20亿参数+30亿张图像,刷新ImageNet最高分!谷歌大脑华人研究员领衔发布最强Transformer

来源:新智元 本文约1300字,建议阅读5分钟 视觉Transformer进阶。
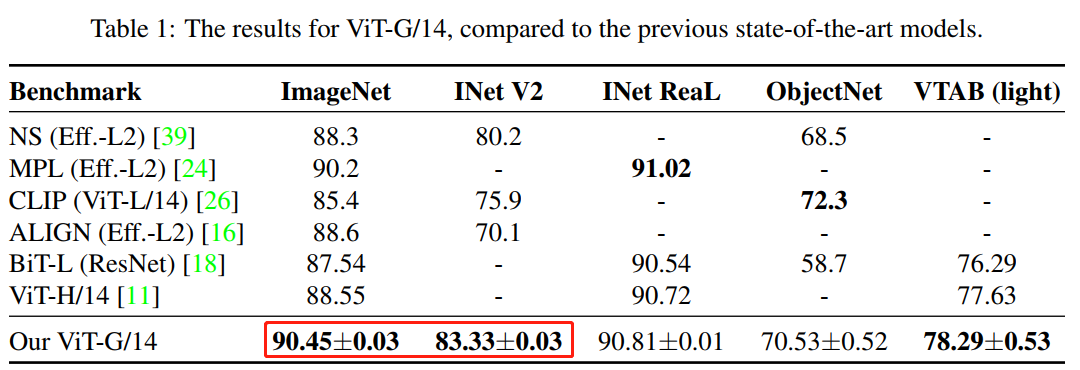

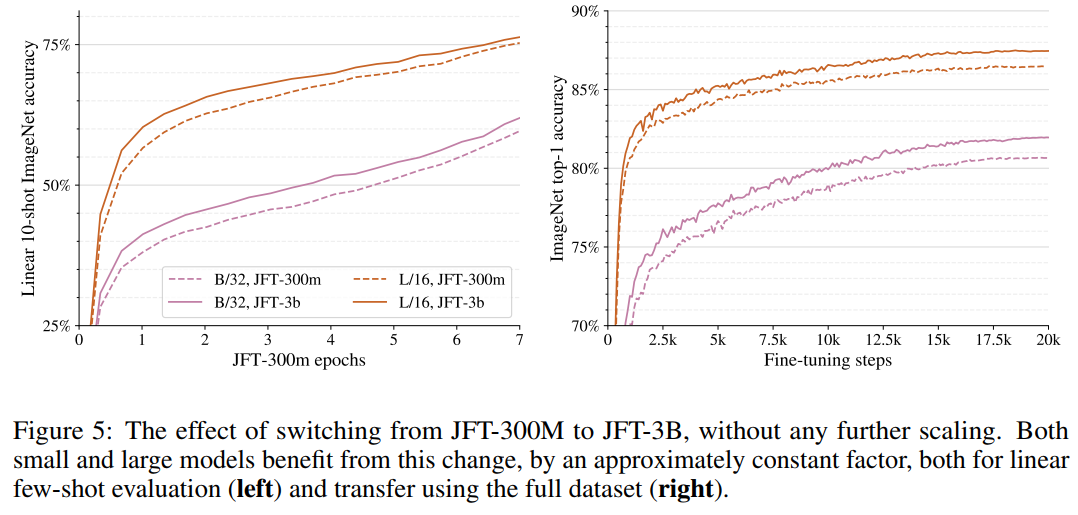
作者团队




参考资料:
https://arxiv.org/pdf/2106.04560.pdf
https://www.marktechpost.com/2021/06/28/google-trains-an-ai-vision-model-with-two-billion-parameter/
评论

来源:新智元 本文约1300字,建议阅读5分钟 视觉Transformer进阶。
参考资料:
https://arxiv.org/pdf/2106.04560.pdf
https://www.marktechpost.com/2021/06/28/google-trains-an-ai-vision-model-with-two-billion-parameter/