
Pandas DataFrame 的可视化工具大全

简介
Excel的好处之一是它提供了一个直观和强大的图形界面来查看你的数据。相比之下,pandas + Jupyter notebook 提供了大量的编程能力,但在图形化显示和操作DataFrame视图方面能力有限。
在Python生态系统中,有几个工具被设计来填补这一空白。它们的复杂程度从简单的JavaScript库到复杂的、全功能的数据分析引擎不等。一个共同点是它们都提供了一种以图形格式查看和选择性地过滤数据的方法。从这个共同点出发,它们在设计和功能上有很大的不同。
本文将回顾这些DataFrame可视化选项中的几个,以便让你了解情况并评估哪些选项可能对你的分析过程有用。
背景介绍
对于这篇文章,我们将使用某销售数据集样本。下面是Jupyter notebook中的数据视图。
import pandas
url = 'https://github.com/chris1610/pbpython/blob/master/data/2018_Sales_Total_v2.xlsx?raw=True'
df = pd.read_excel(url)
df
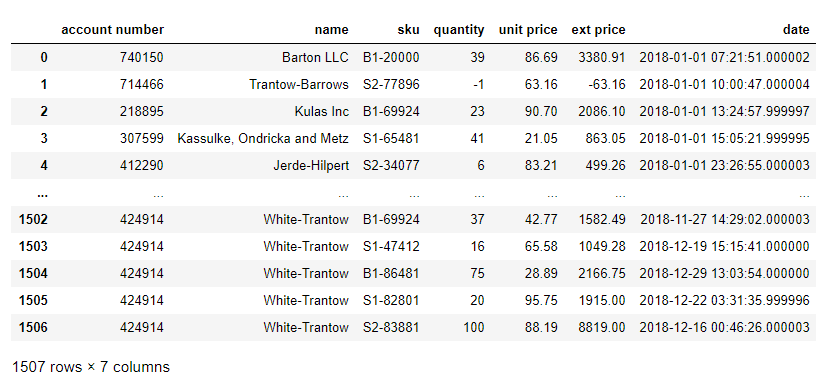
下面是Excel中一个类似的视图,对所有列都应用了过滤器。
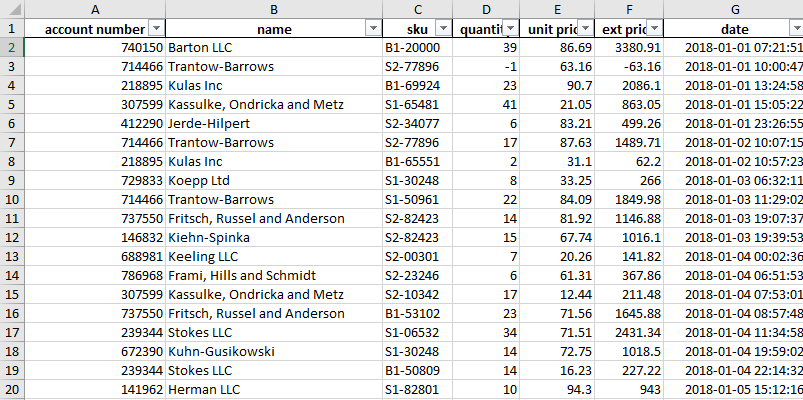
这种在Excel中熟悉的视图使你能够轻松地看到你的所有数据。你可以通过过滤和排序来检查数据,并在需要时深入了解细节。当你在探索一个新的数据集或解决一个现有数据集的新问题时,这种类型的功能是最有用的。
显然,对于数百万行的数据,这是不可行的。然而,即使你有大的数据集,并且是一个pandas专家,希望你仍然会把DataFrames转存到Excel,并查看数据的子集。
