
12张图,二手房数据分析及可视化
回复“书籍”即可获赠Python从入门到进阶共10本电子书
写在前面
本文用到的数据是之前在链家爬取的武汉二手房信息。这次我们来挖掘一下数据背后的秘密...
「文中主要涉及的Python库」:
pandas:读取 csv 文件中的内容,并对数据进行处理。matplotlib:它是基于 numpy 的一套 Python 工具包。这个包提供了丰富的数据绘图工具,主要用于绘制一些统计图形。seaborn:seaborn 是基于 matplotlib 的图形可视化 python 包。是在 matplotlib 的基础上进行了更高级的 API 封装,使作图更加容易,相比于 matplotlib 中的一些图用 seaborn 做会更具有吸引力,但特色方面(绘图细节)不及 matplotlib 。一般将 seaborn 视为 matplotlib 的补充,而不是替代物。同时它能高度兼容 numpy 与 pandas 数据结构以及 scipy 与 statsmodels 等统计模式(后文中会体会到兼容 pandas 的好处的)。pyecharts:pyecharts 是一个用于生成 Echarts 图表的类库。Echarts 是百度开源的一个数据可视化 JS 库。一般用它来绘制动态图,可视化效果非常好。jieba:一款非常流行的中文分词包。主要有三种分词模式全模式、精确模式(本文使用)、搜索引擎模式。在分词前可以添加自定义词典来提升分词的准确率。collections:主要使用 Counter 类,统计各值出现的次数。
话不多说,进入正题。
1.数据读取
首先读取 house_info.csv 文件,并查看数据集的结构信息。
import pandas as pd
df = pd.read_csv('house_info.csv')
df.info()
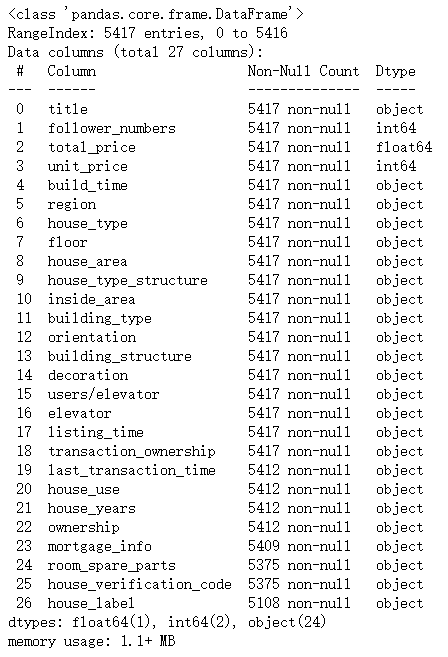 根据上面的信息可以知道,数据集共 27 列,
根据上面的信息可以知道,数据集共 27 列,house_label 列中有较多的缺失值, floor 列和 house_area 的类型为 object 应将转成数值类型。
2.数据预处理
2.1缺失值处理
首先删除包含缺失值的行。删除后数据行数为 5108 行。
df.dropna(inplace=True)
df.reset_index(drop=True, inplace=True)
2.2列处理
由于后面需要通过 pyecharts 绘制地图,而 东湖高新区,沌口开发区 并未有详细经纬度划分,故根据大致地理位置,将其分别归属为 洪山区和汉南区 。
「处理内容」
提取 floor楼层中的数字将房价面积由 “85.99m²”-->“85.99” 将东湖高新划分到洪山,沌口开发区划分到汉南
# 提取floor楼层中的数字
df['floor'] = df['floor'].str.extract(r'(\d+)', expand=False).astype('int')
# 将房价面积由“85.99m²”-->“85.99”
df['house_area'] = df['house_area'].apply(lambda x: x[:-1]).astype('float')
