
逐行深入分析:langchain-ChatGLM项目的源码解读
文末《大模型项目开发线下营》秒杀!!!
再回顾一遍langchain-ChatGLM这个项目的架构图(图源)
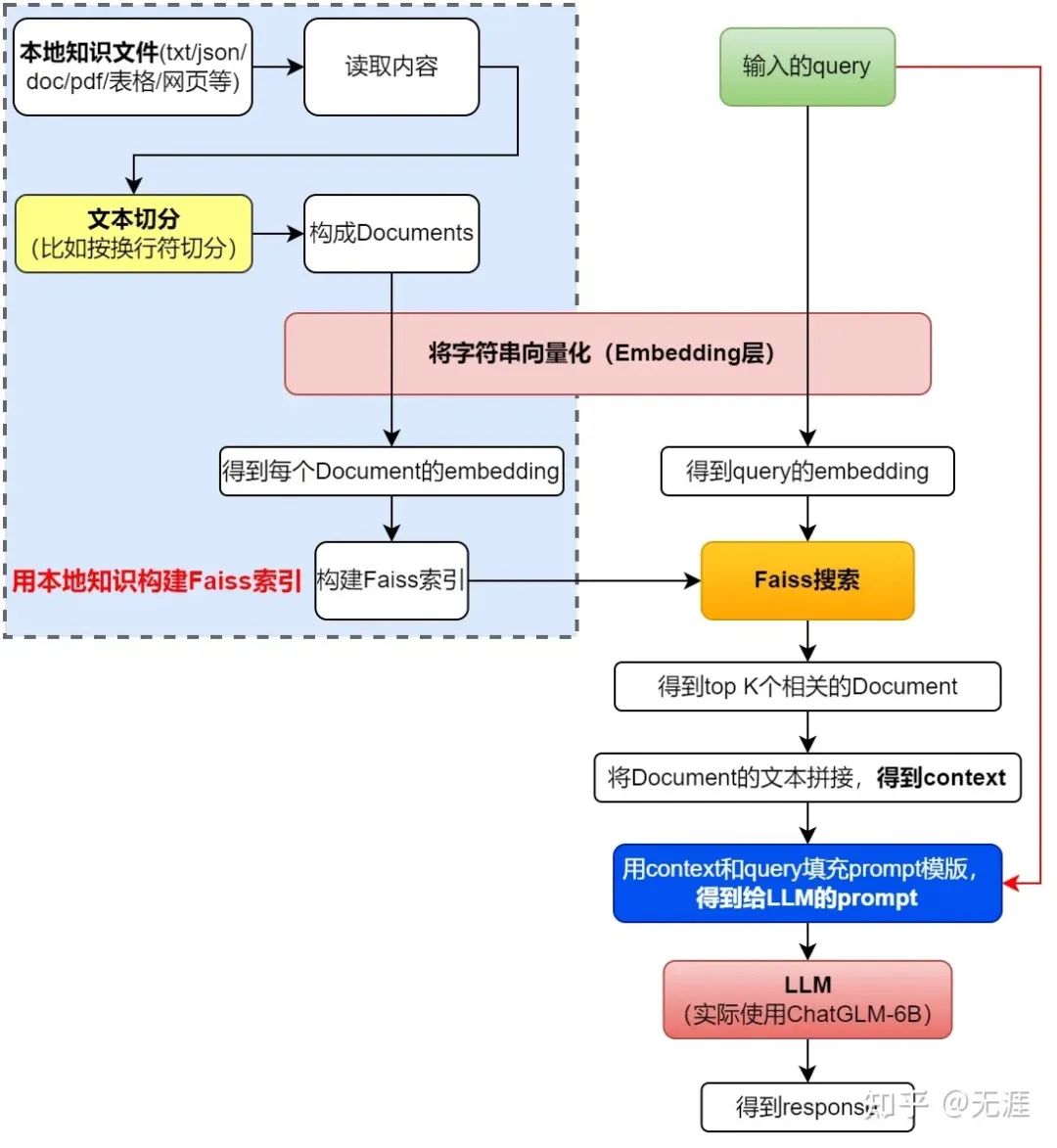
 你会发现该项目主要由以下各大模块组成
你会发现该项目主要由以下各大模块组成
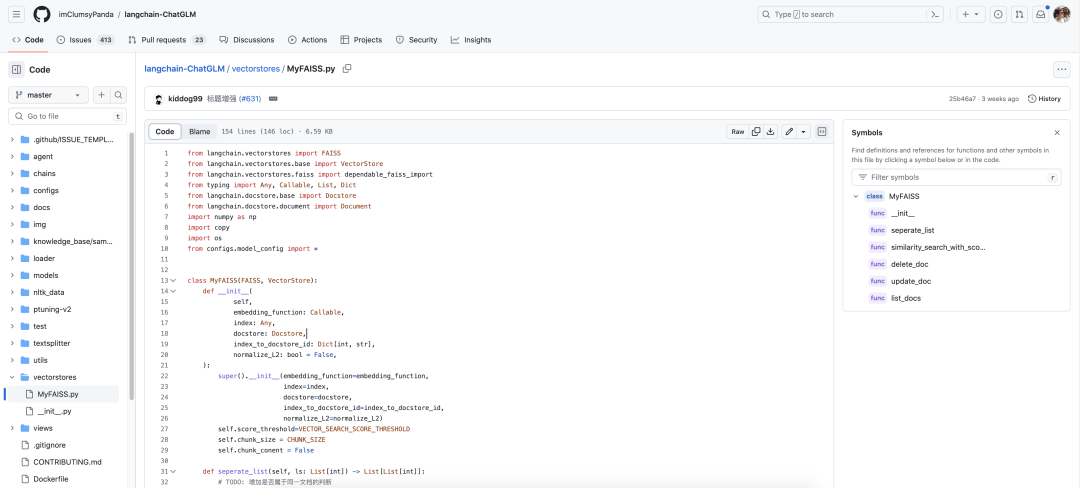
chains:工作链路实现,如 chains/local_doc_qa 实现了基于本地⽂档的问答实现
configs:配置文件存储
knowledge_bas/content:用于存储上传的原始⽂件
loader:文档加载器的实现类
models:llm的接⼝类与实现类,针对开源模型提供流式输出⽀持
textsplitter:文本切分的实现类
vectorstores:用于存储向量库⽂件,即本地知识库本体
..
