
Excel大批量数据的导入和导出,如何做优化?
点击上方 java项目开发,选择 设为星标
优质文章,及时送达
--
概要
Java对Excel的操作一般都是用POI,但是数据量大的话可能会导致频繁的FGC或OOM,这篇文章跟大家说下如果避免踩POI的坑,以及分别对于xls和xlsx文件怎么优化大批量数据的导入和导出。
一次线上问题
这是一次线上的问题,因为一个大数据量的Excel导出功能,而导致服务器频繁FGC,具体如图所示
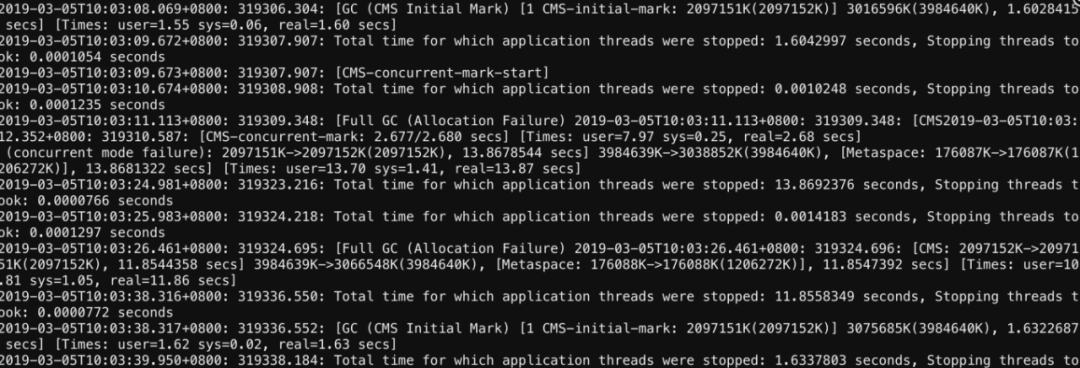
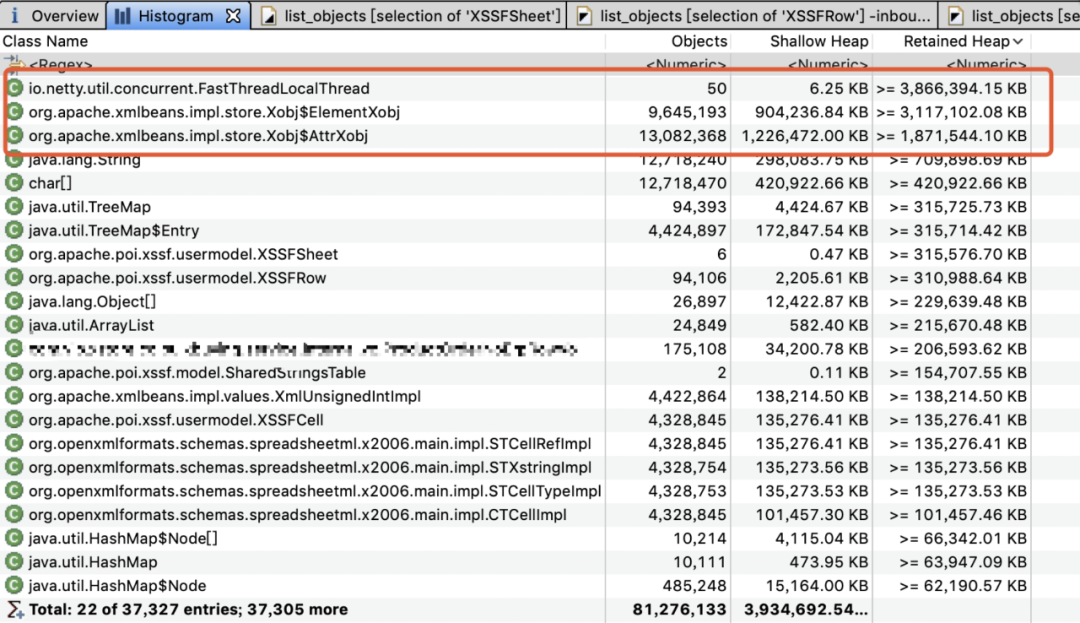
可以看出POI的对象以及相关的XML对象占用了绝大部分的内存消耗,频繁FGC说明这些对象一直存活,没有被回收。
原因是由于导出的数据比较大量,大概有10w行 * 50列,由于后台直接用XSSFWorkbook导出,在导出结束前内存有大量的Row,Cell,Style等,以及基于XLSX底层存储的XML对象没有被释放。
Excel的存储格式
下面的优化内容涉及Excel的底层存储格式,所以要先跟大家讲一下。
XLS
03版的XLS采用的是一种名为BIFF8(Binary-Interchange-File-Format),基于OLE2规范的二进制文件格式。大概就是一种结构很复杂的二进制文件,具体细节我也不是很清楚,大家也没必要去了解它,已经被淘汰了。想了解的话可以看看Excel XLS文件格式
XLSX
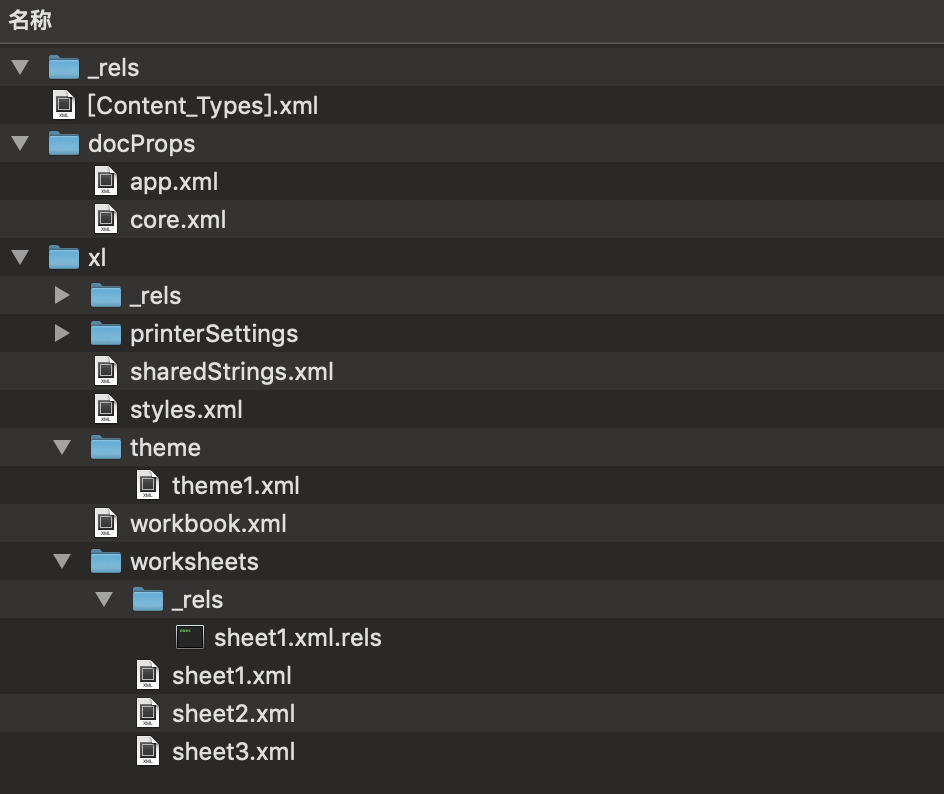
07版的XLSX则是采用OOXML(Office Open Xml)的格式存储数据。简单来说就是一堆xml文件用zip打包之后文件。这个对于大家来说就熟悉了,把xlsx文件后缀名改为zip后,再解压出来就可以看到文件结构
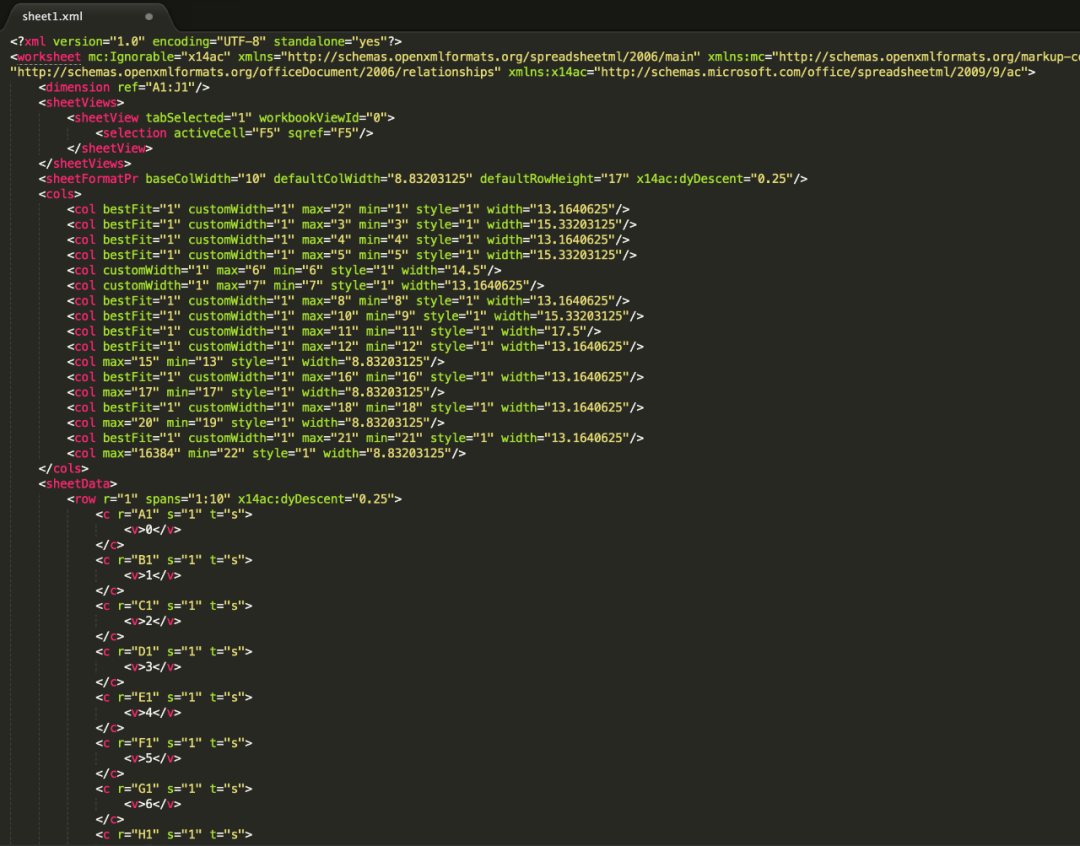
打开sheet1.xml,可以看到是描述第一个sheet的内容
导出优化
事例源码基于POI3.17版本
XLSX
由于xlsx底层使用xml存储,占用内存会比较大,官方也意识到这个问题,在3.8版本之后,提供了SXSSFWorkbook来优化写性能。
官方说明
https://poi.apache.org/components/spreadsheet/how-to.html#sxssf
使用
SXSSFWorkbook使用起来特别的简单,只需要改一行代码就OK了。
原来你的代码可能是长这样的
Workbook workbook = new XSSFWorkbook(inputStream);
那么你只需要改成这样子,就可以用上SXSSFWorkbook了
Workbook workbook = new SXSSFWorkbook(new XSSFWorkbook(inputStream));
其原理是可以定义一个window size(默认100),生成Excel期间只在内存维持window size那么多的行数Row,超时window size时会把之前行Row写到一个临时文件并且remove释放掉,这样就可以达到释放内存的效果。
SXSSFSheet在创建Row时会判断并刷盘、释放超过window size的Row。
@Override
public SXSSFRow createRow(int rownum)
{
int maxrow = SpreadsheetVersion.EXCEL2007.getLastRowIndex();
if (rownum < 0 || rownum > maxrow) {
throw new IllegalArgumentException("Invalid row number (" + rownum
+ ") outside allowable range (0.." + maxrow + ")");
}
// attempt to overwrite a row that is already flushed to disk
if(rownum <= _writer.getLastFlushedRow() ) {
throw new IllegalArgumentException(
"Attempting to write a row["+rownum+"] " +
"in the range [0," + _writer.getLastFlushedRow() + "] that is already written to disk.");
