
强大易用!新一代爬虫利器 Playwright 的介绍
Playwright 是微软在 2020 年初开源的新一代自动化测试工具,它的功能类似于 Selenium、Pyppeteer 等,都可以驱动浏览器进行各种自动化操作。它的功能也非常强大,对市面上的主流浏览器都提供了支持,API 功能简洁又强大。虽然诞生比较晚,但是现在发展得非常火热。
因为 Playwright 是一个类似 Selenium 一样可以支持网页页面渲染的工具,再加上其强大又简洁的 API,Playwright 同时也可以作为网络爬虫的一个爬取利器。

1. Playwright 的特点
- Playwright 支持当前所有主流浏览器,包括 Chrome 和 Edge(基于 Chromium)、Firefox、Safari(基于 WebKit) ,提供完善的自动化控制的 API。
- Playwright 支持移动端页面测试,使用设备模拟技术可以使我们在移动 Web 浏览器中测试响应式 Web 应用程序。
- Playwright 支持所有浏览器的 Headless 模式和非 Headless 模式的测试。
- Playwright 的安装和配置非常简单,安装过程中会自动安装对应的浏览器和驱动,不需要额外配置 WebDriver 等。
- Playwright 提供了自动等待相关的 API,当页面加载的时候会自动等待对应的节点加载,大大简化了 API 编写复杂度。
本节我们就来了解下 Playwright 的使用方法。
2. 安装
Playwright 目前提供了 Python 和 Node.js 的 API,下面我们针对 Python 版的 Playwright 进行介绍。
要使用 Playwright,需要 Python 3.7 版本及以上,请确保 Python 的版本符合要求。
要安装 Playwright,可以直接使用 pip3,命令如下:
pip3 install playwright
安装完成之后需要进行一些初始化操作:
playwright install
这时候 Playwrigth 会安装 Chromium, Firefox and WebKit 浏览器并配置一些驱动,我们不必关心中间配置的过程,Playwright 会为我们配置好。
具体的安装说明可以参考:https://setup.scrape.center/playwright。
安装完成之后,我们便可以使用 Playwright 启动 Chromium 或 Firefox 或 WebKit 浏览器来进行自动化操作了。
3. 基本使用
Playwright 支持两种编写模式,一种是类似 Pyppetter 一样的异步模式,另一种是像 Selenium 一样的同步模式,我们可以根据实际需要选择使用不同的模式。
我们先来看一个基本同步模式的例子:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
for browser_type in [p.chromium, p.firefox, p.webkit]:
browser = browser_type.launch(headless=False)
page = browser.new_page()
page.goto('https://www.baidu.com')
page.screenshot(path=f'screenshot-{browser_type.name}.png')
print(page.title())
browser.close()
首先我们导入了 sync_playwright 方法,然后直接调用了这个方法,该方法返回的是一个 PlaywrightContextManager 对象,可以理解是一个浏览器上下文管理器,我们将其赋值为变量 p。
接着我们调用了 PlaywrightContextManager 对象的 chromium、firefox、webkit 属性依次创建了一个 Chromium、Firefox 以及 Webkit 浏览器实例,接着用一个 for 循环依次执行了它们的 launch 方法,同时设置了 headless 参数为 False。
“注意:如果不设置为 False,默认是无头模式启动浏览器,我们看不到任何窗口。
”
launch 方法返回的是一个 Browser 对象,我们将其赋值为 browser 变量。然后调用 browser 的 new_page 方法,相当于新建了一个选项卡,返回的是一个 Page 对象,将其赋值为 page,这整个过程其实和 Pyppeteer 非常类似。接着我们就可以调用 page 的一系列 API 来进行各种自动化操作了,比如调用 goto,就是加载某个页面,这里我们访问的是百度的首页。接着我们调用了 page 的 screenshot 方法,参数传一个文件名称,这样截图就会自动保存为该图片名称,这里名称中我们加入了 browser_type 的 name 属性,代表浏览器的类型,结果分别就是 chromium, firefox, webkit。另外我们还调用了 title 方法,该方法会返回页面的标题,即 HTML 中 title 节点中的文字,也就是选项卡上的文字,我们将该结果打印输出到控制台。最后操作完毕,调用 browser 的 close 方法关闭整个浏览器,运行结束。
