
基于Seq2Seq模型自动生成春联

向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
一、【数据集构造】
诗词歌句属于自然语言一部分,对于计算机来说自然需要对数据进行数字化处理。其中步骤主要分成分词、编码、数据集输入输出构造。
1、分词方面
传统自然语言处理在分词方面使用“词”为划分粒度,以此来增加字间的关系,常见的编码包,比如jieba分词等。在数据集构造的时候,本文想到诗词与现代语言相比,更加凝练 ,一字可以有多义,比如“备”字,可以有“准备”、“具备”、”周全“这些意思,因此在诗词文本上采用了”字“为粒度的方式进行划分。而且这种方式,在代码上也好实现一些。
2、编码方面
分布式编码起源于Harris的分布假说,它认为某个单词的含义可以由上下文进行联合表示,认为相似的词会出现于相同语境(上下文)。本文出于诗词中存在一定的语义关系,前后联系的考虑,为了保留字间关联,本文使用了分布式编码的方式,使用Word2Vec的方式构建字向量,对汉字进行数字化。
3、数据输入输出安排
输入输出数据集分成四个部分,与后面模型结构相关:Encoder_inputs、Encoder_outputs、Decoder_inputs和Decoder_outputs,我们先来了解数据,后面模型部分会进行详细介绍划分原因。
第一、二部分Encoder部分
是为了训练一个上联生成模型Encoder,需要构造数据的输入encoder_inputs和encoder_outputs。为了增强句间的字的语序特征,本文提出使用”1:N”的方式,根据时序对诗句进行拆分,构造长度相同的数据集诗句。具体表现为下图1。
