
给127.0.0.1发了个包,我发现了···
大家好,我是飞哥!
我们拆解完了 Linux 网络包的接收过程,也搞定了网络包的发送过程。内核收发网络包整体流程就算是摸清楚了。
正在飞哥对这两篇文章洋洋得意的时候,收到了一位读者的发来的提问:“飞哥, 127.0.0.1 本机网络 IO 是咋通信的”。额,,这题好像之前确实没讲到。。
现在本机网络 IO 应用非常广。在 php 中 一般 Nginx 和 php-fpm 是通过 127.0.0.1 来进行通信的。在微服务中,由于 side car 模式的应用,本机网络请求更是越来越多。所以,我想如果能深度理解这个问题在实践中将非常的有意义,在此感谢@文武 的提出。
今天咱们就把 127.0.0.1 的网络 IO 问题搞搞清楚!为了方便讨论,我把这个问题拆分成两问:
127.0.0.1 本机网络 IO 需要经过网卡吗? 和外网网络通信相比,在内核收发流程上有啥差别?
铺垫完毕,拆解正式开始!!
一、跨机网路通信过程
在开始讲述本机通信过程之前,我们还是先回顾一下跨机网络通信。
1.1 跨机数据发送
从 send 系统调用开始,直到网卡把数据发送出去,整体流程如下:
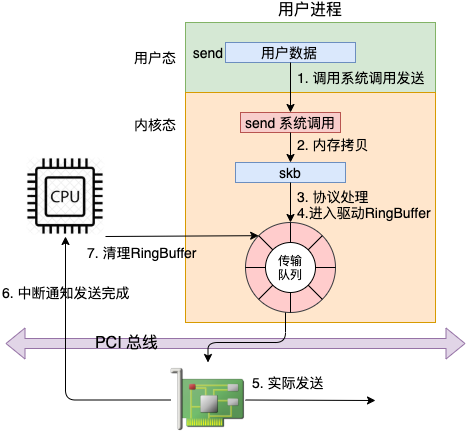
在这幅图中,我们看到用户数据被拷贝到内核态,然后经过协议栈处理后进入到了 RingBuffer 中。随后网卡驱动真正将数据发送了出去。当发送完成的时候,是通过硬中断来通知 CPU,然后清理 RingBuffer。
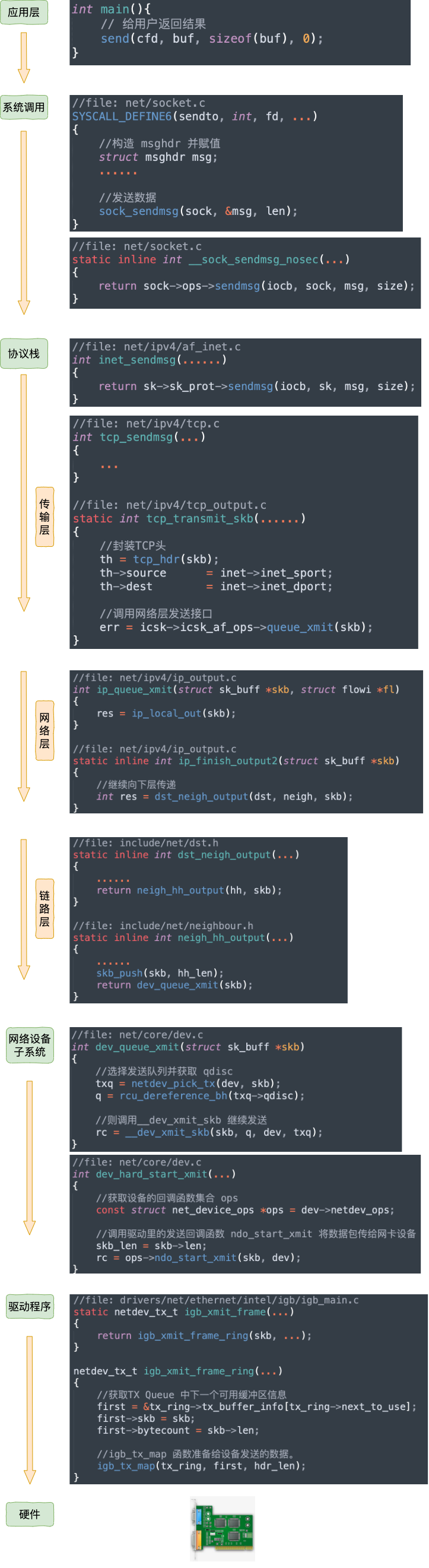
不过上面这幅图并没有很好地把内核组件和源码展示出来,我们再从代码的视角看一遍。
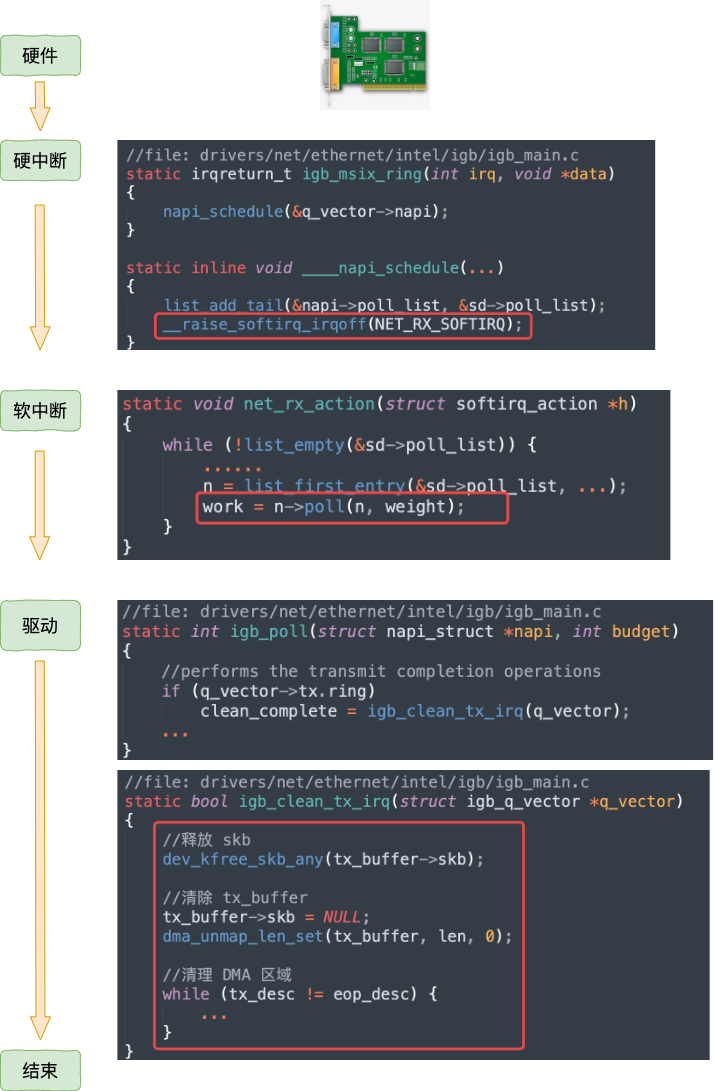
等网络发送完毕之后。网卡在发送完毕的时候,会给 CPU 发送一个硬中断来通知 CPU。收到这个硬中断后会释放 RingBuffer 中使用的内存。