运行一下,这时候我们可以看到有三个浏览器依次启动并加载了百度这个页面,分别是 Chromium、Firefox 和 Webkit 三个浏览器,页面加载完成之后,生成截图、控制台打印结果就退出了。
这时候当前目录便会生成三个截图文件,都是百度的首页,文件名中都带有了浏览器的名称,如图所示:

控制台运行结果如下:
百度一下,你就知道
百度一下,你就知道
百度一下,你就知道
通过运行结果我们可以发现,我们非常方便地启动了三种浏览器并完成了自动化操作,并通过几个 API 就完成了截图和数据的获取,整个运行速度是非常快的,者就是 Playwright 最最基本的用法。
当然除了同步模式,Playwright 还提供异步的 API,如果我们项目里面使用了 asyncio,那就应该使用异步模式,写法如下:
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as p:
for browser_type in [p.chromium, p.firefox, p.webkit]:
browser = await browser_type.launch()
page = await browser.new_page()
await page.goto('https://www.baidu.com')
await page.screenshot(path=f'screenshot-{browser_type.name}.png')
print(await page.title())
await browser.close()
asyncio.run(main())
可以看到整个写法和同步模式基本类似,导入的时候使用的是 async_playwright 方法,而不再是 sync_playwright 方法。写法上添加了 async/await 关键字的使用,最后的运行效果是一样的。
另外我们注意到,这例子中使用了 with as 语句,with 用于上下文对象的管理,它可以返回一个上下文管理器,也就对应一个 PlaywrightContextManager 对象,无论运行期间是否抛出异常,它能够帮助我们自动分配并且释放 Playwright 的资源。
4. 代码生成
Playwright 还有一个强大的功能,那就是可以录制我们在浏览器中的操作并将代码自动生成出来,有了这个功能,我们甚至都不用写任何一行代码,这个功能可以通过 playwright 命令行调用 codegen 来实现,我们先来看看 codegen 命令都有什么参数,输入如下命令:
playwright codegen --help
结果类似如下:
Usage: npx playwright codegen [options] [url]
open page and generate code for user actions
Options:
-o, --output saves the generated script to a file
--target language to use, one of javascript, python, python-async, csharp (default: "python")
-b, --browser browser to use, one of cr, chromium, ff, firefox, wk, webkit (default: "chromium")
--channel Chromium distribution channel, "chrome", "chrome-beta", "msedge-dev", etc
--color-scheme emulate preferred color scheme, "light" or "dark"
--device emulate device, for example "iPhone 11"
--geolocation specify geolocation coordinates, for example "37.819722,-122.478611"
--load-storage load context storage state from the file, previously saved with --save-storage
--lang specify language / locale, for example "en-GB"
