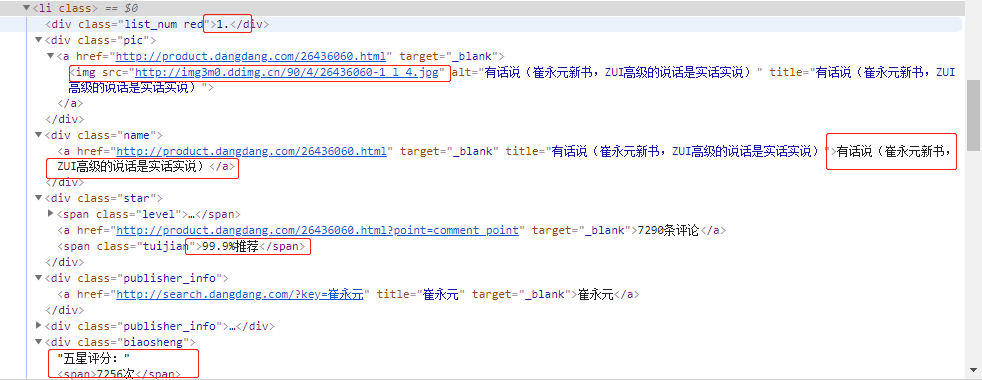
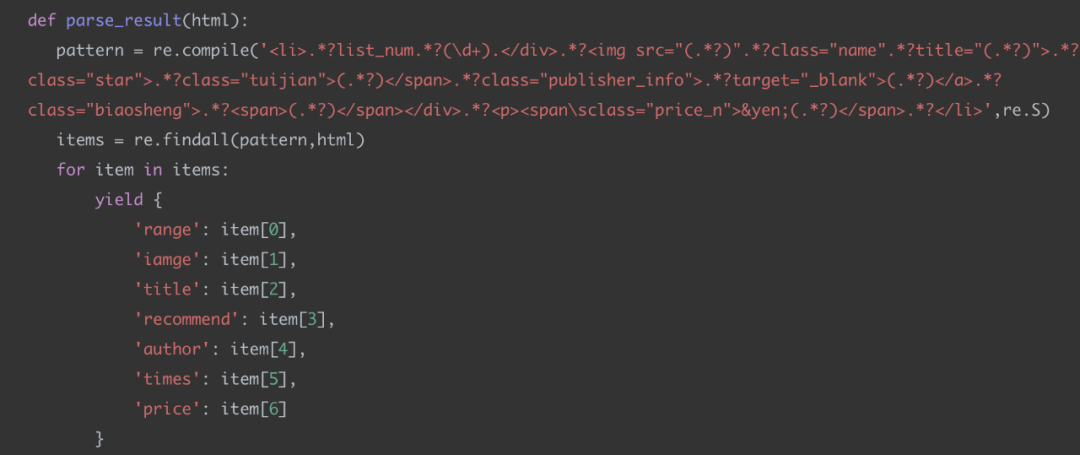
我们可以使用 ()对相关的匹配进行分组,这样得到多个分组(group1、group2、group3...)结果,这样可以很方便的从中提取内容,像这样:
.*? 和 .*
这两玩意都是匹配多个字符的「东西」,不过一个带了「?」一个不带,它们有什么区别呢?
.*? 表示的是非贪婪匹配
.* 表示的是贪婪匹配
啥意思呢?
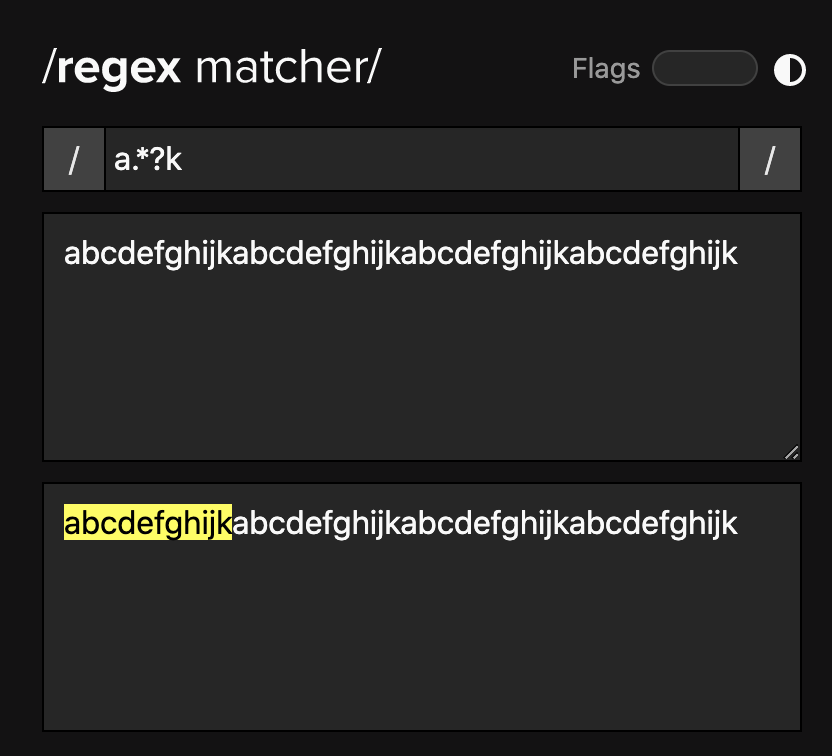
举一个最简单的例子,比如我们有一个这样的文本:
abcdefghijkabcdefghijkabcdefghijkabcdefghijk
如果我们想从中提取 a 到 k 的内容,你可以发现,当我们「贪婪」的时候得到的结果就是这样的:
abcdefghijkabcdefghijkabcdefghijkabcdefghijk
「非贪婪」的时候,得到的结果就是这样的:
abcdefghijk
那么用在它们两身上,就是这样的,贪婪:
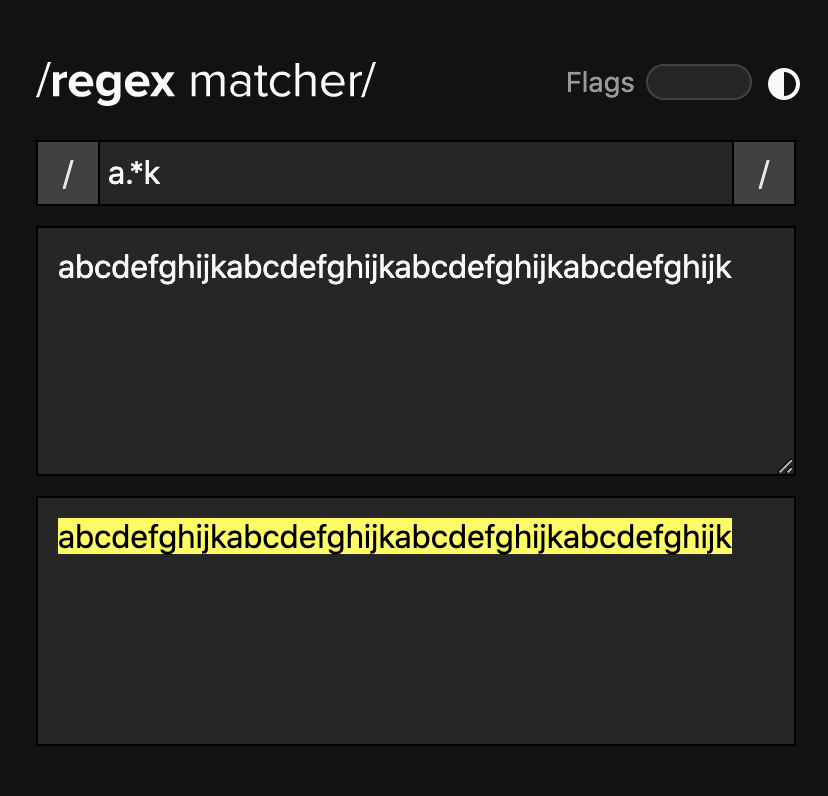
非贪婪:
意思就是这么个意思~
ok,这就是我常常会使用到的正则表达式,在 Python 中,有个 re 库可以专门操作这些玩意的,你可以到下面这个链接看到具体的解释:
https://docs.python.org/zh-cn/3/library/re.html
顺便,再给你推荐几个正则表达式可以参考的地方:
这里,有图文相关的正则表达式给你参考:
https://github.com/cdoco/common-regex
这里,可以让你校验自己写的正则:
https://regexr.com/
这里,有多个语言版本的正则表达式教程(如果你想更进一步了解反向引用,零宽断言的可以看看):
https://github.com/ziishaned/learn-regex/blob/master/README.md
我在上面演示用到的插件,叫「Regex Matcher」。
ok,以上就是小帅b今天给你带来的分享,正则表达式算是基础且通用的技能了,希望对你有帮助,如果有的话,请拼命点赞分享赞赏一波,哈哈,那么我们下回见,peace!