
Scrapy源码剖析:Scrapy有哪些核心组件?
爬虫类
Crawler 的 crawl 方法,我们来看这个方法:@defer.inlineCallbacks
def crawl(self, *args, **kwargs):
assert not self.crawling, "Crawling already taking place"
self.crawling = True
try:
# 从spiderloader中找到爬虫类 并实例化爬虫实例
self.spider = self._create_spider(*args, **kwargs)
# 创建引擎
self.engine = self._create_engine()
# 调用爬虫类的start_requests方法 拿到种子URL列表
start_requests = iter(self.spider.start_requests())
# 执行引擎的open_spider 并传入爬虫实例和初始请求
yield self.engine.open_spider(self.spider, start_requests)
yield defer.maybeDeferred(self.engine.start)
except Exception:
if six.PY2:
exc_info = sys.exc_info()
self.crawling = False
if self.engine is not None:
yield self.engine.close()
if six.PY2:
six.reraise(*exc_info)
raise
Crawler 实例化时,会创建 SpiderLoader,它会根据我们定义的配置文件 settings.py 找到存放爬虫的位置,我们写的爬虫代码都在这里。SpiderLoader 会扫描这些代码文件,并找到父类是 scrapy.Spider 爬虫类,然后根据爬虫类中的 name 属性(在编写爬虫时,这个属性是必填的),生成一个 {spider_name: spider_cls} 的字典,最后根据 scrapy crawl 命令中的 spider_name 找到我们写的爬虫类,然后实例化它,在这里就是调用了_create_spider方法:def _create_spider(self, *args, **kwargs):
# 调用类方法from_crawler实例化
return self.spidercls.from_crawler(self, *args, **kwargs)
from_crawler 进行的初始化,找到 scrapy.Spider 类:@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
spider = cls(*args, **kwargs)
spider._set_crawler(crawler)
return spider
def _set_crawler(self, crawler):
self.crawler = crawler
# 把settings对象赋给spider实例
self.settings = crawler.settings
crawler.signals.connect(self.close, signals.spider_closed)
settings 配置,来看构造方法干了些什么?class Spider(object_ref):
name = None
custom_settings = None
def __init__(self, name=None, **kwargs):
# name必填
if name is not None:
self.name = name
elif not getattr(self, 'name', None):
raise ValueError("%s must have a name" % type(self).__name__)
self.__dict__.update(kwargs)
# 如果没有设置start_urls 默认是[]
if not hasattr(self, 'start_urls'):
self.start_urls = []
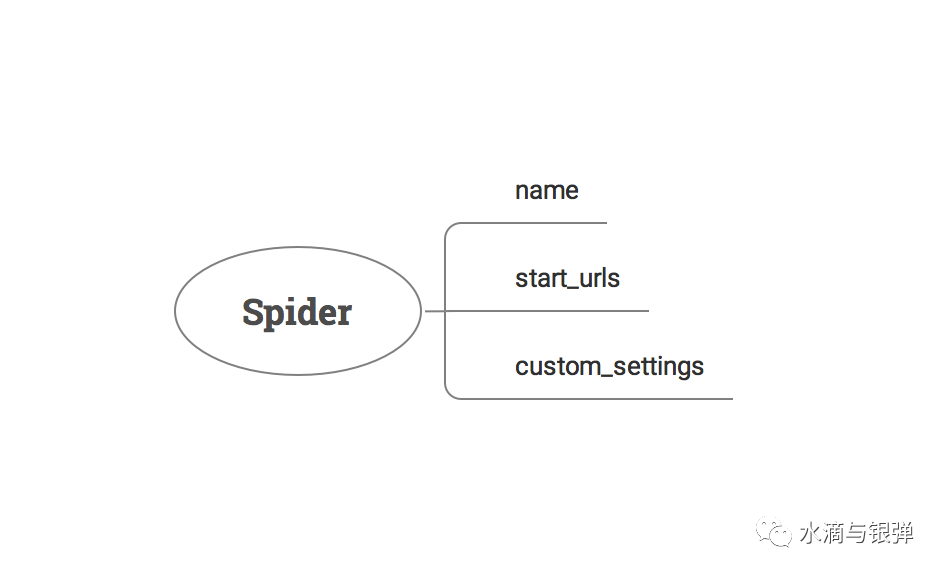
name、start_urls、custom_settings:name:在运行爬虫时通过它找到我们编写的爬虫类;start_urls:抓取入口,也可以叫做种子URL;custom_settings:爬虫自定义配置,会覆盖配置文件中的配置项;
引擎
Crawler 的 crawl 方法,紧接着就是创建引擎对象,也就是 _create_engine 方法,看看初始化时都发生了什么?class ExecutionEngine(object):
"""引擎"""
def __init__(self, crawler, spider_closed_callback):