我使用Excel+python的部分原因是,在Excel中检查数据的特别能力要比普通的DataFrame视图好得多。
有了这个背景,让我们来看看在Excel中复制这种简单的查看能力的一些选项。
JavaScript工具
最简单的方法是使用一个JavaScript库来为Jupyter notebook中的DataFrame视图添加一些交互性。
Qgrid
我们要看的第一个工具是来自Quantopian的Qgrid。这个Jupyter notebook部件使用SlickGrid组件来为你的DataFrame添加互动性。
一旦它被安装,你可以显示一个支持排序和过滤数据的DataFrame版本。
import qgrid
import pandas
url = 'https://github.com/chris1610/pbpython/blob/master/data/2018_Sales_Total_v2.xlsx?raw=True'
df = pd.read_excel(url)
widget = qgrid.show_grid(df)
widget
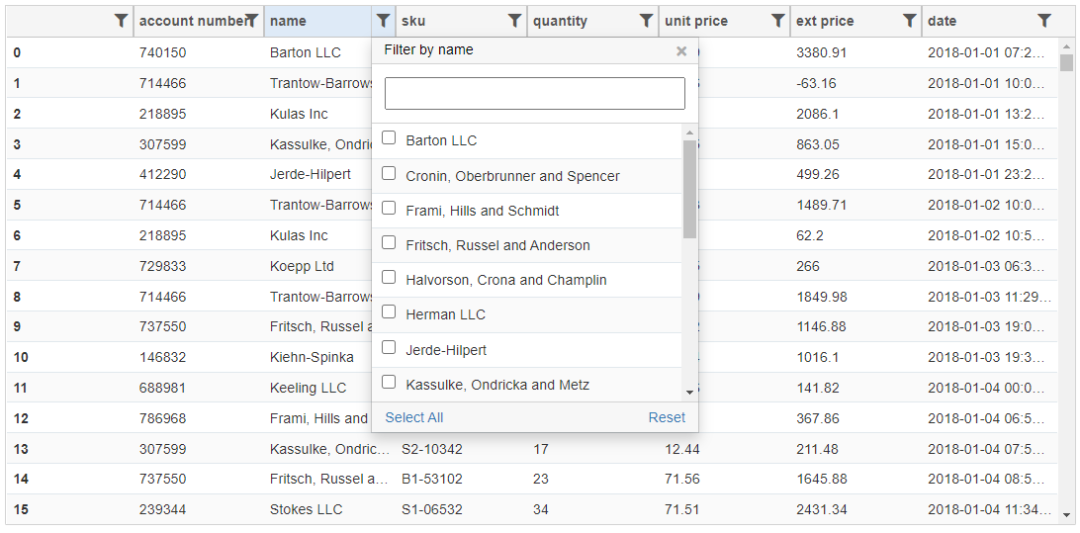
Qgrid支持使用基于底层数据类型的各种部件进行直观的过滤。此外,你可以配置一些渲染功能,然后将选定的数据读入一个DataFrame。这是一个相当有用的功能。
Qgrid不进行任何可视化,也不允许你使用pandas表达式来过滤和选择数据。
总的来说,Qgrid对于简单的数据操作和检查来说效果不错。
PivottableJs
下一个选项并不是用来查看DataFrame的,但我认为它是一个非常有用的总结数据的工具,所以我把它包括在内。
pivottablejs模块使用一个透视表JavaScript库,用于交互式数据透视和总结。