# 将东湖高新划分到洪山,沌口开发区划分到汉南
df.loc[df['region'] == '东湖高新', 'region'] = '洪山'
df.loc[df['region'] == '沌口开发区', 'region'] = '汉南'
# 将region列中值后添加“区”,如“汉阳”-->“汉阳区”
df['region'] = df['region'] + '区'
通过 describe() 函数查看数值列的属性描述。如果查看全部列可以将参数 include 指定为 all (默认为 None )。
df.describe()
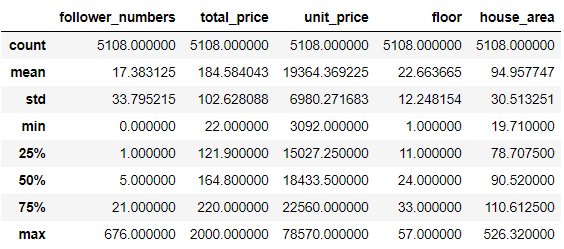 图中显示武汉二手房平均关注人数为 17 人,平均总价 184 万,平均单价 19364 元/m²,平均楼层 22 层,平均房屋面积 95 m²。另还有标准差、最小值、四分之一分位数、二分之一分位数、四分之三分位数、最大值等信息。
图中显示武汉二手房平均关注人数为 17 人,平均总价 184 万,平均单价 19364 元/m²,平均楼层 22 层,平均房屋面积 95 m²。另还有标准差、最小值、四分之一分位数、二分之一分位数、四分之三分位数、最大值等信息。
3.各区二手房数量条形图
获取数据中各区信息和对应区的房屋数量,绘制条形图。
import pyecharts.options as opts
from pyecharts.charts import Bar
from pyecharts.globals import ThemeType
region_list = df['region'].value_counts().index.tolist()
house_count_list = df['region'].value_counts().values.tolist()
c = Bar(init_opts=opts.InitOpts(theme=ThemeType.CHALK)
c.add_xaxis(region_list)
c.add_yaxis("武汉市", house_count_list)
c.set_global_opts(title_opts=opts.TitleOpts(title="武汉各区二手房数量柱状图", subtitle=""),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(interval=0)))
# c.render("武汉各区二手房数量柱状图.html")
c.render_notebook()
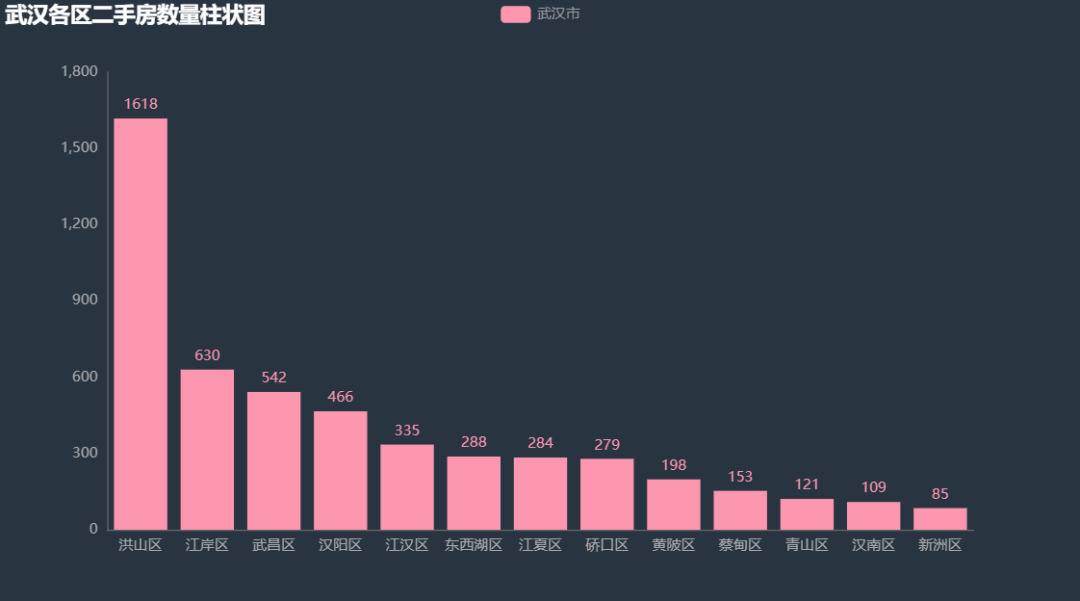 尽管洪山区是将东湖高新区合并后统计的,但合并前二者二手房数量同样很多,其次为江岸区,江景独美。下面我们通过 「2D地图」 和 「3D地图」 的形式看各区房价在地图上的分布。
尽管洪山区是将东湖高新区合并后统计的,但合并前二者二手房数量同样很多,其次为江岸区,江景独美。下面我们通过 「2D地图」 和 「3D地图」 的形式看各区房价在地图上的分布。
4.各区房价分布2D地图
统计各区名称及对应的单价中位数(中位数受极值的影响很小)。加载本地的武汉市地图数据(各区经纬度信息)。绘制房价分布 2D 地图。
region_list = df['region'].value_counts().index.tolist()