self.crawler = crawler
# 这里也把settings配置保存到引擎中
self.settings = crawler.settings
# 信号
self.signals = crawler.signals
# 日志格式
self.logformatter = crawler.logformatter
self.slot = None
self.spider = None
self.running = False
self.paused = False
# 从settings中找到Scheduler调度器,找到Scheduler类
self.scheduler_cls = load_object(self.settings['SCHEDULER'])
# 同样,找到Downloader下载器类
downloader_cls = load_object(self.settings['DOWNLOADER'])
# 实例化Downloader
self.downloader = downloader_cls(crawler)
# 实例化Scraper 它是引擎连接爬虫类的桥梁
self.scraper = Scraper(crawler)
self._spider_closed_callback = spider_closed_callback
Scheduler、Downloader、Scrapyer,其中 Scheduler 只进行了类定义,没有实例化。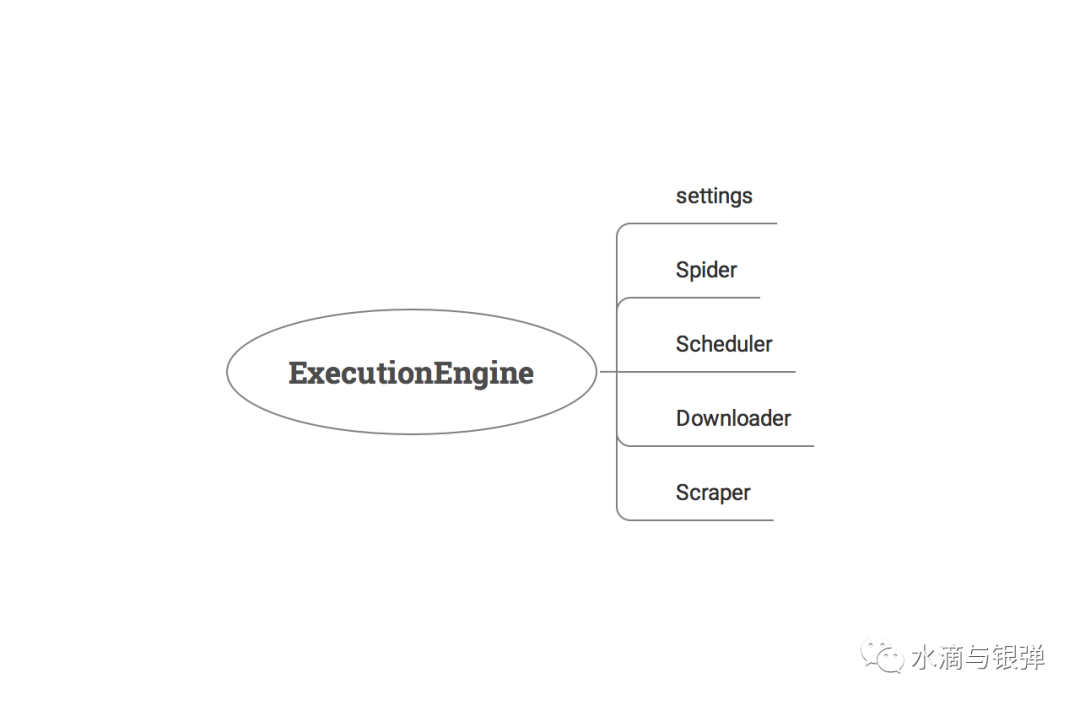
调度器
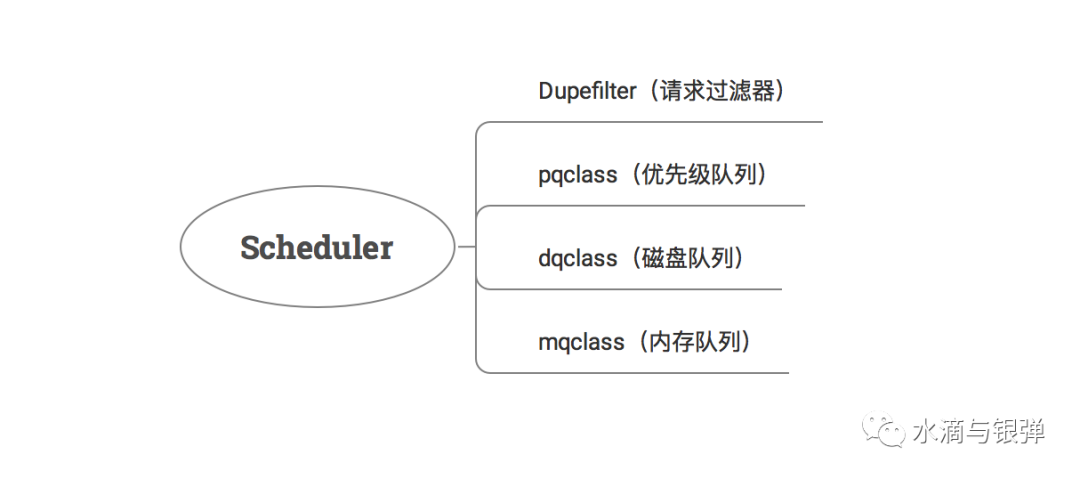
open_spider 方法中,我们提前来看一下调度器的初始化。class Scheduler(object):
"""调度器"""
def __init__(self, dupefilter, jobdir=None, dqclass=None, mqclass=None,
logunser=False, stats=None, pqclass=None):
# 指纹过滤器
self.df = dupefilter
# 任务队列文件夹
self.dqdir = self._dqdir(jobdir)
# 优先级任务队列类
self.pqclass = pqclass
# 磁盘任务队列类
self.dqclass = dqclass
# 内存任务队列类
self.mqclass = mqclass
# 日志是否序列化
self.logunser = logunser
self.stats = stats
@classmethod
def from_crawler(cls, crawler):
settings = crawler.settings
# 从配置文件中获取指纹过滤器类
dupefilter_cls = load_object(settings['DUPEFILTER_CLASS'])
# 实例化指纹过滤器
dupefilter = dupefilter_cls.from_settings(settings)
# 从配置文件中依次获取优先级任务队列类、磁盘队列类、内存队列类
pqclass = load_object(settings['SCHEDULER_PRIORITY_QUEUE'])
dqclass = load_object(settings['SCHEDULER_DISK_QUEUE'])
mqclass = load_object(settings['SCHEDULER_MEMORY_QUEUE'])
# 请求日志序列化开关
logunser = settings.getbool('LOG_UNSERIALIZABLE_REQUESTS', settings.getbool('SCHEDULER_DEBUG'))
return cls(dupefilter, jobdir=job_dir(settings), logunser=logunser,
stats=crawler.stats, pqclass=pqclass, dqclass=dqclass, mqclass=mqclass)
实例化请求指纹过滤器:主要用来过滤重复请求; 定义不同类型的任务队列:优先级任务队列、基于磁盘的任务队列、基于内存的任务队列;
RFPDupeFilter:class RFPDupeFilter(BaseDupeFilter):
"""请求指纹过滤器"""
def __init__(self, path=None, debug=False):
self.file = None
# 指纹集合 使用的是Set 基于内存
self.fingerprints = set()
self.logdupes = True
self.debug = debug
self.logger = logging.getLogger(__name__)