一旦安装了它,使用起来就很简单。
from pivottablejs import pivot_ui
pivot_ui(df)
在这个例子中,我通过点击和拖动总结了每个客户的购买数量。

除了基本的求和功能外,你也可以做一些可视化和统计分析。
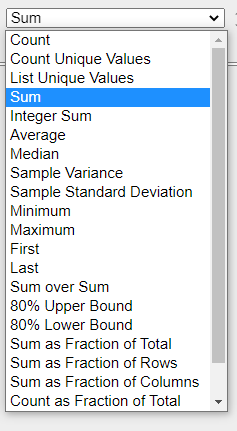
这个小组件对于过滤原始的DataFrame没有用处,但是对于数据的透视和总结来说确实很强大。其中一个很好的特点是,一旦你建立了透视表,你就可以过滤数据。
这个部件的另一个缺点是,它没有利用任何pandas的透视或选择功能。尽管如此,pivottablejs仍然是一个非常有用的快速透视和总结的工具。
数据分析应用
第二类GUI应用是成熟的应用,通常使用网络后端,如Flask或基于Qt的独立应用。这些应用程序的复杂性和能力各不相同,从简单的表格视图和绘图能力到强大的统计分析。这些工具的一个独特之处在于,它们与pandas紧密结合,因此你可以使用pandas代码来过滤数据并与这些应用程序进行交互。
PandasGUI
我将讨论的第一个应用程序是PandasGUI。这个应用程序的独特之处在于,它是一个用Qt构建的独立应用程序,可以从Jupyter notebook中调用。
使用前面例子中的相同数据,导入 show命令。
from pandasgui import show
show(df)
如果一切顺利的话,你最终会得到一个独立的GUI。因为它是一个独立的应用程序,你可以对视图进行相当多的配置。例如,我移动了几个标签,在一个页面上显示更多的能力。
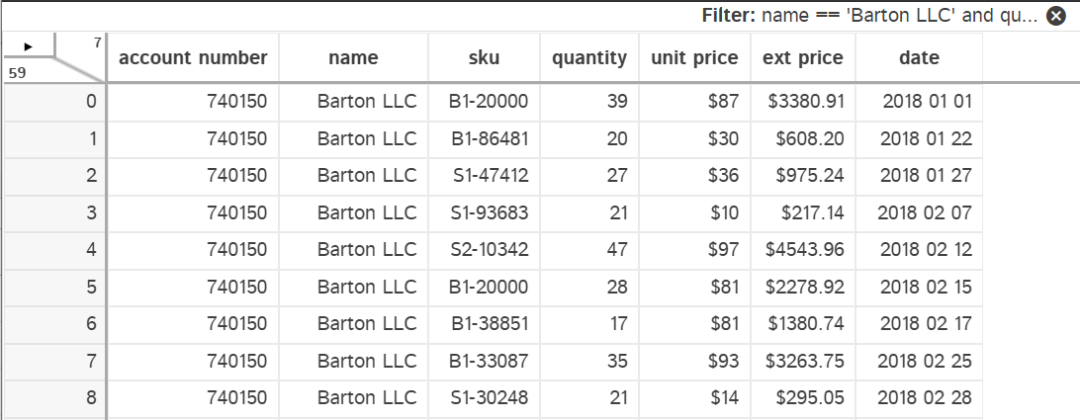
在这个例子中,我使用pandas查询语法过滤数据,以显示一个客户和购买数量>15的情况。