}
// attempt to overwrite a existing row in the input template
if(_sh.getPhysicalNumberOfRows() > 0 && rownum <= _sh.getLastRowNum() ) {
throw new IllegalArgumentException(
"Attempting to write a row["+rownum+"] " +
"in the range [0," + _sh.getLastRowNum() + "] that is already written to disk.");
}
SXSSFRow newRow=new SXSSFRow(this);
_rows.put(rownum,newRow);
allFlushed = false;
//如果大于窗口的size,就会flush
if(_randomAccessWindowSize>=0&&_rows.size()>_randomAccessWindowSize)
{
try
{
flushRows(_randomAccessWindowSize);
}
catch (IOException ioe)
{
throw new RuntimeException(ioe);
}
}
return newRow;
}
public void flushRows(int remaining) throws IOException
{
//flush每一个row
while(_rows.size() > remaining) {
flushOneRow();
}
if (remaining == 0) {
allFlushed = true;
}
}
private void flushOneRow() throws IOException
{
Integer firstRowNum = _rows.firstKey();
if (firstRowNum!=null) {
int rowIndex = firstRowNum.intValue();
SXSSFRow row = _rows.get(firstRowNum);
// Update the best fit column widths for auto-sizing just before the rows are flushed
_autoSizeColumnTracker.updateColumnWidths(row);
//写盘
_writer.writeRow(rowIndex, row);
//然后把row remove掉,这里的_rows是一个TreeMap结构
_rows.remove(firstRowNum);
lastFlushedRowNumber = rowIndex;
}
}
我们再看看刷盘的具体操作
SXSSFSheet在创建的时候,都会创建一个SheetDataWriter,刷盘动作正是由这个类完成的
看下SheetDataWriter的初始化
public SheetDataWriter() throws IOException {
//创建临时文件
_fd = createTempFile();
//拿到文件的BufferedWriter
_out = createWriter(_fd);
}
//在本地创建了一个临时文件前缀为poi-sxssf-sheet,后缀为.xml
public File createTempFile() throws IOException {
return TempFile.createTempFile("poi-sxssf-sheet", ".xml");
}
public static File createTempFile(String prefix, String suffix) throws IOException {
//用一个策略去创建文件
return strategy.createTempFile(prefix, suffix);
}
//这个策略就是在执行路径先创建一个目录(如果不存在的话),然后再在里面创建一个随机唯一命名的文件
public File createTempFile(String prefix, String suffix) throws IOException {
