
一文读懂零拷贝技术|splice原理与实现
splice 原理重温
在《splice使用》一文中介绍了 splice 的原理和使用,现在我们来分析一下 splice 的代码实现。
我们先来回顾一下 splice 的原理:
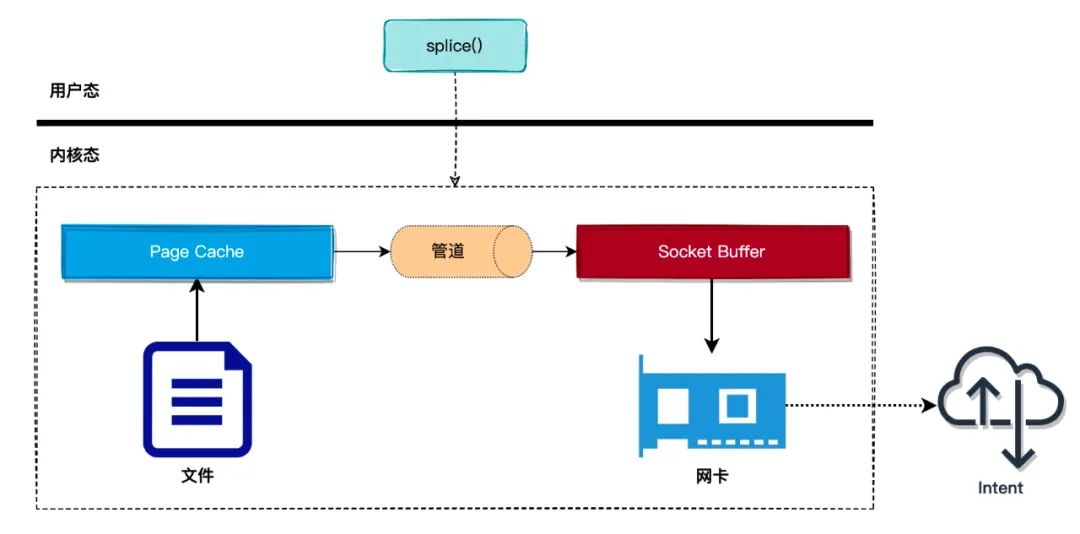
如上图所示,使用 splice 拷贝数据时,需要通过管道作为中转。splice 首先将 页缓存 绑定到 管道 的写端,然后通过 管道 的读端读取到 页缓存 的数据,并且拷贝到 socket 缓冲区中。
管道的实现可以参考:《图解 | Linux进程通信 - 管道实现》
我们在《图解 | Linux进程通信 - 管道实现》一文中介绍过,管道有个 环形缓冲区,这个 环形缓冲区 需要绑定真实的物理内存页。而 splice 就是将管道的 环形缓冲区 绑定到文件的 页缓存,如下图所示:
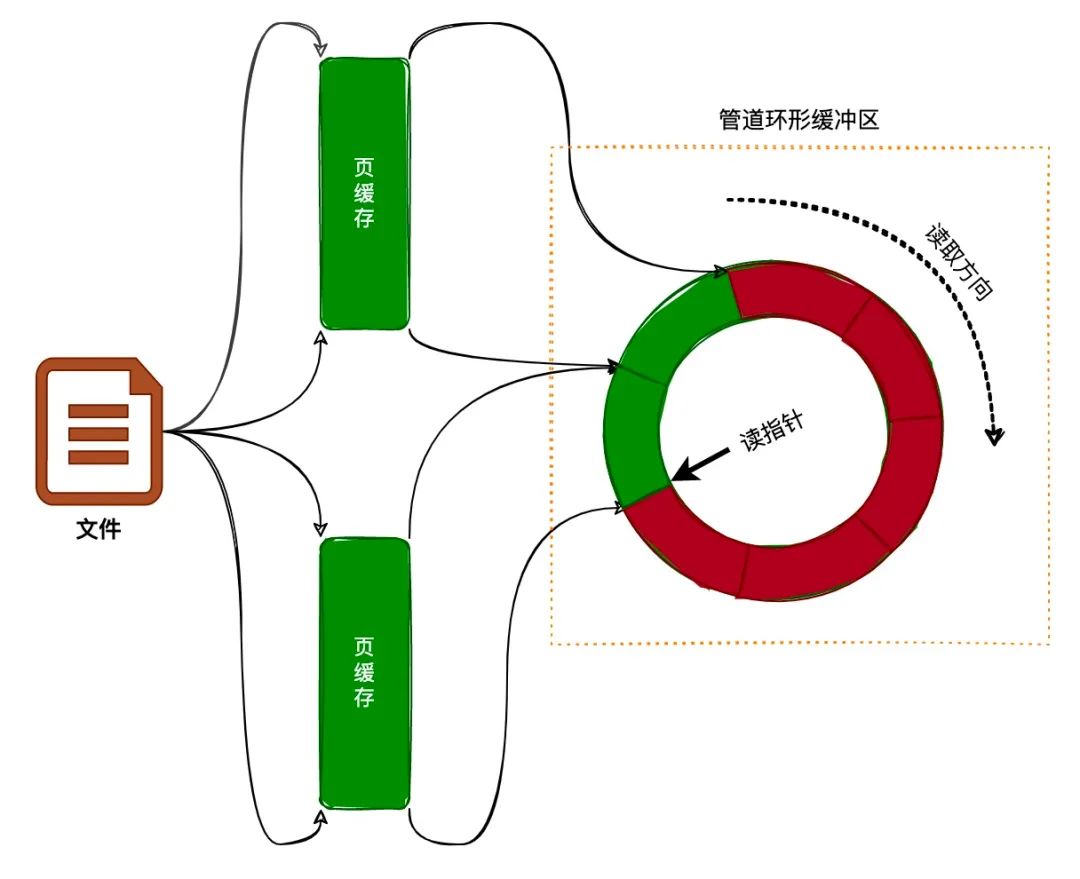
通过将文件页缓存绑定到管道的环形缓冲区后,就可以通过管道的读端读取文件页缓存的数据。
splice 代码实现
在《splice使用》一文中介绍过 splice 的使用过程,要将文件内容发送到客户端连接的步骤如下:
-
首先,使用
splice()系统调用将文件的内容与管道绑定。 -
然后,使用
splice()系统调用将管道的数据拷贝到客户端连接 socket。
我们先来看看 splice() 系统调用的实现,代码如下:
asmlinkage long
sys_splice(int fd_in, loff_t *off_in,
int fd_out, loff_t *off_out,
size_t len, unsigned int flags)
{
long error;
struct file *in, *out;
int fput_in, fput_out;
...
error = -EBADF;
in = fget_light(fd_in, &fput_in); // 1. 获取数据输入方文件对象
if (in) {
if (in->f_mode & FMODE_READ) {
out = fget_light(fd_out, &fput_out); // 2. 获取数据输出方文件对象
if (out) {
if (out->f_mode & FMODE_WRITE)
// 3. 调用 do_splice() 函数进行下一步操作
error = do_splice(in, off_in, out, off_out, len, flags);
fput_light(out, fput_out);
}
}
fput_light(in, fput_in);
}
return error;
}
splice() 系统调用主要调用 do_splice() 函数进行下一步处理,我们来分析一下 do_splice() 函数的实现。do_splice() 函数主要分两种情况进行处理,代码如下:
static long
do_splice(struct file *in, loff_t *off_in,
struct file *out, loff_t *off_out,
size_t len, unsigned int flags)
{
struct pipe_inode_info *pipe;
loff_t offset, *off;
long ret;
// 情况1: 如果输入端是一个管道?
pipe = pipe_info(in->f_path.dentry->d_inode);
if (pipe) {
...
