
真正的缓存之王,Google Guava 只是弟弟
点击关注公众号,Java干货及时送达
作者:rickiyang
来源:www.cnblogs.com/rickiyang/p/11074158.html
FIFO:先进先出,在这种淘汰算法中,先进入缓存的会先被淘汰,会导致命中率很低。
LRU:最近最少使用算法,每次访问数据都会将其放在我们的队尾,如果需要淘汰数据,就只需要淘汰队首即可。仍然有个问题,如果有个数据在 1 分钟访问了 1000次,再后 1 分钟没有访问这个数据,但是有其他的数据访问,就导致了我们这个热点数据被淘汰。
LFU:最近最少频率使用,利用额外的空间记录每个数据的使用频率,然后选出频率最低进行淘汰。这样就避免了 LRU 不能处理时间段的问题。
当数据的访问模式不随时间变化的时候,LFU的策略能够带来最佳的缓存命中率。然而LFU有两个缺点:
首先,它需要给每个记录项维护频率信息,每次访问都需要更新,这是个巨大的开销;
其次,如果数据访问模式随时间有变,LFU的频率信息无法随之变化,因此早先频繁访问的记录可能会占据缓存,而后期访问较多的记录则无法被命中。
因此,大多数的缓存设计都是基于LRU或者其变种来进行的。相比之下,LRU并不需要维护昂贵的缓存记录元信息,同时也能够反应随时间变化的数据访问模式。然而,在许多负载之下,LRU依然需要更多的空间才能做到跟LFU一致的缓存命中率。因此,一个“现代”的缓存,应当能够综合两者的长处。

<dependency><groupId>com.github.ben-manes.caffeinegroupId><artifactId>caffeineartifactId><version>2.6.2version>dependency>
/** * 手动加载 * @param key * @return */public Object manulOperator(String key) { Cache<String, Object> cache = Caffeine.newBuilder() .expireAfterWrite(1, TimeUnit.SECONDS) .expireAfterAccess(1, TimeUnit.SECONDS) .maximumSize(10) .build(); //如果一个key不存在,那么会进入指定的函数生成value Object value = cache.get(key, t -> setValue(key).apply(key)); cache.put("hello",value); //判断是否存在如果不存返回null Object ifPresent = cache.getIfPresent(key); //移除一个key cache.invalidate(key); return value;}public Function setValue(String key){ return t -> key + "value";} /** * 同步加载 * @param key * @return */public Object syncOperator(String key){ LoadingCache<String, Object> cache = Caffeine.newBuilder() .maximumSize(100) .expireAfterWrite(1, TimeUnit.MINUTES) .build(k -> setValue(key).apply(key)); return cache.get(key);}public Function<String, Object> setValue(String key){ return t -> key + "value";}/** * 异步加载 * * @param key * @return */public Object asyncOperator(String key){ AsyncLoadingCache<String, Object> cache = Caffeine.newBuilder() .maximumSize(100) .expireAfterWrite(1, TimeUnit.MINUTES) .buildAsync(k -> setAsyncValue(key).get()); return cache.get(key);}public CompletableFuture<Object> setAsyncValue(String key){ return CompletableFuture.supplyAsync(() -> { return key + "value"; });}// 根据缓存的计数进行驱逐LoadingCache cache = Caffeine.newBuilder() .maximumSize(10000) .build(key -> function(key));// 根据缓存的权重来进行驱逐(权重只是用于确定缓存大小,不会用于决定该缓存是否被驱逐)LoadingCache cache1 = Caffeine.newBuilder() .maximumWeight(10000) .weigher(key -> function1(key)) .build(key -> function(key)); // 基于固定的到期策略进行退出LoadingCache cache = Caffeine.newBuilder() .expireAfterAccess(5, TimeUnit.MINUTES) .build(key -> function(key));LoadingCache cache1 = Caffeine.newBuilder() .expireAfterWrite(10, TimeUnit.MINUTES) .build(key -> function(key));// 基于不同的到期策略进行退出LoadingCache cache2 = Caffeine.newBuilder() .expireAfter(new Expiry() { @Override public long expireAfterCreate(String key, Object value, long currentTime) { return TimeUnit.SECONDS.toNanos(seconds); } @Override public long expireAfterUpdate(@Nonnull String s, @Nonnull Object o, long l, long l1) { return 0; } @Override public long expireAfterRead(@Nonnull String s, @Nonnull Object o, long l, long l1) { return 0; } }).build(key -> function(key)); 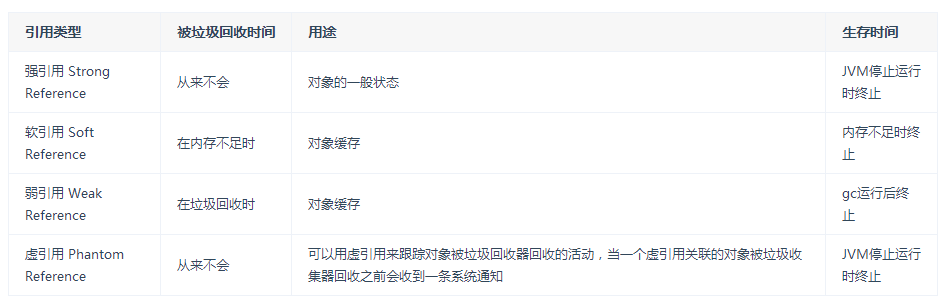
