
模型监控
共 2536字,需浏览 6分钟
·
2020-09-15 13:58
信用评分模型监控报告可以从观察期间的稳定度(前端监控报告)与表现期间的鉴别度(后端监控报告)两个方面对各项指标进行监控。
目录
一、前端监控报告
1.1 评分分布表(SDR)
1.2 群体稳定度指标(PSI)
1.3 变量稳定度分析
1.4 人工否决分析
1.5 数据输入错误率分析
1.6 产品大事记
二、后端监控报告
2.1 好坏客户评分分布表
2.2 母体鉴别度分析
2.3 变量鉴别度分析
2.4 好坏概率与评分分析
2.5 人工否决表现分析
一、前端监控
前端监控报告可以在模型上线后一个月开始执行,目的是观察申请客户或者近期客户的类型与模型开发样本是否一致,避免客群发生剧烈波动而导致模型失效的情况发生。
评分分布表
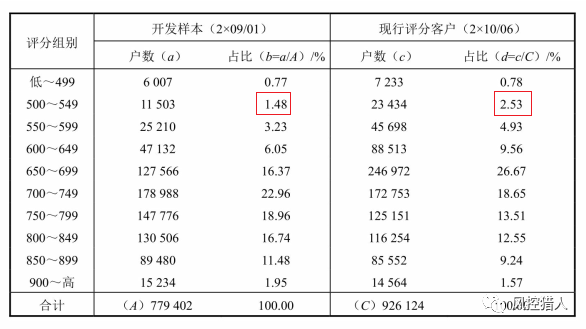
评分分布表是统计各个评分组别的评分客户数及其占全体户数的比率。上图中,开发样本中500-549组别中客户占比为1.48%,而现行客户中此组别占比为2.53%,左右两列对比观察发现“高评分组别占比减少,且客户占比向低评分组别移动”,其具体原因需要根据变量稳定度分析来进行更详细的分析。评分分布表也可以采用条形图的方式,更加直观清晰。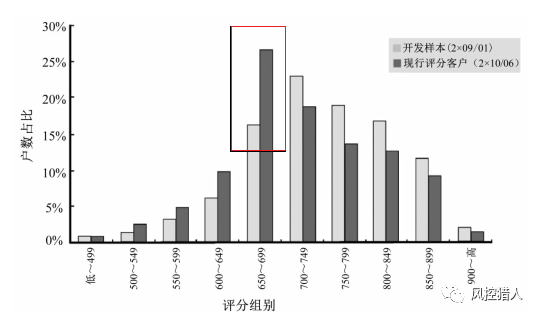
群体稳定度指标(PSI)
群体稳定度指标是用来衡量整体评分卡在开发样本时点与现行评分时点的客户占比的差异程度,PSI越小表示越稳定。一般PSI小于0.1说明群体之间无明显变化,较为稳定;PSI大于0.25说明群体之间有显著变化,需要进行评分模型的调整;介于0.1-0.25之间说明有波动,需要密切观察稳定性。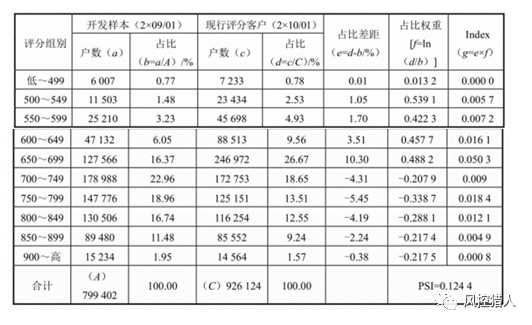
PSI的公式为:
此外还可以每月对PSI进行监控,现行样本就是当月样本,开发样本就是当月之前的所有样本,将个月份的PSI绘制成一条折线,便于观察PSI趋势的变化。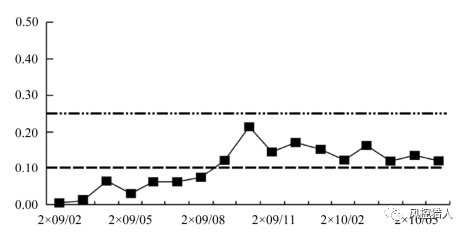