// 调用 do_splice_from() 函数管道数据拷贝到目标文件句柄
ret = do_splice_from(pipe, out, off, len, flags);
...
return ret;
}
// 情况2: 如果输出端是一个管道?
pipe = pipe_info(out->f_path.dentry->d_inode);
if (pipe) {
...
// 调用 do_splice_to() 函数将文件内容与管道绑定
ret = do_splice_to(in, off, pipe, len, flags);
...
return ret;
}
return -EINVAL;
}
如上面代码所示,do_splice() 函数分两种情况处理,如下:
-
如果输入端是一个管道,则调用
do_splice_from()函数进行处理。 -
如果输出端是一个管道,则调用
do_splice_to()函数进行处理。
下面我们分别来说明这两种情况的处理过程。
1. 输入端是一个管道
如果输入端是一个管道(也就是说从管道拷贝数据到输出端句柄),那么将会调用 do_splice_from() 函数进行处理,do_splice_from() 函数的实现如下:
static long
do_splice_from(struct pipe_inode_info *pipe, struct file *out,
loff_t *ppos, size_t len, unsigned int flags)
{
...
return out->f_op->splice_write(pipe, out, ppos, len, flags);
}
如果输出端是一个普通文件,那么 out->f_op->splice_write() 将会指向 generic_file_splice_write() 函数。如果输出端是一个 socket,那么 out->f_op->splice_write() 将会指向 generic_splice_sendpage() 函数。
下面将以 generic_file_splice_write() 函数作为分析对象,generic_file_splice_write() 函数会调用 __splice_from_pipe() 进行下一步处理,如下所示:
ssize_t
generic_file_splice_write(struct pipe_inode_info *pipe, struct file *out,
loff_t *ppos, size_t len, unsigned int flags)
{
...
ret = __splice_from_pipe(pipe, &sd, pipe_to_file);
...
return ret;
}
我们接着来分析 __splice_from_pipe() 函数的实现:
ssize_t
__splice_from_pipe(struct pipe_inode_info *pipe, struct splice_desc *sd,
splice_actor *actor)
{
...
for (;;) {
if (pipe->nrbufs) {
// 1. 获取管道环形缓冲区
struct pipe_buffer *buf = pipe->bufs + pipe->curbuf;
const struct pipe_buf_operations *ops = buf->ops;
...
// 2. 把管道环形缓冲区的数据拷贝到输出端文件。
// 其中 actor 指针指向 pipe_to_file() 函数,由 generic_file_splice_write() 函数传入
err = actor(pipe, buf, sd);
if (err <= 0) {
if (!ret && err != -ENODATA)
ret = err;
break;
}
...
}
...
}
...
return ret;
}
对 __splice_from_pipe() 函数进行简化后,逻辑就很简单。主要过程如下:
- 获取管道环形缓冲区(管道的实现可以参考《图解 | Linux进程通信 - 管道实现》一文)。
-
调用
pipe_to_file()函数把管道环形缓冲区的数据拷贝到输出端的文件中。
所以,输入端是一个管道的调用链如下:
sys_splice()
└→ do_splice()
└→ do_splice_from()
└→ generic_file_splice_write()
└→ __splice_from_pipe()
└→ pipe_to_file()
2. 输出端是一个管道
如果输出端是一个管道(也就是说将输入端与管道绑定),那么将会调用 do_splice_to() 函数进行处理,do_splice_to() 函数的实现如下:
static long
do_splice_to(struct file *in, loff_t *ppos, struct pipe_inode_info *pipe,
size_t len, unsigned int flags)
{
...
return in->f_op->splice_read(in, ppos, pipe, len, flags);
}
如果输入端是一个普通文件,那么 in->f_op->splice_read() 将会指向 generic_file_splice_read() 函数。如果输出端是一个 socket,那么 in->f_op->splice_read() 将会指向 sock_splice_read() 函数。
下面将以 generic_file_splice_read() 函数作为分析对象,generic_file_splice_read() 函数会调用 __generic_file_splice_read() 进行下一步处理,如下所示:
static int
__generic_file_splice_read(struct file *in, loff_t *ppos,
struct pipe_inode_info *pipe,
size_t len, unsigned int flags)
{
...
struct page *pages[PIPE_BUFFERS];
struct splice_pipe_desc spd = {
.pages = pages,
...