我基本给“下面该项目中的每一行代码”都添加上了中文注释
且为理解更顺畅,我解读各个代码文件夹的顺序是根据项目流程逐一展开的 (而非上图GitHub上各个代码文件夹的呈现顺序)
1、agent:custom_agent/bing_search
1.1 agent/custom_agent.py
from langchain.agents import Tool # 导入工具模块from langchain.tools import BaseTool # 导入基础工具类from langchain import PromptTemplate, LLMChain # 导入提示模板和语言模型链from agent.custom_search import DeepSearch # 导入自定义搜索模块# 导入基础单动作代理,输出解析器,语言模型单动作代理和代理执行器from langchain.agents import BaseSingleActionAgent, AgentOutputParser, LLMSingleActionAgent, AgentExecutorfrom typing import List, Tuple, Any, Union, Optional, Type # 导入类型注释模块from langchain.schema import AgentAction, AgentFinish # 导入代理动作和代理完成模式from langchain.prompts import StringPromptTemplate # 导入字符串提示模板from langchain.callbacks.manager import CallbackManagerForToolRun # 导入工具运行回调管理器from langchain.base_language import BaseLanguageModel # 导入基础语言模型import re # 导入正则表达式模块# 定义一个代理模板字符串agent_template = """你现在是一个{role}。这里是一些已知信息:{related_content}{background_infomation}{question_guide}:{input}{answer_format}"""# 定义一个自定义提示模板类,继承自字符串提示模板class CustomPromptTemplate(StringPromptTemplate):template: str # 提示模板字符串tools: List[Tool] # 工具列表# 定义一个格式化函数,根据提供的参数生成最终的提示模板def format(self, **kwargs) -> str:intermediate_steps = kwargs.pop("intermediate_steps")# 判断是否有互联网查询信息if len(intermediate_steps) == 0:# 如果没有,则给出默认的背景信息,角色,问题指导和回答格式background_infomation = "\n"role = "傻瓜机器人"question_guide = "我现在有一个问题"answer_format = "如果你知道答案,请直接给出你的回答!如果你不知道答案,请你只回答\"DeepSearch('搜索词')\",并将'搜索词'替换为你认为需要搜索的关键词,除此之外不要回答其他任何内容。\n\n下面请回答我上面提出的问题!"else:# 否则,根据 intermediate_steps 中的 AgentAction 拼装 background_infomationbackground_infomation = "\n\n你还有这些已知信息作为参考:\n\n"action, observation = intermediate_steps[0]background_infomation += f"{observation}\n"role = "聪明的 AI 助手"question_guide = "请根据这些已知信息回答我的问题"answer_format = ""kwargs["background_infomation"] = background_infomationkwargs["role"] = rolekwargs["question_guide"] = question_guidekwargs["answer_format"] = answer_formatreturn self.template.format(**kwargs) # 格式化模板并返回# 定义一个自定义搜索工具类,继承自基础工具类class CustomSearchTool(BaseTool):name: str = "DeepSearch" # 工具名称description: str = "" # 工具描述# 定义一个运行函数,接受一个查询字符串和一个可选的回调管理器作为参数,返回DeepSearch的搜索结果def _run(self, query: str, run_manager: Optional[CallbackManagerForToolRun] = None):return DeepSearch.search(query = query)# 定义一个异步运行函数,但由于DeepSearch不支持异步,所以直接抛出一个未实现错误async def _arun(self, query: str):raise NotImplementedError("DeepSearch does not support async")# 定义一个自定义代理类,继承自基础单动作代理class CustomAgent(BaseSingleActionAgent):# 定义一个输入键的属性def input_keys(self):return ["input"]# 定义一个计划函数,接受一组中间步骤和其他参数,返回一个代理动作或者代理完成def plan(self, intermedate_steps: List[Tuple[AgentAction, str]],**kwargs: Any) -> Union[AgentAction, AgentFinish]:return AgentAction(tool="DeepSearch", tool_input=kwargs["input"], log="")# 定义一个自定义输出解析器,继承自代理输出解析器class CustomOutputParser(AgentOutputParser):# 定义一个解析函数,接受一个语言模型的输出字符串,返回一个代理动作或者代理完成def parse(self, llm_output: str) -> Union[AgentAction, AgentFinish]:# 使用正则表达式匹配输出字符串,group1是调用函数名字,group2是传入参数match = re.match(r'^[\s\w]*(DeepSearch)\(([^\)]+)\)', llm_output, re.DOTALL)print(match)# 如果语言模型没有返回 DeepSearch() 则认为直接结束指令if not match:return AgentFinish(return_values={"output": llm_output.strip()},log=llm_output,)# 否则的话都认为需要调用 Toolelse:action = match.group(1).strip()action_input = match.group(2).strip()return AgentAction(tool=action, tool_input=action_input.strip(" ").strip('"'), log=llm_output)# 定义一个深度代理类class DeepAgent:tool_name: str = "DeepSearch" # 工具名称agent_executor: any # 代理执行器tools: List[Tool] # 工具列表llm_chain: any # 语言模型链# 定义一个查询函数,接受一个相关内容字符串和一个查询字符串,返回执行器的运行结果def query(self, related_content: str = "", query: str = ""):tool_name =这段代码的主要目的是建立一个深度搜索的AI代理。AI代理首先通过接收一个问题输入,然后根据输入生成一个提示模板,然后通过该模板引导AI生成回答或进行更深入的搜索。现在,我将继续为剩余的代码添加中文注释```pythonself.tool_nameresult = self.agent_executor.run(related_content=related_content, input=query ,tool_name=self.tool_name)return result # 返回执行器的运行结果# 在初始化函数中,首先从DeepSearch工具创建一个工具实例,并添加到工具列表中def __init__(self, llm: BaseLanguageModel, **kwargs):tools = [Tool.from_function(func=DeepSearch.search,name="DeepSearch",description="")]self.tools = tools # 保存工具列表tool_names = [tool.name for tool in tools] # 提取工具列表中的工具名称output_parser = CustomOutputParser() # 创建一个自定义输出解析器实例# 创建一个自定义提示模板实例prompt = CustomPromptTemplate(template=agent_template,tools=tools,input_variables=["related_content","tool_name", "input", "intermediate_steps"])# 创建一个语言模型链实例llm_chain = LLMChain(llm=llm, prompt=prompt)self.llm_chain = llm_chain # 保存语言模型链实例# 创建一个语言模型单动作代理实例agent = LLMSingleActionAgent(llm_chain=llm_chain,output_parser=output_parser,stop=["\nObservation:"],allowed_tools=tool_names)# 创建一个代理执行器实例agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True)self.agent_executor = agent_executor # 保存代理执行器实例
1.2 agent/bing_search.py