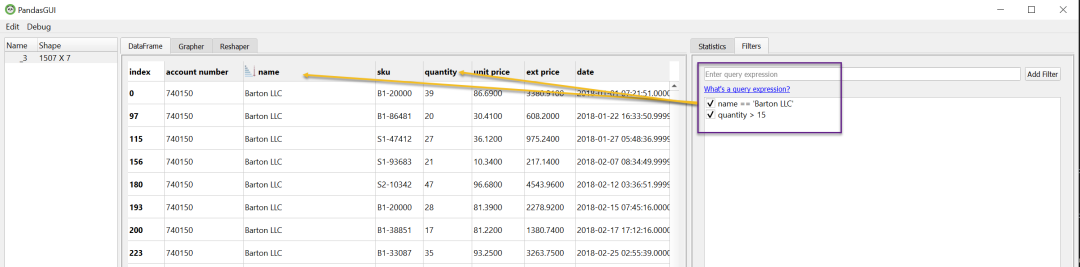
PandasGUI与Plotly集成,也可以建立可视化。下面是一个单价柱状图的例子。
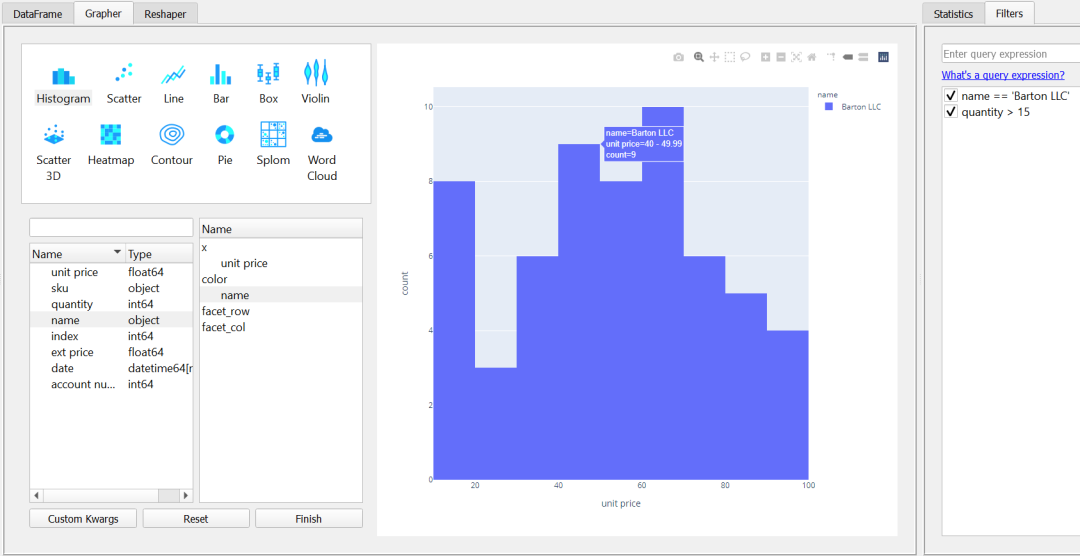
PandasGUI的一个很好的功能是,过滤器在所有标签中都对DataFrame有效。你可以使用这个功能,在绘制或转换数据时尝试不同的数据视图。
PandasGUI的另一个功能是,你可以通过透视或融合来重新塑造数据。下面是一个按SKU分类的单位销售量的汇总。

下面是产生的视图的样子。
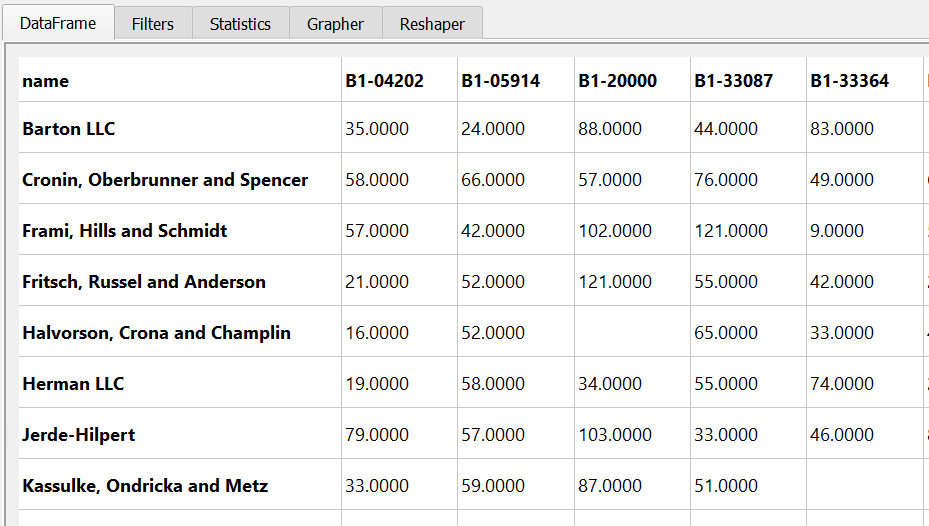
PandasGUI是一个令人印象深刻的应用程序。我喜欢它如何跟踪所有的变化,并且只是一个标准pandas功能的小包装。这个程序正在积极开发中,所以我将密切关注它,看它如何随着时间的推移而改进和发展。
Tabloo
Tabloo这个名字让我每次看到它都会微笑。希望某个BI商业化可视化工具不会因为这个名字的相似性而感到不悦!
无论如何,Tabloo使用Flask后端为DataFrames提供一个简单的可视化工具,以及类似于PandasGUI的绘图能力。
使用Tabloo与PandasGUI非常相似。
import tabloo
tabloo.show(df)
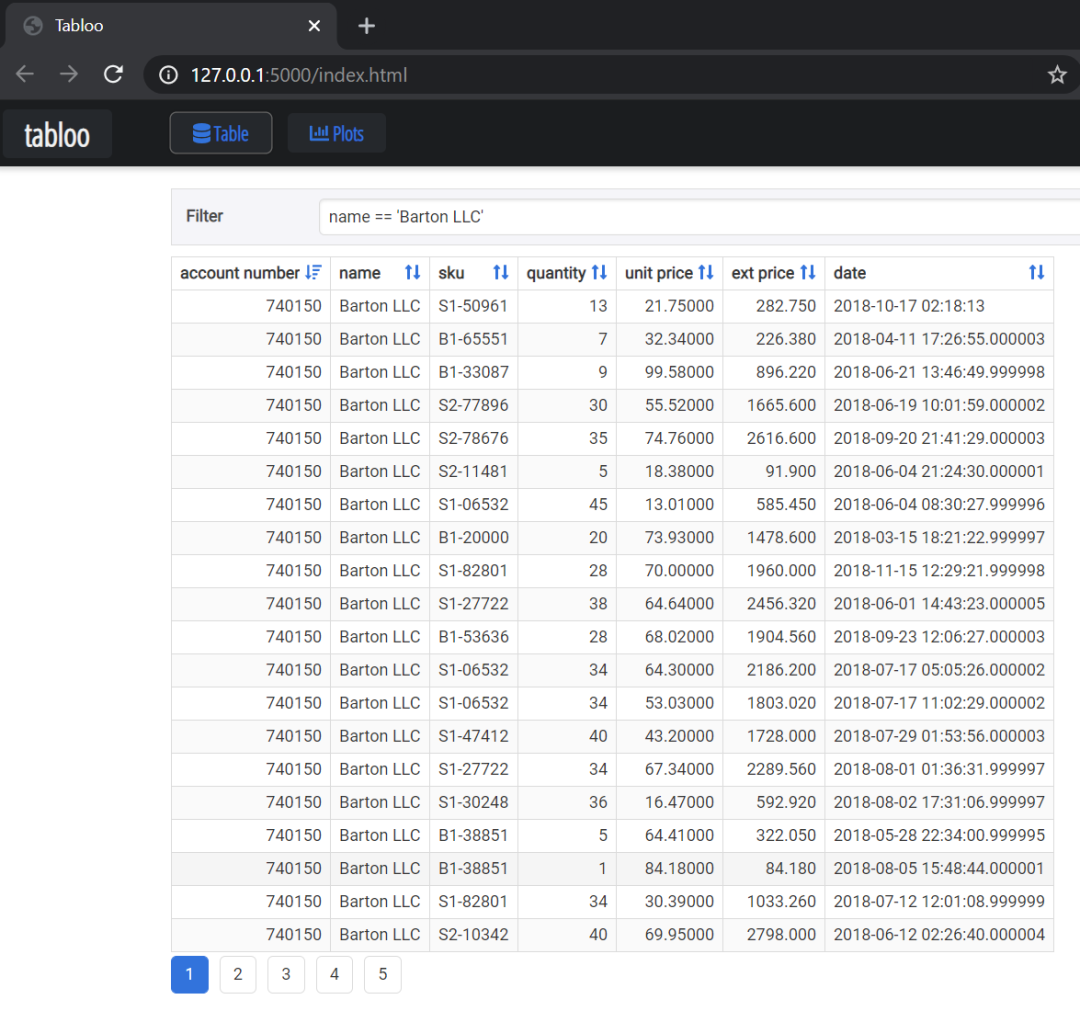
Tabloo使用了像PandasGUI那样的查询语法,但我无法弄清楚如何像PandasGUI那样添加多个过滤器。
最后,Tabloo确实也有一些基本的绘图功能,但它不像PandasGUI那样丰富。
Tabloo有一些有趣的概念,但没有像PandasGUI那样的能力。它已经有一段时间没有更新了,所以它可能处于休眠状态,但我想把它包含进来,以获得尽可能完整的调查。
