
B站崩了上热搜,A站跟着躺枪!微信、支付宝:跟我们比起来这是小问题

极市导读
今日凌晨,B 站发布公告称,昨晚,B 站的部分服务器机房发生故障,造成无法访问。技术团队随即进行了问题排查和修复,现在服务已经陆续恢复正常。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
崩了!
劳累了一天的年轻人们,正准备躺平拿出手机,打开那熟悉的小破站App,一键三连自己最喜爱的up主的最新视频。突然发现:
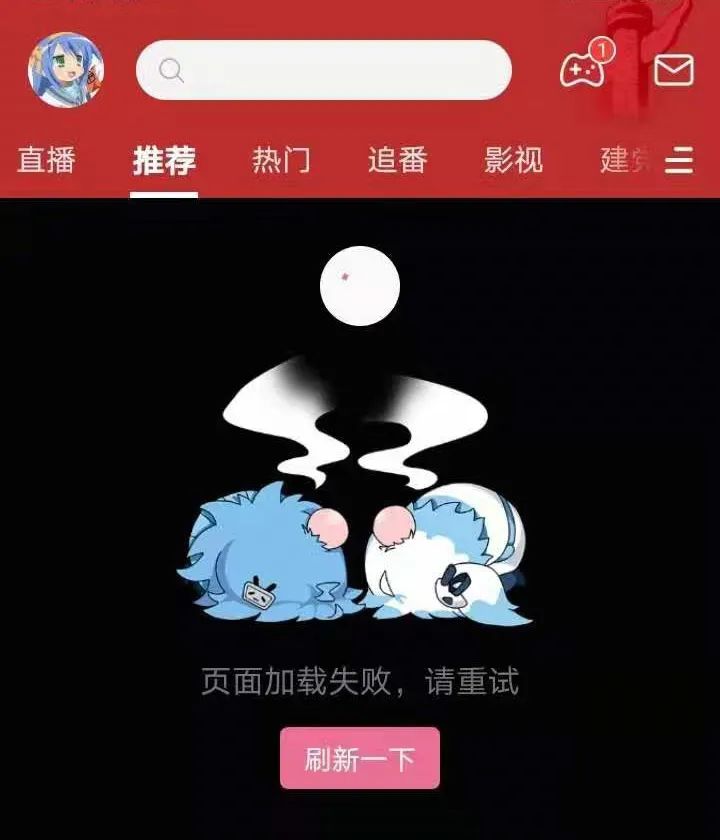
瞬间,「B站崩了」的消息登上热搜,微博运维心头一紧。
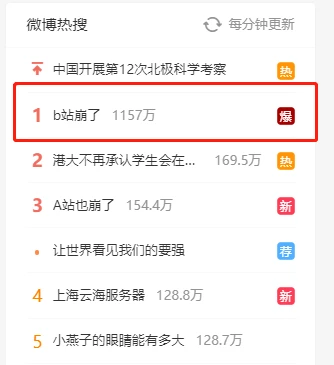
部分网友表示:A站、豆瓣等网站也出现访问故障,重连Wi-Fi也没有用。
今日凌晨,B 站发布公告称,昨晚,B 站的部分服务器机房发生故障,造成无法访问。技术团队随即进行了问题排查和修复,现在服务已经陆续恢复正常。

「小破站」发生什么事了?
这份模棱两可的声明显然无法阻挡住吃瓜群众的热情。
短短几分钟,关于B站的各种揣测消息就变成了百家讲坛:
有火灾说、删库跑路说、刑事案件说、服务器供应商说、黑客攻击说、大楼坍塌说、外星人说……

还有人煞有介事地Po出了B站运营小妹的朋友圈,说B站停电了……
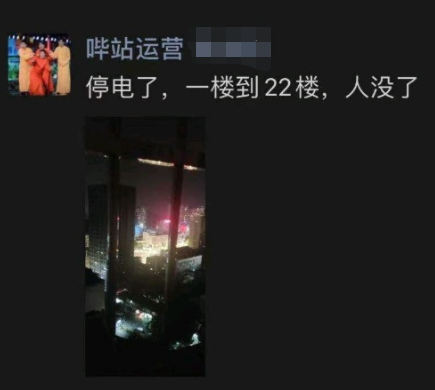
随后立刻有专业人士指出:B站作为一个上市的互联网公司,服务器多地备份是最最起码的事,楼里停电这个解释,估计只能骗骗没有学过数据库的高中生。
至于A站和晋江文学网为什么会挂,很可能是因为B站挂了,大批用户无片可看,就涌入A站和豆瓣,造成网站的流量激增,哪怕A站和B站不共用云服务,也可能被压垮。
B站7000多万日活网友的威力可见一斑。