#coding=utf8# 声明文件编码格式为 utf8from langchain.utilities import BingSearchAPIWrapper# 导入 BingSearchAPIWrapper 类,这个类用于与 Bing 搜索 API 进行交互from configs.model_config import BING_SEARCH_URL, BING_SUBSCRIPTION_KEY# 导入配置文件中的 Bing 搜索 URL 和 Bing 订阅密钥def bing_search(text, result_len=3):# 定义一个名为 bing_search 的函数,该函数接收一个文本和结果长度的参数,默认结果长度为3if not (BING_SEARCH_URL and BING_SUBSCRIPTION_KEY):# 如果 Bing 搜索 URL 或 Bing 订阅密钥未设置,则返回一个错误信息的文档return [{"snippet": "please set BING_SUBSCRIPTION_KEY and BING_SEARCH_URL in os ENV","title": "env inof not fould","link": "https://python.langchain.com/en/latest/modules/agents/tools/examples/bing_search.html"}]search = BingSearchAPIWrapper(bing_subscription_key=BING_SUBSCRIPTION_KEY,bing_search_url=BING_SEARCH_URL)# 创建 BingSearchAPIWrapper 类的实例,该实例用于与 Bing 搜索 API 进行交互return search.results(text, result_len)# 返回搜索结果,结果的数量由 result_len 参数决定if __name__ == "__main__":# 如果这个文件被直接运行,而不是被导入作为模块,那么就执行以下代码r = bing_search('python')# 使用 Bing 搜索 API 来搜索 "python" 这个词,并将结果保存在变量 r 中print(r)# 打印出搜索结果
2、models:包含models和文档加载器loader
models:llm的接⼝类与实现类,针对开源模型提供流式输出⽀持
loader:文档加载器的实现类
2.1 models/chatglm_llm.py
from abc import ABC # 导入抽象基类from langchain.llms.base import LLM # 导入语言学习模型基类from typing import Optional, List # 导入类型标注模块from models.loader import LoaderCheckPoint # 导入模型加载点from models.base import (BaseAnswer, # 导入基本回答模型AnswerResult) # 导入回答结果模型class ChatGLM(BaseAnswer, LLM, ABC): # 定义ChatGLM类,继承基础回答、语言学习模型和抽象基类max_token: int = 10000 # 最大的token数temperature: float = 0.01 # 温度参数,用于控制生成文本的随机性top_p = 0.9 # 排序前0.9的token会被保留checkPoint: LoaderCheckPoint = None # 检查点模型# history = [] # 历史记录history_len: int = 10 # 历史记录长度def __init__(self, checkPoint: LoaderCheckPoint = None): # 初始化方法super().__init__() # 调用父类的初始化方法self.checkPoint = checkPoint # 赋值检查点模型@propertydef _llm_type(self) -> str: # 定义只读属性_llm_type,返回语言学习模型的类型return "ChatGLM"@propertydef _check_point(self) -> LoaderCheckPoint: # 定义只读属性_check_point,返回检查点模型return self.checkPoint@propertydef _history_len(self) -> int: # 定义只读属性_history_len,返回历史记录的长度return self.history_lendef set_history_len(self, history_len: int = 10) -> None: # 设置历史记录长度self.history_len = history_lendef _call(self, prompt: str, stop: Optional[List[str]] = None) -> str: # 定义_call方法,实现模型的具体调用print(f"__call:{prompt}") # 打印调用的提示信息response, _ = self.checkPoint.model.chat( # 调用模型的chat方法,获取回答和其他信息self.checkPoint.tokenizer, # 使用的分词器prompt, # 提示信息history=[], # 历史记录max_length=self.max_token, # 最大长度temperature=self.temperature # 温度参数)print(f"response:{response}") # 打印回答信息print(f"+++++++++++++++++++++++++++++++++++") # 打印分隔线return response # 返回回答def generatorAnswer(self, prompt: str,history: List[List[str]] = [],streaming: bool = False): # 定义生成回答的方法,可以处理流式输入if streaming: # 如果是流式输入history += [[]] # 在历史记录中添加新的空列表for inum, (stream_resp, _) in enumerate(self.checkPoint.model.stream_chat( # 对模型的stream_chat方法返回的结果进行枚举self.checkPoint.tokenizer, # 使用的分词器prompt, # 提示信息history=history[-self.history_len:-1] if self.history_len > 1 else [], # 使用的历史记录max_length=self.max_token, # 最大长度temperature=self.temperature # 温度参数)):# self.checkPoint.clear_torch_cache() # 清空缓存history[-1] = [prompt, stream_resp] # 更新最后一个历史记录answer_result = AnswerResult() # 创建回答结果对象answer_result.history = history # 更新回答结果的历史记录answer_result.llm_output = {"answer": stream_resp} # 更新回答结果的输出yield answer_result # 生成回答结果else: # 如果不是流式输入response, _ = self.checkPoint.model.chat( # 调用模型的chat方法,获取回答和其他信息self.checkPoint.tokenizer, # 使用的分词器prompt, # 提示信息history=history[-self.history_len:] if self.history_len > 0 else [], # 使用的历史记录max_length=self.max_token, # 最大长度temperature=self.temperature # 温度参数)self.checkPoint.clear_torch_cache() # 清空缓存history += [[prompt, response]] # 更新历史记录answer_result = AnswerResult() # 创建回答结果对象answer_result.history = history # 更新回答结果的历史记录answer_result.llm_output = {"answer": response} # 更新回答结果的输出yield answer_result # 生成回答结果
2.2 models/shared.py
这个文件的作用是远程调用LLM
import sys # 导入sys模块,通常用于与Python解释器进行交互from typing import Any # 从typing模块导入Any,用于表示任何类型# 从models.loader.args模块导入parser,可能是解析命令行参数用from models.loader.args import parser# 从models.loader模块导入LoaderCheckPoint,可能是模型加载点from models.loader import LoaderCheckPoint# 从configs.model_config模块导入llm_model_dict和LLM_MODELfrom configs.model_config import (llm_model_dict, LLM_MODEL)# 从models.base模块导入BaseAnswer,即模型的基础类from models.base import BaseAnswer# 定义一个名为loaderCheckPoint的变量,类型为LoaderCheckPoint,并初始化为NoneloaderCheckPoint: LoaderCheckPoint = Nonedef loaderLLM(llm_model: str = None, no_remote_model: bool = False, use_ptuning_v2: bool = False) -> Any:"""初始化 llm_model_ins LLM:param llm_model: 模型名称:param no_remote_model: 是否使用远程模型,如果需要加载本地模型,则添加 `--no-remote-model:param use_ptuning_v2: 是否使用 p-tuning-v2 PrefixEncoder:return:"""pre_model_name = loaderCheckPoint.model_name # 获取loaderCheckPoint的模型名称llm_model_info = llm_model_dict[pre_model_name] # 从模型字典中获取模型信息if no_remote_model: # 如果不使用远程模型loaderCheckPoint.no_remote_model = no_remote_model # 将loaderCheckPoint的no_remote_model设置为Trueif use_ptuning_v2: # 如果使用p-tuning-v2loaderCheckPoint.use_ptuning_v2 = use_ptuning_v2 # 将loaderCheckPoint的use_ptuning_v2设置为Trueif llm_model: # 如果指定了模型名称llm_model_info = llm_model_dict[llm_model] # 从模型字典中获取指定的模型信息if loaderCheckPoint.no_remote_model: # 如果不使用远程模型loaderCheckPoint.model_name = llm_model_info['name'] # 将loaderCheckPoint的模型名称设置为模型信息中的nameelse: # 如果使用远程模型loaderCheckPoint.model_name = llm_model_info['pretrained_model_name'] # 将loaderCheckPoint的模型名称设置为模型信息中的pretrained_model_nameloaderCheckPoint.model_path = llm_model_info["local_model_path"] # 设置模型的本地路径if 'FastChatOpenAILLM' in llm_model_info["provides"]: # 如果模型信息中的provides包含'FastChatOpenAILLM'loaderCheckPoint.unload_model() # 卸载模型else: # 如果不包含loaderCheckPoint.reload_model() # 重新加载模型provides_class = getattr(sys.modules['models'], llm_model_info['provides']) # 获取模型类modelInsLLM = provides_class(checkPoint=loaderCheckPoint) # 创建模型实例if 'FastChatOpenAILLM' in llm_model_info["provides"]: # 如果模型信息中的provides包含'FastChatOpenAILLM'modelInsLLM.set_api_base_url(llm_model_info['api_base_url']) # 设置API基础URLmodelInsLLM.call_model_name(llm_model_info['name']) # 设置模型名称return modelInsLLM # 返回模型实例3.3 configs:配置文件存储model_config.pyimport torch.cudaimport torch.backendsimport osimport loggingimport uuidLOG_FORMAT = "%(levelname) -5s %(asctime)s" "-1d: %(message)s"logger = logging.getLogger()logger.setLevel(logging.INFO)logging.basicConfig(format=LOG_FORMAT)# 在以下字典中修改属性值,以指定本地embedding模型存储位置# 如将 "text2vec": "GanymedeNil/text2vec-large-chinese" 修改为 "text2vec": "User/Downloads/text2vec-large-chinese"# 此处请写绝对路径embedding_model_dict = {"ernie-tiny": "nghuyong/ernie-3.0-nano-zh","ernie-base": "nghuyong/ernie-3.0-base-zh","text2vec-base": "shibing624/text2vec-base-chinese","text2vec": "GanymedeNil/text2vec-large-chinese","m3e-small": "moka-ai/m3e-small","m3e-base": "moka-ai/m3e-base",}# Embedding model nameEMBEDDING_MODEL = "text2vec"# Embedding running deviceEMBEDDING_DEVICE = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"# supported LLM models# llm_model_dict 处理了loader的一些预设行为,如加载位置,模型名称,模型处理器实例# 在以下字典中修改属性值,以指定本地 LLM 模型存储位置# 如将 "chatglm-6b" 的 "local_model_path" 由 None 修改为 "User/Downloads/chatglm-6b"# 此处请写绝对路径llm_model_dict = {"chatglm-6b-int4-qe": {"name": "chatglm-6b-int4-qe","pretrained_model_name": "THUDM/chatglm-6b-int4-qe","local_model_path": None,"provides": "ChatGLM"},"chatglm-6b-int4": {"name": "chatglm-6b-int4","pretrained_model_name": "THUDM/chatglm-6b-int4","local_model_path": None,"provides": "ChatGLM"},"chatglm-6b-int8": {"name": "chatglm-6b-int8","pretrained_model_name": "THUDM/chatglm-6b-int8","local_model_path": None,"provides": "ChatGLM"},"chatglm-6b": {"name": "chatglm-6b","pretrained_model_name": "THUDM/chatglm-6b","local_model_path": None,"provides": "ChatGLM"},"chatglm2-6b": {"name": "chatglm2-6b","pretrained_model_name": "THUDM/chatglm2-6b","local_model_path": None,"provides": "ChatGLM"},"chatglm2-6b-int4": {"name": "chatglm2-6b-int4","pretrained_model_name": "THUDM/chatglm2-6b-int4","local_model_path": None,"provides": "ChatGLM"},"chatglm2-6b-int8": {"name": "chatglm2-6b-int8","pretrained_model_name": "THUDM/chatglm2-6b-int8","local_model_path": None,"provides": "ChatGLM"},"chatyuan": {"name": "chatyuan","pretrained_model_name": "ClueAI/ChatYuan-large-v2","local_model_path": None,"provides": None},"moss": {"name": "moss","pretrained_model_name": "fnlp/moss-moon-003-sft","local_model_path": None,"provides": "MOSSLLM"},"vicuna-13b-hf": {"name": "vicuna-13b-hf","pretrained_model_name": "vicuna-13b-hf","local_model_path": None,"provides": "LLamaLLM"},# 通过 fastchat 调用的模型请参考如下格式"fastchat-chatglm-6b": {"name": "chatglm-6b", # "name"修改为fastchat服务中的"model_name""pretrained_model_name": "chatglm-6b","local_model_path": None,"provides": "FastChatOpenAILLM", # 使用fastchat api时,需保证"provides"为"FastChatOpenAILLM""api_base_url": "http://localhost:8000/v1" # "name"修改为fastchat服务中的"api_base_url"},"fastchat-chatglm2-6b": {"name": "chatglm2-6b", # "name"修改为fastchat服务中的"model_name""pretrained_model_name": "chatglm2-6b","local_model_path": None,"provides": "FastChatOpenAILLM", # 使用fastchat api时,需保证"provides"为"FastChatOpenAILLM""api_base_url": "http://localhost:8000/v1" # "name"修改为fastchat服务中的"api_base_url"},# 通过 fastchat 调用的模型请参考如下格式"fastchat-vicuna-13b-hf": {"name": "vicuna-13b-hf", # "name"修改为fastchat服务中的"model_name""pretrained_model_name": "vicuna-13b-hf","local_model_path": None,"provides": "FastChatOpenAILLM", # 使用fastchat api时,需保证"provides"为"FastChatOpenAILLM""api_base_url": "http://localhost:8000/v1" # "name"修改为fastchat服务中的"api_base_url"},}# LLM 名称LLM_MODEL = "chatglm-6b"# 量化加载8bit 模型LOAD_IN_8BIT = False# Load the model with bfloat16 precision. Requires NVIDIA Ampere GPU.BF16 = False# 本地lora存放的位置LORA_DIR = "loras/"# LLM lora path,默认为空,如果有请直接指定文件夹路径LLM_LORA_PATH = ""USE_LORA = True if LLM_LORA_PATH else False# LLM streaming reponseSTREAMING = True# Use p-tuning-v2 PrefixEncoderUSE_PTUNING_V2 = False# LLM running deviceLLM_DEVICE = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"# 知识库默认存储路径KB_ROOT_PATH = os.path.join(os.path.dirname(os.path.dirname(__file__)), "knowledge_base")# 基于上下文的prompt模版,请务必保留"{question}"和"{context}"PROMPT_TEMPLATE = """已知信息:{context}根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。