Dtale
最后一个应用程序是Dtale,它是最复杂的选项。Dtale的架构与Tabloo类似,它使用Flask后端,但也包括一个强大的React前端。Dtale是一个成熟的项目,有很多的文档和很多的功能。我将在这篇文章中只介绍一小部分功能。
开始使用Dtale与本类别中的其他应用程序类似。
import dtale
dtale.show(df)

这个视图给你一个提示,Dtale不仅仅是一个数据框架查看器。它是一个非常强大的统计工具集。我不能在这里介绍所有的增强功能,但这里有一个快速例子,显示了单位价格列的直方图。
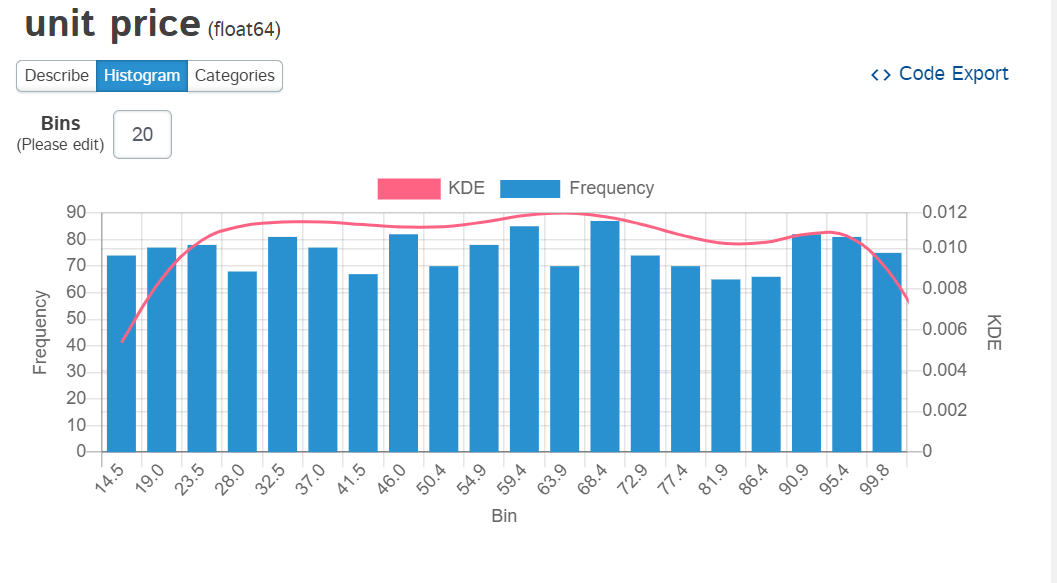
我非常喜欢Dtale的一个特点是,你可以导出代码并看到它在做什么。这是一个非常强大的功能,使Excel+Python解决方案区别于普通的Excel。
下面是一个从上面的可视化中导出代码的例子。
# DISCLAIMER: 'df' refers to the data you passed in when calling 'dtale.show'
import numpy as np
import pandas as pd
if isinstance(df, (pd.DatetimeIndex, pd.MultiIndex)):
df = df.to_frame(index=False)
# remove any pre-existing indices for ease of use in the D-Tale code, but this is not required
df = df.reset_index().drop('index', axis=1, errors='ignore')