median_unit_price = []
for region in region_list:
median_unit_price.append(df.loc[df['region'] == region, 'unit_price'].median())
# 绘制2D地图
from pyecharts.charts import Map
# 加载武汉市地图数据
json_data = json.load(open('武汉市.json', encoding='utf-8'))
data_pair = [list(z) for z in zip(region_list, median_unit_price)]
text_style = opts.TextStyleOpts(color='#fff')
c = Map(init_opts=opts.InitOpts(width='1500px', height='700px', bg_color='#404a58'))
c.add_js_funcs("echarts.registerMap('武汉市',{});".format(json_data))
c.add(series_name="武汉市", data_pair=data_pair, maptype="武汉市", label_opts=opts.LabelOpts(color='#fff'))
c.set_global_opts(legend_opts=opts.LegendOpts(textstyle_opts=text_style),
title_opts=opts.TitleOpts(title="武汉", title_textstyle_opts=text_style)
,visualmap_opts=opts.VisualMapOpts(split_number=6, max_=30000, range_text=['高', '低'],
textstyle_opts=text_style))
# c.render("武汉市各区房价分布2D图.html")
c.render_notebook()
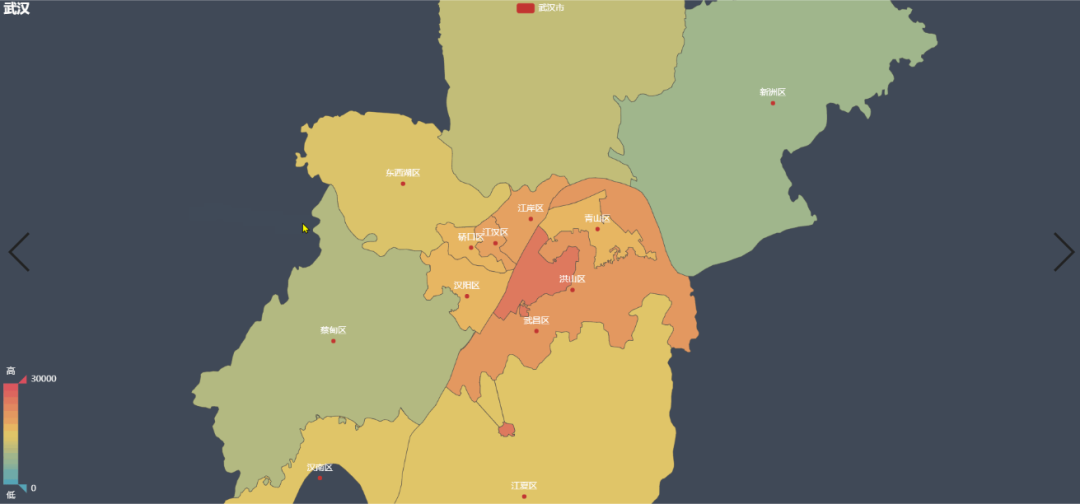
根据地图的信息,房价较高的区域集中在武汉市中心区域,以武昌区为首房价单价为 24600 元/m²。其余中心城市房价也均在 15000 元/m²以上。最低房价为新洲区,房价中位数为 7806 元/m²。下面通过3D地图来观察一下。
5.各区房价分布3D地图
所需要的数据与2D地图相同,代码较多这里就不在这里展示了(需要的朋友在文末获取)。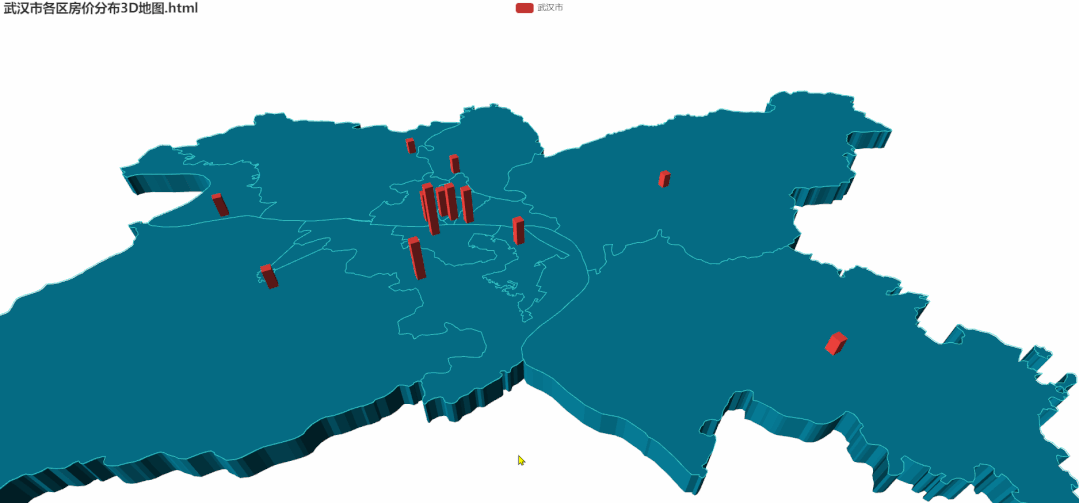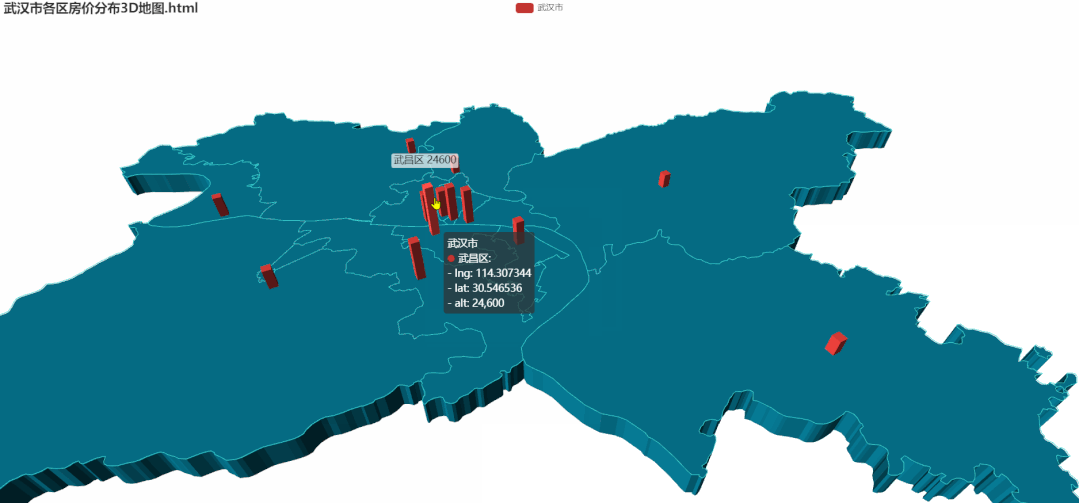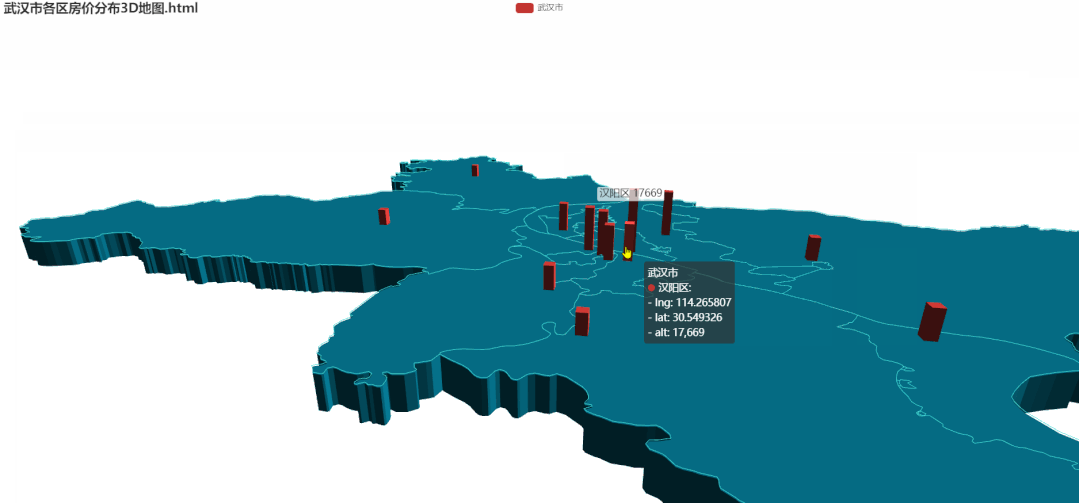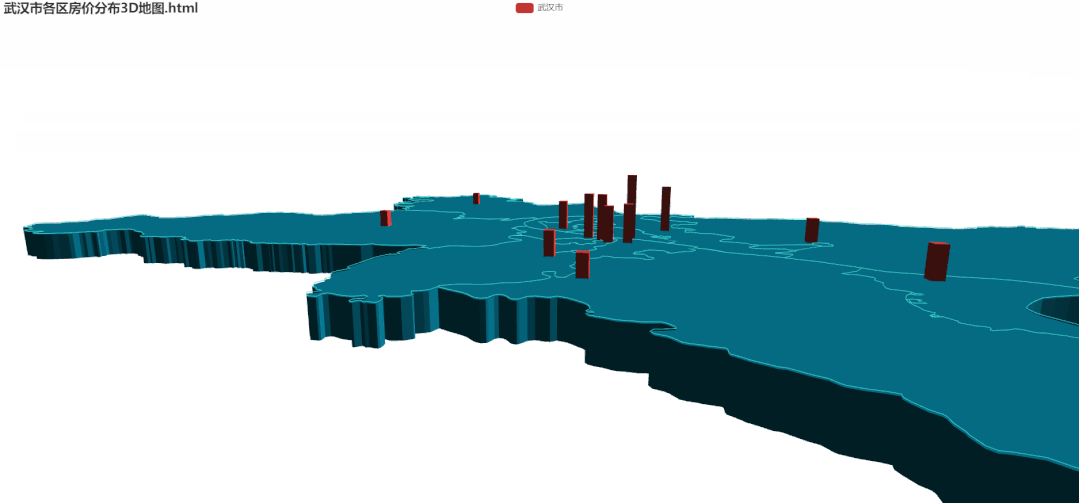 相比于2D,3D图中的各区房价差异会更加明显。看着也比较 NB!!接下来通过箱型图详细看一下各区单价的异常值。
相比于2D,3D图中的各区房价差异会更加明显。看着也比较 NB!!接下来通过箱型图详细看一下各区单价的异常值。
6.各区二手房单价箱型图
统计各区名称信息及对应单价信息,并绘制箱型图。