1.2 跨机数据接收
当数据包到达另外一台机器的时候,Linux 数据包的接收过程开始了。
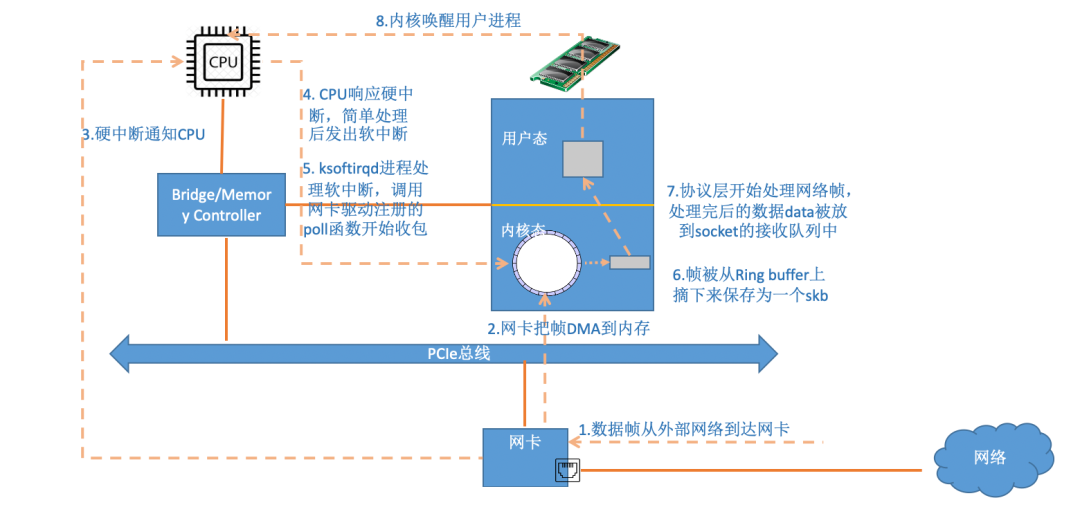
当网卡收到数据以后,CPU发起一个中断,以通知 CPU 有数据到达。当CPU收到中断请求后,会去调用网络驱动注册的中断处理函数,触发软中断。ksoftirqd 检测到有软中断请求到达,开始轮询收包,收到后交由各级协议栈处理。当协议栈处理完并把数据放到接收队列的之后,唤醒用户进程(假设是阻塞方式)。
我们再同样从内核组件和源码视角看一遍。
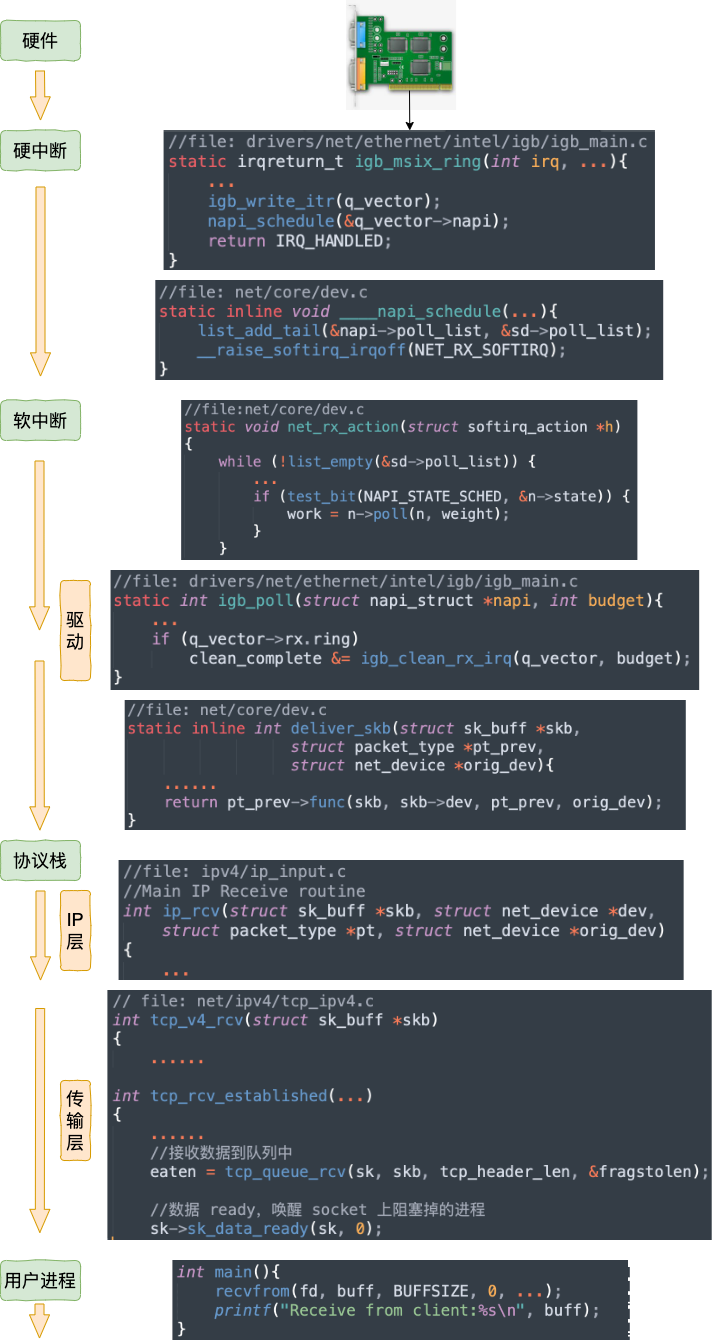
1.3 跨机网络通信汇总
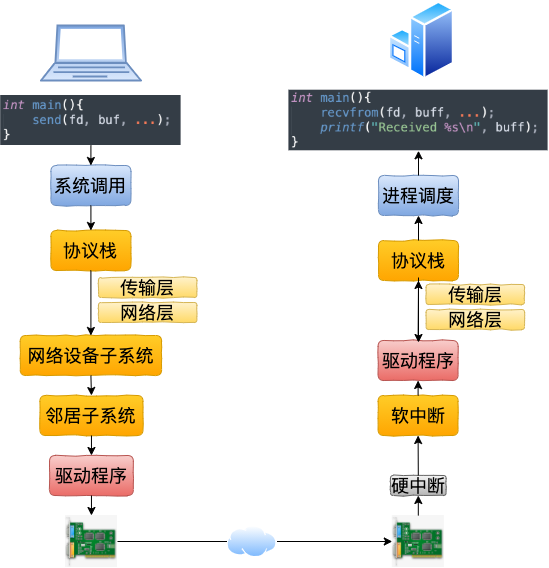
二、本机发送过程
在第一节中,我们看到了跨机时整个网络发送过程(嫌第一节流程图不过瘾,想继续看源码了解细节的同学可以参考 拆解 Linux 网络包发送过程) 。
在本机网络 IO 的过程中,流程会有一些差别。为了突出重点,将不再介绍整体流程,而是只介绍和跨机逻辑不同的地方。有差异的地方总共有两个,分别是路由和驱动程序。
2.1 网络层路由
发送数据会进入协议栈到网络层的时候,网络层入口函数是 ip_queue_xmit。在网络层里会进行路由选择,路由选择完毕后,再设置一些 IP 头、进行一些 netfilter 的过滤后,将包交给邻居子系统。
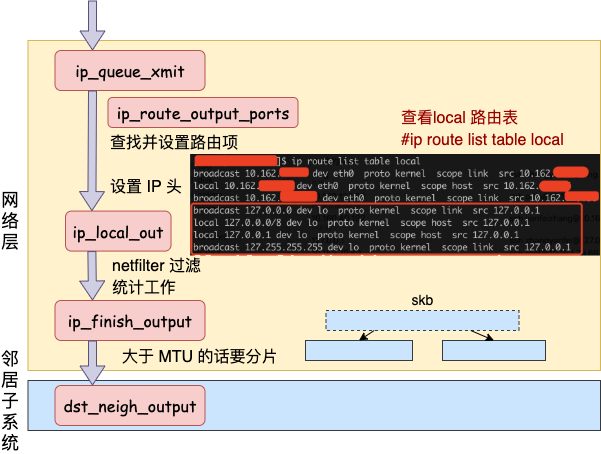
对于本机网络 IO 来说,特殊之处在于在 local 路由表中就能找到路由项,对应的设备都将使用 loopback 网卡,也就是我们常见的 lo。
我们来详细看看路由网络层里这段路由相关工作过程。从网络层入口函数 ip_queue_xmit 看起。