df.columns = [str(c) for c in df.columns] # update columns to strings in case they are numbers
s = df[~pd.isnull(df['{col}'])][['{col}']]
chart, labels = np.histogram(s, bins=20)
import scipy.stats as sts
kde = sts.gaussian_kde(s['unit price'])
kde_data = kde.pdf(np.linspace(labels.min(), labels.max()))
# main statistics
stats = df['unit price'].describe().to_frame().T
关于过滤数据的问题,Dtale也允许你对数据进行格式化。在下面的例子中,我对货币和日期列进行了格式化,使其更容易阅读。
正如我先前所说,Dtale是一个强大的工具,有很多能力。如果你有兴趣,我鼓励你检查一下,看看它是否适合你。
需要注意的一个方面是,在试图运行Dtale时,你可能会遇到Windows防火墙问题。在一个封闭的公司机器上,这可能是一个问题。关于各种安装选项的更多细节,请参考文档。
不管这个问题如何,我认为它绝对值得检查一下Dtale,即使只是为了看看你可以使用的所有功能。
IDE变量查看器
如果你在VS Code或Spyder等工具中进行开发,你可以使用一个简单的DataFrame变量查看器。
例如,这里是使用Spyder的变量资源管理器对我们的DataFrame的查看。
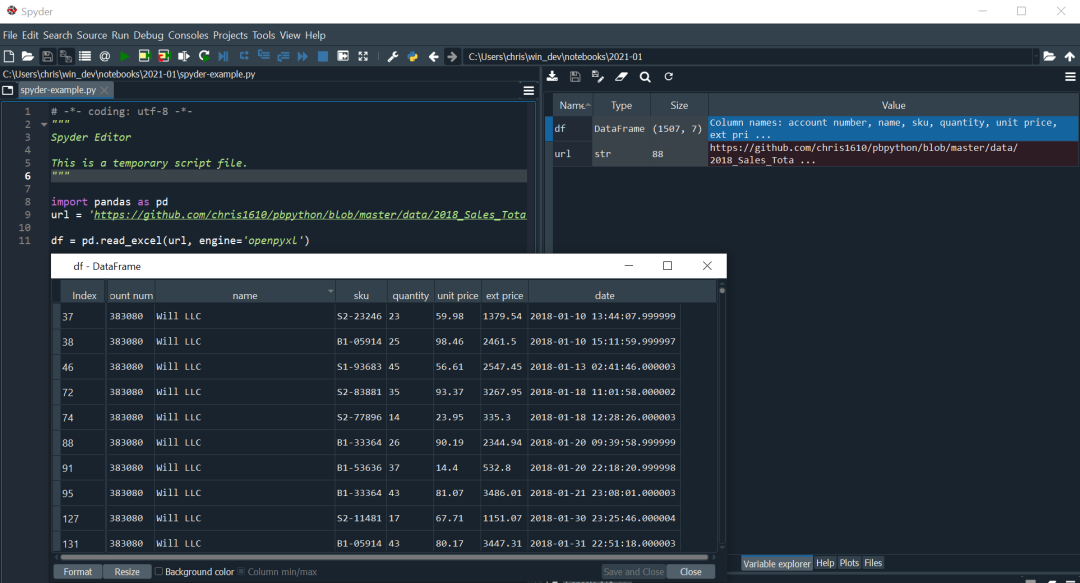
如果你使用Spyder,这个查看器是非常方便的。你在GUI中没有任何过滤数据的能力,但你可以改变排序顺序。