--proxy-server specify proxy server, for example "http://myproxy:3128" or "socks5://myproxy:8080"
--save-storage save context storage state at the end, for later use with --load-storage
--timezone time zone to emulate, for example "Europe/Rome"
--timeout timeout for Playwright actions in milliseconds (default: "10000")
--user-agent specify user agent string
--viewport-size specify browser viewport size in pixels, for example "1280, 720"
-h, --help display help for command
Examples:
$ codegen
$ codegen --target=python
$ codegen -b webkit https://example.com
可以看到这里有几个选项,比如 -o 代表输出的代码文件的名称;--target 代表使用的语言,默认是 python,即会生成同步模式的操作代码,如果传入 python-async 就会生成异步模式的代码;-b 代表的是使用的浏览器,默认是 Chromium,其他还有很多设置,比如 --device 可以模拟使用手机浏览器,比如 iPhone 11,--lang 代表设置浏览器的语言,--timeout 可以设置页面加载超时时间。
好,了解了这些用法,那我们就来尝试启动一个 Firefox 浏览器,然后将操作结果输出到 script.py 文件,命令如下:
playwright codegen -o script.py -b firefox
这时候就弹出了一个 Firefox 浏览器,同时右侧会输出一个脚本窗口,实时显示当前操作对应的代码。
我们可以在浏览器中做任何操作,比如打开百度,然后点击输入框并输入 nba,然后再点击搜索按钮,浏览器窗口如下:
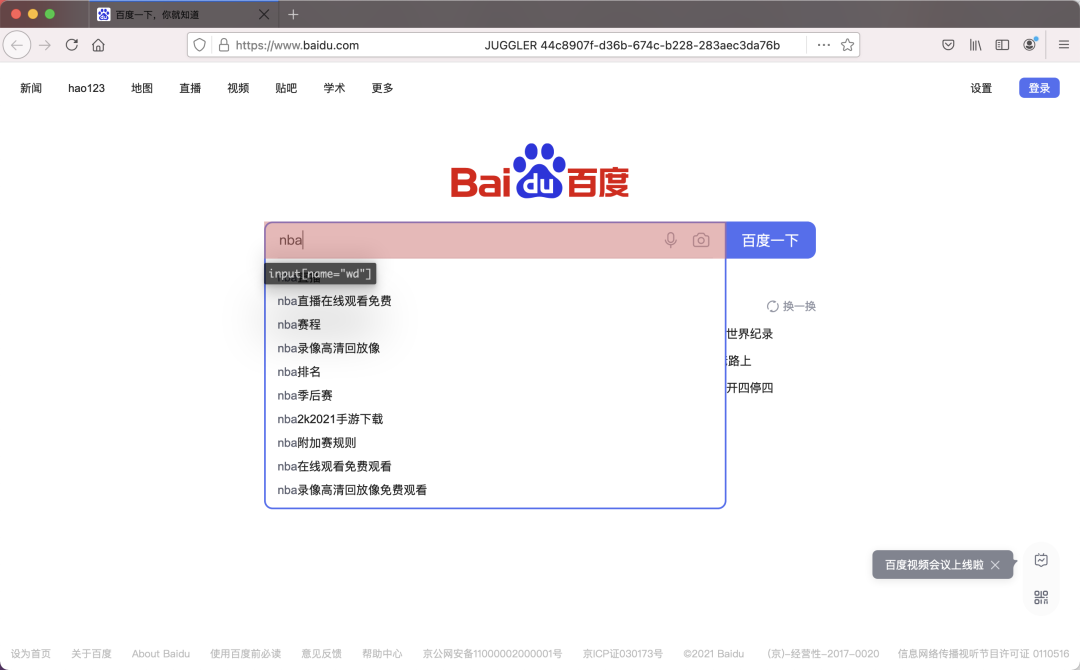
可以看见浏览器中还会高亮显示我们正在操作的页面节点,同时还显示了对应的选择器字符串input[name="wd"],右侧的窗口如图所示:
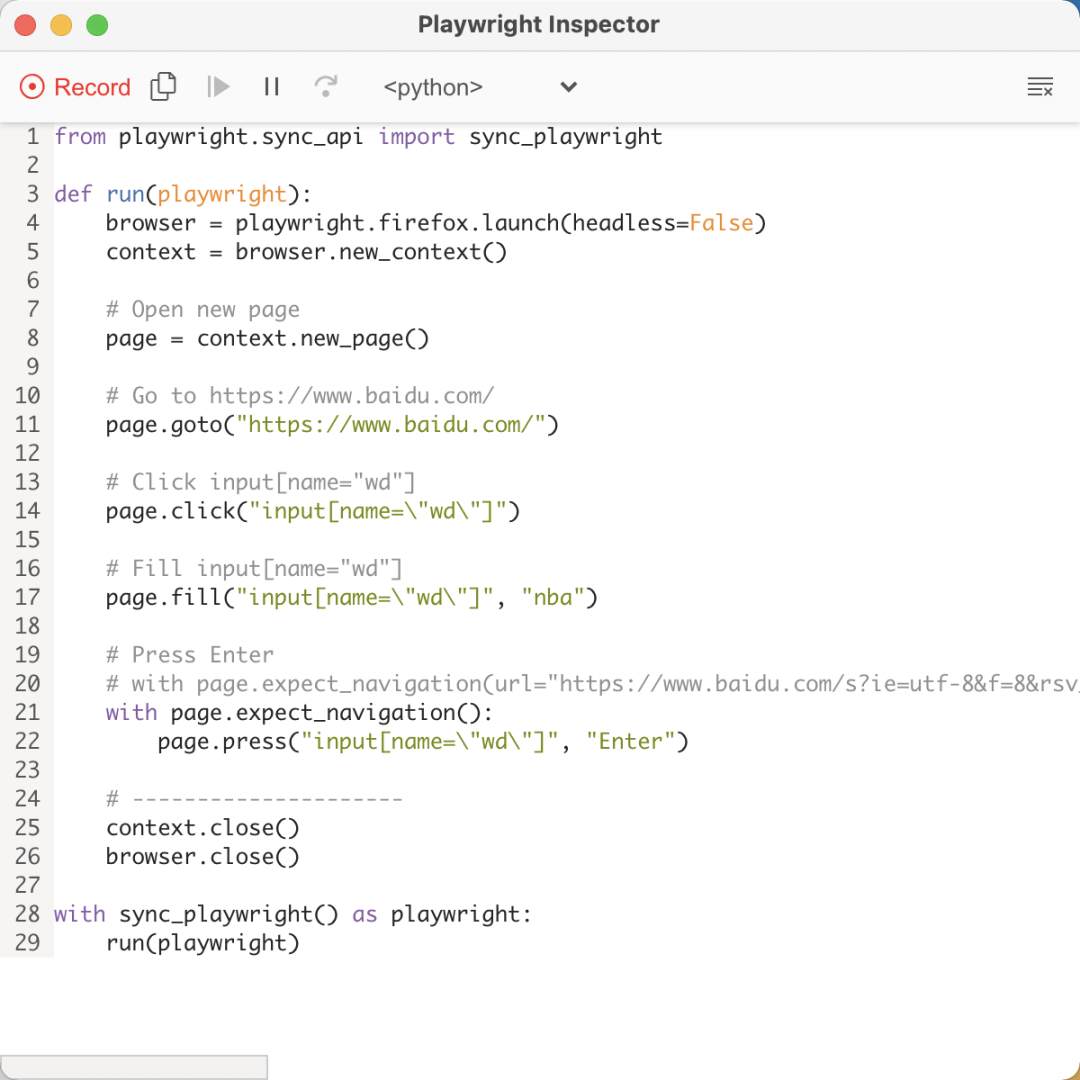
在操作过程中,该窗口中的代码就实时变化,可以看到这里生成了我们一系列操作的对应代码,比如在搜索框中输入 nba,就对应如下代码:
page.fill("input[name=\"wd\"]", "nba")
操作完毕之后,关闭浏览器,Playwright 会生成一个 script.py 文件,内容如下:
from playwright.sync_api import sync_playwright
def run(playwright):
browser = playwright.firefox.launch(headless=False)
context = browser.new_context()
# Open new page
page = context.new_page()
# Go to https://www.baidu.com/
page.goto("https://www.baidu.com/")
# Click input[name="wd"]
page.click("input[name=\"wd\"]")
# Fill input[name="wd"]
page.fill("input[name=\"wd\"]", "nba")
# Click text=百度一下
with page.expect_navigation():
page.click("text=百度一下")
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
可以看到这里生成的代码和我们之前写的示例代码几乎差不多,而且也是完全可以运行的,运行之后就可以看到它又可以复现我们刚才所做的操作了。
所以,有了这个功能,我们甚至都不用编写任何代码,只通过简单的可视化点击就能把代码生成出来,可谓是非常方便了!
另外这里有一个值得注意的点,仔细观察下生成的代码,和前面的例子不同的是,这里 new_page 方法并不是直接通过 browser 调用的,而是通过 context 变量调用的,这个 context 又是由 browser 通过调用 new_context 方法生成的。有读者可能就会问了,这个 context 究竟是做什么的呢?