//file: net/ipv4/ip_output.c
int ip_queue_xmit(struct sk_buff *skb, struct flowi *fl)
{
//检查 socket 中是否有缓存的路由表
rt = (struct rtable *)__sk_dst_check(sk, 0);
if (rt == NULL) {
//没有缓存则展开查找
//则查找路由项, 并缓存到 socket 中
rt = ip_route_output_ports(...);
sk_setup_caps(sk, &rt->dst);
}
查找路由项的函数是 ip_route_output_ports,它又依次调用到 ip_route_output_flow、__ip_route_output_key、fib_lookup。调用过程省略掉,直接看 fib_lookup 的关键代码。
//file:include/net/ip_fib.h
static inline int fib_lookup(struct net *net, const struct flowi4 *flp,
struct fib_result *res)
{
struct fib_table *table;
table = fib_get_table(net, RT_TABLE_LOCAL);
if (!fib_table_lookup(table, flp, res, FIB_LOOKUP_NOREF))
return 0;
table = fib_get_table(net, RT_TABLE_MAIN);
if (!fib_table_lookup(table, flp, res, FIB_LOOKUP_NOREF))
return 0;
return -ENETUNREACH;
}
在 fib_lookup 将会对 local 和 main 两个路由表展开查询,并且是先查 local 后查询 main。我们在 Linux 上使用命令名可以查看到这两个路由表, 这里只看 local 路由表(因为本机网络 IO 查询到这个表就终止了)。
#ip route list table local
local 10.143.x.y dev eth0 proto kernel scope host src 10.143.x.y
local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1
从上述结果可以看出,对于目的是 127.0.0.1 的路由在 local 路由表中就能够找到了。fib_lookup 工作完成,返回__ip_route_output_key 继续。
//file: net/ipv4/route.c
struct rtable *__ip_route_output_key(struct net *net, struct flowi4 *fl4)
{
if (fib_lookup(net, fl4, &res)) {
}
if (res.type == RTN_LOCAL) {
dev_out = net->loopback_dev;
...
}
rth = __mkroute_output(&res, fl4, orig_oif, dev_out, flags);
return rth;
}
对于是本机的网络请求,设备将全部都使用 net->loopback_dev,也就是 lo 虚拟网卡。
接下来的网络层仍然和跨机网络 IO 一样,最终会经过 ip_finish_output,最终进入到 邻居子系统的入口函数 dst_neigh_output 中。
