
ECCV 2020 Oral 中谷歌论文盘点,点云与3D方向工作居多
共 3536字,需浏览 8分钟
·
2020-09-06 06:49
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
最佳论文荣誉提名
[2].Quaternion Equivariant Capsule Networks for 3D Point Clouds
作者 | Yongheng Zhao, Tolga Birdal, Jan Eric Lenssen, Emanuele Menegatti, Leonidas Guibas, Federico Tombari
单位 | 帕多瓦大学;斯坦福大学;慕尼黑工业大学;多特蒙德工业大学;谷歌
论文 | https://arxiv.org/abs/1912.12098
代码 | https://github.com/tolgabirdal/qecnetworks
主页 | https://tolgabirdal.github.io/qecnetworks/
备注 | ECCV 2020 Oral
发明了新的3D胶囊网络,用于3D识别与方向估计。
[3].SoftPoolNet: Shape Descriptor for Point Cloud Completion and Classification
作者 | Yida Wang, David Joseph Tan, Nassir Navab, Federico Tombari
单位 | Technische Universit¨at M¨unchen;谷歌
论文 | https://arxiv.org/abs/2008.07358
备注 | ECCV 2020 Oral
发明了新的用于点云的形状描述,用于点云补全和分类。
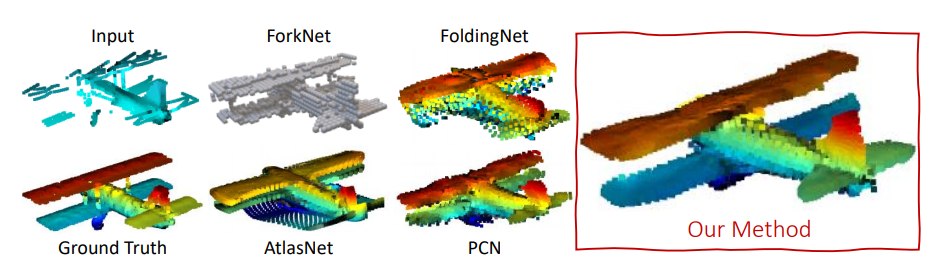
[4].Combining Implicit Function Learning and Parametric Models for 3D Human Reconstruction
作者 | Bharat Lal Bhatnagar, Cristian Sminchisescu, Christian Theobalt, Gerard Pons-Moll
单位 | 萨尔大学;谷歌
论文 | https://arxiv.org/abs/2007.11432
代码 | https://github.com/bharat-b7/IPNet
主页 | http://virtualhumans.mpi-inf.mpg.de/ipnet/
备注 | ECCV 2020 Oral
结合隐式函数与参数模型的3D人体重建。

[5].CoReNet: Coherent 3D scene reconstruction from a single RGB image
作者 | Stefan Popov, Pablo Bauszat, Vittorio Ferrari
单位 | 谷歌
论文 | https://arxiv.org/abs/2004.12989
备注 | ECCV 2020 Oral
从单幅图片进行连贯的3D场景重建。

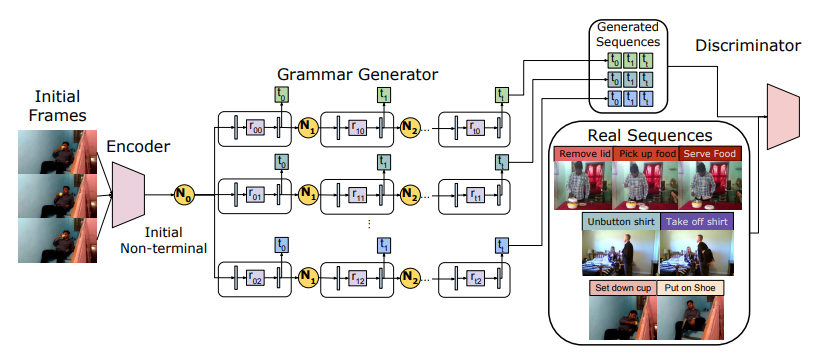
[6].Adversarial Generative Grammars for Human Activity Prediction
作者 | AJ Piergiovanni, Anelia Angelova, Alexander Toshev, Michael S. Ryoo
单位 | 谷歌;石溪大学
论文 | https://arxiv.org/abs/2008.04888
代码 | 即将
备注 | ECCV 2020 Oral
对抗生成语法用于人类活动预测。
[7].Self6D: Self-Supervised Monocular 6D Object Pose Estimation
作者 | Gu Wang, Fabian Manhardt, Jianzhun Shao, Xiangyang Ji, Nassir Navab, Federico Tombari
单位 | 清华大学;慕尼黑工业大学;谷歌
论文 | https://arxiv.org/abs/2004.06468
代码 | https://github.com/THU-DA-6D-Pose-Group/Self6D-Diff-Renderer
备注 | ECCV 2020 Oral
自监督学习+单目6D位姿估计。
[8].What Matters in Unsupervised Optical Flow?