# 统计各个区二手房单价信息
unit_price_list = []
for region in region_list:
unit_price_list.append(df.loc[df['region'] == region, 'unit_price'].values.tolist())
# 绘制箱型图
from pyecharts.charts import Boxplot
c = Boxplot(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
c.add_xaxis(region_list)
c.add_yaxis("武汉市", c.prepare_data(unit_price_list))
c.set_global_opts(title_opts=opts.TitleOpts(title="武汉各区二手房总价箱型图"),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(interval=0)))
# c.render("boxplot_base.html")
c.render_notebook()
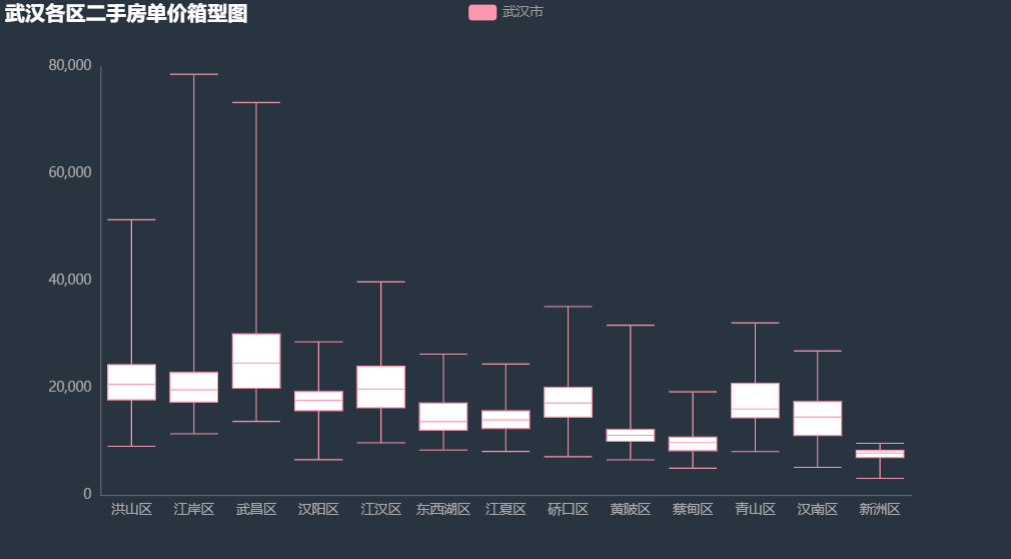
pyecharts 中的箱型图的上下边界为最大值最小值,与标准箱型图中的最大观察值,最小观察值不同。我们根据上四分位数和下四分位数的分布,可以看出洪山区、江岸区、武昌区这些房价较高的区域成典型的 「右偏态」 (异常值集中在较大值的一侧,尾部很长)。这说明很多二手房的价格可能因为地段,装修等原因,单价严重偏离当地房价平均水平。
7.二手房面积分布与价格关系图
由于 pyecharts 中的散点图不太方便绘制趋势线,我们直接使用 seaborn 来绘制,二手房面积分布及面积与价格的相关性。
import matplotlib.pyplot as plt
import seaborn as sns
f, [ax1,ax2] = plt.subplots(1, 2, figsize=(16, 6))
# 房屋面积
sns.distplot(df['house_area'], ax=ax1, color='r')
sns.kdeplot(df['house_area'], shade=True, ax=ax1)
ax1.set_xlabel('面积')
# 房屋面积和价格的关系
sns.regplot(x='house_area', y='total_price', data=df, ax=ax2)
ax2.set_xlabel('面积')
ax2.set_ylabel('总价')
plt.show()
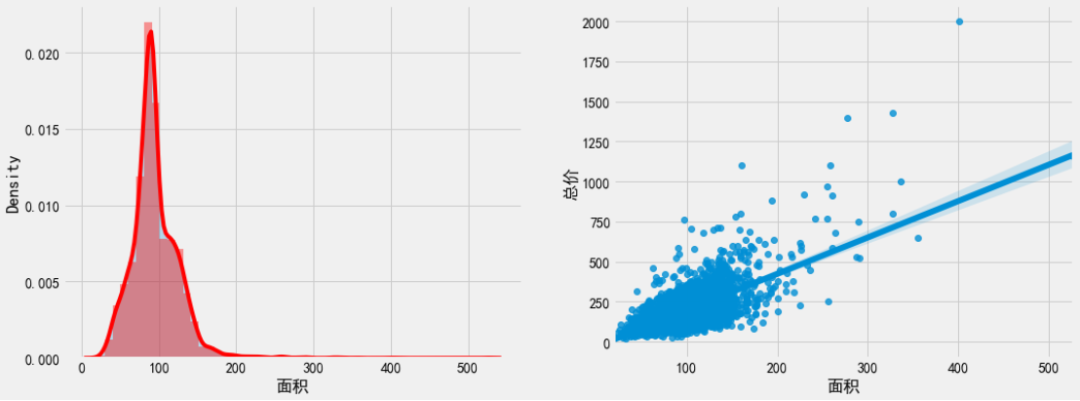 二手房面积主要分布在60 - 130m²之间。最吸引人的还是面积 400m² ,总价 2000 万的那个点,鹤立鸡群。
二手房面积主要分布在60 - 130m²之间。最吸引人的还是面积 400m² ,总价 2000 万的那个点,鹤立鸡群。
8.楼层与房价分布3D条形图