本机网络 IO 需要进行 IP 分片吗?因为和正常的网络层处理过程一样会经过 ip_finish_output 函数。在这个函数中,如果 skb 大于 MTU 的话,仍然会进行分片。只不过 lo 的 MTU 比 Ethernet 要大很多。通过 ifconfig 命令就可以查到,普通网卡一般为 1500,而 lo 虚拟接口能有 65535。
在邻居子系统函数中经过处理,进入到网络设备子系统(入口函数是 dev_queue_xmit)。
2.2 网络设备子系统
网络设备子系统的入口函数是 dev_queue_xmit。简单回忆下之前讲述跨机发送过程的时候,对于真的有队列的物理设备,在该函数中进行了一系列复杂的排队等处理以后,才调用 dev_hard_start_xmit,从这个函数 再进入驱动程序来发送。在这个过程中,甚至还有可能会触发软中断来进行发送,流程如图:
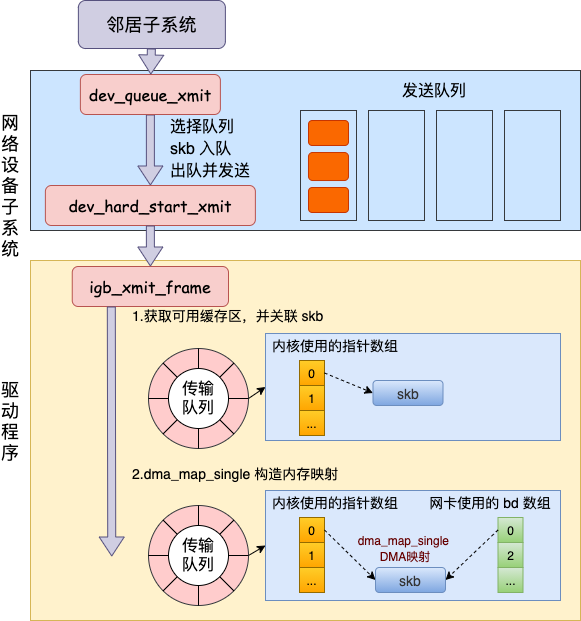
但是对于启动状态的回环设备来说(q->enqueue 判断为 false),就简单多了。没有队列的问题,直接进入 dev_hard_start_xmit。接着进入回环设备的“驱动”里的发送回调函数 loopback_xmit,将 skb “发送”出去。
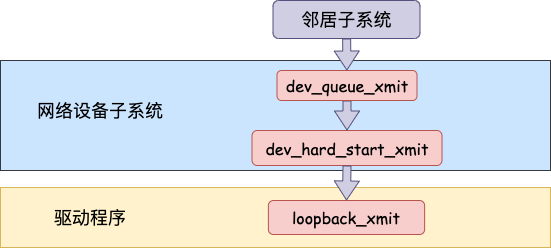
我们来看下详细的过程,从网络设备子系统的入口 dev_queue_xmit 看起。
//file: net/core/dev.c
int dev_queue_xmit(struct sk_buff *skb)
{
q = rcu_dereference_bh(txq->qdisc);
if (q->enqueue) {//回环设备这里为 false
rc = __dev_xmit_skb(skb, q, dev, txq);
goto out;
}
//开始回环设备处理
if (dev->flags & IFF_UP) {
dev_hard_start_xmit(skb, dev, txq, ...);
...
