
用 Elasticsearch 造个“知网”难不难?
近期“知网”的热度一直不减,本来可以拿一些热点图片、网友评论作为开场。算了,这不是我一个技术博主该做的。
此处仅拿2022年5月24日早晨 6:00 微博搜索“知网”得到的前20条动态信息的词云说话。
 基于 ik_smart 中文分词器的词云图
基于 ik_smart 中文分词器的词云图在网友不建议专家建议的大环境下,作为老百姓对“知网”的建议如下:
1、尊重版权,每篇文档被下载(人工备案下载,非爬虫)获得的收益一半(比例待商榷)费用给第一作者,这会极大的激发大家的创作动力。
2、将文章收益、被引用次数等作为未来文章评价指标。好文章(被引用多、被下载多)会有高收益,不好的文章会石沉大海。这会极大鼓励高校研究人员写好文章。
此处省略1万字......
当然,这些都不是我们平头老百姓该操心的事,作为技术人员,我更关注“知网”的本质——搜索。进一步说根据用户复杂的搜索条件,召回满意的结果。
问题来了,Elasticsearch 三大核心应用场景之一全文检索。用 Elasticsearch 能不能造一个“知网”呢?
这引发了我的极大的兴趣。
1、需求分析
首先,为避免“井底之蛙”,需求降级,降低到自己可控的程度。
天眼查了一下:“知网成立于2004年,共1649人”。得出初步结论,这是有18年技术积累的公司。 版权原因,我们也拿不到知网那么多的数据,只能先象征性的拿手里的文档模拟一下,研究技术的可行性。
其次,“知网”支持的搜索非常复杂,我们只研究“一框”搜索。

