
分布式架构概述及设计
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
引言
随着越来越多的人参与到互联网的浪潮来,曾经的单体应用架构越来越无法满足需求,所以,分布式集群架构出现,也因此,分布式搭建开发成为了Web开发者必掌握的技能之一。那什么是分布式呢?怎么实现分布式以及怎么处理分布式带来的问题呢?本系列文章就来源于对分布式各组件系统的学习总结,包含但不限于Zookeeper、Dubbo、消息队列(ActiveMQ、Kafka、RabbitMQ)、Nosql(Redis、MongoDB)、Niginx、分库分表MyCat、Netty等内容。作为跟大多数人一样的学习使用者,而非布道者,个人理解难免会有偏差或是其它错误,希望各位读者不吝指教。
正文
一、什么是分布式
简单的说,“分工协作,专人做专事”就是分布式的概念。就好比你是你们公司唯一的码农,那么前后端都需要你自己来开发(单体架构),但随着业务的增长,你确实忙不过来了,老板给你招来了一个前端,那么你就只需要专注后端开发就行了(分布式)。但是软件的分布式搭建远远不像现实例子中这么简单,需要考虑和处理很多方面的问题,我们先了解以下几个常见的概念:
集群:你们公司业务增长的非常快,老板发现你一个后端忙不过来了,就又招了几个后端开发来协助你,这就是后端集群;再往后,发现前端也忙不过来了,又配备几个前端,就是前端集群。所以也不难看出,将应用拆分后,你可以有针对性地扩展单个服务,做成集群,这就是分布式的好处之一。
节点:这个也非常好理解,一个服务就是一个节点,比如你就是后端集群中的一个节点,而集群本身也可以看成是整个应用的一个集群节点。
副本:副本就是为服务和数据提供的冗余,保证高可用。