}
}
在 dev_hard_start_xmit 中还是将调用设备驱动的操作函数。
//file: net/core/dev.c
int dev_hard_start_xmit(struct sk_buff *skb, struct net_device *dev,
struct netdev_queue *txq)
{
//获取设备驱动的回调函数集合 ops
const struct net_device_ops *ops = dev->netdev_ops;
//调用驱动的 ndo_start_xmit 来进行发送
rc = ops->ndo_start_xmit(skb, dev);
...
}
2.3 “驱动”程序
对于真实的 igb 网卡来说,它的驱动代码都在 drivers/net/ethernet/intel/igb/igb_main.c 文件里。顺着这个路子,我找到了 loopback 设备的“驱动”代码位置:drivers/net/loopback.c。在 drivers/net/loopback.c
//file:drivers/net/loopback.c
static const struct net_device_ops loopback_ops = {
.ndo_init = loopback_dev_init,
.ndo_start_xmit= loopback_xmit,
.ndo_get_stats64 = loopback_get_stats64,
};
所以对 dev_hard_start_xmit 调用实际上执行的是 loopback “驱动” 里的 loopback_xmit。为什么我把“驱动”加个引号呢,因为 loopback 是一个纯软件性质的虚拟接口,并没有真正意义上的驱动,它的工作流程大致如图。
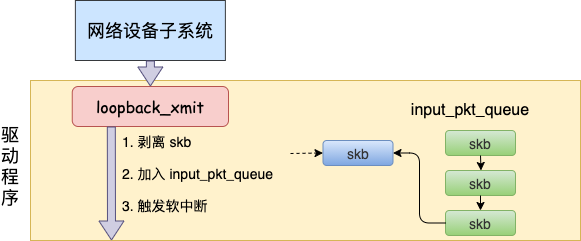
我们再来看详细的代码。
//file:drivers/net/loopback.c
static netdev_tx_t loopback_xmit(struct sk_buff *skb,
struct net_device *dev)
{
//剥离掉和原 socket 的联系
skb_orphan(skb);
//调用netif_rx
if (likely(netif_rx(skb) == NET_RX_SUCCESS)) {
}
}
在 skb_orphan 中先是把 skb 上的 socket 指针去掉了(剥离了出来)。
注意,在本机网络 IO 发送的过程中,传输层下面的 skb 就不需要释放了,直接给接收方传过去就行了。总算是省了一点点开销。不过可惜传输层的 skb 同样节约不了,还是得频繁地申请和释放。
接着调用 netif_rx,在该方法中 中最终会执行到 enqueue_to_backlog 中(netif_rx -> netif_rx_internal -> enqueue_to_backlog)。
//file: net/core/dev.c
static int enqueue_to_backlog(struct sk_buff *skb, int cpu,
unsigned int *qtail)
{
sd = &per_cpu(softnet_data, cpu);
...
__skb_queue_tail(&sd->input_pkt_queue, skb);
...
