
15个目标检测开源数据集
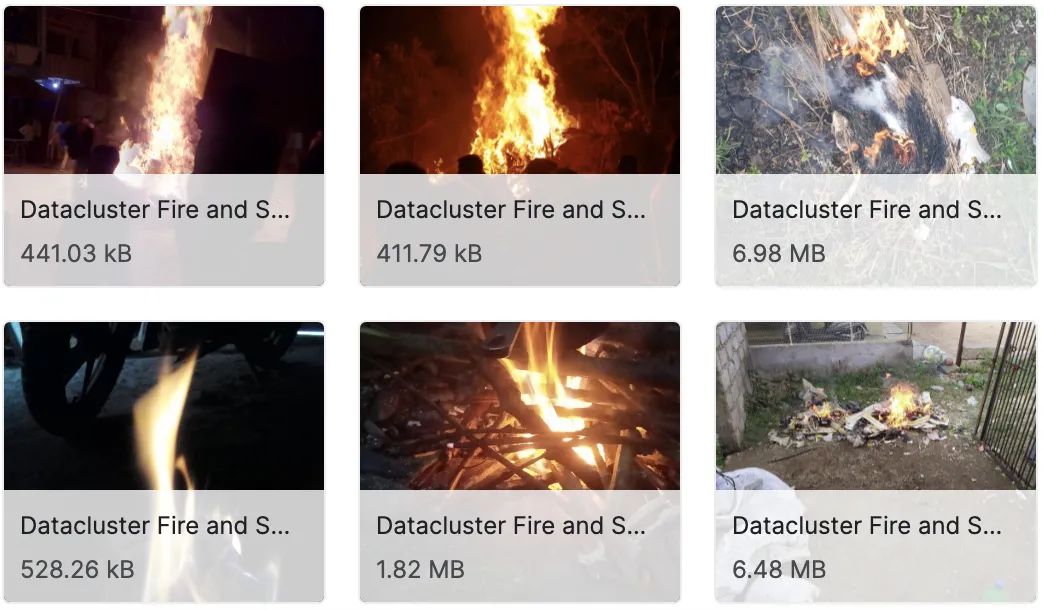
1.火焰和烟雾图像数据集
数据集链接:http://m6z.cn/6fzn0f
该数据集由早期火灾和烟雾的图像数据集组成。数据集由在真实场景中使用手机拍摄的早期火灾和烟雾图像组成。大约有7000张图像数据。图像是在各种照明条件(室内和室外场景)、天气等条件下拍摄的。该数据集非常适合早期火灾和烟雾探测。数据集可用于火灾和烟雾识别、检测、早期火灾和烟雾、异常检测等。数据集还包括典型的家庭场景,如垃圾焚烧、纸塑焚烧、田间作物焚烧、家庭烹饪等。本文仅含100张左右。
2.DOTA航拍图像数据集
DOTA是用于航空图像中目标检测的大型数据集。它可以用于开发和评估航空图像中的目标探测器。这些图像是从不同的传感器和平台收集的。每个图像的大小在800×800到20000×20000像素之间,包含显示各种比例、方向和形状的对象。DOTA图像中的实例由航空图像解释专家通过任意(8 d.o.f.)四边形进行注释。

3. AITEX数据集
数据集链接:http://m6z.cn/5DdJL1
该数据库由七个不同织物结构的245张4096 x 256像素图像组成。数据库中有140个无缺陷图像,每种类型的织物20个,除此之外,有105幅纺织行业中常见的不同类型的织物缺陷(12种缺陷)图像。图像的大尺寸允许用户使用不同的窗口尺寸,从而增加了样本数量。

4. T-LESS数据集
数据集链接:http://m6z.cn/5wnucm
该数据集采集的目标为工业应用、纹理很少的目标,同时缺乏区别性的颜色,且目标具有对称性和互相关性,数据集由三个同步的传感器获得,一个结构光传感器,一个RGBD sensor,一个高分辨率RGBsensor,从每个传感器分别获得了3.9w训练集和1w测试集,此外为每个目标创建了2个3D model,一个是CAD手工制作的另一个是半自动重建的。训练集图片的背景大多是黑色的,而测试集的图片背景很多变,会包含不同光照、遮挡等等变换(之所以这么做作者说是为了使任务更具有挑战性)。
同时作者解释了本数据集的优势在于:1.大量跟工业相关的目标;2.训练集都是在可控的环境下抓取的;3.测试集有大量变换的视角;4.图片是由同步和校准的sensor抓取的;5.准确的6D pose标签;6.每个目标有两种3D模型;