# 请求指纹可存入磁盘
if path:
self.file = open(os.path.join(path, 'requests.seen'), 'a+')
self.file.seek(0)
self.fingerprints.update(x.rstrip() for x in self.file)
@classmethod
def from_settings(cls, settings):
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(job_dir(settings), debug)
Set,而且可以控制这些指纹是否存入磁盘以供下次重复使用。基于磁盘的任务队列:在配置文件可配置存储路径,每次执行后会把队列任务保存到磁盘上; 基于内存的任务队列:每次都在内存中执行,下次启动则消失;
# 基于磁盘的任务队列(后进先出)
SCHEDULER_DISK_QUEUE = 'scrapy.squeues.PickleLifoDiskQueue'
# 基于内存的任务队列(后进先出)
SCHEDULER_MEMORY_QUEUE = 'scrapy.squeues.LifoMemoryQueue'
# 优先级队列
SCHEDULER_PRIORITY_QUEUE = 'queuelib.PriorityQueue'
JOBDIR 配置项,那么每次执行爬虫时,都会把任务队列保存在磁盘中,下次启动爬虫时可以重新加载继续执行我们的任务。scrapy.squeues 模块了,在这里定义了很多种队列:# 先进先出磁盘队列(pickle序列化)
PickleFifoDiskQueue = _serializable_queue(queue.FifoDiskQueue, \
_pickle_serialize, pickle.loads)
# 后进先出磁盘队列(pickle序列化)
PickleLifoDiskQueue = _serializable_queue(queue.LifoDiskQueue, \
_pickle_serialize, pickle.loads)
# 先进先出磁盘队列(marshal序列化)
MarshalFifoDiskQueue = _serializable_queue(queue.FifoDiskQueue, \
marshal.dumps, marshal.loads)
# 后进先出磁盘队列(marshal序列化)
MarshalLifoDiskQueue = _serializable_queue(queue.LifoDiskQueue, \
marshal.dumps, marshal.loads)
# 先进先出内存队列
FifoMemoryQueue = queue.FifoMemoryQueue
# 后进先出内存队列
LifoMemoryQueue = queue.LifoMemoryQueue
下载器
default_settings.py 中,下载器配置如下:DOWNLOADER = 'scrapy.core.downloader.Downloader'
Downloader 类的初始化:class Downloader(object):
"""下载器"""
def __init__(self, crawler):
# 同样的 拿到settings对象
self.settings = crawler.settings
self.signals = crawler.signals
self.slots = {}
self.active = set()
# 初始化DownloadHandlers
self.handlers = DownloadHandlers(crawler)
# 从配置中获取设置的并发数
self.total_concurrency = self.settings.getint('CONCURRENT_REQUESTS')
# 同一域名并发数
self.domain_concurrency = self.settings.getint('CONCURRENT_REQUESTS_PER_DOMAIN')
# 同一IP并发数
self.ip_concurrency = self.settings.getint('CONCURRENT_REQUESTS_PER_IP')
# 随机延迟下载时间
self.randomize_delay = self.settings.getbool('RANDOMIZE_DOWNLOAD_DELAY')
# 初始化下载器中间件
self.middleware = DownloaderMiddlewareManager.from_crawler(crawler)
self._slot_gc_loop = task.LoopingCall(self._slot_gc)
self._slot_gc_loop.start(60)