中间件:为开发者提供便利,屏蔽复杂的底层的一类框架组件。如服务管理通信、序列化、负载均衡等组件。
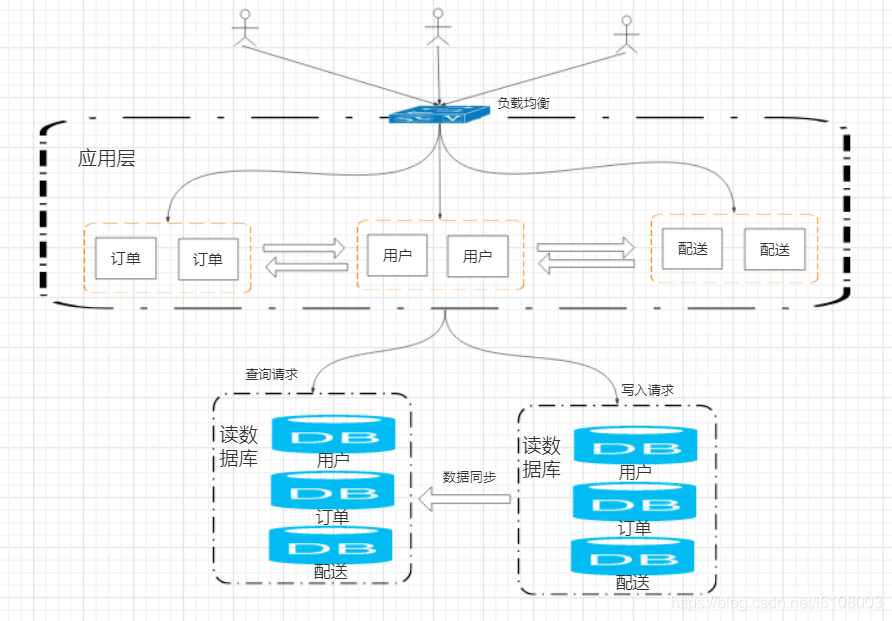
上图就是一个简单的分布式架构,但并不是所有的应用一开始就要设计为分布式架构,因为一开始业务量并不大,没有必要耗费大量的时间和成本去完成一个分布式架构,甚至有可能到最后都用不上,因此在设计时我们应该遵循演进原则,由简入深。下面就来简单分析一下分布式架构的演进过程。
二、分布式架构的演化过程
单机版
以商城为例,为了简单说明,这里就只列出用户、订单、配送服务。
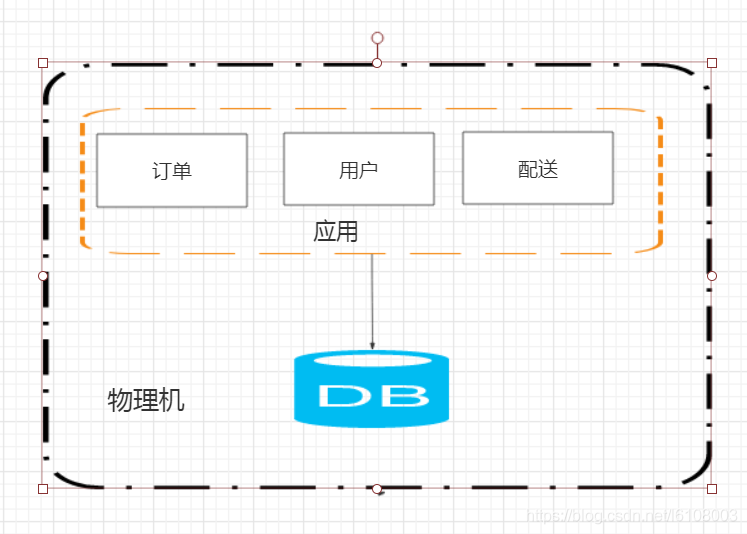
如图,大部分应用最开始都是将应用和数据库放到一台物理机上提供服务,但随着访问量的提升,服务器负载越来越高,我们首先会优化代码、对机器做垂直扩容(内存、容量)等,但单台机器的性能是存在上限的,且对单机扩容的性价比会随着性能的提升越来越低,那我们就会想到增加服务器。
将应用服务器和数据库服务器分离
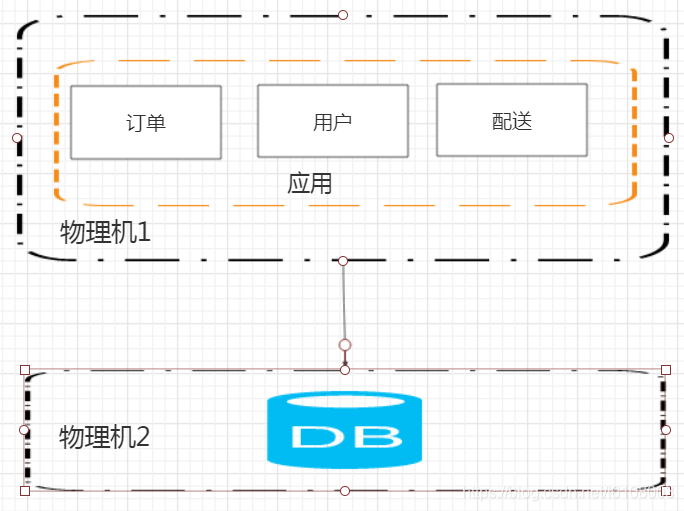
在一开始,我们可能只会增加一台服务器,并将应用和数据库分离:
搭建应用服务器集群
随着访问量的继续增加,单台应用服务器也无法满足需求了,我们就需要搭建应用服务器集群来对外提供服务了
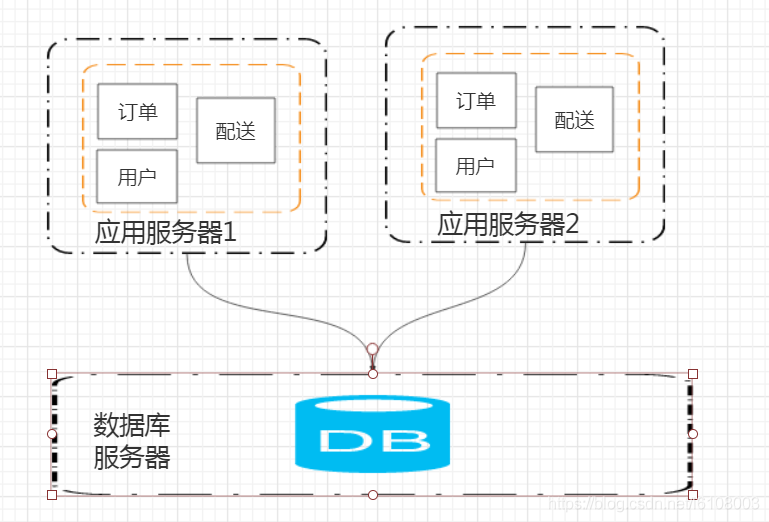
但是,在搭建应用服务器集群之后,问题就出现了,用户在访问时,应该到哪个服务器上去?如何平均服务器压力?以及用户的session如何维护(A首先访问了1号应用服务器并登陆,但下次请求可能是去到2号服务器,但这台服务器上并没有用户的session信息)?