// Identify and create our temp dir, if needed
createPOIFilesDirectory();
// Generate a unique new filename
File newFile = File.createTempFile(prefix, suffix, dir);
// Set the delete on exit flag, unless explicitly disabled
if (System.getProperty(KEEP_FILES) == null) {
newFile.deleteOnExit();
}
// All done
return newFile;
}
POI就是把超过window size的Row刷到临时文件里,然后再把临时文件转为正常的xlsx文件格式输出。
我们看看刷盘时写了什么,SheetDataWriter的writeRow方法
public void writeRow(int rownum, SXSSFRow row) throws IOException {
if (_numberOfFlushedRows == 0)
_lowestIndexOfFlushedRows = rownum;
_numberLastFlushedRow = Math.max(rownum, _numberLastFlushedRow);
_numberOfCellsOfLastFlushedRow = row.getLastCellNum();
_numberOfFlushedRows++;
beginRow(rownum, row);
Iterator cells = row.allCellsIterator();
int columnIndex = 0;
while (cells.hasNext()) {
writeCell(columnIndex++, cells.next());
}
endRow();
}
void beginRow(int rownum, SXSSFRow row) throws IOException {
_out.write(");
writeAttribute("r", Integer.toString(rownum + 1));
if (row.hasCustomHeight()) {
writeAttribute("customHeight", "true");
writeAttribute("ht", Float.toString(row.getHeightInPoints()));
}
if (row.getZeroHeight()) {
writeAttribute("hidden", "true");
}
if (row.isFormatted()) {
writeAttribute("s", Integer.toString(row.getRowStyleIndex()));
writeAttribute("customFormat", "1");
}
if (row.getOutlineLevel() != 0) {
writeAttribute("outlineLevel", Integer.toString(row.getOutlineLevel()));
}
if(row.getHidden() != null) {
writeAttribute("hidden", row.getHidden() ? "1" : "0");
}
if(row.getCollapsed() != null) {
writeAttribute("collapsed", row.getCollapsed() ? "1" : "0");
}
_out.write(">\n");
this._rownum = rownum;
}
void endRow() throws IOException {
_out.write("\n");
}
public void writeCell(int columnIndex, Cell cell) throws IOException {
if (cell == null) {
return;
}
String ref = new CellReference(_rownum, columnIndex).formatAsString();
_out.write(");
writeAttribute("r", ref);