作者 | Rico Jonschkowski, Austin Stone, Jonathan T. Barron, Ariel Gordon, Kurt Konolige, Anelia Angelova
单位 | 谷歌
论文 | https://arxiv.org/abs/2006.04902
代码 | https://github.com/google-research/google-research/tree/master/uflow
备注 | ECCV 2020 Oral
非监督光流估计研究。
[9].Appearance Consensus Driven Self-Supervised Human Mesh Recovery
作者 | Jogendra Nath Kundu, Mugalodi Rakesh, Varun Jampani, Rahul Mysore Venkatesh, R. Venkatesh Babu
单位 | Indian Institute of Science, Bangalore;谷歌
论文 | https://arxiv.org/abs/2008.01341
代码 | 即将
主页 | https://sites.google.com/view/ss-human-mesh
备注 | ECCV 2020 Oral
表观共识驱动的自监督人体网格修复。
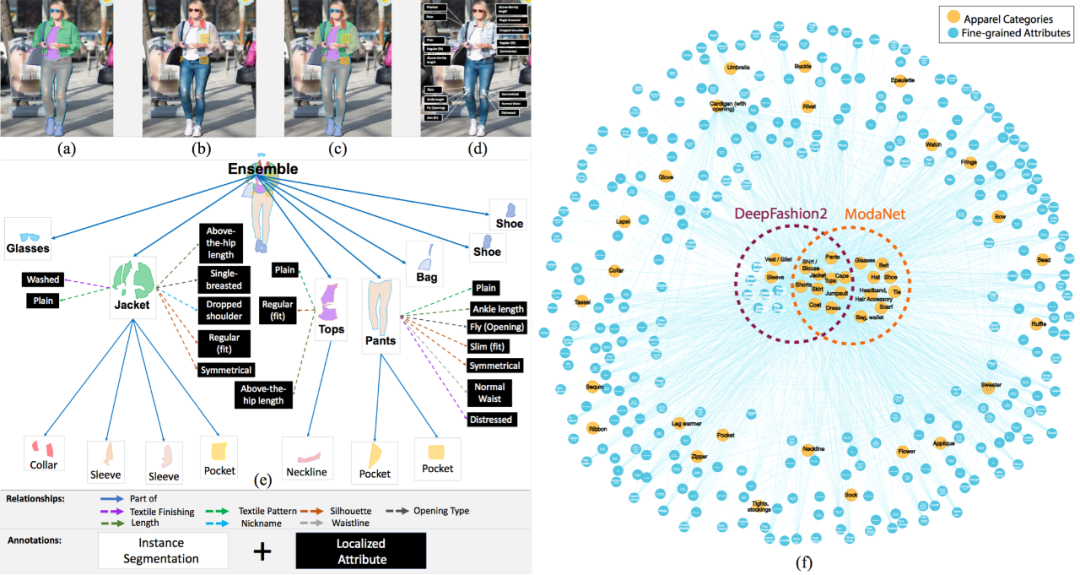
[10].Fashionpedia: Ontology, Segmentation, and an Attribute Localization Dataset
作者 | Menglin Jia, Mengyun Shi, Mikhail Sirotenko, Yin Cui, Claire Cardie, Bharath Hariharan, Hartwig Adam, Serge Belongie
单位 | 康奈尔大学;康奈尔科技校区;谷歌等
论文 | https://arxiv.org/abs/2004.12276
主页 | https://fashionpedia.github.io/home/index.html
备注 | ECCV 2020 Oral
定义了一个实例分割与细粒度属性定位的视觉新任务,并提出一个时尚领域的数据集。
你觉得哪项工作最有意思呢,欢迎留言~