把标题检索搞明白了,其他只是时间问题。
再次,“知网”是全网论文的集合体,我们聚焦本地磁盘文件的集合体。
文件类型包含但不限于:.txt, .pdf, .ppt, .doc,.docx 等文档。
综上,为避免落成“螳臂当车”的笑柄,我们把需求转化为简版的“知网”——本地知识库检索系统。
核心功能点如下:
支持多种格式历史文档(pdf、ppt、doc、xls、txt)的解析及索引化。 支持文档基础数据(标题、大小、发布时间、修改时间、作者、全文)的建模。 支持新写入文档数据的解析及索引化,定时周期可配置。 支持建模后的数据存入Elasticsearch,支持通过浏览器访问。 支持kibana可视化分析。
2、技术选型
原则:不重复造轮子,自己可控,使用已有的、成熟的、开源的技术栈体系。
2017 年我带领小伙伴做过类似的知识库检索系统,只不过当时的技术体系较旧,Elasticsearch 也是2.X 版本。
相关技术实现如下两图所示:
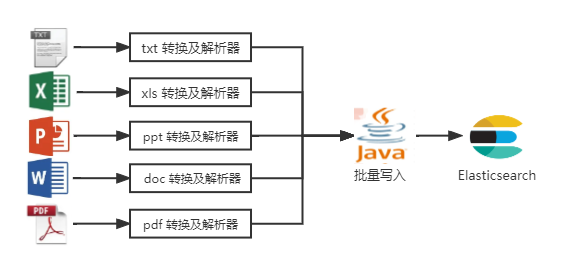
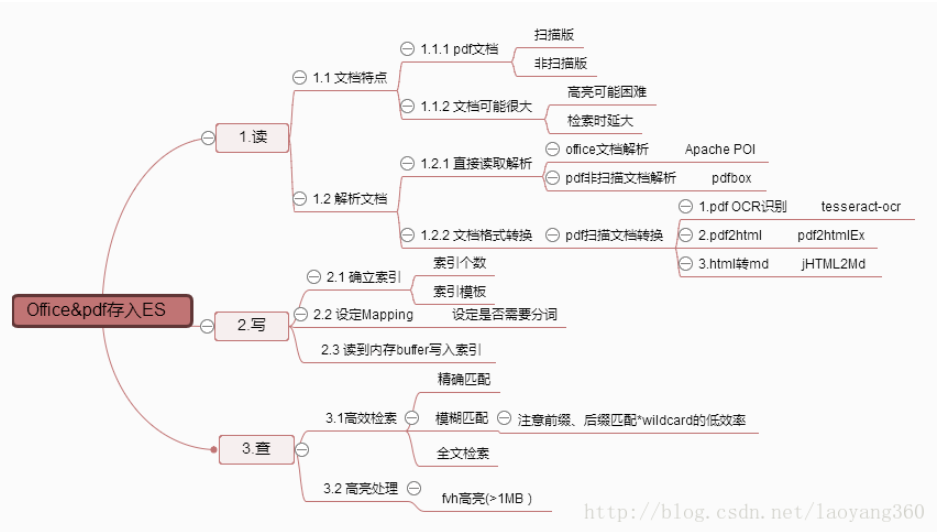
关于文档格式转换及解析器,又会涉及如下 N 多技术栈。
早期的技术实现大半时间都花费在了文档格式转换和解析处理上。有没有更好的实现方式,一直是我关心的问题。从最早的自己找各类解析工具用到了 openoffice 组件,到内容检测和分析框架 Tika,再到 Elasticsearch 自身支持的 Ingest Attachment 文档处理器插件,最终到 Elastic 工程师开源的文档爬虫工具——FSCrawler。