// 当key和value都没有引用时驱逐缓存LoadingCache cache = Caffeine.newBuilder() .weakKeys() .weakValues() .build(key -> function(key));// 当垃圾收集器需要释放内存时驱逐LoadingCache cache1 = Caffeine.newBuilder() .softValues() .build(key -> function(key)); Cache<String, Object> cache = Caffeine.newBuilder().removalListener((String key, Object value, RemovalCause cause) ->System.out.printf("Key %s was removed (%s)%n", key, cause)).build();
LoadingCache<String, Object> cache2 = Caffeine.newBuilder().writer(new CacheWriter<String, Object>() {public void write(String key, Object value) {// 写入到外部存储}public void delete(String key, Object value, RemovalCause cause) {// 删除外部存储}}).build(key -> function(key));
Cache<String, Object> cache = Caffeine.newBuilder().maximumSize(10_000).recordStats().build();
hitRate(): 返回缓存命中率evictionCount(): 缓存回收数量averageLoadPenalty(): 加载新值的平均时间<dependency><groupId>org.springframework.bootgroupId><artifactId>spring-boot-starter-cacheartifactId>dependency><dependency><groupId>com.github.ben-manes.caffeinegroupId><artifactId>caffeineartifactId><version>2.6.2version>dependency>
class SingleDatabaseApplication { public static void main(String[] args) { SpringApplication.run(SingleDatabaseApplication.class, args); }}spring.cache.cache-names=cache1spring.cache.caffeine.spec=initialCapacity=50,maximumSize=500,expireAfterWrite=10s
spring:cache:type: caffeine:userCachecaffeine:spec: maximumSize=1024,refreshAfterWrite=60s
import com.github.benmanes.caffeine.cache.CacheLoader;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;/** * @author: rickiyang * @date: 2019/6/15 * @description: */ class CacheConfig { /** * 相当于在构建LoadingCache对象的时候 build()方法中指定过期之后的加载策略方法 * 必须要指定这个Bean,refreshAfterWrite=60s属性才生效 * @return */ public CacheLoader<String, Object> cacheLoader() { CacheLoader<String, Object> cacheLoader = new CacheLoader<String, Object>() { public Object load(String key) throws Exception { return null; } // 重写这个方法将oldValue值返回回去,进而刷新缓存 @Override public Object reload(String key, Object oldValue) throws Exception { return oldValue; } }; return cacheLoader; }}initialCapacity=[integer]: 初始的缓存空间大小maximumSize=[long]: 缓存的最大条数maximumWeight=[long]: 缓存的最大权重expireAfterAccess=[duration]: 最后一次写入或访问后经过固定时间过期expireAfterWrite=[duration]: 最后一次写入后经过固定时间过期refreshAfterWrite=[duration]: 创建缓存或者最近一次更新缓存后经过固定的时间间隔,刷新缓存weakKeys: 打开key的弱引用weakValues:打开value的弱引用softValues:打开value的软引用recordStats:开发统计功能注意:expireAfterWrite和expireAfterAccess同时存在时,以expireAfterWrite为准。maximumSize和maximumWeight不可以同时使用weakValues和softValues不可以同时使用package com.rickiyang.learn.cache;import com.github.benmanes.caffeine.cache.CacheLoader;import com.github.benmanes.caffeine.cache.Caffeine;import org.apache.commons.compress.utils.Lists;import org.springframework.cache.CacheManager;import org.springframework.cache.caffeine.CaffeineCache;import org.springframework.cache.support.SimpleCacheManager;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.context.annotation.Primary;import java.util.ArrayList;import java.util.List;import java.util.concurrent.TimeUnit;/** * @author: rickiyang * @date: 2019/6/15 * @description: */ class CacheConfig { /** * 创建基于Caffeine的Cache Manager * 初始化一些key存入 * @return */ public CacheManager caffeineCacheManager() { SimpleCacheManager cacheManager = new SimpleCacheManager(); ArrayList caches = Lists.newArrayList(); List list = setCacheBean(); for(CacheBean cacheBean : list){ caches.add(new CaffeineCache(cacheBean.getKey(), Caffeine.newBuilder().recordStats() .expireAfterWrite(cacheBean.getTtl(), TimeUnit.SECONDS) .maximumSize(cacheBean.getMaximumSize()) .build())); } cacheManager.setCaches(caches); return cacheManager; } /** * 初始化一些缓存的 key * @return */ private List setCacheBean() { List list = Lists.newArrayList(); CacheBean userCache = new CacheBean(); userCache.setKey("userCache"); userCache.setTtl(60); userCache.setMaximumSize(10000); CacheBean deptCache = new CacheBean(); deptCache.setKey("userCache"); deptCache.setTtl(60); deptCache.setMaximumSize(10000); list.add(userCache); list.add(deptCache); return list; } class CacheBean { private String key; private long ttl; private long maximumSize; public String getKey() { return key; } public void setKey(String key) { this.key = key; } public long getTtl() { return ttl; } public void setTtl(long ttl) { this.ttl = ttl; } public long getMaximumSize() { return maximumSize; } public void setMaximumSize(long maximumSize) { this.maximumSize = maximumSize; } }} @Cacheable 触发缓存入口(这里一般放在创建和获取的方法上,@Cacheable注解会先查询是否已经有缓存,有会使用缓存,没有则会执行方法并缓存)
@CacheEvict 触发缓存的eviction(用于删除的方法上)
@CachePut 更新缓存且不影响方法执行(用于修改的方法上,该注解下的方法始终会被执行)
@Caching 将多个缓存组合在一个方法上(该注解可以允许一个方法同时设置多个注解)
@CacheConfig 在类级别设置一些缓存相关的共同配置(与其它缓存配合使用)
@Cacheable:它的注解的方法是否被执行取决于Cacheable中的条件,方法很多时候都可能不被执行。
@CachePut:这个注解不会影响方法的执行,也就是说无论它配置的条件是什么,方法都会被执行,更多的时候是被用到修改上。
public Cacheable { /** * 要使用的cache的名字 */ ("cacheNames") String[] value() default {}; /** * 同value(),决定要使用那个/些缓存 */ ("value") String[] cacheNames() default {}; /** * 使用SpEL表达式来设定缓存的key,如果不设置默认方法上所有参数都会作为key的一部分 */ String key() default ""; /** * 用来生成key,与key()不可以共用 */ String keyGenerator() default ""; /** * 设定要使用的cacheManager,必须先设置好cacheManager的bean,这是使用该bean的名字 */ String cacheManager() default ""; /** * 使用cacheResolver来设定使用的缓存,用法同cacheManager,但是与cacheManager不可以同时使用 */ String cacheResolver() default ""; /** * 使用SpEL表达式设定出发缓存的条件,在方法执行前生效 */ String condition() default ""; /** * 使用SpEL设置出发缓存的条件,这里是方法执行完生效,所以条件中可以有方法执行后的value */ String unless() default ""; /** * 用于同步的,在缓存失效(过期不存在等各种原因)的时候,如果多个线程同时访问被标注的方法 * 则只允许一个线程通过去执行方法 */ boolean sync() default false;}package com.rickiyang.learn.cache;import com.rickiyang.learn.entity.User;import org.springframework.cache.annotation.CacheEvict;import org.springframework.cache.annotation.CachePut;import org.springframework.cache.annotation.Cacheable;import org.springframework.stereotype.Service;/** * @author: rickiyang * @date: 2019/6/15 * @description: 本地cache */ class UserCacheService { /** * 查找 * 先查缓存,如果查不到,会查数据库并存入缓存 * @param id */ (value = "userCache", key = "#id", sync = true) public void getUser(long id){ //查找数据库 } /** * 更新/保存 * @param user */ @CachePut(value = "userCache", key = "#user.id") public void saveUser(User user){ //todo 保存数据库 } /** * 删除 * @param user */ @CacheEvict(value = "userCache",key = "#user.id") public void delUser(User user){ //todo 保存数据库 }}
@Cacheable(key = "targetClass + methodName +#p0")
往 期 推 荐
1、Log4j2维护者吐槽没工资还要挨骂,GO安全负责人建议开源作者向公司收费 2、太难了!让程序员崩溃的8个瞬间 3、2021年程序员们都在用的神级数据库 4、Windows重要功能被阉割,全球用户怒喷数月后微软终于悔改 5、牛逼!国产开源的远程桌面火了,只有9MB 支持自建中继器! 6、摔到老三的 Java,未来在哪? 7、真香!用 IDEA 神器看源码,效率真高! 点分享
点收藏
点点赞
点在看