其实这个 context 变量对应的是一个 BrowserContext 对象,BrowserContext 是一个类似隐身模式的独立上下文环境,其运行资源是单独隔离的,在做一些自动化测试过程中,每个测试用例我们都可以单独创建一个 BrowserContext 对象,这样可以保证每个测试用例之间互不干扰,具体的 API 可以参考https://playwright.dev/python/docs/api/class-browsercontext。
5. 移动端浏览器支持
Playwright 另外一个特色功能就是可以支持移动端浏览器的模拟,比如模拟打开 iPhone 12 Pro Max 上的 Safari 浏览器,然后手动设置定位,并打开百度地图并截图。首先我们可以选定一个经纬度,比如故宫的经纬度是 39.913904, 116.39014,我们可以通过 geolocation 参数传递给 Webkit 浏览器并初始化。
示例代码如下:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
iphone_12_pro_max = p.devices['iPhone 12 Pro Max']
browser = p.webkit.launch(headless=False)
context = browser.new_context(
**iphone_12_pro_max,
locale='zh-CN',
geolocation={'longitude': 116.39014, 'latitude': 39.913904},
permissions=['geolocation']
)
page = context.new_page()
page.goto('https://amap.com')
page.wait_for_load_state(state='networkidle')
page.screenshot(path='location-iphone.png')
browser.close()
这里我们先用 PlaywrightContextManager 对象的 devices 属性指定了一台移动设备,这里传入的是手机的型号,比如 iPhone 12 Pro Max,当然也可以传其他名称,比如 iPhone 8,Pixel 2 等。
前面我们已经了解了 BrowserContext 对象,BrowserContext 对象也可以用来模拟移动端浏览器,初始化一些移动设备信息、语言、权限、位置等信息,这里我们就用它来创建了一个移动端 BrowserContext 对象,通过 geolocation 参数传入了经纬度信息,通过 permissions 参数传入了赋予的权限信息,最后将得到的 BrowserContext 对象赋值为 context 变量。
接着我们就可以用 BrowserContext 对象来新建一个页面,还是调用 new_page 方法创建一个新的选项卡,然后跳转到高德地图,并调用了 wait_for_load_state 方法等待页面某个状态完成,这里我们传入的 state 是 networkidle,也就是网络空闲状态。因为在页面初始化和加载过程中,肯定是伴随有网络请求的,所以加载过程中肯定不算 networkidle 状态,所以这里我们传入 networkidle 就可以标识当前页面和数据加载完成的状态。加载完成之后,我们再调用 screenshot 方法获取当前页面截图,最后关闭浏览器。
运行下代码,可以发现这里就弹出了一个移动版浏览器,然后加载了高德地图,并定位到了故宫的位置,如图所示:
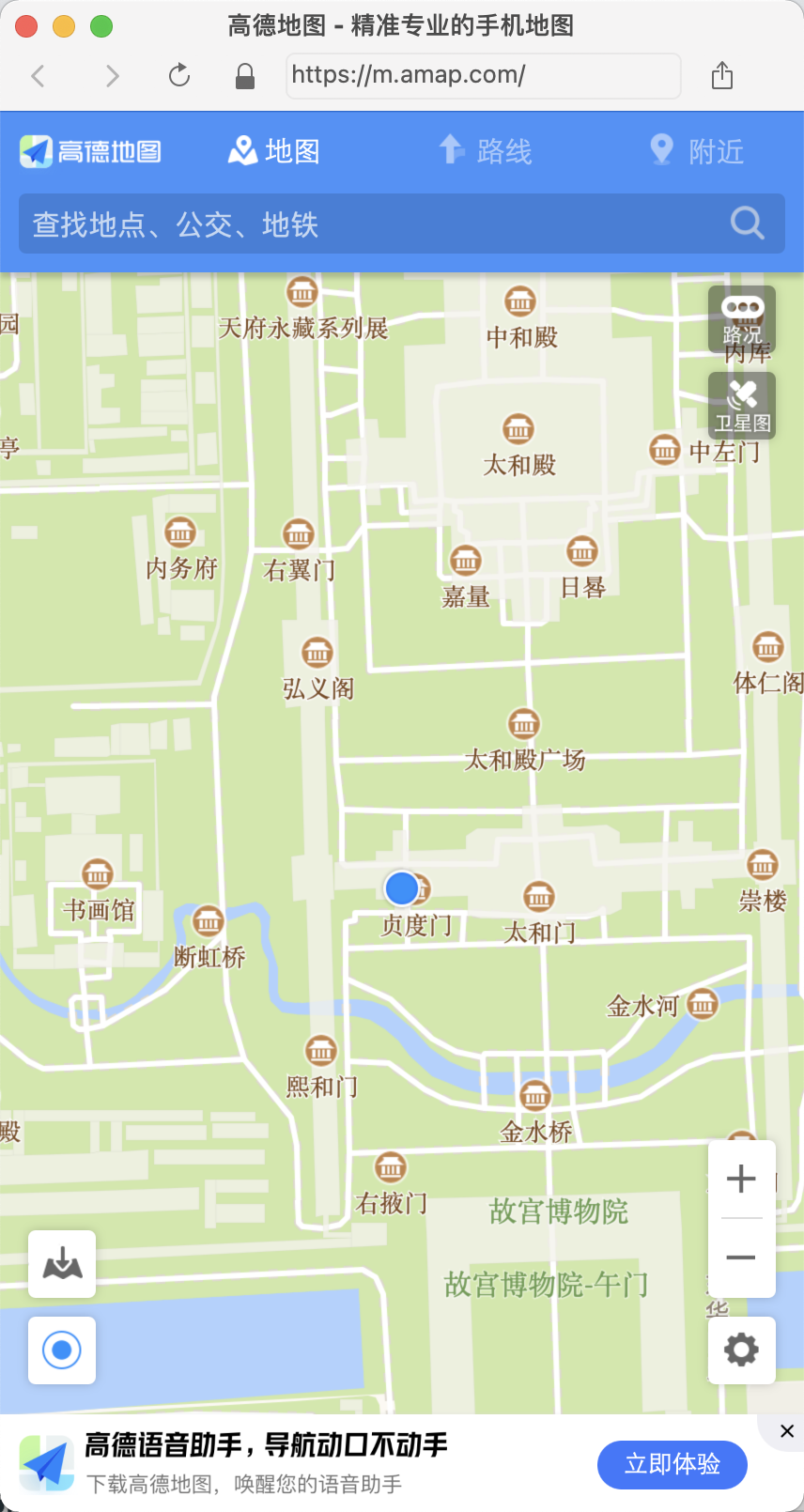
输出的截图也是浏览器中显示的结果。
所以这样我们就成功实现了移动端浏览器的模拟和一些设置,其操作 API 和 PC 版浏览器是完全一样的。
6. 选择器
前面我们注意到 click 和 fill 等方法都传入了一个字符串,这些字符串有的符合 CSS 选择器的语法,有的又是 text= 开头的,感觉似乎没太有规律的样子,它到底支持怎样的匹配规则呢?下面我们来了解下。
传入的这个字符串,我们可以称之为 Element Selector,它不仅仅支持 CSS 选择器、XPath,Playwright 还扩展了一些方便好用的规则,比如直接根据文本内容筛选,根据节点层级结构筛选等等。
文本选择
文本选择支持直接使用text=这样的语法进行筛选,示例如下:
page.click("text=Log in")
这就代表选择文本是 Log in 的节点,并点击。
CSS 选择器
CSS 选择器之前也介绍过了,比如根据 id 或者 class 筛选:
page.click("button")
page.click("#nav-bar .contact-us-item")
根据特定的节点属性筛选:
page.click("[data-test=login-button]")
page.click("[aria-label='Sign in']")
CSS 选择器 + 文本
我们还可以使用 CSS 选择器结合文本值进行海选,比较常用的就是 has-text 和 text,前者代表包含指定的字符串,后者代表字符串完全匹配,示例如下:
page.click("article:has-text('Playwright')")
page.click("#nav-bar :text('Contact us')")
第一个就是选择文本中包含 Playwright 的 article 节点,第二个就是选择 id 为 nav-bar 节点中文本值等于 Contact us 的节点。