2.1 OpenOffice
相比于闭源的金山WPS、微软Office,OpenOffice 现在已经成为全球领先的跨平台、全功能、多语言、公开对象接口、可扩展文件格式的开源办公软件 。引入相关 jar 包,即可实现文档的解析工作。
http://www.openoffice.org/
2.2 Tika
Apache Tika 用Java编写,用于文件类型检测和从各种格式的文件内容提取的库。
使用Tika可以开发出通用型检测器和内容提取到的不同类型的文件,如电子表格,文本文件,图像,PDF文件甚至多媒体输入格式,在一定程度上提取结构化文本以及元数据。
https://tika.apache.org/
2.3 Ingest Attachment 文件处理器插件
基于 Tika 实现的 Elasticsearch 文件处理插件,支持:PPT、XLS、PDF、WORD 等格式。
需要单独安装实现,安装实现如下:
sudo bin/elasticsearch-plugin install ingest-attachment
https://www.elastic.co/guide/en/elasticsearch/plugins/current/ingest-attachment.html
2.4 FSCrawler 文档爬虫工具
2019-02-25 我在社群给小伙伴推荐过,当时我写了如下的两段话。
应用场景:文件系统检索、中文知识库构建、简化pdf、office等文档解析繁琐步骤,一键导入构建索引实现检索等操作。
使用效果(推荐理由):
1、效果不错,已经集成提卡映射Mapping可定制。 2、集成得非常好。自己写的话:第一步,不同类型解析(pdf还有可能涉及OCR识别)、第二步:定好mapping,第三步:导入。 3、各种配置写得很一目了然,上手快。 4、全部开源,如果有需要可以定制化改代码。 5、支持5.x,6.x,以及还未公布的7.x。(ps现在 7.X、8.X 都已经支持) 6、作者貌似是 Elastic 公司的。
https://github.com/dadoonet/fscrawler
https://t.zsxq.com/02EMR7MRn
诚然,仅从更贴合 Elasticsearch 实现的角度来讲,FSCrawler 是文档分析的“终结者”。它几乎包含了我上面所述两幅图的全部技术实现。
所以,我们选型 FSCrawler 作为文档数据源处理+写入 Elasticsearch 同步工具。
2.5 Python Flask 轻量级 Web 框架
Flask 是目前最流行的 Python Web 框架之一。自 2010 年开源以来,Flask 受到了越来越多的 Python 开发者的喜欢,其受欢迎程度不输于 Django。
Flask 足够轻量,只用 5 行就能写出一个最简单的 Web 程序,但并不简陋,它能适应各类项目的开发。
截止:2022-05-24,GitHub Flask 框架 star 数:59.1k。