CellStyle cellStyle = cell.getCellStyle();
if (cellStyle.getIndex() != 0) {
// need to convert the short to unsigned short as the indexes can be up to 64k
// ideally we would use int for this index, but that would need changes to some more
// APIs
writeAttribute("s", Integer.toString(cellStyle.getIndex() & 0xffff));
}
CellType cellType = cell.getCellTypeEnum();
switch (cellType) {
case BLANK: {
_out.write('>');
break;
}
case FORMULA: {
_out.write(">" );
outputQuotedString(cell.getCellFormula());
_out.write("");
switch (cell.getCachedFormulaResultTypeEnum()) {
case NUMERIC:
double nval = cell.getNumericCellValue();
if (!Double.isNaN(nval)) {
_out.write("" );
_out.write(Double.toString(nval));
_out.write("");
}
break;
default:
break;
}
break;
}
case STRING: {
if (_sharedStringSource != null) {
XSSFRichTextString rt = new XSSFRichTextString(cell.getStringCellValue());
int sRef = _sharedStringSource.addEntry(rt.getCTRst());
writeAttribute("t", STCellType.S.toString());
_out.write(">" );
_out.write(String.valueOf(sRef));
_out.write("");
} else {
writeAttribute("t", "inlineStr");
_out.write(">);
if (hasLeadingTrailingSpaces(cell.getStringCellValue())) {
writeAttribute("xml:space", "preserve");
}
_out.write(">");
outputQuotedString(cell.getStringCellValue());
_out.write("
}
break;
}
case NUMERIC: {
writeAttribute("t", "n");
_out.write(">" );
_out.write(Double.toString(cell.getNumericCellValue()));
_out.write("");
break;
}
case BOOLEAN: {
writeAttribute("t", "b");
_out.write(">" );
_out.write(cell.getBooleanCellValue() ? "1" : "0");
_out.write("");
break;
}
case ERROR: {
FormulaError error = FormulaError.forInt(cell.getErrorCellValue());
writeAttribute("t", "e");
_out.write(">" );
_out.write(error.getString());
_out.write("");
break;
}
default: {
throw new IllegalStateException("Invalid cell type: " + cellType);
}
}
_out.write("");
}
| 可以看到临时文件里内容跟xlsx的文件格式是保持一致的。
测试
本地测试使用SXSSFWorkbook导出30w行 * 10列内存使用情况