CSS 选择器 + 节点关系
还可以结合节点关系来筛选节点,比如使用 has 来指定另外一个选择器,示例如下:
page.click(".item-description:has(.item-promo-banner)")
比如这里选择的就是选择 class 为 item-description 的节点,且该节点还要包含 class 为 item-promo-banner 的子节点。
另外还有一些相对位置关系,比如 right-of 可以指定位于某个节点右侧的节点,示例如下:
page.click("input:right-of(:text('Username'))")
这里选择的就是一个 input 节点,并且该 input 节点要位于文本值为 Username 的节点的右侧。
XPath
当然 XPath 也是支持的,不过 xpath 这个关键字需要我们自行制定,示例如下:
page.click("xpath=//button")
这里需要在开头指定xpath=字符串,代表后面是一个 XPath 表达式。
关于更多选择器的用法和最佳实践,可以参考官方文档:https://playwright.dev/python/docs/selectors。
7. 常用操作方法
上面我们了解了浏览器的一些初始化设置和基本的操作实例,下面我们再对一些常用的操作 API 进行说明。
常见的一些 API 如点击 click,输入 fill 等操作,这些方法都是属于 Page 对象的,所以所有的方法都从 Page 对象的 API 文档查找就好了,文档地址:https://playwright.dev/python/docs/api/class-page。
下面介绍几个常见的 API 用法。
事件监听
Page 对象提供了一个 on 方法,它可以用来监听页面中发生的各个事件,比如 close、console、load、request、response 等等。
比如这里我们可以监听 response 事件,response 事件可以在每次网络请求得到响应的时候触发,我们可以设置对应的回调方法获取到对应 Response 的全部信息,示例如下:
from playwright.sync_api import sync_playwright
def on_response(response):
print(f'Statue {response.status}: {response.url}')
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.on('response', on_response)
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
browser.close()
这里我们在创建 Page 对象之后,就开始监听 response 事件,同时将回调方法设置为 on_response,on_response 对象接收一个参数,然后把 Response 的状态码和链接都输出出来了。
运行之后,可以看到控制台输出结果如下:
Statue 200: https://spa6.scrape.center/
Statue 200: https://spa6.scrape.center/css/app.ea9d802a.css
Statue 200: https://spa6.scrape.center/js/app.5ef0d454.js
Statue 200: https://spa6.scrape.center/js/chunk-vendors.77daf991.js
Statue 200: https://spa6.scrape.center/css/chunk-19c920f8.2a6496e0.css
...
Statue 200: https://spa6.scrape.center/css/chunk-19c920f8.2a6496e0.css
Statue 200: https://spa6.scrape.center/js/chunk-19c920f8.c3a1129d.js
Statue 200: https://spa6.scrape.center/img/logo.a508a8f0.png
Statue 200: https://spa6.scrape.center/fonts/element-icons.535877f5.woff
Statue 301: https://spa6.scrape.center/api/movie?limit=10&offset=0&token=NGMwMzFhNGEzMTFiMzJkOGE0ZTQ1YjUzMTc2OWNiYTI1Yzk0ZDM3MSwxNjIyOTE4NTE5
Statue 200: https://spa6.scrape.center/api/movie/?limit=10&offset=0&token=NGMwMzFhNGEzMTFiMzJkOGE0ZTQ1YjUzMTc2OWNiYTI1Yzk0ZDM3MSwxNjIyOTE4NTE5
Statue 200: https://p0.meituan.net/movie/da64660f82b98cdc1b8a3804e69609e041108.jpg@464w_644h_1e_1c
Statue 200: https://p0.meituan.net/movie/283292171619cdfd5b240c8fd093f1eb255670.jpg@464w_644h_1e_1c
....