};
...
// 1. 查找已经存在页缓存的页面
spd.nr_pages = find_get_pages_contig(mapping, index, nr_pages, pages);
index += spd.nr_pages;
...
// 2. 如果有些页缓存还不存在,那么申请新的页缓存
while (spd.nr_pages < nr_pages) {
page = find_get_page(mapping, index);
...
pages[spd.nr_pages++] = page;
index++;
}
// 3. 如果页缓存与硬盘的数据不一致,那么先从硬盘同步到页缓存
for (page_nr = 0; page_nr < nr_pages; page_nr++) {
...
page = pages[page_nr];
...
if (!PageUptodate(page)) {
...
error = mapping->a_ops->readpage(in, page); // 从硬盘读取数据
...
}
...
spd.nr_pages++;
index++;
}
...
// 4. 将页缓存与管道绑定
if (spd.nr_pages)
return splice_to_pipe(pipe, &spd);
return error;
}
__generic_file_splice_read() 函数的代码比较长,为了更易于分析,所以对其进行了精简。从精简后的代码可以看出,__generic_file_splice_read() 函数主要完成 4 个步骤:
- 查找要绑定的页缓存是否已经存在(已经从硬盘同步到页缓存)。
- 如果还有没有同步到内核的页缓存,那么申请新的页缓存。
- 如果页缓存与硬盘的数据不一致,那么先从硬盘同步到页缓存。
-
调用
splice_to_pipe()函数将页缓存与管道绑定。
所以最终会调用 splice_to_pipe() 函数将页缓存与管道绑定,我们来看看 splice_to_pipe() 函数的实现:
ssize_t
splice_to_pipe(struct pipe_inode_info *pipe, struct splice_pipe_desc *spd)
{
unsigned int spd_pages = spd->nr_pages;
int ret, do_wakeup, page_nr;
...
for (;;) {
...
if (pipe->nrbufs < PIPE_BUFFERS) {
// 指向管道环形缓冲区当前位置
int newbuf = (pipe->curbuf + pipe->nrbufs) & (PIPE_BUFFERS - 1);
struct pipe_buffer *buf = pipe->bufs + newbuf;
// 将环形缓冲区与页缓存绑定
buf->page = spd->pages[page_nr];
buf->offset = spd->partial[page_nr].offset;
buf->len = spd->partial[page_nr].len;
buf->private = spd->partial[page_nr].private;
buf->ops = spd->ops;
if (spd->flags & SPLICE_F_GIFT)
buf->flags |= PIPE_BUF_FLAG_GIFT;
pipe->nrbufs++;
page_nr++;
ret += buf->len;
...
if (pipe->nrbufs < PIPE_BUFFERS)
continue;
break;
}
...
}
...
return ret;
}
splice_to_pipe() 函数代码虽然比较长,但是逻辑很简单,就是将管道的环形缓冲区与文件的页缓存进行绑定,这样就能过通过管道的读端来读取页缓存的数据。
所以,输出端是一个管道的调用链如下:
sys_splice()
└→ do_splice()
└→ do_splice_to()
└→ generic_file_splice_read()
└→ __generic_file_splice_read()
└→ splice_to_pipe()
总结
本文主要介绍了 splice 的原理与实现,splice 是 零拷贝技术 的一种实现。希望通过本文,能够让读者对 零拷贝技术 有更深入的理解。
当然本文也忽略了很多实现的细节,所以在阅读的过程中遇到某些细节不理解的时候,可以直接阅读源代码来解疑。