DownloadHandlers:class DownloadHandlers(object):
"""下载器处理器"""
def __init__(self, crawler):
self._crawler = crawler
self._schemes = {} # 存储scheme对应的类路径 后面用于实例化
self._handlers = {} # 存储scheme对应的下载器
self._notconfigured = {}
# 从配置中找到DOWNLOAD_HANDLERS_BASE 构造下载处理器
# 注意:这里是调用getwithbase方法 取的是配置中的XXXX_BASE配置
handlers = without_none_values(
crawler.settings.getwithbase('DOWNLOAD_HANDLERS'))
# 存储scheme对应的类路径 后面用于实例化
for scheme, clspath in six.iteritems(handlers):
self._schemes[scheme] = clspath
crawler.signals.connect(self._close, signals.engine_stopped)
# 用户可自定义的下载处理器
DOWNLOAD_HANDLERS = {}
# 默认的下载处理器
DOWNLOAD_HANDLERS_BASE = {
'file': 'scrapy.core.downloader.handlers.file.FileDownloadHandler',
'http': 'scrapy.core.downloader.handlers.http.HTTPDownloadHandler',
'https': 'scrapy.core.downloader.handlers.http.HTTPDownloadHandler',
's3': 'scrapy.core.downloader.handlers.s3.S3DownloadHandler',
'ftp': 'scrapy.core.downloader.handlers.ftp.FTPDownloadHandler',
}
http 和 https 对应的处理器。DownloaderMiddlewareManager 初始化过程,同样地,这里又调用了类方法 from_crawler 进行初始化,而且 DownloaderMiddlewareManager 继承了MiddlewareManager 类,来看它在初始化做了哪些工作:class MiddlewareManager(object):
"""所有中间件的父类,提供中间件公共的方法"""
component_name = 'foo middleware'
@classmethod
def from_crawler(cls, crawler):
# 调用from_settings
return cls.from_settings(crawler.settings, crawler)
@classmethod
def from_settings(cls, settings, crawler=None):
# 调用子类_get_mwlist_from_settings得到所有中间件类的模块
mwlist = cls._get_mwlist_from_settings(settings)
middlewares = []
enabled = []
# 依次实例化
for clspath in mwlist:
try:
# 加载这些中间件模块
mwcls = load_object(clspath)
# 如果此中间件类定义了from_crawler 则调用此方法实例化
if crawler and hasattr(mwcls, 'from_crawler'):
mw = mwcls.from_crawler(crawler)
# 如果此中间件类定义了from_settings 则调用此方法实例化
elif hasattr(mwcls, 'from_settings'):
mw = mwcls.from_settings(settings)
# 上面2个方法都没有,则直接调用构造实例化
else:
mw = mwcls()
middlewares.append(mw)
enabled.append(clspath)
except NotConfigured as e:
if e.args:
clsname = clspath.split('.')[-1]
logger.warning("Disabled %(clsname)s: %(eargs)s",
{'clsname': clsname, 'eargs': e.args[0]},
extra={'crawler': crawler})
logger.info("Enabled %(componentname)ss:\n%(enabledlist)s",