问题是:{question}"""# 缓存知识库数量,如果是ChatGLM2,ChatGLM2-int4,ChatGLM2-int8模型若检索效果不好可以调成’10’CACHED_VS_NUM = 1# 文本分句长度SENTENCE_SIZE = 100# 匹配后单段上下文长度CHUNK_SIZE = 250# 传入LLM的历史记录长度LLM_HISTORY_LEN = 3# 知识库检索时返回的匹配内容条数VECTOR_SEARCH_TOP_K = 5# 知识检索内容相关度 Score, 数值范围约为0-1100,如果为0,则不生效,经测试设置为小于500时,匹配结果更精准VECTOR_SEARCH_SCORE_THRESHOLD = 0NLTK_DATA_PATH = os.path.join(os.path.dirname(os.path.dirname(__file__)), "nltk_data")FLAG_USER_NAME = uuid.uuid4().hexlogger.info(f"""loading model configllm device: {LLM_DEVICE}embedding device: {EMBEDDING_DEVICE}dir: {os.path.dirname(os.path.dirname(__file__))}flagging username: {FLAG_USER_NAME}""")# 是否开启跨域,默认为False,如果需要开启,请设置为True# is open cross domainOPEN_CROSS_DOMAIN = False# Bing 搜索必备变量# 使用 Bing 搜索需要使用 Bing Subscription Key,需要在azure port中申请试用bing search# 具体申请方式请见# https://learn.microsoft.com/en-us/bing/search-apis/bing-web-search/create-bing-search-service-resource# 使用python创建bing api 搜索实例详见:# https://learn.microsoft.com/en-us/bing/search-apis/bing-web-search/quickstarts/rest/pythonBING_SEARCH_URL = "https://api.bing.microsoft.com/v7.0/search"# 注意不是bing Webmaster Tools的api key,# 此外,如果是在服务器上,报Failed to establish a new connection: [Errno 110] Connection timed out# 是因为服务器加了防火墙,需要联系管理员加白名单,如果公司的服务器的话,就别想了GGBING_SUBSCRIPTION_KEY = ""# 是否开启中文标题加强,以及标题增强的相关配置# 通过增加标题判断,判断哪些文本为标题,并在metadata中进行标记;# 然后将文本与往上一级的标题进行拼合,实现文本信息的增强。ZH_TITLE_ENHANCE = False3.4 loader:文档加载与text转换3.4.1 loader/pdf_loader.py# 导入类型提示模块,用于强化代码的可读性和健壮性from typing import List# 导入UnstructuredFileLoader,这是一个从非结构化文件中加载文档的类from langchain.document_loaders.unstructured import UnstructuredFileLoader# 导入PaddleOCR,这是一个开源的OCR工具,用于从图片中识别和读取文字from paddleocr import PaddleOCR# 导入os模块,用于处理文件和目录import os# 导入fitz模块,用于处理PDF文件import fitz# 导入nltk模块,用于处理文本数据import nltk# 导入模型配置文件中的NLTK_DATA_PATH,这是nltk数据的路径from configs.model_config import NLTK_DATA_PATH# 设置nltk数据的路径,将模型配置中的路径添加到nltk的数据路径中nltk.data.path = [NLTK_DATA_PATH] + nltk.data.path# 定义一个类,UnstructuredPaddlePDFLoader,该类继承自UnstructuredFileLoaderclass UnstructuredPaddlePDFLoader(UnstructuredFileLoader):# 定义一个内部方法_get_elements,返回一个列表def _get_elements(self) -> List:# 定义一个内部函数pdf_ocr_txt,用于从pdf中进行OCR并输出文本文件def pdf_ocr_txt(filepath, dir_path="tmp_files"):# 将dir_path与filepath的目录部分合并成一个新的路径full_dir_path = os.path.join(os.path.dirname(filepath), dir_path)# 如果full_dir_path对应的目录不存在,则创建这个目录if not os.path.exists(full_dir_path):os.makedirs(full_dir_path)# 创建一个PaddleOCR实例,设置一些参数ocr = PaddleOCR(use_angle_cls=True, lang="ch", use_gpu=False, show_log=False)# 打开pdf文件doc = fitz.open(filepath)# 创建一个txt文件的路径txt_file_path = os.path.join(full_dir_path, f"{os.path.split(filepath)[-1]}.txt")# 创建一个临时的图片文件路径img_name = os.path.join(full_dir_path, 'tmp.png')# 打开txt_file_path对应的文件,并以写模式打开with open(txt_file_path, 'w', encoding='utf-8') as fout:# 遍历pdf的所有页面for i in range(doc.page_count):# 获取当前页面page = doc[i]# 获取当前页面的文本内容,并写入txt文件text = page.get_text("")fout.write(text)fout.write("\n")# 获取当前页面的所有图片img_list = page.get_images()# 遍历所有图片for img in img_list:# 将图片转换为Pixmap对象pix = fitz.Pixmap(doc, img[0])# 如果图片有颜色信息,则将其转换为RGB格式if pix.n - pix.alpha >= 4:pix = fitz.Pixmap(fitz.csRGB, pix)# 保存图片pix.save(img_name)# 对图片进行OCR识别result = ocr.ocr(img_name)# 从OCR结果中提取文本,并写入txt文件ocr_result = [i[1][0] for line in result for i in line]fout.write("\n".join(ocr_result))# 如果图片文件存在,则删除它if os.path.exists(img_name):os.remove(img_name)# 返回txt文件的路径return txt_file_path# 调用上面定义的函数,获取txt文件的路径txt_file_path = pdf_ocr_txt(self.file_path)# 导入partition_text函数,该函数用于将文本文件分块from unstructured.partition.text import partition_text# 对txt文件进行分块,并返回分块结果return partition_text(filename=txt_file_path, **self.unstructured_kwargs)# 运行入口if __name__ == "__main__":# 导入sys模块,用于操作Python的运行环境import sys# 将当前文件的上一级目录添加到Python的搜索路径中sys.path.append(os.path.dirname(os.path.dirname(__file__)))# 定义一个pdf文件的路径filepath = os.path.join(os.path.dirname(os.path.dirname(__file__)), "knowledge_base", "samples", "content", "test.pdf")# 创建一个UnstructuredPaddlePDFLoader的实例loader = UnstructuredPaddlePDFLoader(filepath, mode="elements")# 加载文档docs = loader.load()# 遍历并打印所有文档for doc in docs:print(doc)
// 待更..