我们现在看看各区的楼层和房价之间关系,听说武汉傍晚江景很美,那高层楼的价格应该要高一些。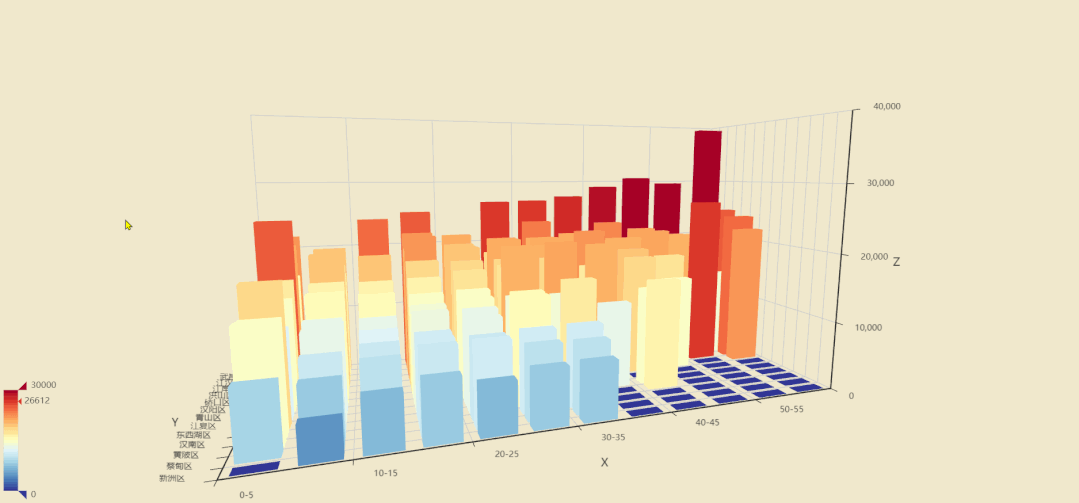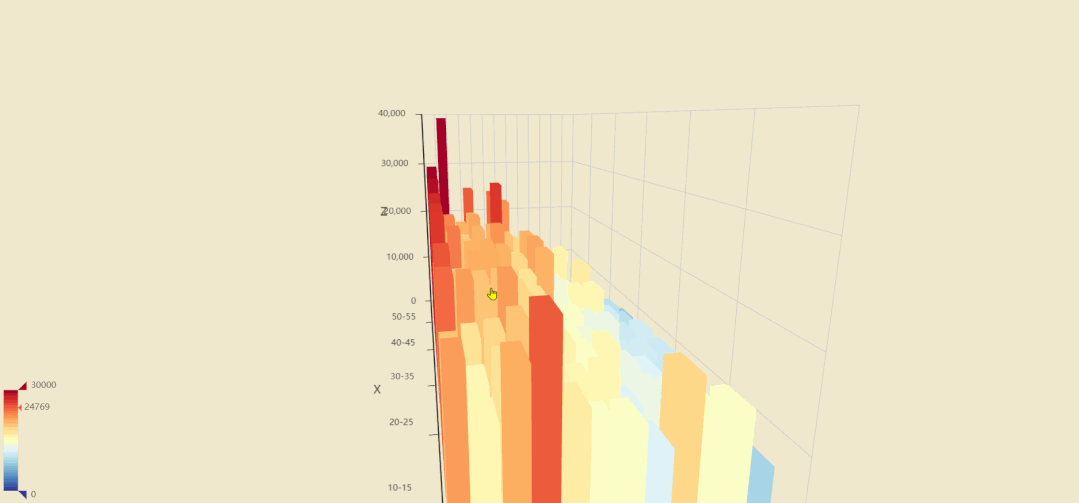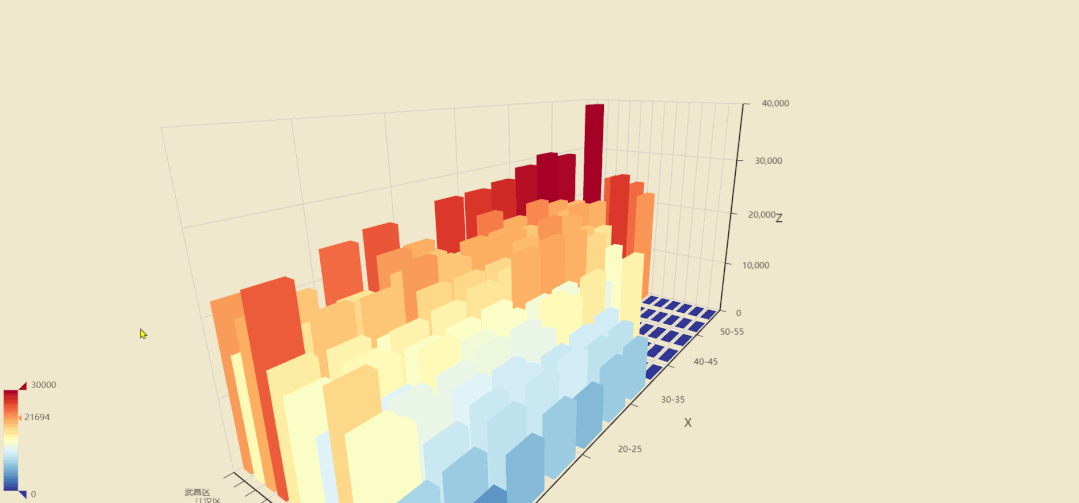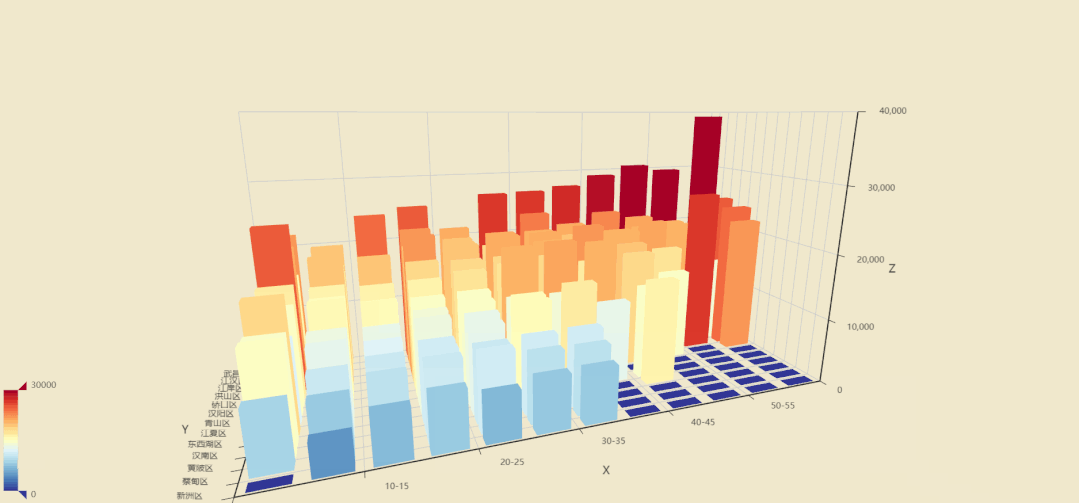
图中各轴含义
X轴:楼层,以5层为间隔范围 Y轴:各区名称 Z轴:单价
其他地区可能各楼层价格差异不大,但最突出的武昌区,江汉区,由于第二大城中湖东湖和临江的优势,让他们的高层房价普遍高于底层。
9.各户型横向条形图
统计户型的种类和各种类的名称,绘制横向条形图。
series = df['house_type'].value_counts()
series.sort_index(ascending=False, inplace=True)
house_type_list = series.index.tolist()
count_list = series.values.tolist()
c = Bar(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
c.add_xaxis(house_type_list)
c.add_yaxis("武汉市", count_list)
c.reversal_axis()
c.set_series_opts(label_opts=opts.LabelOpts(position="right"))
c.set_global_opts(title_opts=opts.TitleOpts(title="武汉二手房各户型横向条形图"),
datazoom_opts=[opts.DataZoomOpts(yaxis_index=0, type_="slider", orient="vertical")],)
# c.render("武汉二手房各户型横向条形图.html")
c.render_notebook()
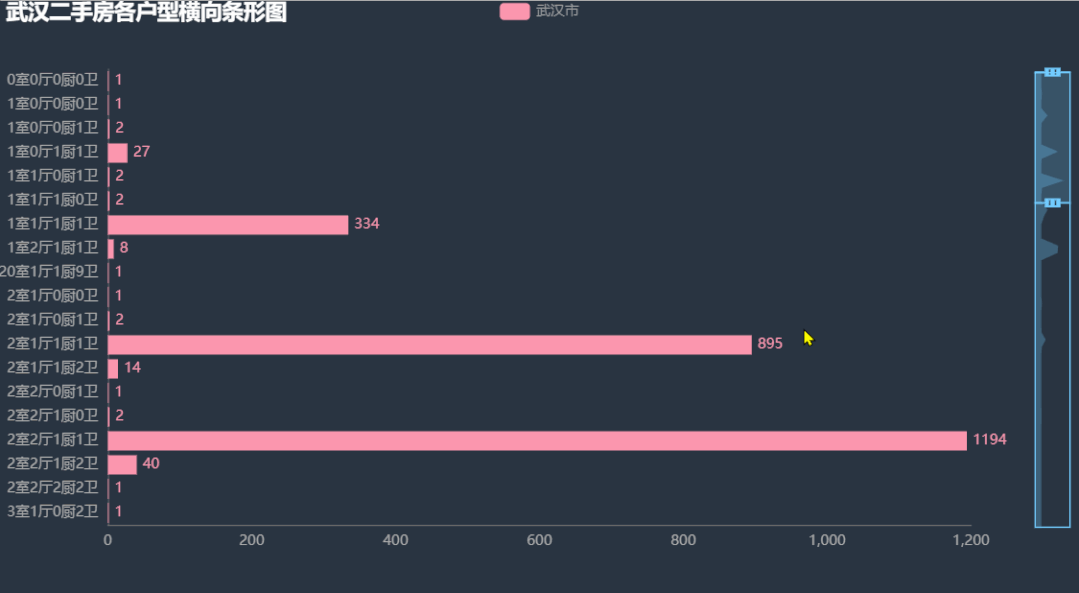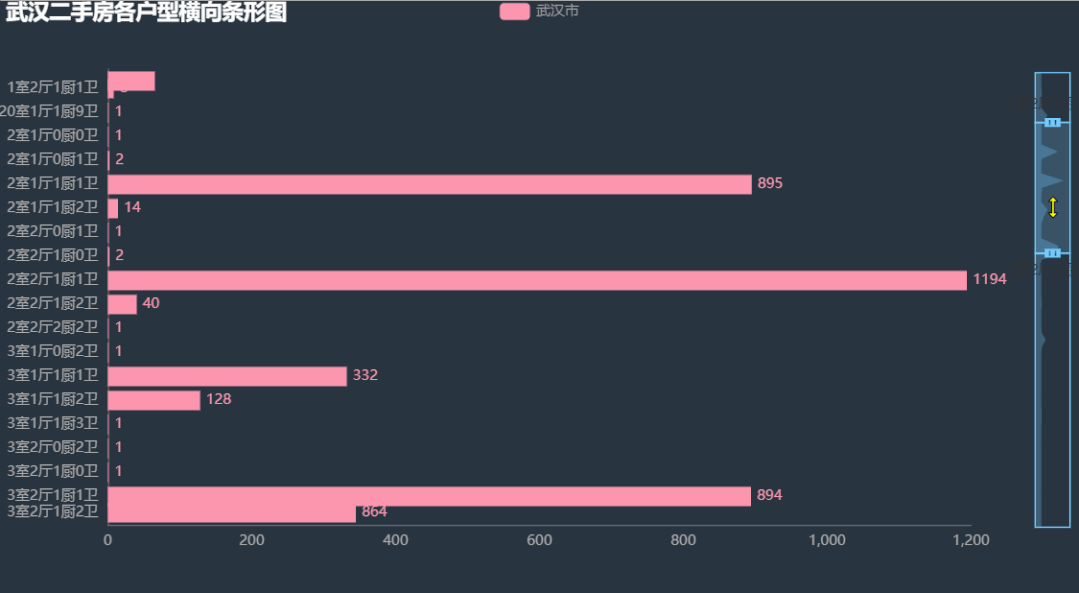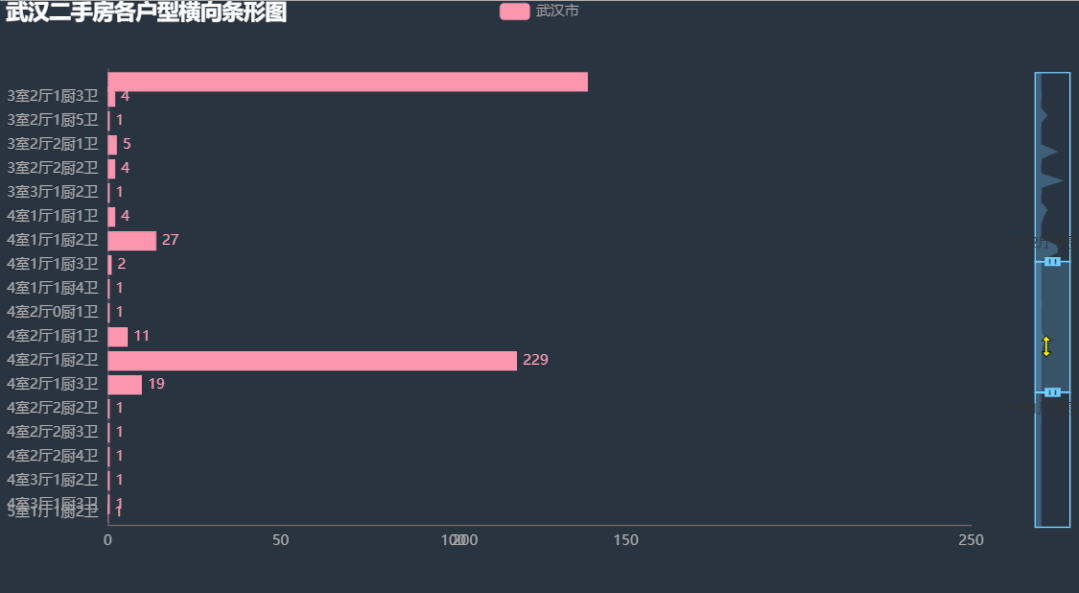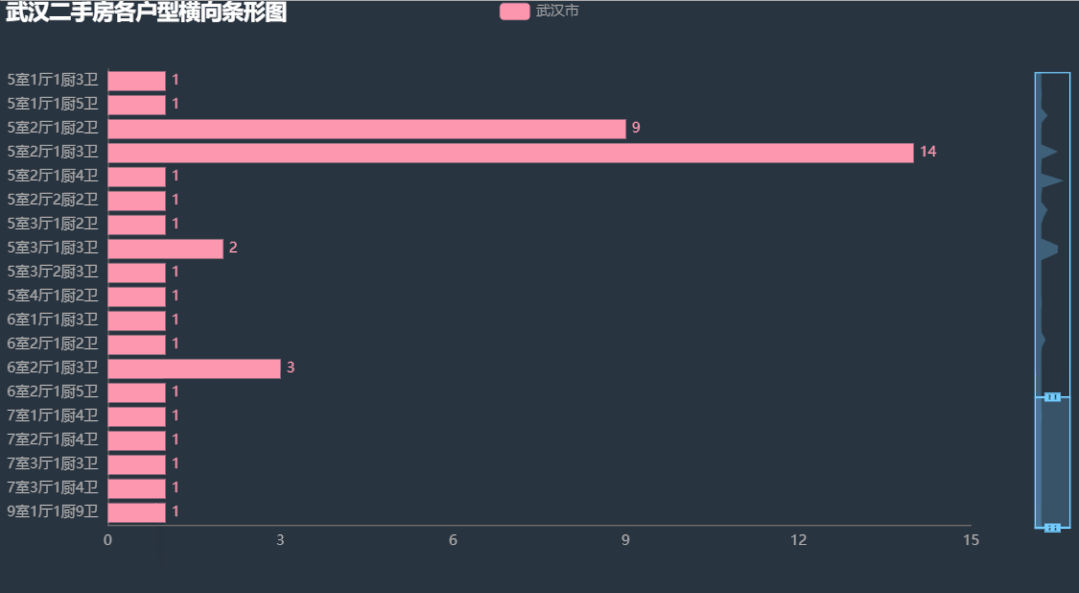 可以看到主要的房型有 「一室一厅一厨一卫」、「两室一厅一厨一卫」、「两室两厅一厨一卫」、「三室一厅一厨一卫」、「三室两厅一厨一卫」、「三室两厅一厨两卫」、「四室一厅一厨两卫」。其中最多的是 「两室两厅一厨一卫」,这也比较符合大多数人年轻人的要求。大的买不起,小的住不下。。
可以看到主要的房型有 「一室一厅一厨一卫」、「两室一厅一厨一卫」、「两室两厅一厨一卫」、「三室一厅一厨一卫」、「三室两厅一厨一卫」、「三室两厅一厨两卫」、「四室一厅一厨两卫」。其中最多的是 「两室两厅一厨一卫」,这也比较符合大多数人年轻人的要求。大的买不起,小的住不下。。
10.房屋装修程度饼状图
现在看看二手房房屋装修的情况,一般二手房的话猜测毛坯应该不多。看看实际情况如何,统计装修的种类和各种类的数量,绘制饼状图。
decoration_list = df['decoration'].value_counts().index.tolist()
count_list = df['decoration'].value_counts().values.tolist()