下面我们看看几个相对靠谱的猜测:
知乎作者@黄珏珅 盲猜了一下,应该是etcd挂了。

通常来说,能造成几乎所有请求都502的,要不就是前端和后端之间的网络通路全挂了,要不就是后端的服务全都挂了。
那么现在的大型互联网公司的基础设施是怎样的呢,大多数使用了kubernetes,实现全国各地的数据中心的容器编排、网络虚拟化等。
而kubernetes的设计上,网络插件和pod编排又是相对独立的。
如果只是网络插件出问题了,那么部分服务器上的网络插件的缓存还在,一定有部分用户还能正常使用。
现在所有的都挂了,那只能是etcd挂掉,导致反向代理无法通过etcd找到对应的pod的虚拟ip,又无法通过网络插件与对应的pod通信。
知乎作者@k8seasy 则认为这个基本属于站点本身故障。从恢复时间看30分钟左右,并且几乎100%恢复,说明应该是某个核心组件崩溃了,导致核心服务不可用。
出现这种可能的不少,最有可能的原因是上线新版本,开始没问题,升级了部分集群,结果新版本有bug,到了某个时刻直接挂了,老版本的压力一大也没扛住。然后紧急定位,回滚解决。
也有网友提出,此次事件与云服务商离不开干系:

云服务提供商提供的CDN出现意外之后,大量请求绕过CDN直接打到网关,网关收到大量请求,自动启动了容灾策略。
容灾策略启动服务降级。服务降级了但没完全降,CDN挂了,网关也跟着挂了,服务雪崩,一直崩到整个环境。
盘点史上严重的服务宕机事件:最高损失上亿美元
在互联网历史上,「小破站」这样的宕机事件只能算是「洒洒水」,不信?我们来看看其他互联网大咖们是如何玩转宕机的。
7小时不能上微信:2013年7月22日,微信服务宕机,造成了将近7个小时的网络中断。据微信官方公布信息,由于上海一支施工队挖断了通信光缆,导致腾讯华东数据处理中心的业务请求纷纷转向华南和华北,进而导致了业务的全面瘫痪。
用支付宝「剁手」失败:2015年5月27日下午,部分用户反映其支付宝出现网络故障,账号无法登录或支付。支付宝官方表示,故障是由于杭州市萧山区某地光纤被挖断导致,该事件造成部分用户无法使用支付宝。随后支付宝工程师紧急将用户请求切换至其他机房,受影响的用户开始逐步恢复。到了晚上7点20分,支付宝方面宣布用户服务已经完全恢复正常。

而在国外,网络宕机的事件更是屡见不鲜。
亚马逊云服务罢工:2015年9月,亚马逊的云服务器因收到来自新上线的DynamoDB功能带来的大量数据请求,导致其因过载而宕机。于是,包括Reddit、Tinder、Netflix和IMDB在内的众多流行应用和网址直接罢工了数小时。
除了Netflix,绝大多数亚马逊云服务的客户在此次“突击检查”中,都被发现毫无准备。而Netflix此前已经使用过一种名为“混沌工程”的技术来模拟类似服务中断事件的发生,使得这起事故对其影响降到了最小。

纳斯达克停摆:2013年8月22日,由于纳斯达克交易所的备用服务器中出现了一个严重的bug,直接导致纳斯达克停摆了3个多小时。当其恢复运作时,已经引起了市场恐慌,大量交易员涌向交易窗口,出售交易所运营商纳斯达克OMX集团的股票,导致OMX集团的股价当日一度大跌逾5%。
事后有人评估,由于纳斯达克停摆造成的经济损失可能达数亿美元。

全美大宕机:2016年10月21日早晨,许多美国用户突然发现包括Twitter、CNN、Spotify等大型网站均无法登陆。这场网络瘫痪从美国东部开始,一路蔓延至全美区域。事后发现查明,原因是服务器遭受了黑客的DDoS攻击。
关于B站宕机事故,新智元的热心读者,开源基础软件公司Zilliz的质量保障团队负责人乔燕良做了较为专业客观的分析:
现在的网站故障造成的原因主要可分为软件服务引起的故障和硬件服务引起的故障。软件服务故障一般可理解为代码逻辑缺陷,常见的是新增或更新某个功能而引入缺陷导致整个服务中断,硬件服务故障一般是由于某些服务设备的损坏造成的服务中断,比如光纤被挖断了。
如果要降低宕机风险,就需要提高服务的高可用性。首先从架构上,建议采用云原生架构,实现自动容错机制和故障隔离,从而能够在服务出现故障时快速迁移或回滚。
其次为防止硬件故障类风险,需要有完善的灾备方案,同城双活或异地灾备目前都已经有比较成熟的方案,国内企业在这块投入相对比较“节约”。
Bilibili,下次一定!
参考资料:http://www.zhihu.com/question/472065470
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
