
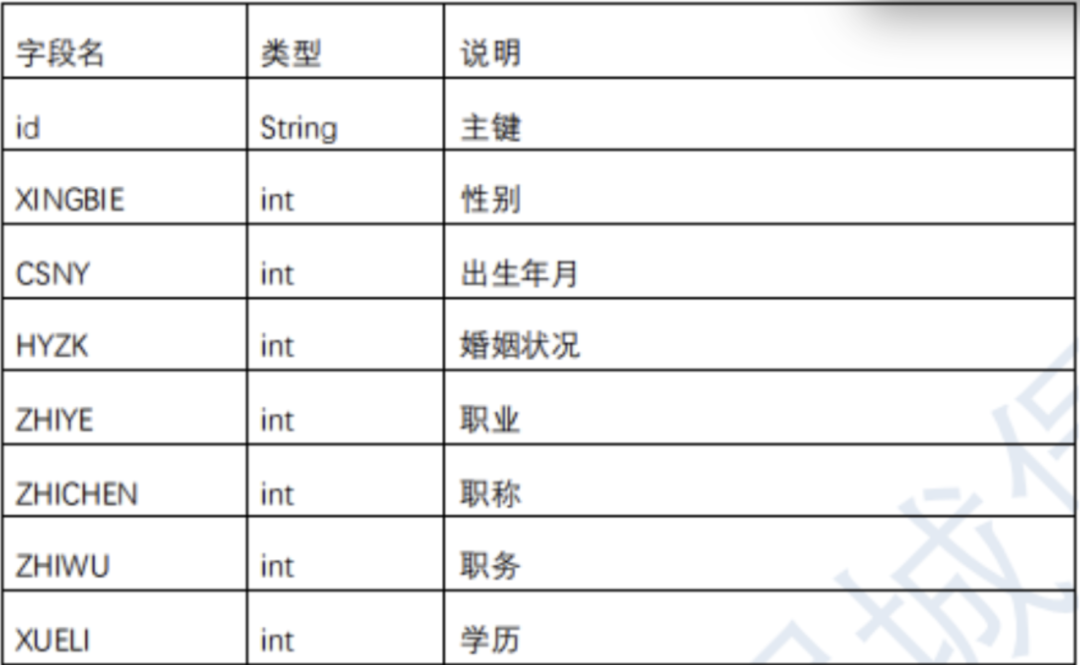
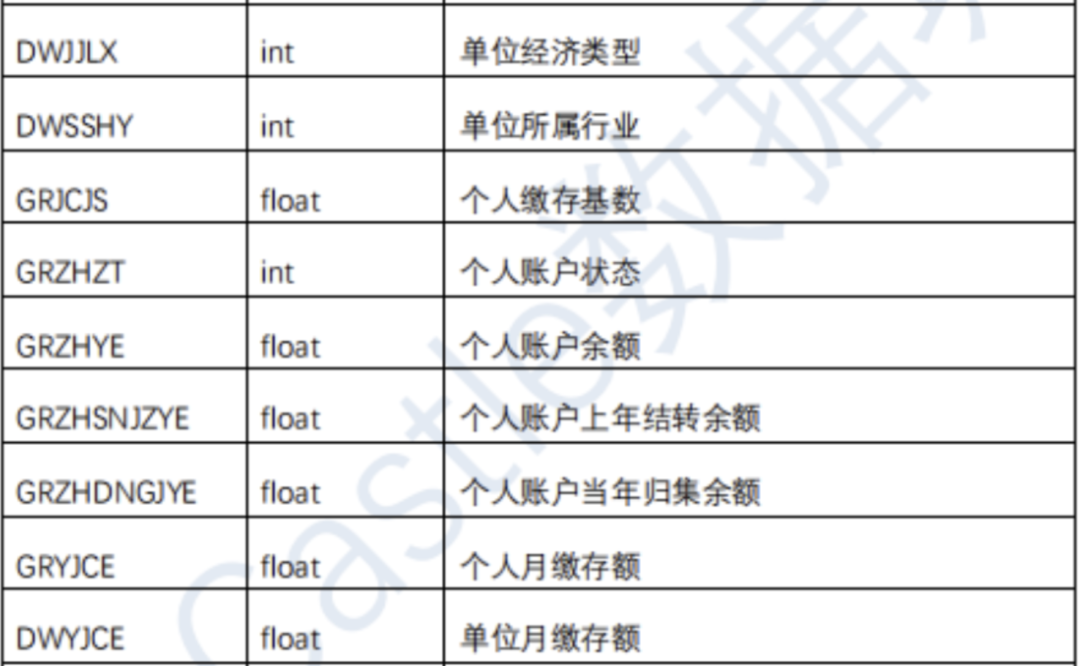
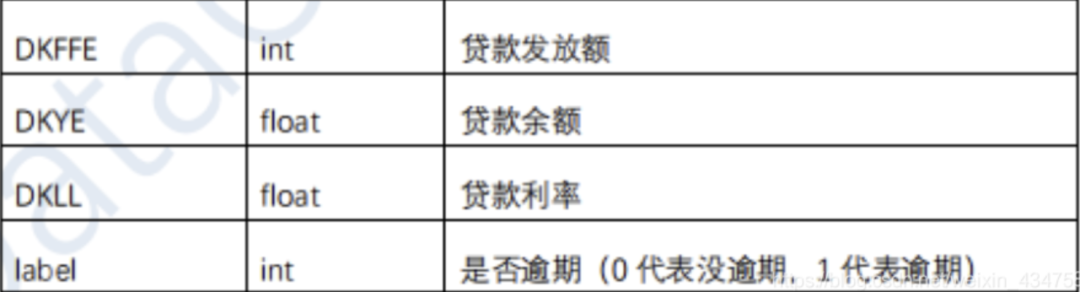
公积金贷款逾期预测

向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
维持和发展信用关系,是保护社会经济秩序的重要前提。随着金融市场的发展,信贷业务日益增多,金融机构迫切需要了解信贷主体的信息情况,对信贷资产的安全性、信贷主体的偿债能力给与科学评价,最大限度地防范贷款逾期风险。
本题的目标是从真实场景和实际应用出发,利用个人的基本身份信息、个人的住房公积金缴存和贷款等数据信息,来建立准确的风险控制模型,来预测用户是否会逾期还款。
赛题一共提供了40000带标签训练集样本,15000不带标签的测试集样本,需要注意的是本赛题测试样本包含干扰样本(干扰样本不参与得分计算),未可得知这些样本究竟是真样本但不参与评测还是本身就是代码生成的假样本,这可能会在很大程度上影响样本的分布。数据仅有一张表,一共有19个基本特征,且均不包含任何缺失值。
评价指标
本次比赛成绩排名根据测试集的在公积金逾期风险监控中,需要尽可能做到尽可能少的误伤和尽可能准确地探测,于是我们选择“在FPR较低时的TPR加权平均值”作为平均指标。