from pyecharts.charts import Pie
c = Pie(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
c.add(series_name="房屋装修",
data_pair=[list(z) for z in zip(decoration_list, count_list)],
rosetype="radius",
radius="55%",
center=["50%", "50%"],
label_opts=opts.LabelOpts(is_show=False, position="center"))
c.set_global_opts(title_opts=opts.TitleOpts(
title="武汉二手房房屋装修饼状图",
pos_left="center",
pos_top="20",
title_textstyle_opts=opts.TextStyleOpts(color="#fff")),
legend_opts=opts.LegendOpts(is_show=False))
c.set_series_opts(tooltip_opts=opts.TooltipOpts(trigger="item", formatter="{a}
{b}: {c} ({d}%)"),
label_opts=opts.LabelOpts(color="rgba(255, 255, 255, 255)"))
# c.render("customized_pie.html")
c.render_notebook()
 根据图中信息超过一般的二手房是精装,毕竟之前住过人的,再简单装修一下,以更高的价格转手肯定还是很香的,将近 25% 的二手房是简装,剩余少量为其他装修类型和毛坯。毛坯二手房确实数量不多,和预料的差不多。
根据图中信息超过一般的二手房是精装,毕竟之前住过人的,再简单装修一下,以更高的价格转手肯定还是很香的,将近 25% 的二手房是简装,剩余少量为其他装修类型和毛坯。毛坯二手房确实数量不多,和预料的差不多。
11.有无电梯与房价关系图
下面我们看看各区二手房有无电梯数量比例,有无电梯的房屋单价有无差距。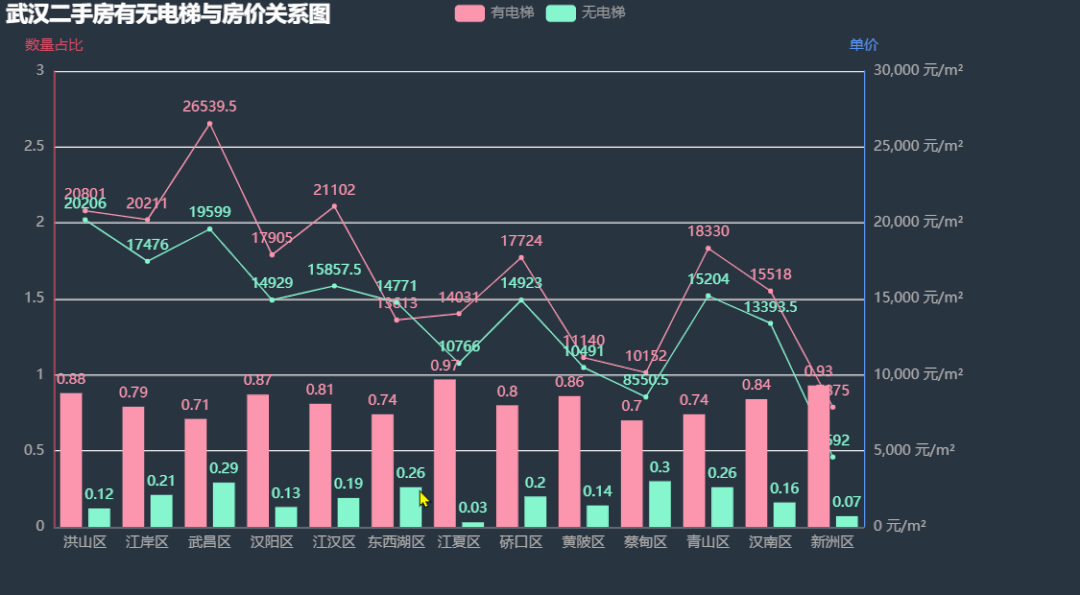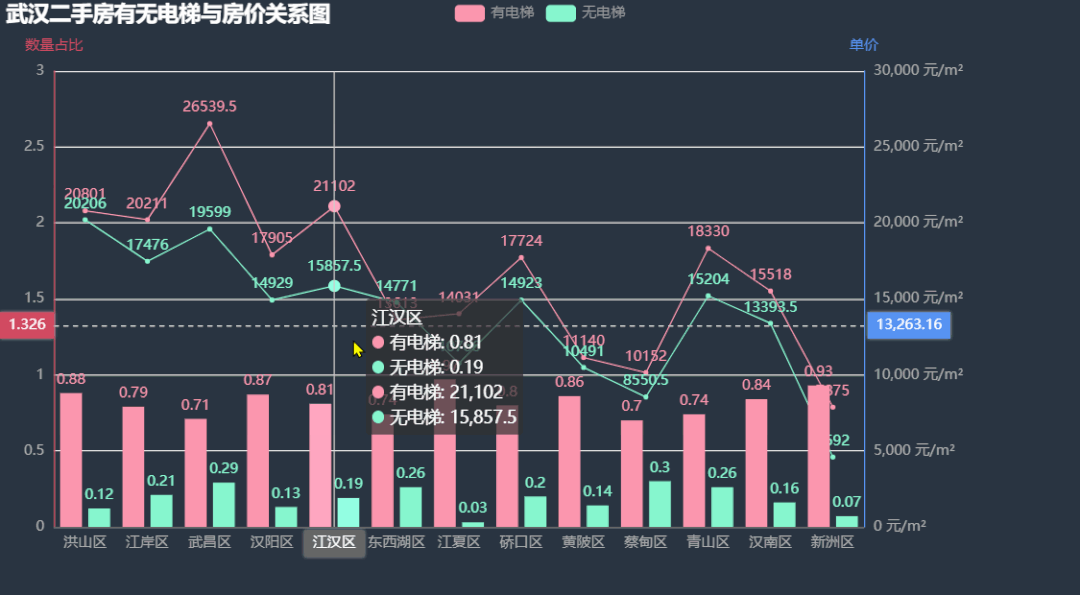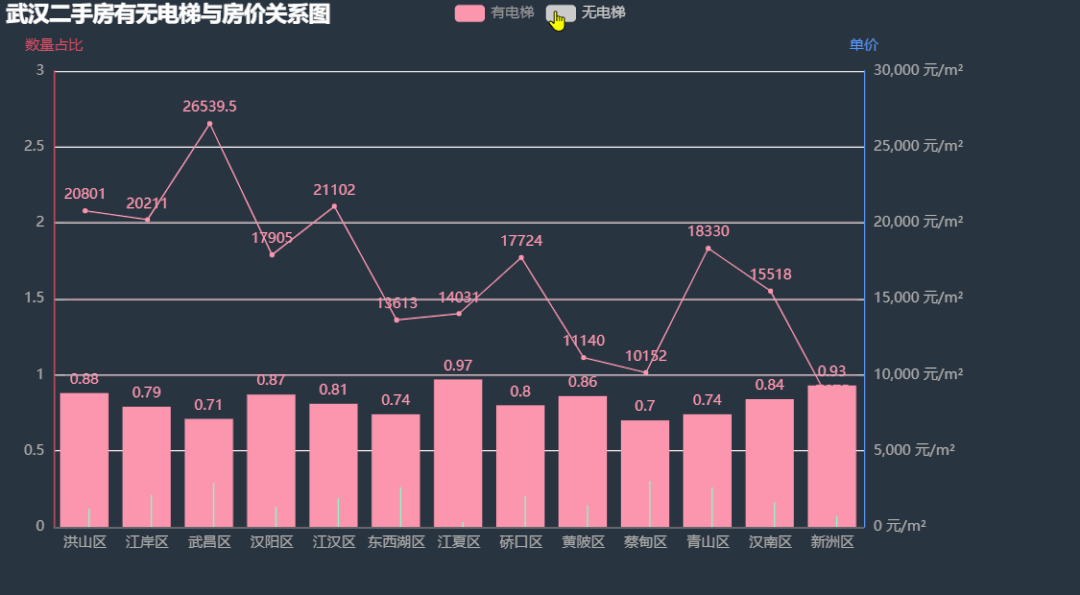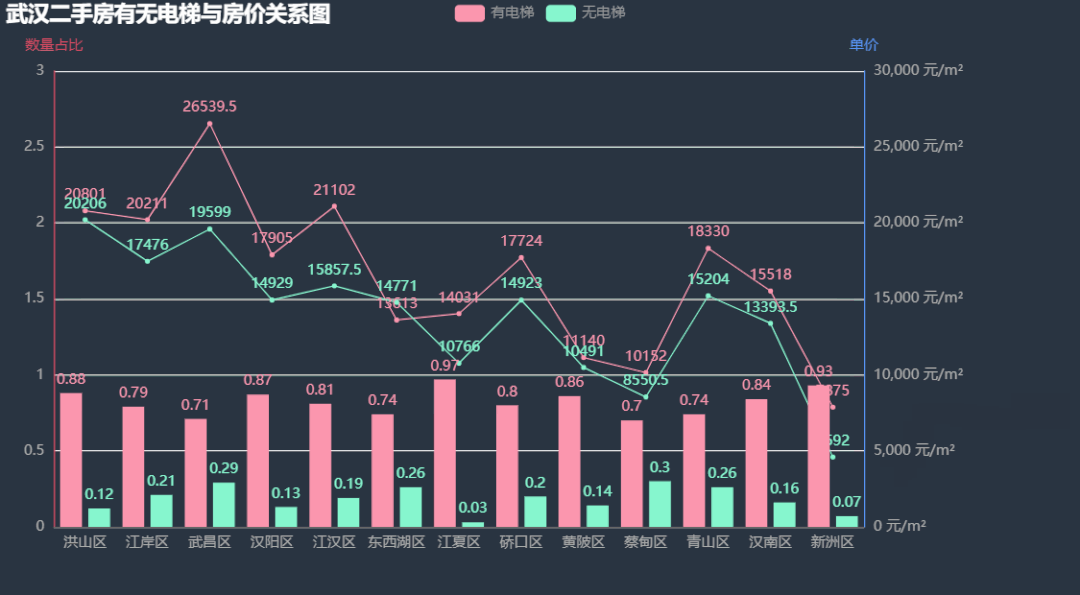 根据上图中的信息,各区二手房中有电梯的数量占了绝大多数,除了东西湖区的房价无电梯比有电梯略高外,其余各区的有电梯房价均比无电梯房价要高,其中武昌区差距最明显,这也印证了上面楼层与房价的关系,武昌区由于江景的原因高楼很吃香。图中新洲区的条形图与折线图有部分重叠,我们下面将两个图分开绘制,效果会更好。
根据上图中的信息,各区二手房中有电梯的数量占了绝大多数,除了东西湖区的房价无电梯比有电梯略高外,其余各区的有电梯房价均比无电梯房价要高,其中武昌区差距最明显,这也印证了上面楼层与房价的关系,武昌区由于江景的原因高楼很吃香。图中新洲区的条形图与折线图有部分重叠,我们下面将两个图分开绘制,效果会更好。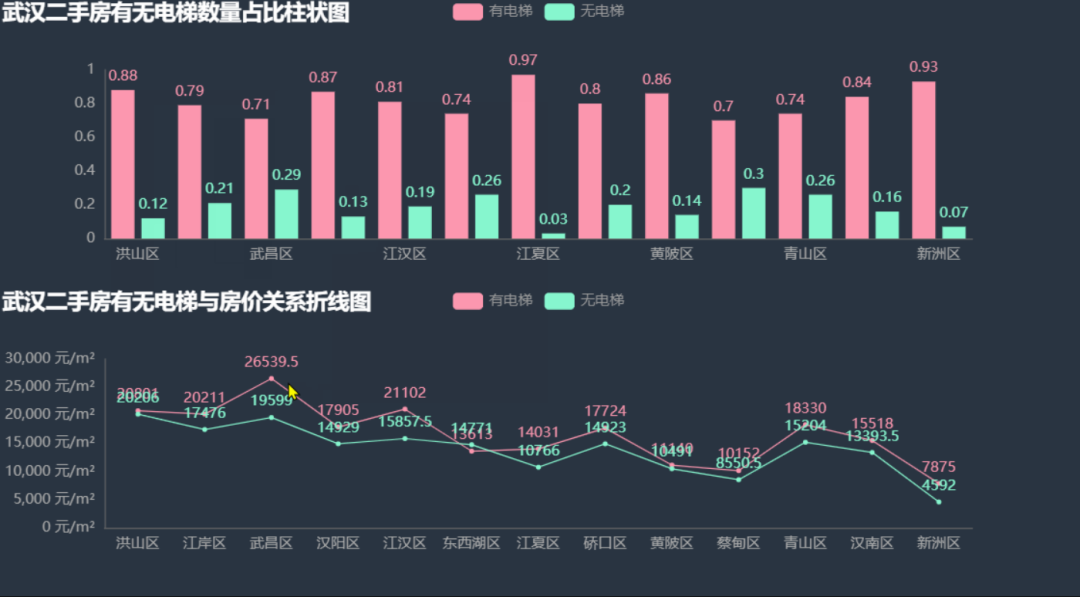