Statue 200: https://p1.meituan.net/movie/b607fba7513e7f15eab170aac1e1400d878112.jpg@464w_644h_1e_1c
“注意:这里省略了部分重复的内容。
”
可以看到,这里的输出结果其实正好对应浏览器 Network 面板中所有的请求和响应内容,和下图是一一对应的:
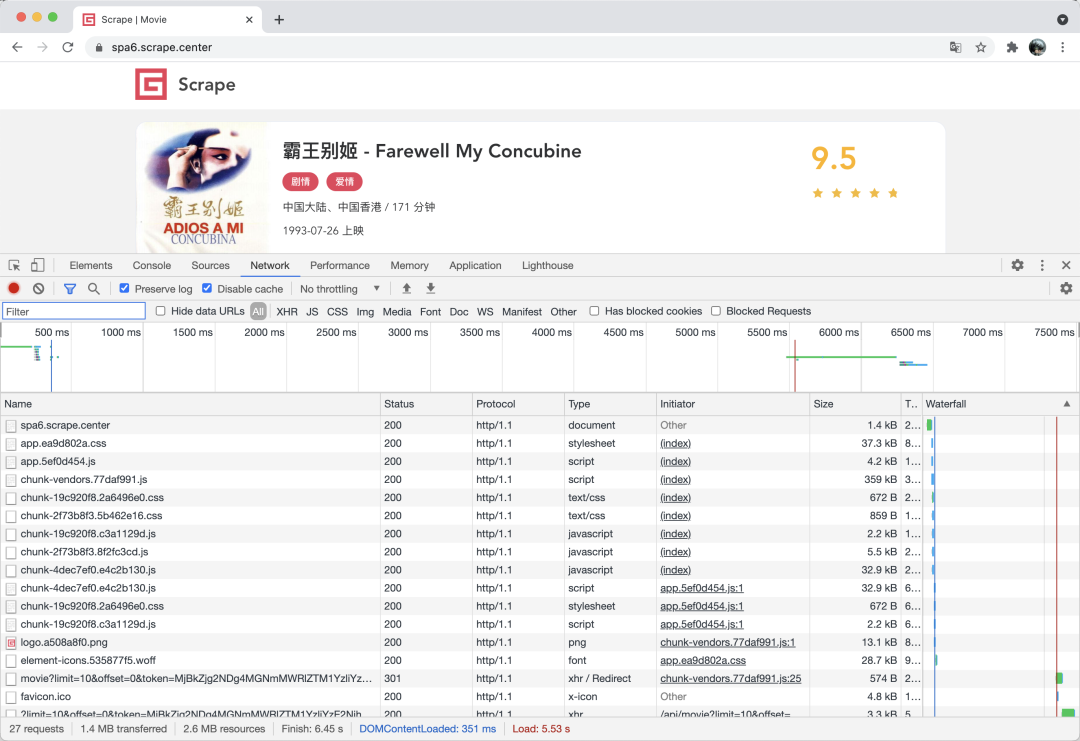
这个网站我们之前分析过,其真实的数据都是 Ajax 加载的,同时 Ajax 请求中还带有加密参数,不好轻易获取。
但有了这个方法,这里如果我们想要截获 Ajax 请求,岂不是就非常容易了?
改写一下判定条件,输出对应的 JSON 结果,改写如下:
from playwright.sync_api import sync_playwright
def on_response(response):
if '/api/movie/' in response.url and response.status == 200:
print(response.json())
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.on('response', on_response)
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
browser.close()
控制台输入如下:
{'count': 100, 'results': [{'id': 1, 'name': '霸王别姬', 'alias': 'Farewell My Concubine', 'cover': 'https://p0.meituan.net/movie/ce4da3e03e655b5b88ed31b5cd7896cf62472.jpg@464w_644h_1e_1c', 'categories': ['剧情', '爱情'], 'published_at': '1993-07-26', 'minute': 171, 'score': 9.5, 'regions': ['中国大陆', '中国香港']},
...