下图代表 Google 搜索走势,黄色:springboot,蓝色:django,蓝色:flask。flask 和 django 走势基本一致,受欢迎程度较高。
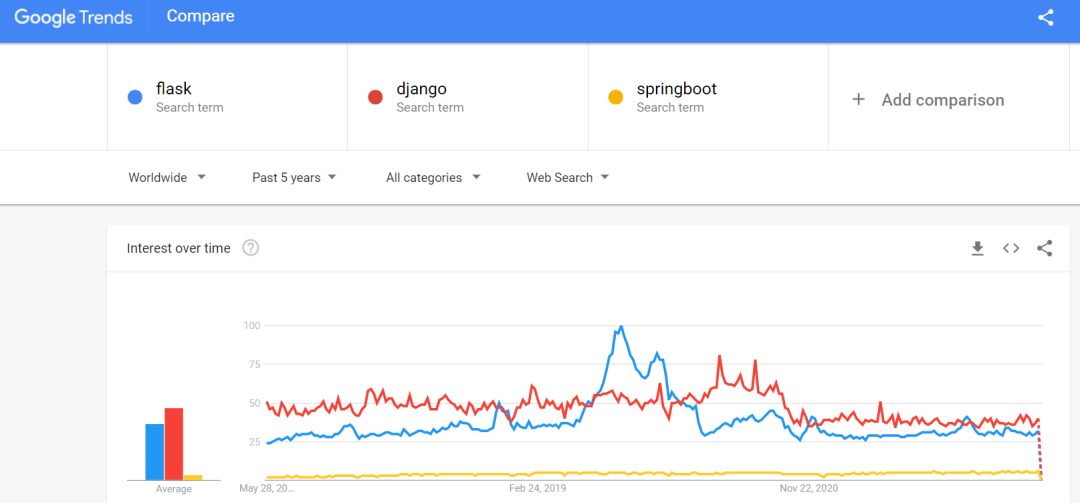
基于此,Web 部分我们选型 Python Flask 框架。
3、 整体架构
基于前面的需求分析和技术选型,整体架构&数据流图如下图所示。
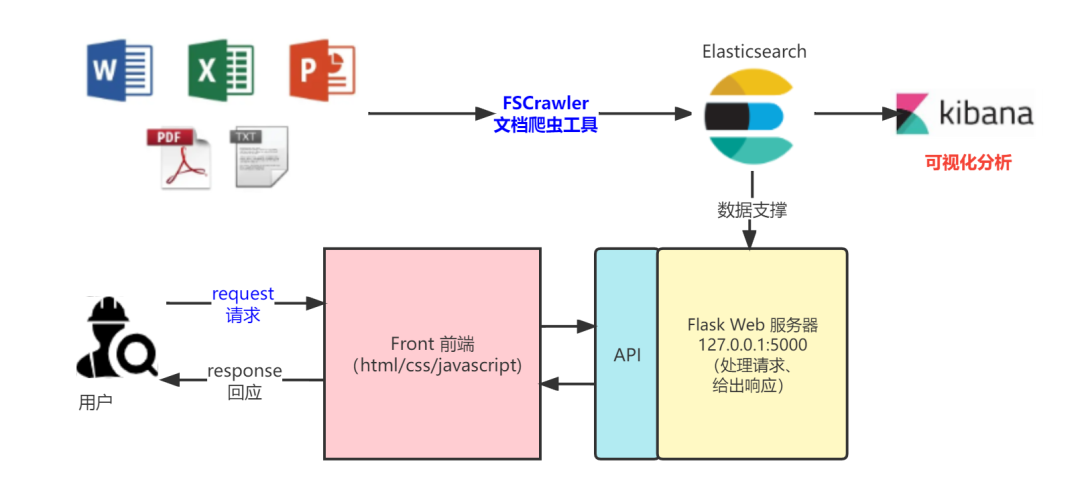
相当于之前的分类型文档解析自己独立实现,FSCrawler 可谓“大包大揽”、“以一敌十”,之前最复杂、最困难的工作全部交由 FSCrawler 完成,包含但不限于:
PDF、DOC、XLS、TXT等文档读取解析 Elasticsearch 数据建模 批量数据同步写入 Elasticsearch 定时同步任务 针对特定图片式样的 PDF 文档,需要OCR 识别实现
有了上面的图,整体就会非常释然,就剩下四个字“干就完了”。
4、 系统实现
直接来个 Gif 动图,看一下实现效果。
相比于之前 java 开发的 web 系统,这次是我全栈实现,涉及到技术包含但不限于:Html、CSS、Javascript、Python、Flask、Elasticsearch、Kibana、FSCrawler。
Html:页面框架。
CSS:页面美化。
JavaScript:动态更新样式的脚本实现。
Python:后端服务接口。
Flask:后端服务框架。
Elasticsearch:数据落地存储。
Kibana:数据可视化分析。