需要注意的是,PSI只显示母体分布是否发生明显波动,并不能表现是往高分组还是低分组移动,需要搭配上面的评分分布表才能够判断变化方向。
变量稳定度分析
母体分布出现波动并不代表模型内所有变量均发生不稳定波动,可以通过变量稳定度分析来确定是什么变量造成母体分布偏移,方法和PSI类似但是公式略有不同。变量分布差距的公式如下:
以学历变量为例: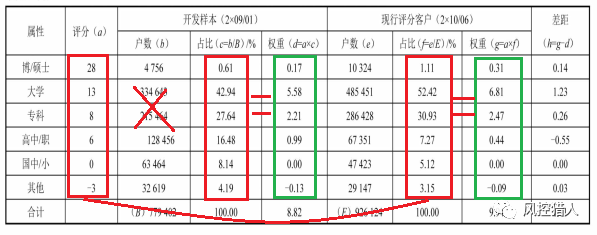
和PSI一样,此变量绝对值越大说明变量分布越不稳定。如果此变量分布差距为正值,说明现行样本与开发样本相比,分布往高分属性移动;如果此变量分布差距为负值,说明现行客户与开发客户相比,分布向低分属性移动。可以参考下面这个额度使用率的例子验证这个属性: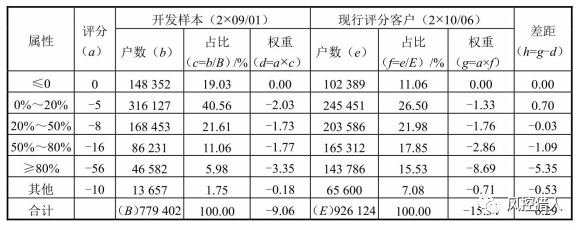
人工否决分析
人工否决分析的目的是监控评分模型与信审人员对于案件风险认知的差距,类似于Swap-Set分析,对临界点附近的案件进行重判,分为高分否决率与低分否决率。
申请评分模型上线前,通常会规范高分否决率与低分否决率的上限。当超过上限时需要与审核人员沟通,避免失去以评分模型作为信用风险决策的目的。
数据输入错误率分析
分为评分错误率(导致错误评分)和关键错误率(导致错误决策)。
产品大事记
所有因评分卡相关政策(如营销活动、目标市场、授信政策、核准点改变)或外部重大事件(法令规章或影响总体经济)需要及时记载并定期维护,便于后续追踪和回溯事件影响。
二、后端监控报告
后端监控报告在模型上线后一段时间(可以为坏客户的延滞月数或表现期长度)开始执行,即需要有样本表现。目的是为了观察评分模型对申请客户或近期客户群体是都仍具备鉴别力。
即前端监控报告监控稳定度,后端监控报告监控区分度。其维度都是开发样本和现行样本。
好坏客户评分分布表
同前端监控中的评分分布表,好坏客户也有相应的评分分布,其目的是为了展示出好坏客户评分的差异情况。不同于前端监控(不同时点、全体客群)的是,后端监控中的样本是同一观察时期的样本,即相同时点不同表现。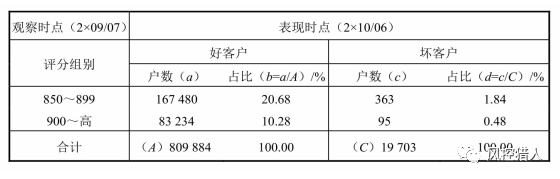
画成评分分布图更加直观: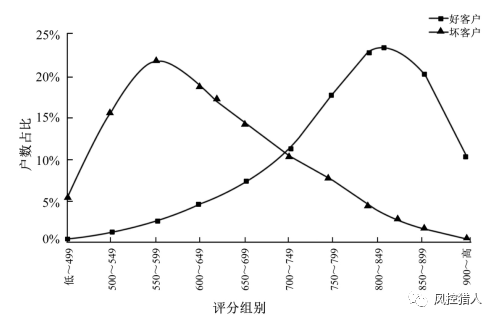