____napi_schedule(sd, &sd->backlog);
在 enqueue_to_backlog 把要发送的 skb 插入 softnet_data->input_pkt_queue 队列中并调用 ____napi_schedule 来触发软中断。
//file:net/core/dev.c
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
list_add_tail(&napi->poll_list, &sd->poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}
只有触发完软中断,发送过程就算是完成了。
三、本机接收过程
在跨机的网络包的接收过程中,需要经过硬中断,然后才能触发软中断。而在本机的网络 IO 过程中,由于并不真的过网卡,所以网卡实际传输,硬中断就都省去了。直接从软中断开始,经过 process_backlog 后送进协议栈,大体过程如图。
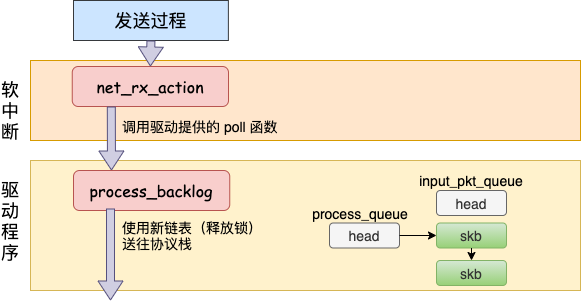
接下来我们再看更详细一点的过程。
在软中断被触发以后,会进入到 NET_RX_SOFTIRQ 对应的处理方法 net_rx_action 中(至于细节参见 图解Linux网络包接收过程 一文中的 3.2 小节)。
//file: net/core/dev.c
static void net_rx_action(struct softirq_action *h){
while (!list_empty(&sd->poll_list)) {
work = n->poll(n, weight);
}
}
我们还记得对于 igb 网卡来说,poll 实际调用的是 igb_poll 函数。那么 loopback 网卡的 poll 函数是谁呢?由于poll_list 里面是 struct softnet_data 对象,我们在 net_dev_init 中找到了蛛丝马迹。
//file:net/core/dev.c
static int __init net_dev_init(void)
{
for_each_possible_cpu(i) {
sd->backlog.poll = process_backlog;
}
}
原来struct softnet_data 默认的 poll 在初始化的时候设置成了 process_backlog 函数,来看看它都干了啥。
static int process_backlog(struct napi_struct *napi, int quota)
{
while(){
while ((skb = __skb_dequeue(&sd->process_queue))) {
__netif_receive_skb(skb);
}
//skb_queue_splice_tail_init()函数用于将链表a连接到链表b上,