VS Code也有一个类似的功能。下面是一个简单的视图,显示了你如何过滤数据。

如果你已经在Spyder或VS code中进行工作,这些功能都很有用。然而,当涉及到复杂的过滤或复杂的数据分析时,它们几乎没有Dtale的能力。
但我希望VS Code能继续改进他们的DataFrame查看器。现在看来,VS Code几乎可以做任何事情,所以我很想看看这个功能是如何发展的。
PyXLL
前面提到的文章需要PyXLL包,这是一个商业应用。我对一个公司开发商业产品没有意见。我认为这对 Python 生态系统的成功至关重要。然而,一个付费的选项意味着你可能需要得到更多的支持才能把它引入你的组织。幸运的是,你可以免费试用30天,看看它是否符合你的需求。
抛开这个注意事项,让我们用我们的例子数据集来试试。
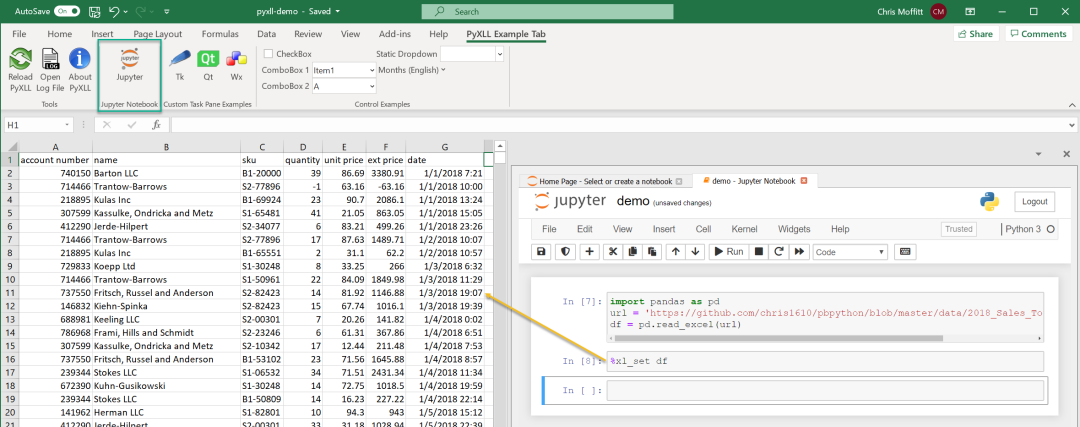
真正强大的是,你可以让notebook与Excel并列,并使用jupyter魔法命令在notebook和Excel之间交换数据。在这个例子中,使用 %xl_set df将直接把DataFrame放到Excel文件中。然后,你可以在混合模式下与Excel工作。
PyXLL在整合Python和Excel方面有很多不同的功能,所以很难将其与前面讨论的框架进行比较。总的来说,我喜欢使用Excel的可视化组件加上Python编程的力量的想法。如果你对这种Python和Excel的结合感兴趣,你肯定应该看看PyXLL。
xlwings
xlwings已经存在了一段时间,xlwings与PyXLL类似,它也是由一家商业公司支持的。然而,它有一个开源的社区版,以及一个付费的专业版。这里的例子使用的是社区版。完整的专业版xlwings软件包有几个不同的功能来整合Excel和Python。