'published_at': None, 'minute': 103, 'score': 9.0, 'regions': ['美国']}, {'id': 10, 'name': '狮子王', 'alias': 'The Lion King', 'cover': 'https://p0.meituan.net/movie/27b76fe6cf3903f3d74963f70786001e1438406.jpg@464w_644h_1e_1c', 'categories': ['动画', '歌舞', '冒险'], 'published_at': '1995-07-15', 'minute': 89, 'score': 9.0, 'regions': ['美国']}]}
简直是得来全不费工夫,我们直接通过这个方法拦截了 Ajax 请求,直接把响应结果拿到了,即使这个 Ajax 请求有加密参数,我们也不用关心,因为我们直接截获了 Ajax 最后响应的结果,这对数据爬取来说实在是太方便了。
另外还有很多其他的事件监听,这里不再一一介绍了,可以查阅官方文档,参考类似的写法实现。
获取页面源码
要获取页面的 HTML 代码其实很简单,我们直接通过 content 方法获取即可,用法如下:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
html = page.content()
print(html)
browser.close()
运行结果就是页面的 HTML 代码。获取了 HTML 代码之后,我们通过一些解析工具就可以提取想要的信息了。
页面点击
刚才我们通过示例也了解了页面点击的方法,那就是 click,这里详细说一下其使用方法。
页面点击的 API 定义如下:
page.click(selector, **kwargs)
这里可以看到必传的参数是 selector,其他的参数都是可选的。第一个 selector 就代表选择器,可以用来匹配想要点击的节点,如果传入的选择器匹配了多个节点,那么只会用第一个节点。
这个方法的内部执行逻辑如下:
- 根据 selector 找到匹配的节点,如果没有找到,那就一直等待直到超时,超时时间可以由额外的 timeout 参数设置,默认是 30 秒。
- 等待对该节点的可操作性检查的结果,比如说如果某个按钮设置了不可点击,那它会等待该按钮变成了可点击的时候才去点击,除非通过 force 参数设置跳过可操作性检查步骤强制点击。
- 如果需要的话,就滚动下页面,将需要被点击的节点呈现出来。
- 调用 page 对象的 mouse 方法,点击节点中心的位置,如果指定了 position 参数,那就点击指定的位置。
click 方法的一些比较重要的参数如下:
- click_count:点击次数,默认为 1。
- timeout:等待要点击的节点的超时时间,默认是 30 秒。
- position:需要传入一个字典,带有 x 和 y 属性,代表点击位置相对节点左上角的偏移位置。
- force:即使不可点击,那也强制点击。默认是 False。
具体的 API 设置参数可以参考官方文档:https://playwright.dev/python/docs/api/class-page/#pageclickselector-kwargs。
文本输入
文本输入对应的方法是 fill,API 定义如下:
page.fill(selector, value, **kwargs)
这个方法有两个必传参数,第一个参数也是 selector,第二个参数是 value,代表输入的内容,另外还可以通过 timeout 参数指定对应节点的最长等待时间。
获取节点属性
除了对节点进行操作,我们还可以获取节点的属性,方法就是 get_attribute,API 定义如下:
page.get_attribute(selector, name, **kwargs)
这个方法有两个必传参数,第一个参数也是 selector,第二个参数是 name,代表要获取的属性名称,另外还可以通过 timeout 参数指定对应节点的最长等待时间。
示例如下:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
href = page.get_attribute('a.name', 'href')
print(href)
browser.close()
这里我们调用了 get_attribute 方法,传入的 selector 是a.name,选定了 class 为 name 的 a 节点,然后第二个参数传入了 href,获取超链接的内容,输出结果如下:
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIx
可以看到对应 href 属性就获取出来了,但这里只有一条结果,因为这里有个条件,那就是如果传入的选择器匹配了多个节点,那么只会用第一个节点。
那怎么获取所有的节点呢?
获取多个节点
获取所有节点可以使用 query_selector_all 方法,它可以返回节点列表,通过遍历获取到单个节点之后,我们可以接着调用单个节点的方法来进行一些操作和属性获取,示例如下:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
elements = page.query_selector_all('a.name')
for element in elements:
print(element.get_attribute('href'))
print(element.text_content())
browser.close()
这里我们通过 query_selector_all 方法获取了所有匹配到的节点,每个节点对应的是一个 ElementHandle 对象,然后 ElementHandle 对象也有 get_attribute 方法来获取节点属性,另外还可以通过 text_content 方法获取节点文本。
运行结果如下:
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIx
霸王别姬 - Farewell My Concubine
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIy
这个杀手不太冷 - Léon
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIz
肖申克的救赎 - The Shawshank Redemption