5、textsplitter:文档切分
5.1 textsplitter/ali_text_splitter.py
ali_text_splitter.py 代码如下所示
# 导入CharacterTextSplitter模块,用于文本切分from langchain.text_splitter import CharacterTextSplitterimport re # 导入正则表达式模块,用于文本匹配和替换from typing import List # 导入List类型,用于指定返回的数据类型# 定义一个新的类AliTextSplitter,继承自CharacterTextSplitterclass AliTextSplitter(CharacterTextSplitter):# 类的初始化函数,如果参数pdf为True,那么使用pdf文本切分规则,否则使用默认规则def __init__(self, pdf: bool = False, **kwargs):# 调用父类的初始化函数,接收传入的其他参数super().__init__(**kwargs)self.pdf = pdf # 将pdf参数保存为类的成员变量# 定义文本切分方法,输入参数为一个字符串,返回值为字符串列表def split_text(self, text: str) -> List[str]:if self.pdf: # 如果pdf参数为True,那么对文本进行预处理# 替换掉连续的3个及以上的换行符为一个换行符text = re.sub(r"\n{3,}", r"\n", text)# 将所有的空白字符(包括空格、制表符、换页符等)替换为一个空格text = re.sub('\s', " ", text)# 将连续的两个换行符替换为一个空字符text = re.sub("\n\n", "", text)# 导入pipeline模块,用于创建一个处理流程from modelscope.pipelines import pipeline# 创建一个document-segmentation任务的处理流程# 用的模型为damo/nlp_bert_document-segmentation_chinese-base,计算设备为cpup = pipeline(task="document-segmentation",model='damo/nlp_bert_document-segmentation_chinese-base',device="cpu")result = p(documents=text) # 对输入的文本进行处理,返回处理结果sent_list = [i for i in result["text"].split("\n\t") if i] # 将处理结果按照换行符和制表符进行切分,得到句子列表return sent_list # 返回句子列表
参数use_document_segmentation指定是否用语义切分文档 此处采取的文档语义分割模型为达摩院开源的:nlp_bert_document-segmentation_chinese-base (这是其论文)
modelscope[nlp]:pip install "modelscope[nlp]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html且考虑到使用了三个模型,可能对于低配置gpu不太友好,因此这里将模型load进cpu计算,有需要的话可以替换device为自己的显卡id
6、knowledge_bas:index.faiss/index.pkl
knowledge_bas下面有两个文件,一个content 即用户上传的原始文件,vector_store则用于存储向量库⽂件,即本地知识库本体,因为content因人而异 谁上传啥就是啥 所以没啥好分析,而vector_store下面则有两个文件,一个index.faiss,一个index.pkl
7、chains:向量搜索/匹配
如之前所述,本节开头图中“FAISS索引、FAISS搜索”中的“FAISS”是Facebook AI推出的一种用于有效搜索大规模高维向量空间中相似度的库,在大规模数据集中快速找到与给定向量最相似的向量是很多AI应用的重要组成部分,例如在推荐系统、自然语言处理、图像检索等领域
7.1 chains/modules /vectorstores.py文件:根据查询向量query在向量数据库中查找与query相似的文本向量
def max_marginal_relevance_search(self,query: str,k: int = 4,fetch_k: int = 20,**kwargs: Any,) -> List[Tuple[Document, float]]:embedding = self.embedding_function(query)docs = self.max_marginal_relevance_search_by_vector(embedding, k, fetch_k)return docs
 max_marginal_relevance_search_by_vector
max_marginal_relevance_search_by_vector
通过给定的嵌入向量,使用最大边际相关性(Maximal Marginal Relevance, MMR)方法来返回相关的文本 MMR是一种解决查询结果多样性和相关性的算法,具体来说,它不仅要求返回的文本与查询尽可能相似,而且希望返回的文本集之间尽可能多样
def max_marginal_relevance_search_by_vector(self, embedding: List[float], k: int = 4, fetch_k: int = 20, **kwargs: Any) -> List[Tuple[Document, float]]:scores, indices = self.index.search(np.array([embedding], dtype=np.float32), fetch_k)embeddings = [self.index.reconstruct(int(i)) for i in indices[0] if i != -1]mmr_selected = maximal_marginal_relevance(np.array([embedding], dtype=np.float32), embeddings, k=k)selected_indices = [indices[0][i] for i in mmr_selected]selected_scores = [scores[0][i] for i in mmr_selected]docs = []for i, score in zip(selected_indices, selected_scores):if i == -1:continue_id = self.index_to_docstore_id[i]doc = self.docstore.search(_id)if not isinstance(doc, Document):raise ValueError(f"Could not find document for id {_id}, got {doc}")docs.append((doc, score))return docs
__from
# 从给定的文本、嵌入向量、元数据等信息构建一个FAISS索引对象def __from(cls,texts: List[str], # 文本列表,每个文本将被转化为一个文本对象embeddings: List[List[float]], # 对应文本的嵌入向量列表embedding: Embeddings, # 嵌入向量生成器,用于将查询语句转化为嵌入向量metadatas: Optional[List[dict]] = None,**kwargs: Any,) -> FAISS:faiss = dependable_faiss_import() # 导入FAISS库index = faiss.IndexFlatIP(len(embeddings[0])) # 使用FAISS库创建一个新的索引,索引的维度等于嵌入文本向量的长度index.add(np.array(embeddings, dtype=np.float32)) # 将嵌入向量添加到FAISS索引中# quantizer = faiss.IndexFlatL2(len(embeddings[0]))# index = faiss.IndexIVFFlat(quantizer, len(embeddings[0]), 100)# index.train(np.array(embeddings, dtype=np.float32))# index.add(np.array(embeddings, dtype=np.float32))documents = []for i, text in enumerate(texts): # 对于每一段文本# 获取对应的元数据,如果没有提供元数据则使用空字典metadata = metadatas[i] if metadatas else {}# 创建一个文本对象并添加到文本列表中documents.append(Document(page_content=text, metadata=metadata))# 为每个文本生成一个唯一的IDindex_to_id = {i: str(uuid.uuid4()) for i in range(len(documents))}# 创建一个文本库,用于存储文本对象和对应的IDdocstore = InMemoryDocstore({index_to_id[i]: doc for i, doc in enumerate(documents)})# 返回FAISS对象return cls(embedding.embed_query, index, docstore, index_to_id)
以上就是这段代码的主要内容,通过使用FAISS和MMR,它可以帮助我们在大量文本中找到与给定查询最相关的文本
7.2 chains /local_doc_qa.py代码文件:向量搜索
导入包和模块 代码开始的部分是一系列的导入语句,导入了必要的 Python 包和模块,包括文件加载器,文本分割器,模型配置,以及一些 Python 内建模块和其他第三方库
改写 HuggingFaceEmbeddings 类的哈希方法 代码定义了一个名为 _embeddings_hash 的函数,并将其赋值给 HuggingFaceEmbeddings 类的 __hash__ 方法。这样做的目的是使 HuggingFaceEmbeddings 对象可以被哈希,即可以作为字典的键或者被加入到集合中
载入向量存储器 定义了一个名为 load_vector_store 的函数,这个函数用于从本地加载一个向量存储器,返回 FAISS 类的对象。其中使用了 lru_cache 装饰器,可以缓存最近使用的 CACHED_VS_NUM 个结果,提高代码效率
文件树遍历tree 函数是一个递归函数,用于遍历指定目录下的所有文件,返回一个包含所有文件的完整路径和文件名的列表。它可以忽略指定的文件或目录
加载文件:load_file 函数根据文件后缀名选择合适的加载器和文本分割器,加载并分割文件
生成提醒:generate_prompt 函数用于根据相关文档和查询生成一个提醒。提醒的模板由 prompt_template 参数提供
创建文档列表search_result2docs#
def search_result2docs(search_results):docs = []for result in search_results:doc = Document(page_content=result["snippet"] if "snippet" in result.keys() else "",metadata={"source": result["link"] if "link" in result.keys() else "","filename": result["title"] if "title" in result.keys() else ""})docs.append(doc)return docs