虽然xlwings不能直接与Jupyter notebook集成,但你可以用DataFrame实时填充Excel电子表格并使用Excel进行分析。
下面是一个简短的代码片段。
import pandas as pd
import xlwings as xw
url = 'https://github.com/chris1610/pbpython/blob/master/data/2018_Sales_Total_v2.xlsx?raw=True'
df = pd.read_excel(url)
# Create a new workbook and add the DataFrame to Sheet1
xw.view(df)
这段代码将打开一个新的Excel实例并将df放入A1单元格。下面是它的样子。
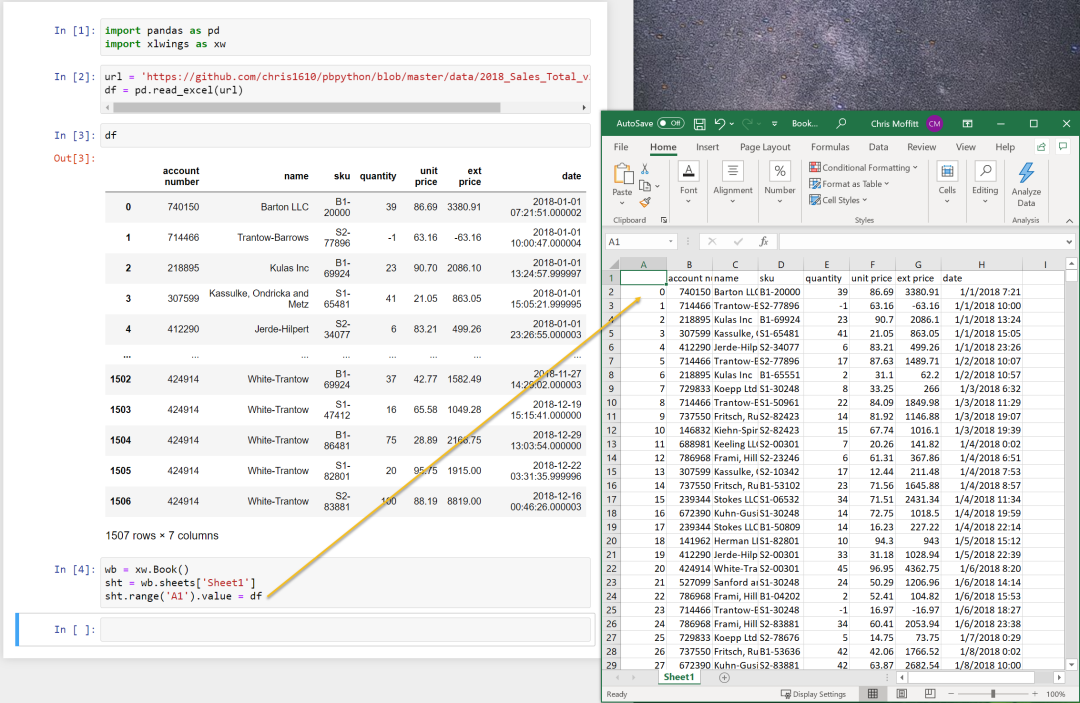
这可以是一个快速的捷径,而不是保存并重新打开Excel来查看你的数据。其实这样做很简单,所以我可能会在自己的数据分析中多尝试一些。
总结
这篇文章已经涵盖了很多内容。这里有一张图片,总结了我们讨论的所有选项。
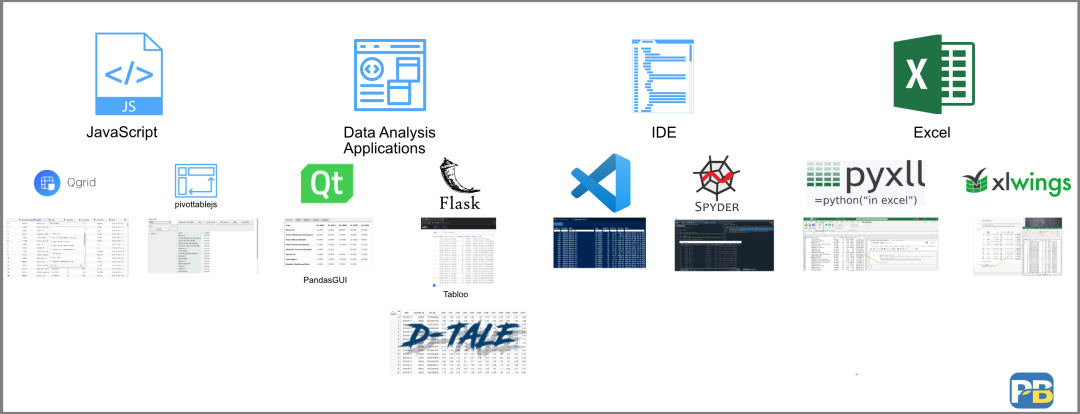
是否有一个适用于所有人的解决方案?我不这么认为。我想写这篇文章的部分原因是,我想引起对 "最佳 "解决方案的讨论。我希望你能借此机会查看其中一些解决方案,看看它们是否适合你的分析过程。这些解决方案中的每一个都以不同的方式解决了问题的不同方面。我猜想,用户很可能会把其中几个结合在一起--这取决于他们试图解决的问题。
我预测我们将继续看到这个领域的演变。我希望我们能够找到一个解决方案,利用Excel的一些互动直观的方面,以及与使用Python和pandas进行数据操作有关的力量和透明度。随着Guido van Rossum加入微软,也许我们会在这个领域看到更多的进展?