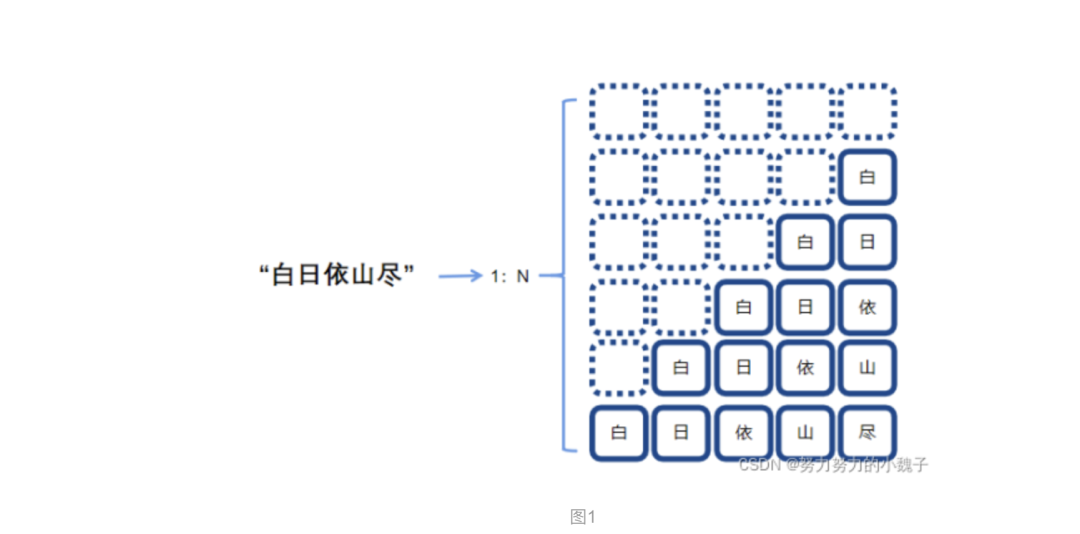
按照时序不同时刻输入的内容不同,字间相互错落一个时间间隔,一行将作为一个输入,对应下一个字为其输出,这样就仿真人们作诗的过程,一字一字生成诗句。使用“X”来表示空格,最后一个完整句对应输出为“END”表示结束。这样,一个N字诗句就将生成(n+1)*n的句子,大大增加了数据集大小,同时也强调了字在句子中的时序特征。比如输入为:“XXXX白”,输出对应“日”;下一个输入就是“XXX白日”,对应输出为“依”;如此构造出多个输入输出。
第三、四部分数据输出Decoder
是为了训练一个能根据上联encoder部分,而对应产生下联的模型。下联模型需要输入和上联模型思想不同,这时候我们输入是下联对应每一个字的前一个单字和上联的输出,将二者联合起来构建一个输入向量;而对应输出应该是真正对应位置的单字;所以输入部分也需要错落一个时间间隔。这样说比较抽象,我们举例来说明,如下图2所示。
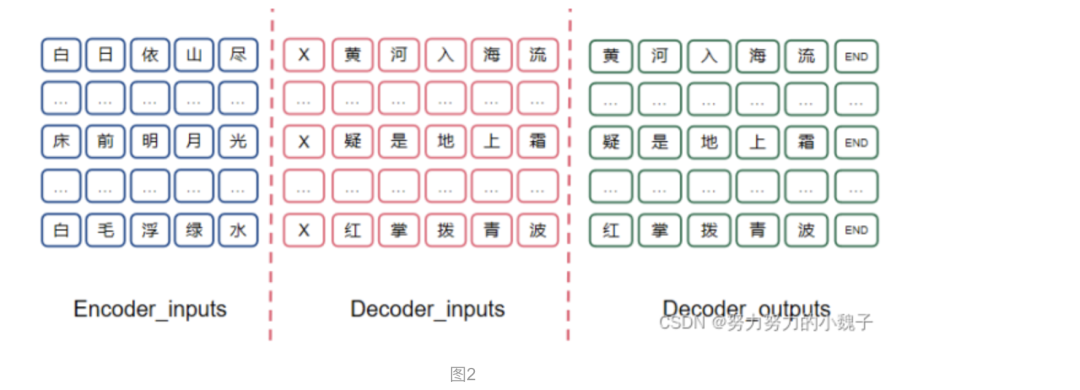
可以看到,上联encoder在Decoder模型的输入为“白日依山尽”,同时在Decoder模型中输入包括错落一个时间(或者说字)的单字,如“X”,对应输出应该是“黄”。其中“X”在这里表示句子的开始,“END”表示结束。
这样做的目的是为了仿照人们吟诗作对的思考过程,需要考虑上联的关系,同时也要考虑前一个字对后一个字生成的影响,其中可能包括平仄关系(这里没有强调,只是个猜想)。
二、【模型搭建】
在构建模型的时候,本文主要思量到的是数据的关系。首先需求上,我们研究的是自然语言,具有时序特点;其次,我们的自然语言处理方面需要联系到前后的关系;最后,要考虑人们吟诗作对的过程的模仿。