{'componentname': cls.component_name,
'enabledlist': pprint.pformat(enabled)},
extra={'crawler': crawler})
# 调用构造方法
return cls(*middlewares)
@classmethod
def _get_mwlist_from_settings(cls, settings):
# 具体有哪些中间件类,子类定义
raise NotImplementedError
def __init__(self, *middlewares):
self.middlewares = middlewares
# 定义中间件方法
self.methods = defaultdict(list)
for mw in middlewares:
self._add_middleware(mw)
def _add_middleware(self, mw):
# 默认定义的 子类可覆盖
# 如果中间件类有定义open_spider 则加入到methods
if hasattr(mw, 'open_spider'):
self.methods['open_spider'].append(mw.open_spider)
# 如果中间件类有定义close_spider 则加入到methods
# methods就是一串中间件的方法链 后期会依次调用
if hasattr(mw, 'close_spider'):
self.methods['close_spider'].insert(0, mw.close_spider)
DownloaderMiddlewareManager 实例化过程:class DownloaderMiddlewareManager(MiddlewareManager):
"""下载中间件管理器"""
component_name = 'downloader middleware'
@classmethod
def _get_mwlist_from_settings(cls, settings):
# 从配置文件DOWNLOADER_MIDDLEWARES_BASE和DOWNLOADER_MIDDLEWARES获得所有下载器中间件
return build_component_list(
settings.getwithbase('DOWNLOADER_MIDDLEWARES'))
def _add_middleware(self, mw):
# 定义下载器中间件请求、响应、异常一串方法
if hasattr(mw, 'process_request'):
self.methods['process_request'].append(mw.process_request)
if hasattr(mw, 'process_response'):
self.methods['process_response'].insert(0, mw.process_response)
if hasattr(mw, 'process_exception'):
self.methods['process_exception'].insert(0, mw.process_exception)
MiddlewareManager 类,然后重写了 _add_middleware 方法,为下载行为定义默认的下载前、下载后、异常时对应的处理方法。
Scraper
Scraper,在Scrapy源码分析(一)架构概览这篇文章中我提到过,这个类没有在架构图中出现,但这个类其实是处于Engine、Spiders、Pipeline 之间,是连通这三个组件的桥梁。class Scraper(object):
def __init__(self, crawler):
self.slot = None
# 实例化爬虫中间件管理器
self.spidermw = SpiderMiddlewareManager.from_crawler(crawler)
# 从配置文件中加载Pipeline处理器类
itemproc_cls = load_object(crawler.settings['ITEM_PROCESSOR'])
# 实例化Pipeline处理器
self.itemproc = itemproc_cls.from_crawler(crawler)
# 从配置文件中获取同时处理输出的任务个数
self.concurrent_items = crawler.settings.getint('CONCURRENT_ITEMS')
self.crawler = crawler
self.signals = crawler.signals
self.logformatter = crawler.logformatter
Scraper 创建了 SpiderMiddlewareManager,它的初始化过程:class SpiderMiddlewareManager(MiddlewareManager):