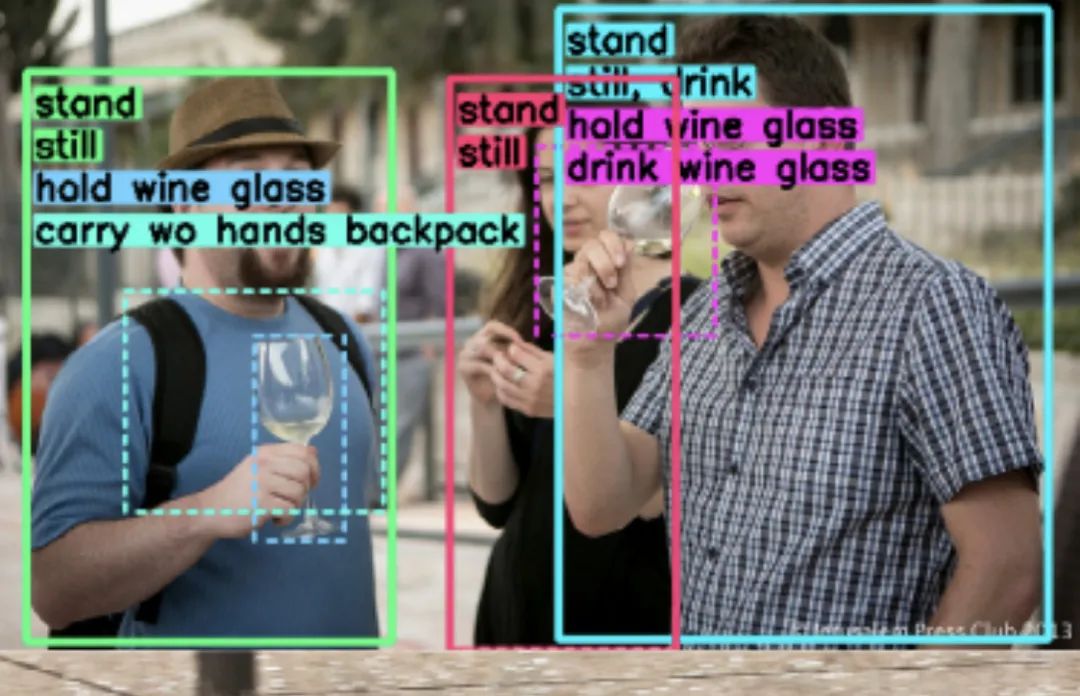
5.H²O 行人交互检测数据集
数据集链接:http://m6z.cn/6fzmQf
H²O由V-COCO数据集中的10301张图像组成,其中添加了3635张图像,这些图像主要包含人与人之间的互动。所有的H²O图像都用一种新的动词分类法进行了注释,包括人与物和人与人之间的互动。该分类法由51个动词组成,分为5类:
描述主语一般姿势的动词 与主语移动方式有关的动词 与宾语互动的动词 描述人与人之间互动的动词 涉及力量或暴力的互动动词
6.SpotGarbage垃圾识别数据集
数据集链接:http://m6z.cn/5ZMmRG
图像中的垃圾(GINI)数据集是SpotGarbage引入的一个数据集,包含2561张图像,956张图像包含垃圾,其余的是在各种视觉属性方面与垃圾非常相似的非垃圾图像。

7.NAO自然界对抗样本数据集
数据集链接:http://m6z.cn/5KJWJA
NAO包含7934张图像和9943个对象,这些图像未经修改,代表了真实世界的场景,但会导致最先进的检测模型以高置信度错误分类。与标准MSCOCO验证集相比,在NAO上评估时,EfficientDet-D7的平均精度(mAP)下降了74.5%。

8.Labelme 图像数据集
数据集链接:http://m6z.cn/5Sg9NX
Labelme Dataset 是用于目标识别的图像数据集,涵盖 1000 多个完全注释和 2000 个部分注释的图像,其中部分注释图像可以被用于训练标记算法 ,测试集拥有来自于世界不同地方拍摄的图像,这可以保证图片在续联和测试之间会有较大的差异。该数据集由麻省理工学院 –计算机科学和人工智能实验室于 2007 年发布,相关论文有《LabelMe: a database and web-based tool for image annotation》。

9.印度车辆数据集
数据集链接:http://m6z.cn/6uxAIx
该数据集包括小众印度车辆的图像,如Autorikshaw、Tempo、卡车等。该数据集由用于分类和目标检测的小众印度车辆图像组成。据观察,这些小众车辆(如autorickshaw、tempo、trucks等)上几乎没有可用的数据集。这些图像是在白天、晚上和晚上的不同天气条件下拍摄的。该数据集具有各种各样的照明、距离、视点等变化。该数据集代表了一组非常具有挑战性的利基类车辆图像。该数据集可用于驾驶员辅助系统、自动驾驶等的图像识别和目标检测。

10.Seeing 3D chairs椅子检测模型
数据集链接:http://m6z.cn/5DdK0v
椅子数据集包含大约1000个不同三维椅子模型的渲染图像。

11.SUN09场景理解数据集
数据集链接:http://m6z.cn/60wX8r
SUN09数据集包含12000个带注释的图像,其中包含200多个对象类别。它由自然、室内和室外图像组成。每个图像平均包含7个不同的注释对象,每个对象的平均占用率为图像大小的5%。对象类别的频率遵循幂律分布。发布者使用 397 个采样良好的类别进行场景识别,并以此搭配最先进的算法建立新的性能界限。
该数据集由普林斯顿视觉与机器人实验室于 2014 年发布,相关论文有《SUN Database: Large-scale Scene Recognition from Abbey to Zoo》、《SUN Database: Exploring a Large Collection of Scene Categories》。
12.Unsplash图片检索数据集
数据集链接:http://m6z.cn/5wnuoM
使用迄今为止公开共享的全球最大的开放检索信息数据集。Unsplash数据集由250000多名贡献摄影师创建,并包含了数十亿次照片搜索的信息和对应的照片信息。由于Unsplash数据集中包含广泛的意图和语义,它为研究和学习提供了新的机会。

13.HICO-DET人物交互检测数据集
数据集链接:http://m6z.cn/5DdK6D
HICO-DET是一个用于检测图像中人-物交互(HOI)的数据集。它包含47776幅图像(列车组38118幅,测试组9658幅),600个HOI类别,由80个宾语类别和117个动词类别构成。HICO-DET提供了超过150k个带注释的人类对象对。V-COCO提供了10346张图像(2533张用于培训,2867张用于验证,4946张用于测试)和16199人的实例。

14.上海科技大学人群统计数据集
数据集链接:http://m6z.cn/5Sgafn
上海科技数据集是一个大规模的人群统计数据集。它由1198张带注释的群组图像组成。数据集分为两部分,A部分包含482张图像,B部分包含716张图像。A部分分为训练和测试子集,分别由300和182张图像组成。B部分分为400和316张图像组成的序列和测试子集。群组图像中的每个人都有一个靠近头部中心的点进行注释。总的来说,该数据集由33065名带注释的人组成。A部分的图像是从互联网上收集的,而B部分的图像是在上海繁忙的街道上收集的。

15.生活垃圾数据集
数据集链接:http://m6z.cn/6n5Adu
大约9000多张独特的图片。该数据集由印度国内常见垃圾对象的图像组成。图像是在各种照明条件、天气、室内和室外条件下拍摄的。该数据集可用于制作垃圾/垃圾检测模型、环保替代建议、碳足迹生成等。

版权申明:内容来源网络,版权归原创者所有。除非无法确认,都会标明作者及出处,如有侵权,烦请告知,我们会立即删除并致歉!