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI0
泰坦尼克号 - Titanic
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI1
罗马假日 - Roman Holiday
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI2
唐伯虎点秋香 - Flirting Scholar
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI3
乱世佳人 - Gone with the Wind
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI4
喜剧之王 - The King of Comedy
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI5
楚门的世界 - The Truman Show
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIxMA==
狮子王 - The Lion King
获取单个节点
获取单个节点也有特定的方法,就是 query_selector,如果传入的选择器匹配到多个节点,那它只会返回第一个节点,示例如下:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto('https://spa6.scrape.center/')
page.wait_for_load_state('networkidle')
element = page.query_selector('a.name')
print(element.get_attribute('href'))
print(element.text_content())
browser.close()
运行结果如下:
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIx
霸王别姬 - Farewell My Concubine
可以看到这里只输出了第一个匹配节点的信息。
网络劫持
最后再介绍一个实用的方法 route,利用 route 方法,我们可以实现一些网络劫持和修改操作,比如修改 request 的属性,修改 response 响应结果等。
看一个实例:
from playwright.sync_api import sync_playwright
import re
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
def cancel_request(route, request):
route.abort()
page.route(re.compile(r"(\.png)|(\.jpg)"), cancel_request)
page.goto("https://spa6.scrape.center/")
page.wait_for_load_state('networkidle')
page.screenshot(path='no_picture.png')
browser.close()
这里我们调用了 route 方法,第一个参数通过正则表达式传入了匹配的 URL 路径,这里代表的是任何包含.png或.jpg 的链接,遇到这样的请求,会回调 cancel_request 方法处理,cancel_request 方法可以接收两个参数,一个是 route,代表一个 CallableRoute 对象,另外一个是 request,代表 Request 对象。这里我们直接调用了 route 的 abort 方法,取消了这次请求,所以最终导致的结果就是图片的加载全部取消了。
观察下运行结果,如图所示:
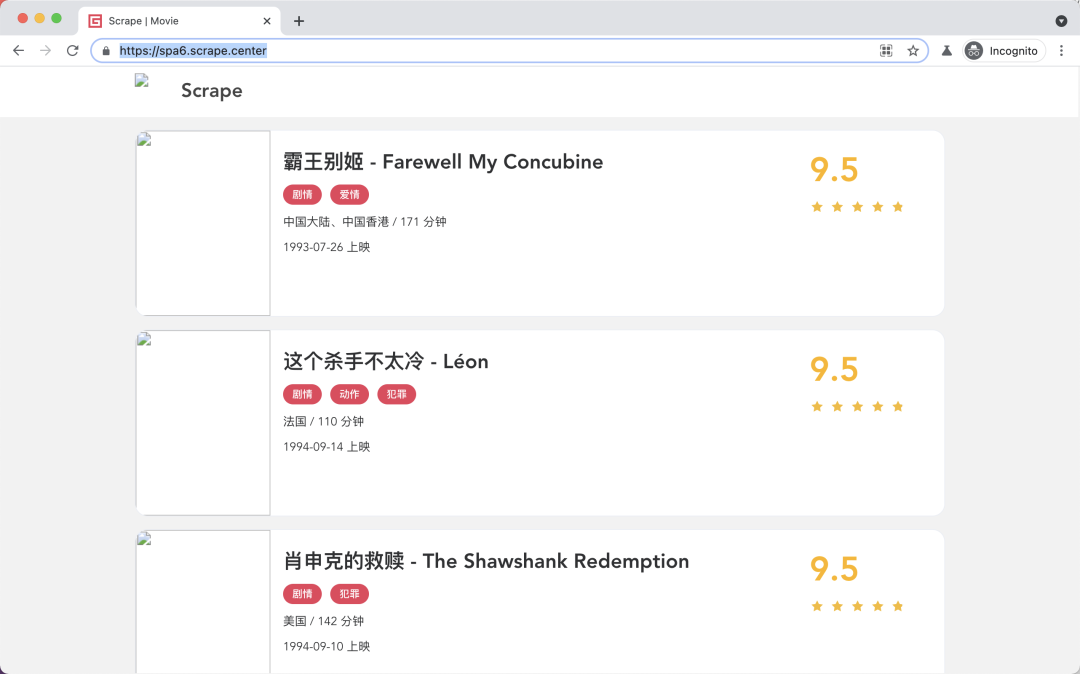
可以看到图片全都加载失败了。
这个设置有什么用呢?其实是有用的,因为图片资源都是二进制文件,而我们在做爬取过程中可能并不想关心其具体的二进制文件的内容,可能只关心图片的 URL 是什么,所以在浏览器中是否把图片加载出来就不重要了。所以如此设置之后,我们可以提高整个页面的加载速度,提高爬取效率。
另外,利用这个功能,我们还可以将一些响应内容进行修改,比如直接修改 Response 的结果为自定义的文本文件内容。
首先这里定义一个 HTML 文本文件,命名为 custom_response.html,内容如下:
html>
<html>
<head>
<title>Hack Responsetitle>
head>
<body>
<h1>Hack Responseh1>
body>
html>
代码编写如下:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
def modify_response(route, request):
route.fulfill(path="./custom_response.html")
page.route('/', modify_response)
page.goto("https://spa6.scrape.center/")
browser.close()
这里我们使用 route 的 fulfill 方法指定了一个本地文件,就是刚才我们定义的 HTML 文件,运行结果如下:
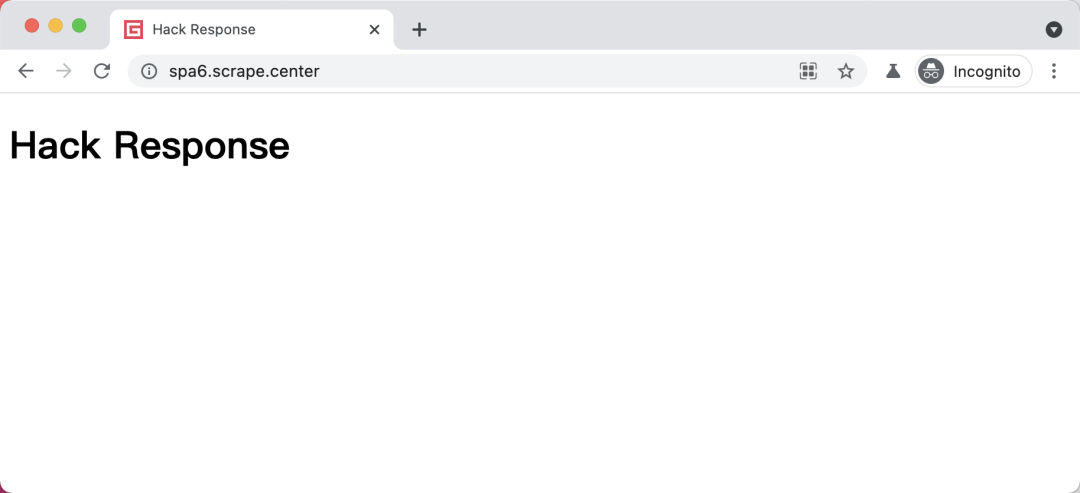
可以看到,Response 的运行结果就被我们修改了,URL 还是不变的,但是结果已经成了我们修改的 HTML 代码。
所以通过 route 方法,我们可以灵活地控制请求和响应的内容,从而在某些场景下达成某些目的。
8. 总结
本节介绍了 Playwright 的基本用法,其 API 强大又易于使用,同时具备很多 Selenium、Pyppeteer 不具备的更好用的 API,是新一代 JavaScript 渲染页面的爬取利器。
本节代码:https://github.com/Python3WebSpider/PlaywrightTest。
我们的文章到此就结束啦,如果你喜欢今天的Python 实战教程,请持续关注Python实用宝典。
有任何问题,可以在公众号后台回复:加群,回答相应红字验证信息,进入互助群询问。
原创不易,希望你能在下面点个赞和在看支持我继续创作,谢谢!
点击下方阅读原文可获得更好的阅读体验
Python实用宝典 (pythondict.com)
不只是一个宝典
欢迎关注公众号:Python实用宝典