之后,定义了一个名为 LocalDocQA 的类,主要用于基于文档的问答任务。基于文档的问答任务的主要功能是,根据一组给定的文档(这里被称为知识库)以及用户输入的问题,返回一个答案,LocalDocQA 类的主要方法包括:
init_cfg():此方法初始化一些变量,包括将 llm_model(一个语言模型用于生成答案)分配给 self.llm,将一个基于HuggingFace的嵌入模型分配给 self.embeddings,将输入参数 top_k 分配给 self.top_k
init_knowledge_vector_store():此方法负责初始化知识向量库。它首先检查输入的文件路径,对于路径中的每个文件,将文件内容加载到 Document 对象中,然后将这些文档转换为嵌入向量,并将它们存储在向量库中
one_knowledge_add():此方法用于向知识库中添加一个新的知识文档。它将输入的标题和内容创建为一个 Document 对象,然后将其转换为嵌入向量,并添加到向量库中
get_knowledge_based_answer():此方法是基于给定的知识库和用户输入的问题,来生成一个答案。它首先根据用户输入的问题找到知识库中最相关的文档,然后生成一个包含相关文档和用户问题的提示,将提示传递给 llm_model 来生成答案 且注意一点,这个函数调用了上面已经实现好的:similarity_search_with_score
get_knowledge_based_conent_test():此方法是为了测试的,它将返回与输入查询最相关的文档和查询提示
# query 查询内容
# vs_path 知识库路径
# chunk_conent 是否启用上下文关联
# score_threshold 搜索匹配score阈值
# vector_search_top_k 搜索知识库内容条数,默认搜索5条结果
# chunk_sizes 匹配单段内容的连接上下文长度
def get_knowledge_based_conent_test(self, query, vs_path, chunk_conent, score_threshold=VECTOR_SEARCH_SCORE_THRESHOLD,
vector_search_top_k=VECTOR_SEARCH_TOP_K, chunk_size=CHUNK_SIZE):
get_search_result_based_answer():此方法与get_knowledge_based_answer() 类似,不过这里使用的是 bing_search 的结果作为知识库
def get_search_result_based_answer(self, query, chat_history=[], streaming: bool = STREAMING):# 对查询进行 Bing 搜索,并获取搜索结果results = bing_search(query)# 将搜索结果转化为文本的形式result_docs = search_result2docs(results)# 生成用于提问的提示语prompt = generate_prompt(result_docs, query)# 通过 LLM(长语言模型)生成回答for answer_result in self.llm.generatorAnswer(prompt=prompt, history=chat_history,streaming=streaming):# 获取回答的文本resp = answer_result.llm_output["answer"]# 获取聊天历史history = answer_result.history# 将聊天历史中的最后一项的提问替换为当前的查询history[-1][0] = query# 组装回答的结果response = {"query": query,"result": resp,"source_documents": result_docs}# 返回回答的结果和聊天历史yield response, history
如你所见,这个函数和上面那个函数的主要区别在于,这个函数是直接利用搜索引擎的搜索结果来生成回答的,而上面那个函数是通过查询相似度搜索来找到最相关的文本,然后基于这些文本生成回答的 而这个bing_search则在3.1.2节中已经定义
接下来是分别用于从向量存储中删除文件、更新文件以及列出文件的三个方法
delete_file_from_vector_store
update_file_from_vector_store
list_file_from_vector_store
# 删除向量存储中的文件def delete_file_from_vector_store(self,filepath: str or List[str], # 文件路径,可以是单个文件或多个文件列表vs_path): # 向量存储路径vector_store = load_vector_store(vs_path, self.embeddings) # 从给定路径加载向量存储status = vector_store.delete_doc(filepath) # 删除指定文件return status # 返回删除状态# 更新向量存储中的文件def update_file_from_vector_store(self,filepath: str or List[str], # 需要更新的文件路径,可以是单个文件或多个文件列表vs_path, # 向量存储路径docs: List[Document],): # 需要更新的文件内容,文件以文档形式给出vector_store = load_vector_store(vs_path, self.embeddings) # 从给定路径加载向量存储status = vector_store.update_doc(filepath, docs) # 更新指定文件return status # 返回更新状态# 列出向量存储中的文件def list_file_from_vector_store(self,vs_path, # 向量存储路径fullpath=False): # 是否返回完整路径,如果为 False,则只返回文件名vector_store = load_vector_store(vs_path, self.embeddings) # 从给定路径加载向量存储docs = vector_store.list_docs() # 列出所有文件if fullpath: # 如果需要完整路径return docs # 返回完整路径列表else: # 如果只需要文件名return [os.path.split(doc)[-1] for doc in docs] # 用 os.path.split 将路径和文件名分离,只返回文件
__main__部分的代码是 LocalDocQA 类的实例化和使用示例
它首先初始化了一个 llm_model_ins 对象
然后创建了一个 LocalDocQA 的实例并调用其 init_cfg() 方法进行初始化
之后,它指定了一个查询和知识库的路径
然后调用 get_knowledge_based_answer() 或 get_search_result_based_answer() 方法获取基于该查询的答案,并打印出答案和来源文档的信息
7.3 chains/text_load.py
chain这个文件夹下 还有最后一个项目文件(langchain-ChatGLM/text_load.py at master · imClumsyPanda/langchain-ChatGLM · GitHub),如下所示
import osimport pineconefrom tqdm import tqdmfrom langchain.llms import OpenAIfrom langchain.text_splitter import SpacyTextSplitterfrom langchain.document_loaders import TextLoaderfrom langchain.document_loaders import DirectoryLoaderfrom langchain.indexes import VectorstoreIndexCreatorfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Pinecone#一些配置文件openai_key="你的key" # 注册 openai.com 后获得pinecone_key="你的key" # 注册 app.pinecone.io 后获得pinecone_index="你的库" #app.pinecone.io 获得pinecone_environment="你的Environment" # 登录pinecone后,在indexes页面 查看Environmentpinecone_namespace="你的Namespace" #如果不存在自动创建#科学上网你懂得os.environ['HTTP_PROXY'] = 'http://127.0.0.1:7890'os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890'#初始化pineconepinecone.init(api_key=pinecone_key,environment=pinecone_environment)index = pinecone.Index(pinecone_index)#初始化OpenAI的embeddingsembeddings = OpenAIEmbeddings(openai_api_key=openai_key)#初始化text_splittertext_splitter = SpacyTextSplitter(pipeline='zh_core_web_sm',chunk_size=1000,chunk_overlap=200)# 读取目录下所有后缀是txt的文件loader = DirectoryLoader('../docs', glob="**/*.txt", loader_cls=TextLoader)#读取文本文件documents = loader.load()# 使用text_splitter对文档进行分割split_text = text_splitter.split_documents(documents)try:for document in tqdm(split_text):# 获取向量并储存到pineconePinecone.from_documents([document], embeddings, index_name=pinecone_index)except Exception as e:print(f"Error: {e}")quit()
8、vectorstores:MyFAISS.py
两个文件,一个__init__.py (就一行代码:from .MyFAISS import MyFAISS),另一个MyFAISS.py,如下代码所示
# 从langchain.vectorstores库导入FAISSfrom langchain.vectorstores import FAISS# 从langchain.vectorstores.base库导入VectorStorefrom langchain.vectorstores.base import VectorStore# 从langchain.vectorstores.faiss库导入dependable_faiss_importfrom langchain.vectorstores.faiss import dependable_faiss_importfrom typing import Any, Callable, List, Dict # 导入类型检查库from langchain.docstore.base import Docstore # 从langchain.docstore.base库导入Docstore# 从langchain.docstore.document库导入Documentfrom langchain.docstore.document import Documentimport numpy as np # 导入numpy库,用于科学计算import copy # 导入copy库,用于数据复制import os # 导入os库,用于操作系统相关的操作from configs.model_config import * # 从configs.model_config库导入所有内容# 定义MyFAISS类,继承自FAISS和VectorStore两个父类class MyFAISS(FAISS, VectorStore):
8.1 定义类的初始化函数:__init__