12.热门二手房标签漏斗图
统计关注人数超过 3 人的热门二手房标签信息,绘制漏斗图,看看这些二手房有什么共同点。
from collections import Counter
# 只统计关注人数超过三人的热门二手房
detail_df = df.loc[df['follower_numbers'] > 3]
label_list = []
for house_label in detail_df['house_label'].values.tolist():
label_list += house_label.split(',')
label_and_count = Counter(label_list)
label_and_count = label_and_count.most_common()
from pyecharts.charts import Funnel
c = Funnel(init_opts=opts.InitOpts(theme=ThemeType.CHALK))
c.add("商品", [list(z) for z in label_and_count])
c.set_global_opts(title_opts=opts.TitleOpts(title="武汉热门二手房标签漏斗图"))
c.render("武汉热门二手房标签漏斗图.html")
c.render_notebook()
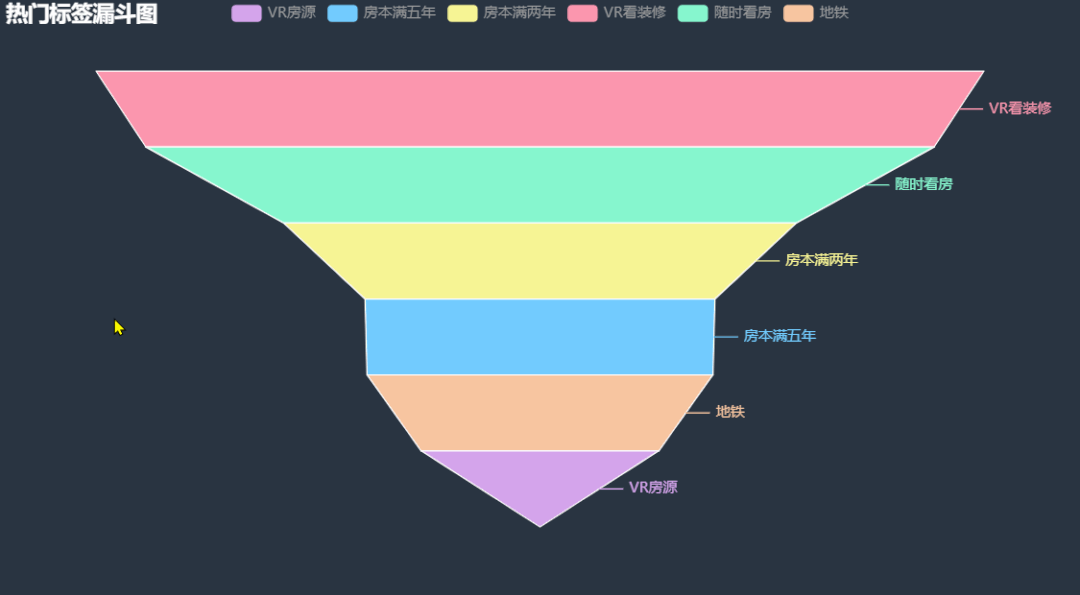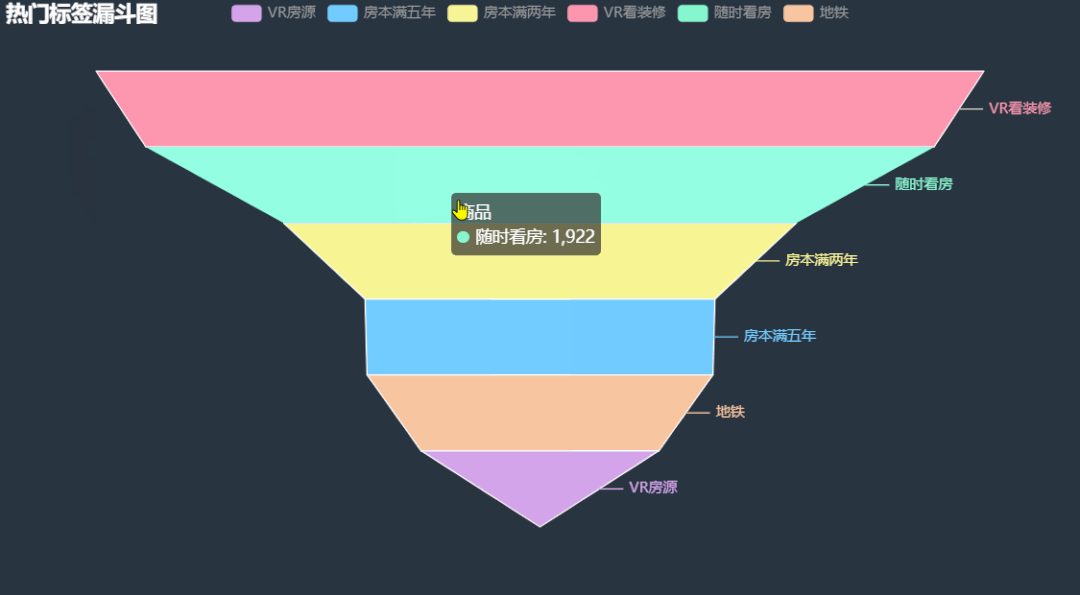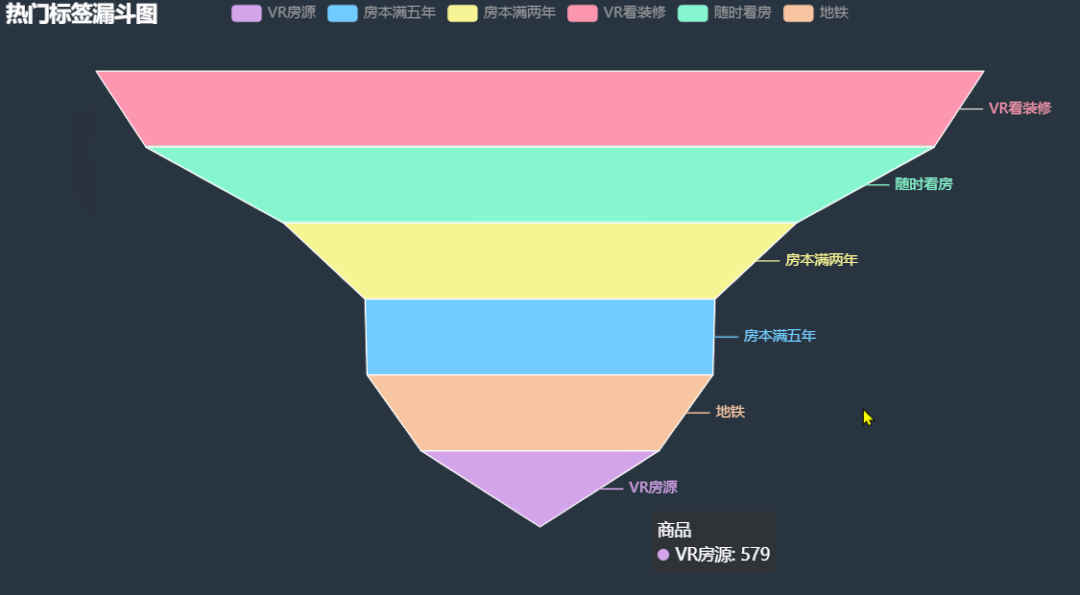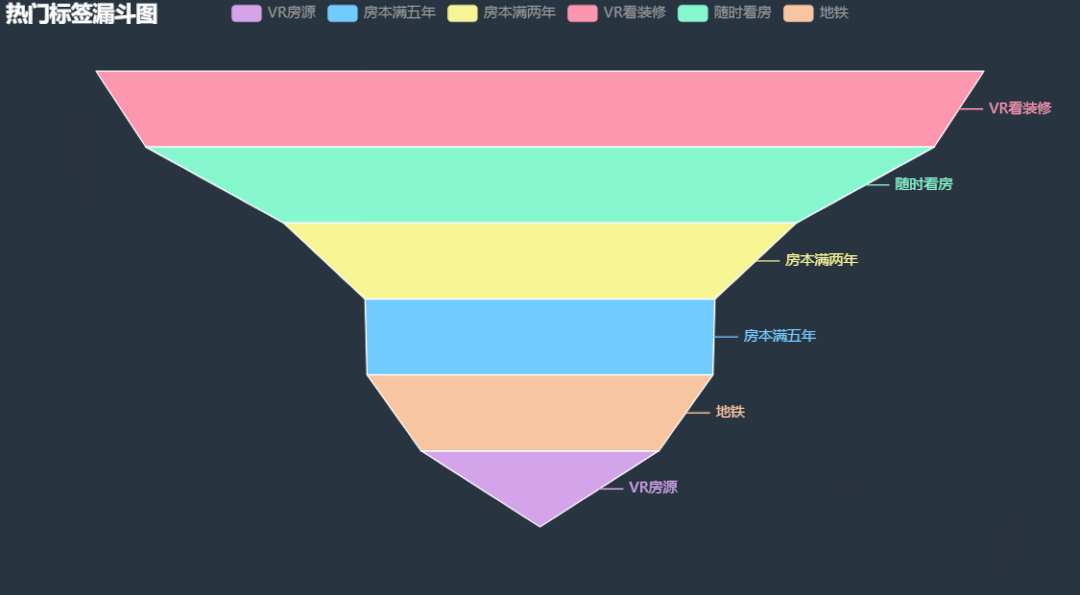 根据图中信息能够很清楚的看到, VR 看装修在热门二手房标签中出现次数最多,我之前在链家尝试过 VR 看房,确实方便,无死角,但就是转的有点晕,哈哈!其余的就是随时看房,房本满两年满五年,毕竟可以少缴税。
根据图中信息能够很清楚的看到, VR 看装修在热门二手房标签中出现次数最多,我之前在链家尝试过 VR 看房,确实方便,无死角,但就是转的有点晕,哈哈!其余的就是随时看房,房本满两年满五年,毕竟可以少缴税。
13.热门标题关键词
现在我们要提取热门二手房中标题的关键词(热门词),首先加载本地停用词。
def load_stopwords(read_path):
'''
读取文件每行内容并保存到列表中
:param read_path: 待读取文件的路径
:return: 保存文件每行信息的列表
'''
result = []
with open(read_path, "r", encoding='utf-8') as f:
for line in f.readlines():
line = line.strip('\n') # 去掉列表中每一个元素的换行符
result.append(line)
return result
# 加载中文停用词
stopwords = load_stopwords('wordcloud_stopwords.txt')
通过 jieba 分词获取标题的分词结果,并去除停用词。