//形成一个新的链表b,并将原来a的头变成空链表。
qlen = skb_queue_len(&sd->input_pkt_queue);
if (qlen)
skb_queue_splice_tail_init(&sd->input_pkt_queue,
&sd->process_queue);
}
}
这次先看对 skb_queue_splice_tail_init 的调用。源码就不看了,直接说它的作用是把 sd->input_pkt_queue 里的 skb 链到 sd->process_queue 链表上去。

然后再看 __skb_dequeue, __skb_dequeue 是从 sd->process_queue 上取下来包来处理。这样和前面发送过程的结尾处就对上了。发送过程是把包放到了 input_pkt_queue 队列里,接收过程是在从这个队列里取出 skb。
最后调用 __netif_receive_skb 将 skb(数据) 送往协议栈。在此之后的调用过程就和跨机网络 IO 又一致了。
送往协议栈的调用链是 __netif_receive_skb => __netif_receive_skb_core => deliver_skb 后 将数据包送入到 ip_rcv 中(详情参见图解Linux网络包接收过程 一文中的 3.3 小节)。
网络再往后依次是传输层,最后唤醒用户进程,这里就不多展开了。
四、本机网络 IO 总结
我们来总结一下本机网络 IO 的内核执行流程。
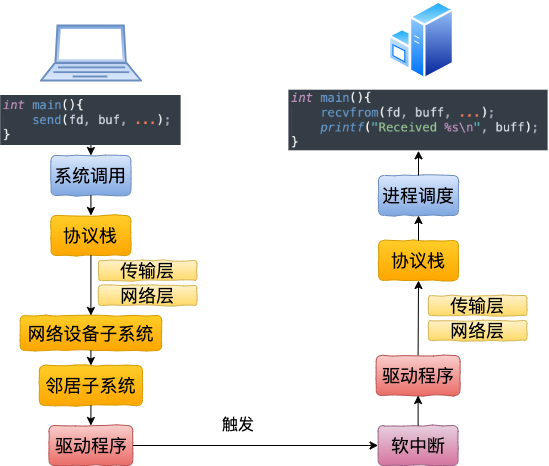
回想下跨机网络 IO 的流程是
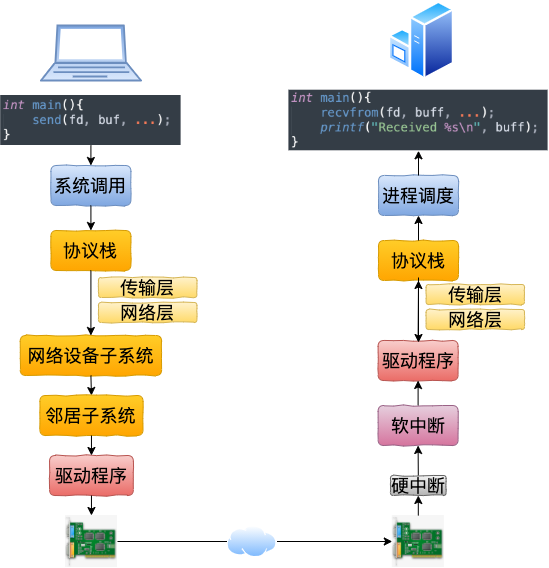
我们现在可以回顾下开篇的三个问题啦。
1)127.0.0.1 本机网络 IO 需要经过网卡吗?
通过本文的叙述,我们确定地得出结论,不需要经过网卡。即使了把网卡拔了本机网络是否还可以正常使用的。
2)数据包在内核中是个什么走向,和外网发送相比流程上有啥差别?
总的来说,本机网络 IO 和跨机 IO 比较起来,确实是节约了一些开销。发送数据不需要进 RingBuffer 的驱动队列,直接把 skb 传给接收协议栈(经过软中断)。但是在内核其它组件上,可是一点都没少,系统调用、协议栈(传输层、网络层等)、网络设备子系统、邻居子系统整个走了一个遍。连“驱动”程序都走了(虽然对于回环设备来说只是一个纯软件的虚拟出来的东东)。所以即使是本机网络 IO,也别误以为没啥开销。
最后再提一下,业界有公司基于 ebpf 来加速 istio 架构中 sidecar 代理和本地进程之间的通信。通过引入 BPF,才算是绕开了内核协议栈的开销,原理如下。
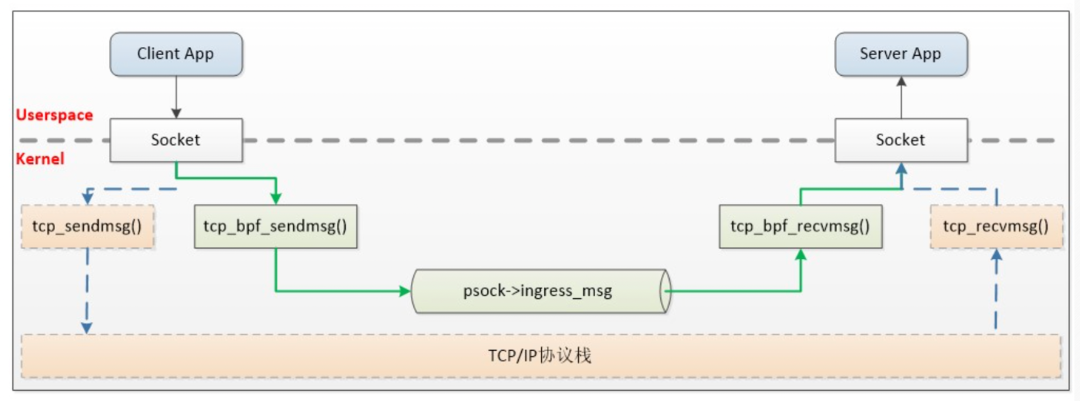
参见:https://cloud.tencent.com/developer/article/1671568