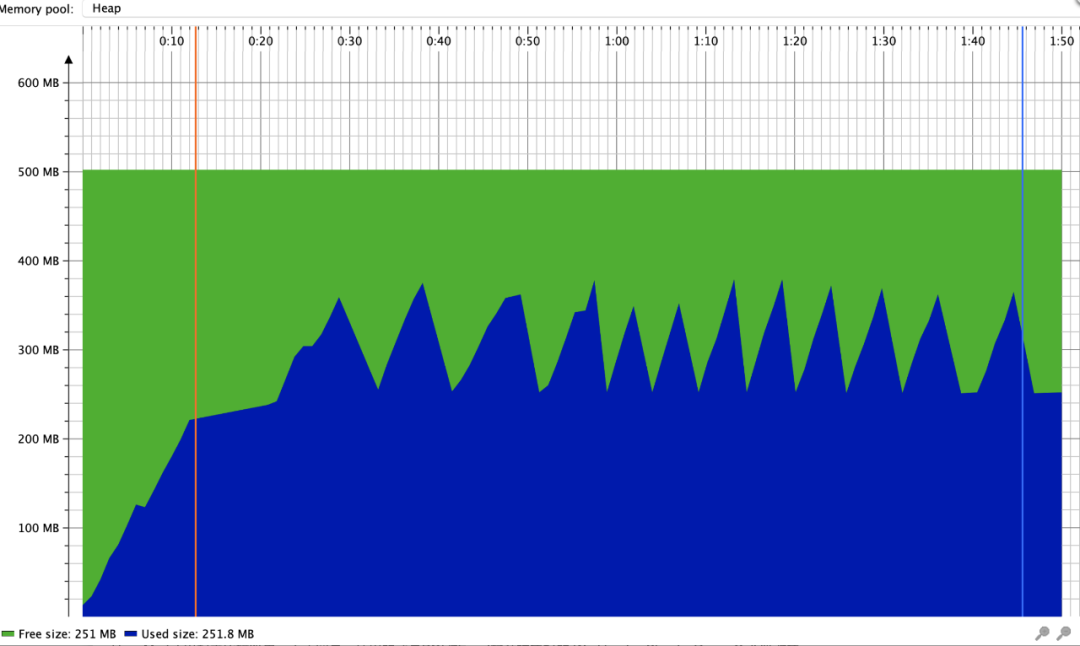
可以看出内存有被回收的情况,比较平稳。
XLS
POI没有像XLSX那样对XLS的写做出性能的优化,原因是:
官方认为XLS的不像XLSX那样占内存 XLS一个Sheet最多也只能有65535行数据
导入优化
POI对导入分为3种模式,用户模式User Model,事件模式Event Model,还有Event User Model。
用户模式
用户模式(User Model)就类似于dom方式的解析,是一种high level api,给人快速、方便开发用的。缺点是一次性将文件读入内存,构建一颗Dom树。并且在POI对Excel的抽象中,每一行,每一个单元格都是一个对象。当文件大,数据量多的时候对内存的占用可想而知。
用户模式就是类似用 WorkbookFactory.create(inputStream),poi 会把整个文件一次性解析,生成全部的Sheet,Row,Cell以及对象,如果导入文件数据量大的话,也很可能会导致OOM。
本地测试用户模式读取XLSX文件,数据量10w行 * 50列,内存使用如下
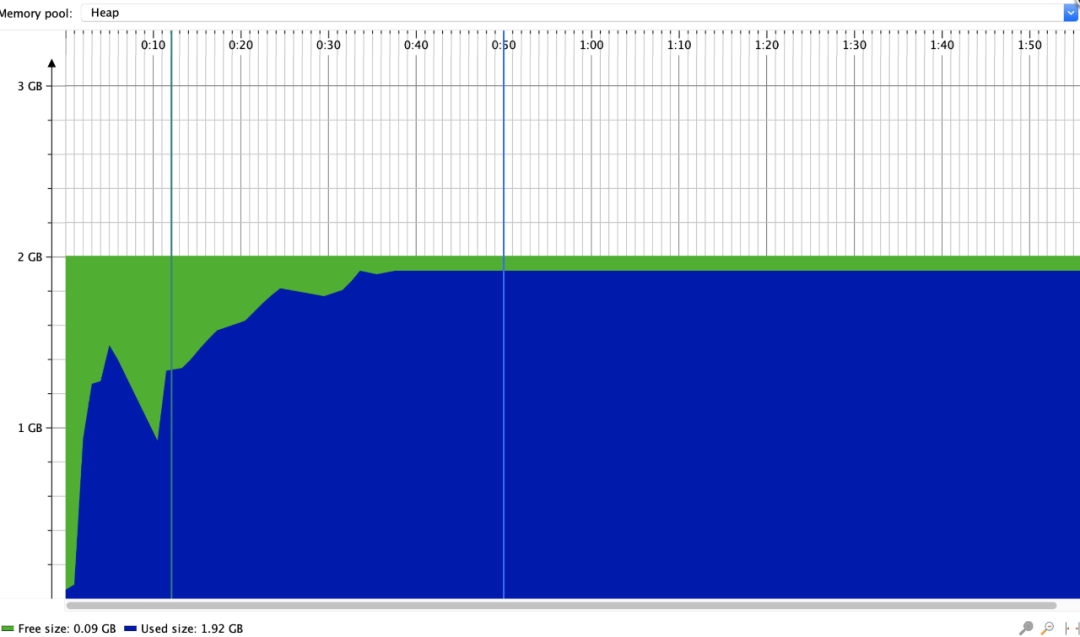
事件模式
事件模式(Event Model)就是SAX解析。Event Model使用的方式是边读取边解析,并且不会将这些数据封装成Row,Cell这样的对象。而都只是普通的数字或者是字符串。并且这些解析出来的对象是不需要一直驻留在内存中,而是解析完使用后就可以回收。所以相比于User Model,Event Model更节省内存,效率也更。
但是作为代价,相比User Model功能更少,门槛也要高一些。我们需要去学习Excel存储数据的各个Xml中每个标签,标签中的属性的含义,然后对解析代码进行设计。
User Event Model
User Event Model也是采用流式解析,但是不同于Event Model,POI基于Event Model为我们封装了一层。我们不再面对Element的事件编程,而是面向StartRow,EndRow,Cell等事件编程。而提供的数据,也不再像之前是原始数据,而是全部格式化好,方便开发者开箱即用。大大简化了我们的开发效率。
XLSX
POI对XLSX支持Event Model和Event User Model
XLSX的Event Model
使用
官网例子:
http://svn.apache.org/repos/asf/poi/trunk/src/examples/src/org/apache/poi/examples/xssf/eventusermodel/FromHowTo.java
简单来说就是需要继承DefaultHandler,覆盖其startElement,endElement方法。然后方法里获取你想要的数据。
原理
DefaultHandler相信熟悉的人都知道,这是JDK自带的对XML的SAX解析用到处理类,POI在进行SAX解析时,把读取到每个XML的元素时则会回调这两个方法,然后我们就可以获取到想用的数据了。
我们回忆一下上面说到的XLSX存储格式中sheet存储数据的格式。
再看看官方例子中的解析过程
@Override
public void startElement(String uri, String localName, String name,
Attributes attributes) throws SAXException {
//c代表是一个单元格cell,判断c这个xml元素里面属性attribute t
// c => cell
if(name.equals("c")) {
// Print the cell reference
System.out.print(attributes.getValue("r") + " - ");
// Figure out if the value is an index in the SST
String cellType = attributes.getValue("t");
nextIsString = cellType != null && cellType.equals("s");
inlineStr = cellType != null && cellType.equals("inlineStr");
}
// Clear contents cache
lastContents = "";
}
@Override