给定一个阀值,可根据混淆矩阵计算TPR(覆盖率)和FPR(打扰率) TPR = TP /(TP + FN) FPR = FP /(FP + TN) 其中,TP、FN、FP、TN分别为真正例、假反例、假正例、真反例。这里的评分指标,首先计算了3个覆盖率TPR:TPR1:FPR=0.001时的TPR TPR2:FPR=0.005时的TPR TPR3:FPR=0.01时的TPR 最终成绩= 0.4 * TPR1 + 0.3 * TPR2 + 0.3 * TPR3 代码如下:
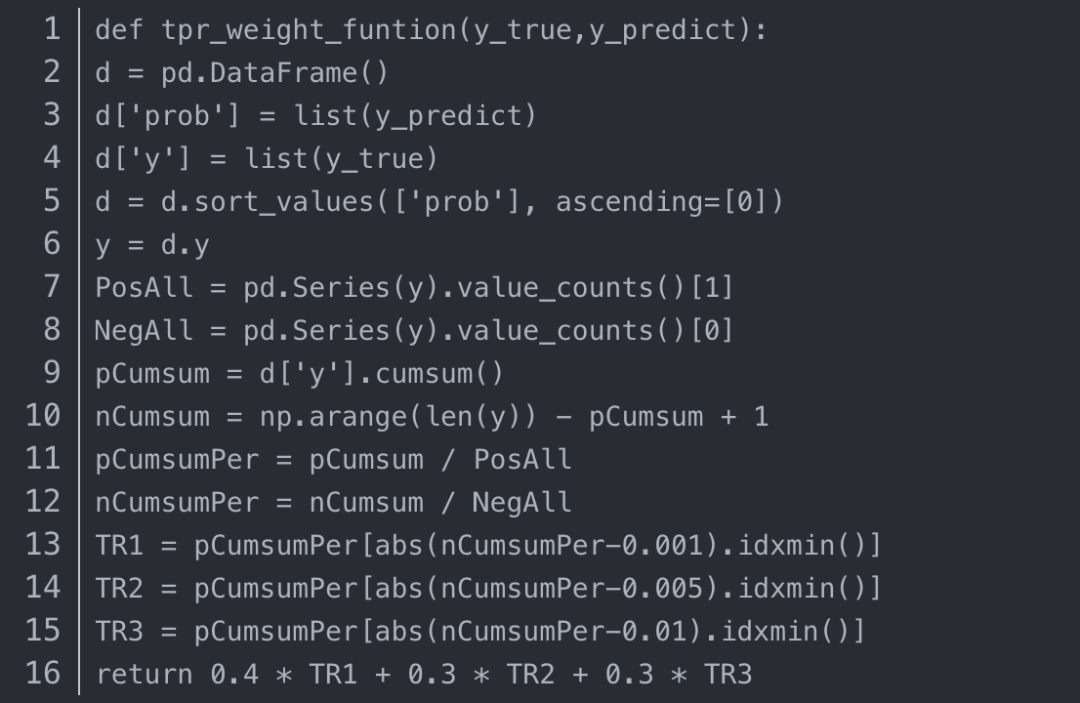
代码 获取方式:
关注微信公众号 datayx 然后回复 公积金 即可获取。
数据清洗
模型决定下限,特征决定上限,而数据清洗是做出良好特征的关键。
对于该赛题而言,做好的数据清洗,tpr就可以到55+,如果能够再结合实际业务场景,做出一些业务性很强的特征,拿到top10的成绩不难。首先根据说明,原始数据是经过脱敏的,而且人为的加入了一些噪声。数据的噪声肯定会极大的影响我们的模型表现,所以深入挖掘数据的规律,对数据进行去噪恢复真值的操作尤为重要。下面主要说两个关键点:
1.为何要对一些原始数值型特征减去237这个magic number??