FSCrawler:本地磁盘文档爬虫解析并写入Elasticsearch。
由于足够轻量级,累计核心代码不到 1000 行。
取名为:织网知识库检索系统。此“织网”非彼“知网”。“织”强调的“精耕细作、日积月累、功不唐捐、水滴石穿”。
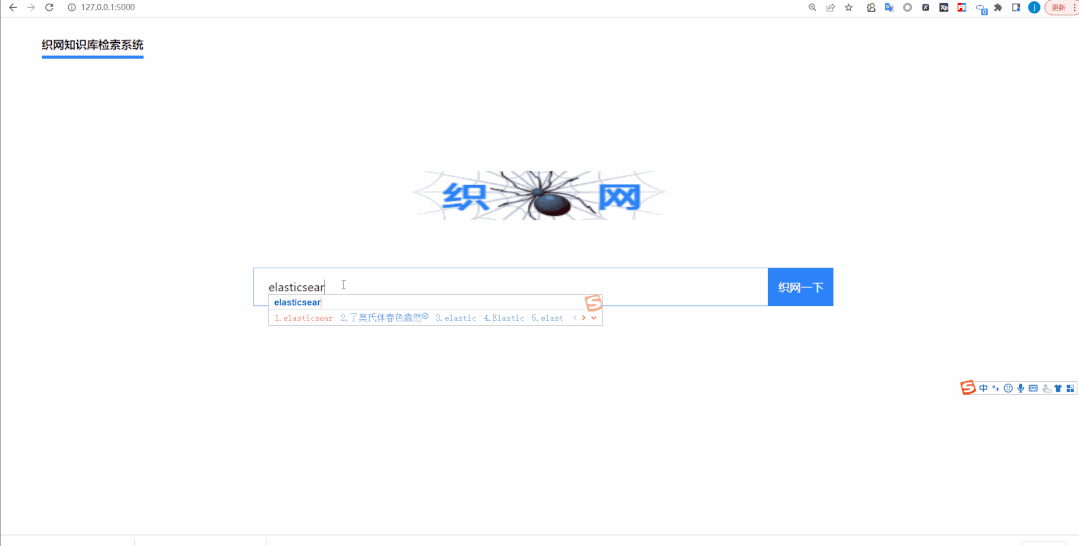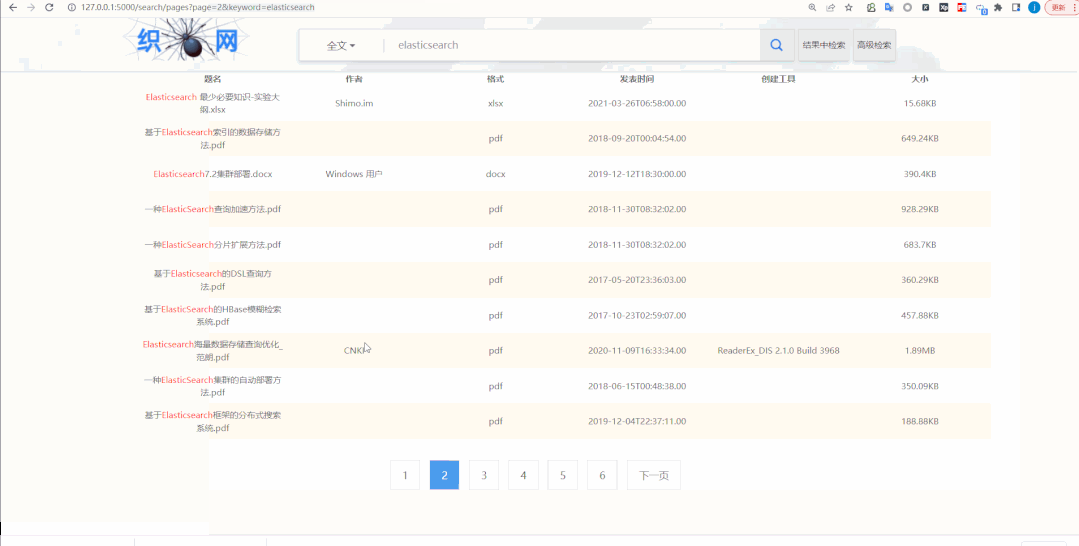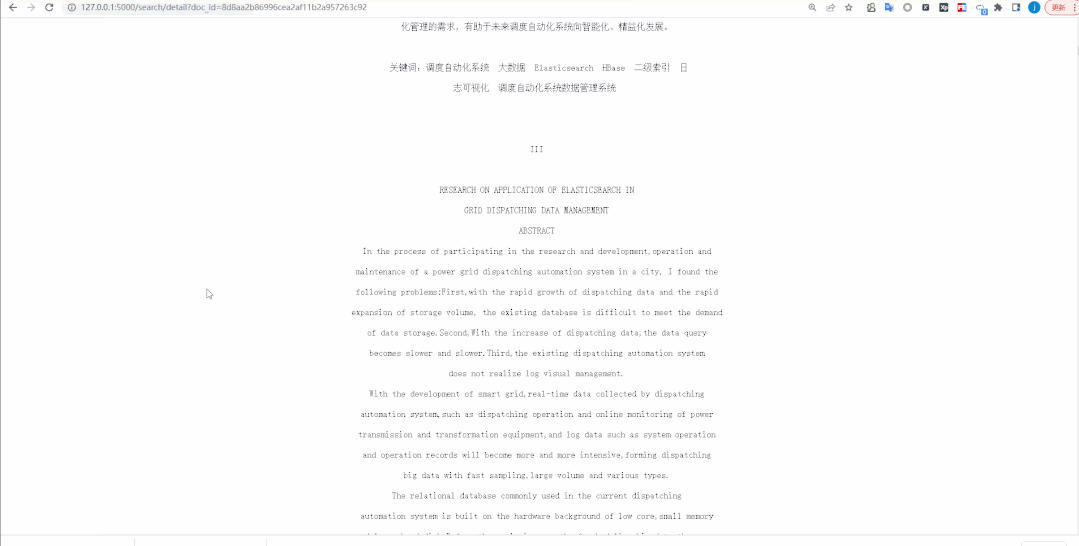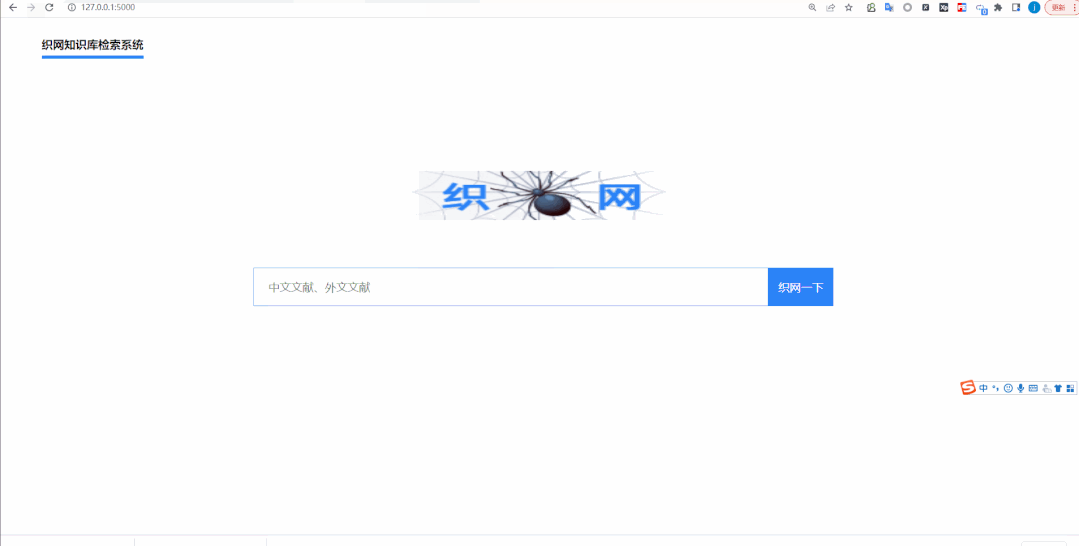
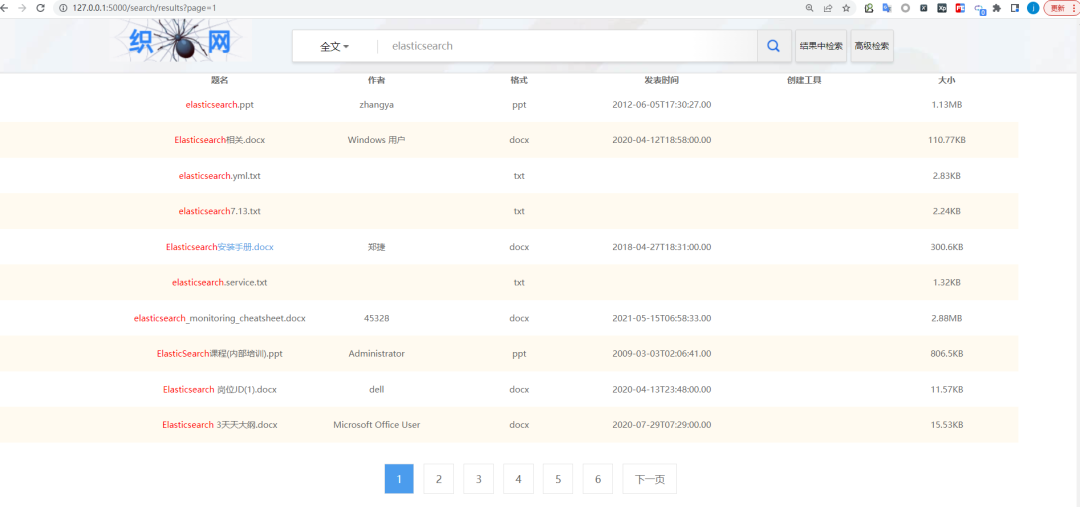

详情页
各位基础稳定数据统计如下:
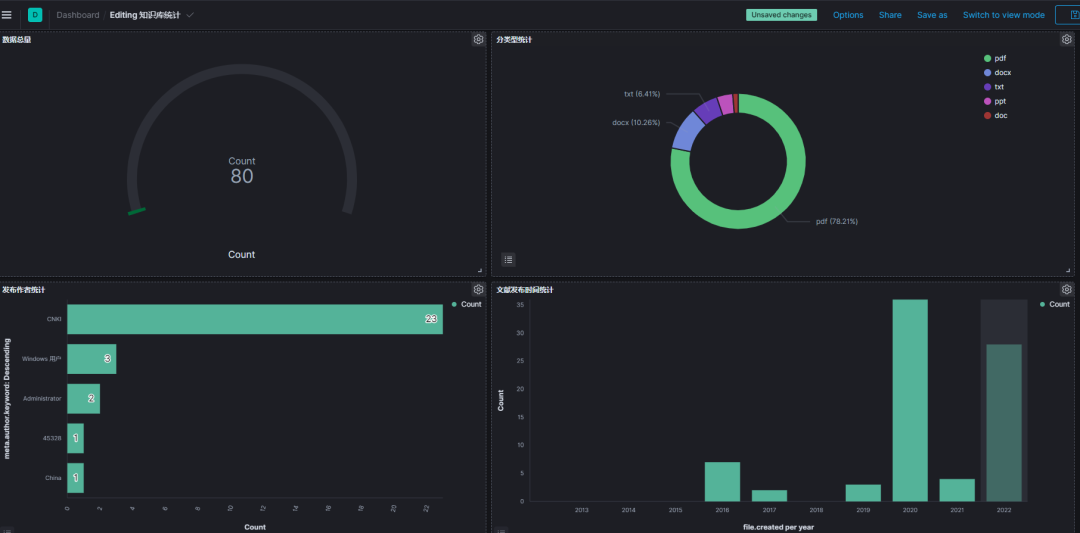
本系统涉及的文档数比较少,但要对 Elastic 充满信心。Elasticsearch 支持动态扩展,支持成千上万、数亿、数十亿只是配置问题和数据量问题,技术层面没有问题。
5、小结
回归文章初心,“知网”是个非常庞大的功能体,仅就检索细节讨论的话,涉及很大一块的内容就是内容分析(分词处理、命名实体识别等 NLP 自然语言处理领域的知识)、以及文档之间的关联性(引用、被引用)等,是不小的工程。
本文是以“知网”的文档检索出发,构建了本地知识库系统,验证了 Elasticsearch 技术栈结合 Python Flask 构建知识库检索系统的可行性。
扫码一起视频聊一聊