我们可以在用户层和应用层之间加上一个负载均衡器来平衡服务器的负载,session可以采取同步的方式,或者增加单独的session共享服务器。
数据库读写分离
应用层的问题暂时解决了,但是此时数据库又顶不住了。那该如何做呢?只是简单的增加数据库的服务器拉提供存储和访问能力么?那肯定不行,这样数据就不一致了。所以我们需要将数据库分为读库和写库。查询请求都到读库去,而写入请求都到写库去。
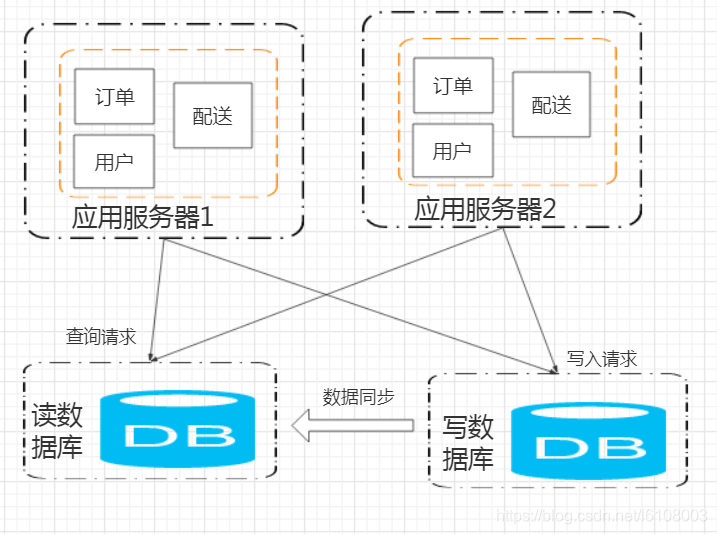
但这样也存在几个问题:
数据如何同步以及同步延迟如何处理?
应用层数据源的选择
大数据查询搜索,可以引入搜索引擎
避免每次访问直接到达数据库,可以引入redis等缓存数据库缓存热点数据
问题看似都解决了,但是每个数据库都存储的是同样的数据,随着业务继续扩大, 我们就不得不考虑对数据库做水平或垂直拆分:
水平拆分:将同一个表中的数据拆分至多个数据库中
垂直拆分:将不同业务的数据放到不同的数据库中

应用拆分
业务继续增长,数据库达到瓶颈时可以继续增加服务器解决,但是应用层呢?也只是单纯的增加服务器么?基于二八原则,其实大部分访问量是集中在20%的功能上的,如果我们只是单纯的增加服务器,那么无疑会浪费掉许多的资源,所以我么会想到能不能针对这20%的应用做扩展呢?当然是可以的,只不过我们需要先将应用拆分为多个子系统(一般是根据业务):
随着应用拆分随之而来的问题是,公用的代码如何处理?各服务之间如何通信?公用代码我们不可能放到每个服务中去,而是应该提出来对外提供服务,同时服务之间的调用可以通过RPC或者HTTP方式来实现。
演化至此,这样的架构就是一个成熟的分布式架构了,但是,架构还是会随着业务和技术的提升不停地演化;而此时你有没有发现这样的一个架构和冯诺伊曼结构很像呢!输入输出设备对应用户和服务之间的输入输出,数据库服务器就像是存储设备,而整个应用层就像是一个CPU(控制器、运算器)。所以,分布式架构可以简单的理解为将多台计算机组成的一台超级计算机。
三、分布式架构的设计
在设计分布式架构时,我们需要了解几个基本的概念。
主流架构模型-SOA和微服务
CAP和BASE理论
DDD(领域驱动设计)
这些理论限于篇幅原因,这里就不展开详述,读者可自行查阅。下面主要来谈谈分布式架构的高可用设计。
分布式架构的高可用设计
在分布式架构中,常常面临的两个矛盾的问题是一致性和高可用,这两个是无法同时满足的,那我们舍谁取谁呢?从用户的角度分析,我们宁可获取到旧数据,也不愿意等半天都打不开应用,所以常常是保证高可用,让数据达到最终一致性,那么如何设计高可用的分布式架构呢?主要从以下几个方面:
搭建服务集群,提高负载,避免单点故障。尤其是特别重要的服务,如访问量较高的服务和核心服务(一旦挂掉就会导致整个应用不可用的服务)。
应对灾难,搭建异地灾备,预防地区因发生地震、台风等自然灾害导致地区的集群服务器都不可用。
接口限流以及服务降级。为防止过高的并发量造成服务器负载过高而出现故障,应对接口限流,同时,当某个或多个服务出现故障时,应当服务降级,避免拖累整个应用。比如支付时因网络故障等导致无法支付,但搜索商品和下单仍然可用。
故障监控报警。
服务的可伸缩性,易于水平扩张服务器数量。
使用缓存降低数据库压力。
使用CDN等加速静态资源的访问。
高可用的分布式架构需要考虑非常多的方面,针对不同的场景有不同的解决方案,而对于不同的公司而言也不需要一应俱全,需要在实践中多思考总结,根据自己的业务情况来设计。
总结
本文从理论层面讲述了分布式的基本概念、演化过程,以及设计,从宏观角度搞清楚分布式的起源以及分布式带来的一系列问题,也就能明白各项技术出现的原因以及应用的场景。
————————————————
版权声明:本文为CSDN博主「夜勿语」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:
https://blog.csdn.net/l6108003/article/details/94835586
锋哥最新SpringCloud分布式电商秒杀课程发布
👇👇👇
👆长按上方微信二维码 2 秒
感谢点赞支持下哈 