可能很多选手很迷惑,看了赛后的top开源代码也不知为何。找到这个点的关键在于结合业务分析数据。对于山东省日照市的公积金相关的各项指标我们是可以在官网查到的。根据公积金计算常见公式:
个人缴存比例=个人月缴存额/个人缴存基数
而根据我们在官网查到的缴存比例是固定值,5%~12%。但所给的数据通过计算个人月缴存额/个人缴存基数的出来的数据却不符合这个规律。进一步通过观察一些样本很容易发现,如果对原始数据-237即可将数据恢复到真实值。而这个缴存比例对于我们的预测结果来说是一个很强的特征,这个从直观上来看也是合理的,如果无法得到一个准确的缴存比例就反映不出固定人群的特征。而且更为重要的是,我们还可以根据缴存比例的特征衍生出更多的强特,如果一开始就有误差,那么这样的误差累积对模型表现是有致命影响的。
2.利率的去噪?? 可能很多选手还没反应过来,还能对利率进行去噪??通过观察原始利率数据的unique特征不难发现,所有的利率数据都是具有噪声的,因为根据业务知识,利率就那几种:长期利率:2.75,短期利率:3.25.而第一套房和第二套房的利率有所不同,第二套房需要增加0.1的利率。所以根据这些知识我们完全可以仅仅利用利率信息挖掘出这么多的用户画像特征。对于原始数据中的某些异常值,只要仔细观察,还可以发现很多值不满足2.75,3.25,或者二套房利率,但他们和2.75,325却是12倍的关系,可以推测这些利率很可能是以月的形式出现,这样我们就可以将它统一到年利率。最终可以得到利率的真实值最多有8种可能,我们只需要根据就近原则将这些加了噪声的数据恢复到离自己最近的那个利率即可很大程度的实现去噪的目的。
特征工程
经过上面的数据清洗,我们可以得到较为干净的数据,此时根据公积金贷款的一些专业知识可以做出一些强特
一些数值特征比如:
贷款余额/贷款发放额,甚至可以结合利率进行精细计算
根据缴存基数得到收入
收入/贷款
账户余额/当年归集
...等等
一些类别特征:
根据复原的利率判断 长期贷款?短期贷款?
根据利率得到是否是 一套房?多套房?
单位所属行业,单位所属类型
...等等
类别与类别/类别与数值之间的交叉特征:类别与类别的交叉特征GBDT等树模型是可以自动学习到的,但有时候手动的做一些特征也无妨,这里项重点强调的是类别与数值的聚合特征,假设我们以一个类别进行groupby,然后统计每一个类别里面对应的该数值特征的均值,方差,最大,最小统计量等特征,一定程度上刻画了这个样本所在一个圈子的特征。这样往往可以做出很多的强特,从实际场景上来讲,中相当于是对用户更具某一个类别特征进行了归类,然后集中统计了下属于这个圈子的群体特征。举个例子就很好理解:按照单位类型进行聚合,比如在体制外这个类别中,收入均值是x,如果某一个样本的收入远远不如这个均值,那么它可能就属于会逾期的那种情况,当然这也是结合其它的特征来判断。这个例子可能不是很恰当,但能一定程度上体现出这种聚合统计特征的重要性。
通过上面的特征工程,如果加上暴力的加减乘除特征(暴力特征往往引入很多无意义的特征列),可以轻易做到上千维,如何进行特征筛选又是一个问题.
如何特征筛选?
(1) 根据树模型的特征重要度,K折CV,将每一折的重要性进行记录,最后取重要性的平均。或者同时训练xgboost,lightgbm,catboost等模型然后多个模型重要度的排序综合考虑
(2) 结合协方差的筛选,其实就是基于特征和目标的相关性来判断。某种程度,该方法比树模型重要度更靠谱
(3) nullImportance 。这也是本次比赛使用的方法,核心思想就是打乱数据标签,训练树模型,得到重要度,该过程可以训练多轮,然后将得到的重要度和为未打乱的数据训练得到的重要度进行一个比较。如果一个特征在打乱前重要度和打乱后的重要性差距很大,说明这是一个重要且靠谱的特征。
机器学习算法AI大数据技术
搜索公众号添加: datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx