转自:新智元
这次,何大神让BERT式预训练在CV上也能训的很好。论文「Masked Autoencoders Are Scalable Vision Learners」证明了 masked autoencoders(MAE) 是一种可扩展的计算机视觉自监督学习方法。论文地址:https://arxiv.org/abs/2111.06377
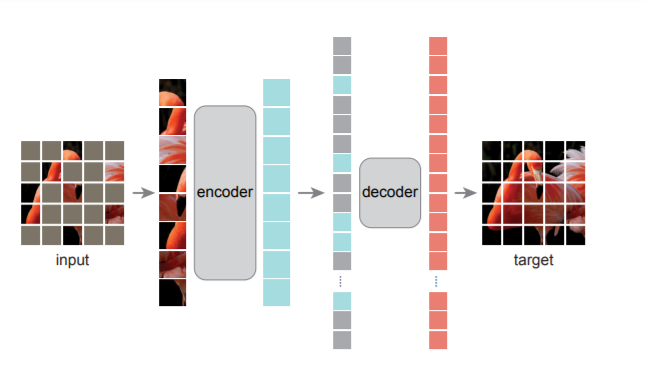
此文最大的贡献,可能是在NLP和CV两大领域之间架起了一座更简便的桥梁。此前,大名鼎鼎的GPT和BERT已经将大型自然语言处理(NLP)模型的性能提升到了一个新的高度。直观点讲,就是事先遮住一些文本片段,让AI模型通过自监督学习,通过海量语料库的预训练,逐步掌握上下文语境,把这些被遮住的片段,用尽可能合乎逻辑的方式填回去。这和我们做「完形填空」的方式有些类似。经过海量数据的学习和训练,AI模型慢慢学会了自己生成自然文本。目前,随着GPT及其后续改进模型的不断进步,生成的自然文本几乎可以乱真。现在,何恺明的这篇文章把NLP领域已被证明极其有效的方式,用在了计算机视觉(CV)领域,而且模型更简单。遮住95%的像素后,仍能还原出物体的轮廓,这居然还能work!本文提出了一种掩膜自编码器 (MAE)架构,可以作为计算机视觉的可扩展自监督学习器使用,而且效果拔群。实现方法很简单:先将输入图像的随机部分予以屏蔽(Mask),再重建丢失的像素。
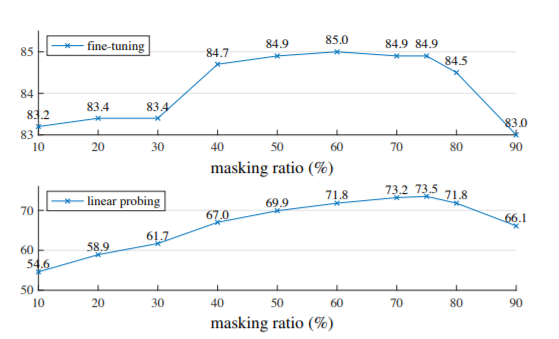
在预训练期间,大比例的随机的图像块子集(如 75%)被屏蔽掉。编码器用于可见patch的小子集。在编码器之后引入掩码标记,并且完整的编码块和掩码标记集由一个小型解码器处理,该解码器以像素为单位重建原始图像。预训练后,解码器被丢弃,编码器应用于未损坏的图像以生成识别任务的表示。MAE 是一种简单的自编码方法,可以在给定部分观察的情况下重建原始信号。由编码器将观察到的信号映射到潜在表示,再由解码器从潜在表示重建原始信号。与经典的自动编码器不同,MAE采用非对称设计,允许编码器仅对部分观察信号(无掩码标记)进行操作,并采用轻量级解码器从潜在表示和掩码标记中重建完整信号。将图像划分为规则的非重叠patch。对patch的子集进行采样并屏蔽剩余patch。我们的采样策略很简单:均匀分布,简单称为“随机抽样”。编码器仅适用于可见的、未屏蔽的patch。编码器通过添加位置嵌入的线性投影嵌入patch,然后通过一系列 Transformer 块处理结果集。编码器只对整个集合的一小部分(如 25%)进行操作。被屏蔽的patch会被移除;不使用掩码令牌。这样可以节约计算资源,使用一小部分计算和内存来训练非常大的编码器。解码器的输入是完整的令牌集。每个掩码标记代表一个共享的、学习过的向量,表示存在要预测的缺失patch。解码器仅在预训练期间用于执行图像重建任务。因此,它的设计可以独立于编码器。实验中使用的解码器更加轻量级。通过这种非对称设计,显著减少了预训练时间。MAE 通过预测每个掩码块的像素值来重建输入图像。解码器输出中的每个元素都是一个表示补丁的像素值向量。解码器的最后一层是线性投影,其输出通道的数量等于补丁中像素值的数量。解码器的输出被重新整形以形成重建的图像。MAE 预训练实施效率高,实现方式简单,而且不需要任何专门的稀疏操作。从上图可以看出,随着输入图像被遮住的比例升高,MAE的性能迅速上升,在75%左右达到最佳效果。
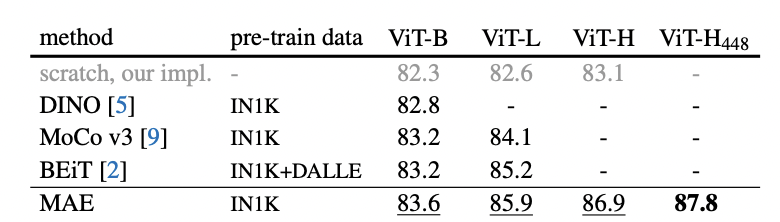
与当前SOTA自监督预训练方法相比,对于 ViT-B 的表现结果都很接近。对于 ViT-L不同方法的结果就存在很大差距,这表明更大模型的挑战是减少过度拟合。
再看最后一列,仅使用ImageNet-1K数据时,ViT-Huge模型的最高精确度为87.8%,这明显超过了所有在ImageNet-21K 预训练的ViT变种模型。作者总结道,与 BEiT方法相比,MAE更准确、更简单、更高效。
「现在是2021年11月12日中午,恺明刚放出来几个小时,就预定了CVPR2022 best paper candidate(这里说的是best paper candidate,不是best paper)」
这篇文章推翻了之前视觉自监督领域的统领范式(NLP里面确实用的比较多,但是CV里面用的并不多),提出了简单本质有效的自监督方法: 基于mask和autoencoder的恢复方法。「大致看了一遍,做的很solid,在iGPT和BEiT的基础上,化繁为简,找出了最关键的点,能够让BERT式预训练在CV上也能训到很好!未来可以预见能比肩GPT3的CV大模型不远矣。」「只想说,凯明大佬cv封神!!!膜拜大佬,求今年cvpr中签。」何恺明,本科就读于清华大学,博士毕业于香港中文大学多媒体实验室。2011年加入微软亚洲研究院(MSRA)工作,主要研究计算机视觉和深度学习。2016年,加入Facebook AI Research(FAIR)担任研究科学家。2020年1月11日,荣登AI全球最具影响力学者榜单。https://arxiv.org/abs/2111.06377https://www.zhihu.com/question/498364155/answers/updatedhttps://www.zhihu.com/question/498364155/answer/2219622610