public void endElement(String uri, String localName, String name)
throws SAXException {
// Process the last contents as required.
// Do now, as characters() may be called more than once
if(nextIsString) {
Integer idx = Integer.valueOf(lastContents);
lastContents = lruCache.get(idx);
if (lastContents == null && !lruCache.containsKey(idx)) {
lastContents = new XSSFRichTextString(sst.getEntryAt(idx)).toString();
lruCache.put(idx, lastContents);
}
nextIsString = false;
}
//v 元素代表这个cell的内容
// v => contents of a cell
// Output after we've seen the string contents
if(name.equals("v") || (inlineStr && name.equals("c"))) {
System.out.println(lastContents);
}
}
可以看出你需要对XLSX的XML格式清楚,才能获取到你想要的东西。
XLSX的Event User Model
使用
官方例子
https://svn.apache.org/repos/asf/poi/trunk/src/examples/src/org/apache/poi/examples/xssf/eventusermodel/XLSX2CSV.java
简单来说就是继承XSSFSheetXMLHandler.SheetContentsHandler,覆盖其startRow,endRow,cell,endSheet 等方法。POI每开始读行,结束读行,读取一个cell,结束读取一个sheet时回调的方法。从方法名上看Event User Model有更好的用户体验。
原理
其实Event User Model也是 Event Model的封装,在XSSFSheetXMLHandler(其实也是一个DefaultHandler来的)中持有一个SheetContentsHandler,在其startElement,endElement方法中会调用SheetContentsHandler的startRow,endRow,cell,endSheet等方法。
我们看看XSSFSheetXMLHandler的startElement和endElement方法
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
if (uri != null && ! uri.equals(NS_SPREADSHEETML)) {
return;
}
if (isTextTag(localName)) {
vIsOpen = true;
// Clear contents cache
value.setLength(0);
} else if ("is".equals(localName)) {
// Inline string outer tag
isIsOpen = true;
} else if ("f".equals(localName)) {
// Clear contents cache
formula.setLength(0);
// Mark us as being a formula if not already
if(nextDataType == xssfDataType.NUMBER) {
nextDataType = xssfDataType.FORMULA;
}
// Decide where to get the formula string from
String type = attributes.getValue("t");
if(type != null && type.equals("shared")) {
// Is it the one that defines the shared, or uses it?