"""爬虫中间件管理器"""
component_name = 'spider middleware'
@classmethod
def _get_mwlist_from_settings(cls, settings):
# 从配置文件中SPIDER_MIDDLEWARES_BASE和SPIDER_MIDDLEWARES获取默认的爬虫中间件类
return build_component_list(settings.getwithbase('SPIDER_MIDDLEWARES'))
def _add_middleware(self, mw):
super(SpiderMiddlewareManager, self)._add_middleware(mw)
# 定义爬虫中间件处理方法
if hasattr(mw, 'process_spider_input'):
self.methods['process_spider_input'].append(mw.process_spider_input)
if hasattr(mw, 'process_spider_output'):
self.methods['process_spider_output'].insert(0, mw.process_spider_output)
if hasattr(mw, 'process_spider_exception'):
self.methods['process_spider_exception'].insert(0, mw.process_spider_exception)
if hasattr(mw, 'process_start_requests'):
self.methods['process_start_requests'].insert(0, mw.process_start_requests)
SPIDER_MIDDLEWARES_BASE = {
# 默认的爬虫中间件类
'scrapy.spidermiddlewares.httperror.HttpErrorMiddleware': 50,
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': 500,
'scrapy.spidermiddlewares.referer.RefererMiddleware': 700,
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware': 800,
'scrapy.spidermiddlewares.depth.DepthMiddleware': 900,
}
HttpErrorMiddleware:针对非 200 响应错误进行逻辑处理; OffsiteMiddleware:如果Spider中定义了 allowed_domains,会自动过滤除此之外的域名请求;RefererMiddleware:追加 Referer头信息;UrlLengthMiddleware:过滤 URL 长度超过限制的请求; DepthMiddleware:过滤超过指定深度的抓取请求;
Pipeline 组件的初始化,默认的 Pipeline 组件是 ItemPipelineManager:class ItemPipelineManager(MiddlewareManager):
component_name = 'item pipeline'
@classmethod
def _get_mwlist_from_settings(cls, settings):
# 从配置文件加载ITEM_PIPELINES_BASE和ITEM_PIPELINES类
return build_component_list(settings.getwithbase('ITEM_PIPELINES'))
def _add_middleware(self, pipe):
super(ItemPipelineManager, self)._add_middleware(pipe)
# 定义默认的pipeline处理逻辑
if hasattr(pipe, 'process_item'):
self.methods['process_item'].append(pipe.process_item)
def process_item(self, item, spider):
# 依次调用所有子类的process_item方法
return self._process_chain('process_item', item, spider)
ItemPipelineManager 也是中间件管理器的一个子类,由于它的行为非常类似于中间件,但由于功能较为独立,所以属于核心组件之一。Scraper 的初始化过程我们可以看出,它管理着 Spiders 和 Pipeline 相关的数据交互。
总结
更多阅读
特别推荐

点击下方阅读原文加入社区会员
评论