# 定义类的初始化函数def __init__(self,embedding_function: Callable,index: Any,docstore: Docstore,index_to_docstore_id: Dict[int, str],normalize_L2: bool = False,:# 调用父类FAISS的初始化函数=embedding_function,index=index,docstore=docstore,index_to_docstore_id=index_to_docstore_id,normalize_L2=normalize_L2)# 初始化分数阈值=VECTOR_SEARCH_SCORE_THRESHOLD# 初始化块大小= CHUNK_SIZE# 初始化块内容= False
8.2 seperate_list:将一个列表分解成多个子列表
# 定义函数seperate_list,将一个列表分解成多个子列表,每个子列表中的元素在原列表中是连续的def seperate_list(self, ls: List[int]) -> List[List[int]]:# TODO: 增加是否属于同一文档的判断lists = []ls1 = [ls[0]]for i in range(1, len(ls)):if ls[i - 1] + 1 == ls[i]:ls1.append(ls[i])else:lists.append(ls1)ls1 = [ls[i]]lists.append(ls1)return lists
similarity_search_with_score_by_vector 函数用于通过向量进行相似度搜索,返回与给定嵌入向量最相似的文本和对应的分数
def similarity_search_with_score_by_vector(self, embedding: List[float], k: int = 4) -> List[Document]:faiss = dependable_faiss_import()vector = np.array([embedding], dtype=np.float32)if self._normalize_L2:faiss.normalize_L2(vector)scores, indices = self.index.search(vector, k)docs = []id_set = set()store_len = len(self.index_to_docstore_id)rearrange_id_list = Falsefor j, i in enumerate(indices[0]):if i == -1 or 0 < self.score_threshold < scores[0][j]:continueif i in self.index_to_docstore_id:_id = self.index_to_docstore_id[i]else:continuedoc = self.docstore.search(_id)if (not self.chunk_conent) or ("context_expand" in doc.metadata and not doc.metadata["context_expand"]):if not isinstance(doc, Document):raise ValueError(f"Could not find document for id {_id}, got {doc}")doc.metadata["score"] = int(scores[0][j])docs.append(doc)continueid_set.add(i)docs_len = len(doc.page_content)for k in range(1, max(i, store_len - i)):break_flag = Falseif "context_expand_method" in doc.metadata and doc.metadata["context_expand_method"] == "forward":expand_range = [i + k]elif "context_expand_method" in doc.metadata and doc.metadata["context_expand_method"] == "backward":expand_range = [i - k]else:expand_range = [i + k, i - k]for l in expand_range:if l not in id_set and 0 <= l < len(self.index_to_docstore_id):_id0 = self.index_to_docstore_id[l]doc0 = self.docstore.search(_id0)if docs_len + len(doc0.page_content) > self.chunk_size or doc0.metadata["source"] != \doc.metadata["source"]:break_flag = Truebreakelif doc0.metadata["source"] == doc.metadata["source"]:docs_len += len(doc0.page_content)id_set.add(l)rearrange_id_list = Trueif break_flag:breakif (not self.chunk_conent) or (not rearrange_id_list):return docsif len(id_set) == 0 and self.score_threshold > 0:return []id_list = sorted(list(id_set))id_lists = self.seperate_list(id_list)for id_seq in id_lists:for id in id_seq:if id == id_seq[0]:_id = self.index_to_docstore_id[id]doc = copy.deepcopy(self.docstore.search(_id))else:_id0 = self.index_to_docstore_id[id]doc0 = self.docstore.search(_id0)doc.page_content += " " + doc0.page_contentif not isinstance(doc, Document):raise ValueError(f"Could not find document for id {_id}, got {doc}")doc_score = min([scores[0][id] for id in [indices[0].tolist().index(i) for i in id_seq if i in indices[0]]])doc.metadata["score"] = int(doc_score)docs.append(doc)return docs
8.4 delete_doc方法:删除文本库中指定来源的文本
#定义了一个名为 delete_doc 的方法,这个方法用于删除文本库中指定来源的文本def delete_doc(self, source: str or List[str]):# 使用 try-except 结构捕获可能出现的异常try:# 如果 source 是字符串类型if isinstance(source, str):# 找出文本库中所有来源等于 source 的文本的idids = [k for k, v in self.docstore._dict.items() if v.metadata["source"] == source]# 获取向量存储的路径vs_path = os.path.join(os.path.split(os.path.split(source)[0])[0], "vector_store")# 如果 source 是列表类型else:# 找出文本库中所有来源在 source 列表中的文本的idids = [k for k, v in self.docstore._dict.items() if v.metadata["source"] in source]# 获取向量存储的路径vs_path = os.path.join(os.path.split(os.path.split(source[0])[0])[0], "vector_store")# 如果没有找到要删除的文本,返回失败信息if len(ids) == 0:return f"docs delete fail"# 如果找到了要删除的文本else:# 遍历所有要删除的文本idfor id in ids:# 获取该id在索引中的位置index = list(self.index_to_docstore_id.keys())[list(self.index_to_docstore_id.values()).index(id)]# 从索引中删除该idself.index_to_docstore_id.pop(index)# 从文本库中删除该id对应的文本self.docstore._dict.pop(id)# TODO: 从 self.index 中删除对应id,这是一个未完成的任务# self.index.reset()# 保存当前状态到本地self.save_local(vs_path)# 返回删除成功的信息return f"docs delete success"# 捕获异常except Exception as e:# 打印异常信息print(e)# 返回删除失败的信息return f"docs delete fail"
# 定义了一个名为 update_doc 的方法,这个方法用于更新文档库中的文档def update_doc(self, source, new_docs):# 使用 try-except 结构捕获可能出现的异常try:# 删除旧的文档delete_len = self.delete_doc(source)# 添加新的文档ls = self.add_documents(new_docs)# 返回更新成功的信息return f"docs update success"# 捕获异常except Exception as e:# 打印异常信息print(e)# 返回更新失败的信息return f"docs update fail"# 定义了一个名为 list_docs 的方法,这个方法用于列出文档库中所有文档的来源def list_docs(self):# 遍历文档库中的所有文档,取出每个文档的来源,转换为集合,再转换为列表,最后返回这个列表return list(set(v.metadata["source"] for v in self.docstore._dict.values()))
故我们在北京(已开营)、上海杭州(9.18开班)、深圳广州、武汉长沙、成都、西安等6个区域先后开《大模型项目开发线下营》
→ 前30人报名额外加送1个直播课:类ChatGPT微调实战或AI绘画与多模态
↓↓↓扫码抢购↓↓↓

↓↓↓扫码抢购↓↓↓
点击“阅读原文”了解课程详情~