String ref = attributes.getValue("ref");
String si = attributes.getValue("si");
if(ref != null) {
// This one defines it
// TODO Save it somewhere
fIsOpen = true;
} else {
// This one uses a shared formula
// TODO Retrieve the shared formula and tweak it to
// match the current cell
if(formulasNotResults) {
logger.log(POILogger.WARN, "shared formulas not yet supported!");
} /*else {
// It's a shared formula, so we can't get at the formula string yet
// However, they don't care about the formula string, so that's ok!
}*/
}
} else {
fIsOpen = true;
}
}
else if("oddHeader".equals(localName) || "evenHeader".equals(localName) ||
"firstHeader".equals(localName) || "firstFooter".equals(localName) ||
"oddFooter".equals(localName) || "evenFooter".equals(localName)) {
hfIsOpen = true;
// Clear contents cache
headerFooter.setLength(0);
}
else if("row".equals(localName)) {
String rowNumStr = attributes.getValue("r");
if(rowNumStr != null) {
rowNum = Integer.parseInt(rowNumStr) - 1;
} else {
rowNum = nextRowNum;
}
//回调了SheetContentsHandler的startRow方法
output.startRow(rowNum);
}
// c => cell
else if ("c".equals(localName)) {
// Set up defaults.
this.nextDataType = xssfDataType.NUMBER;
this.formatIndex = -1;
this.formatString = null;
cellRef = attributes.getValue("r");
String cellType = attributes.getValue("t");
String cellStyleStr = attributes.getValue("s");
if ("b".equals(cellType))
nextDataType = xssfDataType.BOOLEAN;
else if ("e".equals(cellType))
nextDataType = xssfDataType.ERROR;
else if ("inlineStr".equals(cellType))
nextDataType = xssfDataType.INLINE_STRING;
else if ("s".equals(cellType))
nextDataType = xssfDataType.SST_STRING;
else if ("str".equals(cellType))
nextDataType = xssfDataType.FORMULA;
else {
// Number, but almost certainly with a special style or format
XSSFCellStyle style = null;
if (stylesTable != null) {
if (cellStyleStr != null) {
int styleIndex = Integer.parseInt(cellStyleStr);
style = stylesTable.getStyleAt(styleIndex);
} else if (stylesTable.getNumCellStyles() > 0) {
style = stylesTable.getStyleAt(0);
}
}
if (style != null) {
this.formatIndex = style.getDataFormat();
this.formatString = style.getDataFormatString();
if (this.formatString == null)
this.formatString = BuiltinFormats.getBuiltinFormat(this.formatIndex);
}
}
}
}
~
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
if (uri != null && ! uri.equals(NS_SPREADSHEETML)) {
return;
}
String thisStr = null;
// v => contents of a cell
if (isTextTag(localName)) {
vIsOpen = false;
// Process the value contents as required, now we have it all
switch (nextDataType) {
case BOOLEAN:
char first = value.charAt(0);
thisStr = first == '0' ? "FALSE" : "TRUE";
break;
case ERROR:
thisStr = "ERROR:" + value;
break;
case FORMULA:
if(formulasNotResults) {
thisStr = formula.toString();
} else {
String fv = value.toString();
if (this.formatString != null) {
try {
// Try to use the value as a formattable number
double d = Double.parseDouble(fv);
thisStr = formatter.formatRawCellContents(d, this.formatIndex, this.formatString);
} catch(NumberFormatException e) {
// Formula is a String result not a Numeric one
thisStr = fv;
}
} else {
// No formatting applied, just do raw value in all cases
thisStr = fv;
}
}
break;
case INLINE_STRING:
// TODO: Can these ever have formatting on them?
XSSFRichTextString rtsi = new XSSFRichTextString(value.toString());
thisStr = rtsi.toString();
break;
case SST_STRING:
String sstIndex = value.toString();
try {
int idx = Integer.parseInt(sstIndex);
XSSFRichTextString rtss = new XSSFRichTextString(sharedStringsTable.getEntryAt(idx));
thisStr = rtss.toString();
}
catch (NumberFormatException ex) {
logger.log(POILogger.ERROR, "Failed to parse SST index '" + sstIndex, ex);
}
break;
case NUMBER:
String n = value.toString();
if (this.formatString != null && n.length() > 0)
thisStr = formatter.formatRawCellContents(Double.parseDouble(n), this.formatIndex, this.formatString);
else
thisStr = n;
break;
default:
thisStr = "(TODO: Unexpected type: " + nextDataType + ")";
break;
}
// Do we have a comment for this cell?