母体鉴别度(KS/Gini)
不再展开介绍。
变量鉴别度分析(IV)
不再展开介绍。
好坏概率与评分分析
好坏概率的计算方式是各评分组别的好客户数除以坏客户数,这个指标应该随着评分的升高而增加,具有鉴别力的模型应呈现出高评分组有较多的好客户(好坏比高),低评分组有较多的坏客户(好坏比低)。由于评分模型一般需要经过风险校准,所以相邻的评分组别的好坏概率应大致呈倍数增加变化。如果直接画出好坏概率和评分组别变化关系的图,会出现如下情况: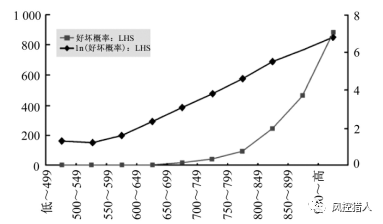
由于各组别的好坏概率呈倍数增长,导致最高评分组好坏概率过大,进而影响到低分组的判别情况。故采用将好坏概率取自然对数的方式来作为另一种观察指标,如下图: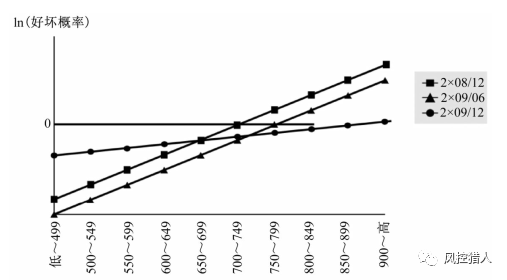
各评分组别的ln(好坏概率)相连接后会接近一条直线,此直线越陡峭说明评分模型的好坏概率差别越大,区分度越高。
图中还出现两条平行直线,这说明这两个时期模型的区分度相近,不同的是同一评分组别下,2x09/06所对应的好坏比率较低,此时可以通过上调授信政策的临界点来达到与之前相同的效果。
人工否决表现分析
和前端监控中的人工否决表现分析,若人为判断过于频繁,会造成评分模型效益下降或整体资产质量不如预期,因此需要定期检视审核人员和模型对于风险的判断是否一致。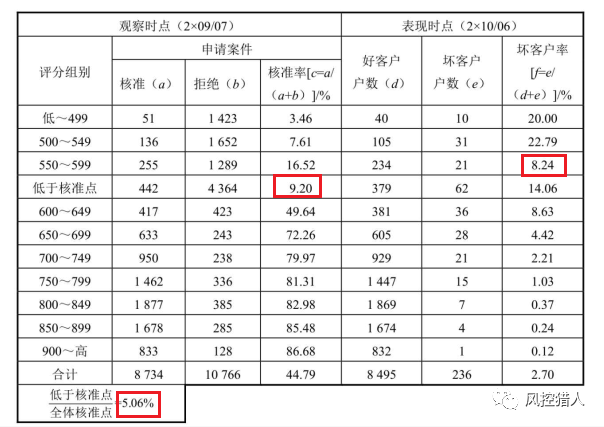
应用评分模型作为决策方式时,通常会为下列两项指标设定上限,以避免人为干预过深:
1.低于核准点案件的核准率:表9-13中的9.20%[442/(442+4364)×100%]。
2.低于核准点案件占全体核准件的核准率:表9-13中的5.06%[442/8734×100%]。
上图中550-599评分的坏客户率为8.24%,低于600-649分组,这是因为低于核准点的案件会经过审核员的核对与评估,因此风险可能更低。
总结:持续有效的信用评分模型需建立在稳定度与鉴别度验证的基础上,定期对评分卡模型的表现进行监控,以保证模型的各项性能不会出现恶化,对风控模型不稳定时追溯定位原因具有重要意义。