import jieba
# 添加自定义词典
jieba.load_userdict("自定义词典.txt")
token_list = []
# 对标题内容进行分词,并将分词结果保存在列表中
for title in detail_df['title']:
tokens = jieba.lcut(title, cut_all=False)
token_list += [token for token in tokens if token not in stopwords]
len(token_list)
| 29203 |
|---|
根据分词列表,使用 Counter 类统计分词列表中各词的出现次数,选取出现次数最多的前 100 ,绘制词云图。
from pyecharts.charts import WordCloud
from collections import Counter
token_count_list = Counter(token_list).most_common(100)
new_token_list = []
for token, count in token_count_list:
new_token_list.append((token, str(count)))
c = WordCloud()
c.add(series_name="热词", data_pair=new_token_list, word_size_range=[20, 200])
c.set_global_opts(
title_opts=opts.TitleOpts(
title="武汉热门二手房标题关键词", title_textstyle_opts=opts.TextStyleOpts(font_size=23)
),
tooltip_opts=opts.TooltipOpts(is_show=True),
)
c.render("武汉热门二手房标题关键词.html")
c.render_notebook()
 热门二手房标题中出现较多的词有:电梯,楼层、采光、精装修、户型、满二、交通等。还有一些与位置相关的词汇,可以通过卖家的这些关键词来作为参考,说不定就是我们之后买房需要注意的内容。
热门二手房标题中出现较多的词有:电梯,楼层、采光、精装修、户型、满二、交通等。还有一些与位置相关的词汇,可以通过卖家的这些关键词来作为参考,说不定就是我们之后买房需要注意的内容。
总结
通过这么多方面的分析,也大致了解了武汉二手房的大致行情,市中心的房价 15000元/m² 起步,外围最低七八千左右。楼层根据自己的需要,如果想看看风景那么高层没毛病,但价格一般较高,如果不差钱武昌区就很香。面积的话,大致100m²左右就足够,太大的价格可能很高,毕竟从箱型图中的数据来看,各区中均有房价远超平均值的存在。装修纯看个人喜好,我个人喜欢自己装修,自己的风格只有自己懂,别人装的可能就感觉没有温馨的感觉。户型就选热门的 两室两厅一厨一卫。还有一些其他要注意的地方,比如采光、房龄、交通、环境 等方面。哈哈,我也不是卖房的,只能「根据一些数据来获取一些粗浅的见解」,大家看个乐就好,真正的分析这点数据肯定不够。总的来说,三个字,买不起,再见!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~