checkForEmptyCellComments(EmptyCellCommentsCheckType.CELL);
XSSFComment comment = commentsTable != null ? commentsTable.findCellComment(new CellAddress(cellRef)) : null;
//回调了SheetContentsHandler的cell方法
// Output
output.cell(cellRef, thisStr, comment);
} else if ("f".equals(localName)) {
fIsOpen = false;
} else if ("is".equals(localName)) {
isIsOpen = false;
} else if ("row".equals(localName)) {
// Handle any "missing" cells which had comments attached
checkForEmptyCellComments(EmptyCellCommentsCheckType.END_OF_ROW);
//回调了SheetContentsHandler的endRow方法
// Finish up the row
output.endRow(rowNum);
// some sheets do not have rowNum set in the XML, Excel can read them so we should try to read them as well
nextRowNum = rowNum + 1;
} else if ("sheetData".equals(localName)) {
// Handle any "missing" cells which had comments attached
checkForEmptyCellComments(EmptyCellCommentsCheckType.END_OF_SHEET_DATA);
}
else if("oddHeader".equals(localName) || "evenHeader".equals(localName) ||
"firstHeader".equals(localName)) {
hfIsOpen = false;
output.headerFooter(headerFooter.toString(), true, localName);
}
else if("oddFooter".equals(localName) || "evenFooter".equals(localName) ||
"firstFooter".equals(localName)) {
hfIsOpen = false;
output.headerFooter(headerFooter.toString(), false, localName);
}
}
代码有点多,
一是为了展示一下XSSFSheetXMLHandler解析XML的过程,大家可以粗略看看 二是可以看出Event User Model也是Event Model的封装
测试
本地测试使用Event User Model读取XLSX文件,数据量10w行 * 50列
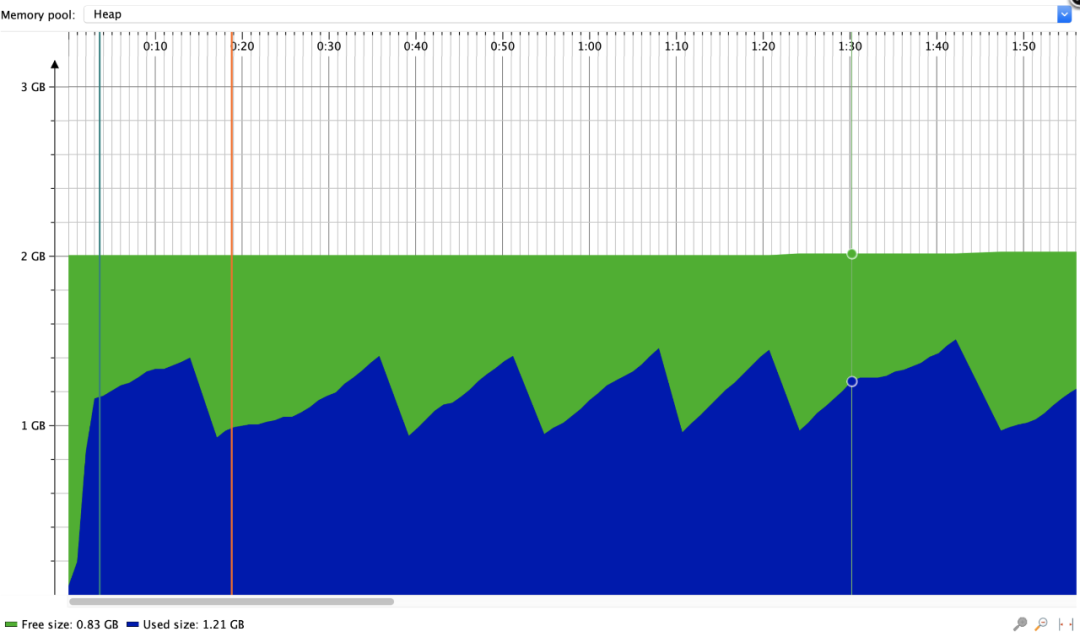
可以看出内存有回收的情况,比User Model好多了。
XLS
POI对XLS支持Event Model
使用
官方例子
http://svn.apache.org/repos/asf/poi/trunk/src/examples/src/org/apache/poi/examples/hssf/eventusermodel/XLS2CSVmra.java
需要继承HSSFListener,覆盖processRecord 方法,POI每读取到一个单元格的数据则会回调次方法。
原理
这里涉及BIFF8格式以及POI对其的封装,大家可以了解一下(因为其格式比较复杂,我也不是很清楚)
总结
POI优化了对XLSX的大批量写,以及支持对XLS和XLSX的SAX读,我们在实际开发时需要根据业务量来选择正确的处理,不然可能会导致OOM。
希望这篇文章能给大家启发。另外阿里开源了一个easyexcel,其实做的事情也差不多,大家可以看下。
作者:Alben https://albenw.github.io/posts/d093ca4e
- END - 推荐案例
温暖提示
为了方便大家更好的学习,本公众号经常分享一些完整的单个功能案例代码给大家去练习,如果本公众号没有你要学习的功能案例,你可以联系小编(微信:xxf960513)提供你的小需求给我,我安排我们这边的开发团队免费帮你完成你的案例。 注意:只能提单个功能的需求不能要求功能太多,比如要求用什么技术,有几个页面,页面要求怎么样?
请长按识别二维码
想学习更多的java功能案例请关注
Java项目开发
如果你觉得这个案例以及我们的分享思路不错,对你有帮助,请分享给身边更多需要学习的朋友。别忘了《留言+点在看》给作者一个鼓励哦