根据这些思想,本文参考了大量自然语言处理方面的应用资料,比如:模型翻译、英文小说自动生成等方面(本来应该贴上链接的,现在一回头找不到资料了,感谢各位大大……跪谢……),想到将翻译模型移植至古诗文生成模型中,框架是Seq2Seq模型,主要模型被我分成两个部分:连字成句模型 和 连句成对模型。模型的整体架构如下图3所示。
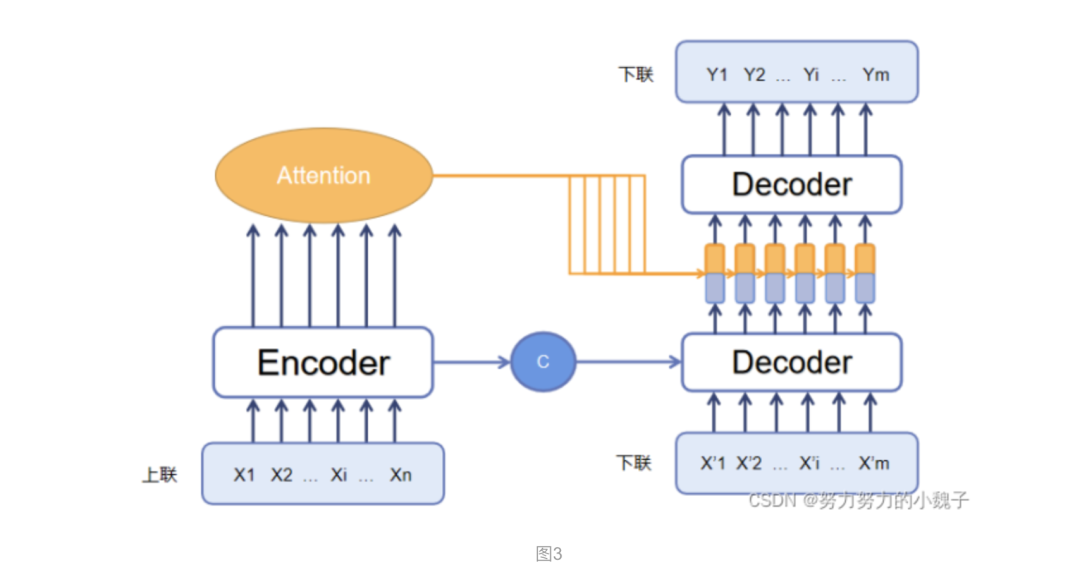
1、连字成句模型
这个部分属于Seq2Seq中Encoder部分,主要用于“首联”的生成。顾名思义,功能是用户输入一个单字,对应模型能够训练生成一整句最优句子。
诗词属于自然语言处理的一部分,具有前后的联系关系,所以选用时序关系的模型最好,常见有RNN。由于RNN在处理长序列句子中存在“梯度爆炸”和“梯度消失”的问题,所以本文选用的是LSTM模型,属于RNN的一种升级模式。同时,又由于一个LSTM只能保证一个单向语义联系,所以为了保留前后的关系,本文选用了双向的LSTM,也做BiLSTM。模型如下图4所示。
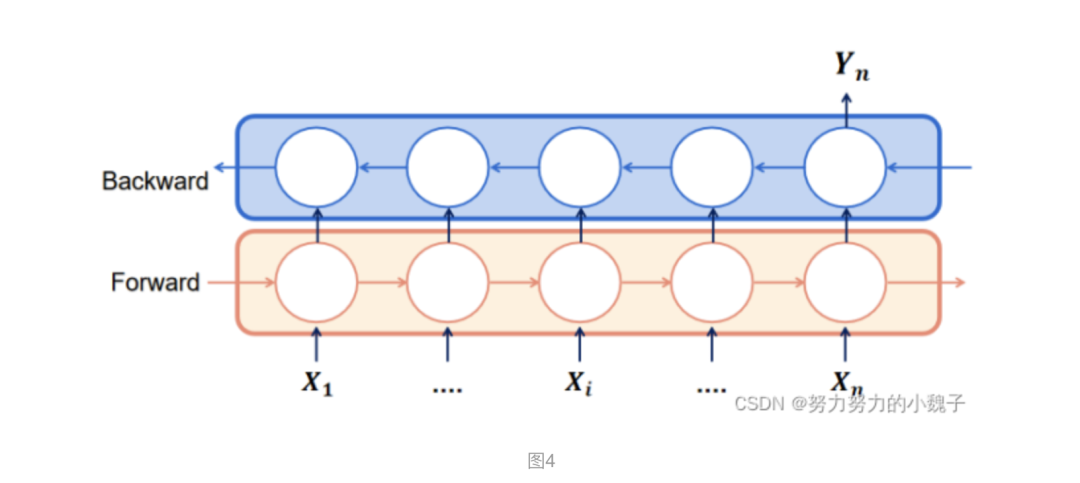
举例说明,联系上部分数据构造方面,输入的X1、X2……Xn是1:N的时序拆解内容,输出的Yn为对应时序下的单字输出。比如,输入”XXXX白“,对应输出Yn为”日”。
2、连句成对模型
连句成对模型功能是生成下联,属于Seq2Seq中Decoder部分。与上联模型不同的是,我们这时候输出是一整个句子(也就是把LSTM模型中每个时序的输出都输出)。模型结构如下图5所示。
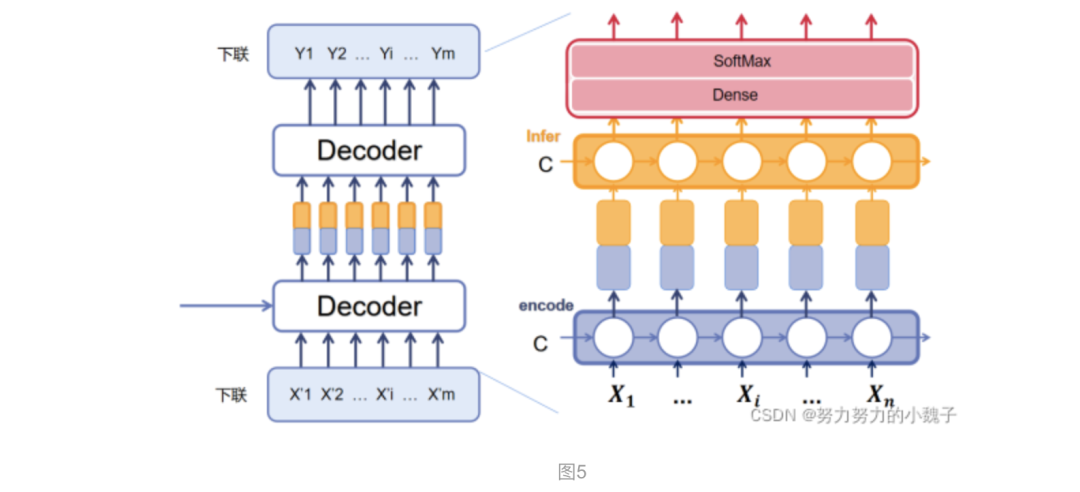
首先介绍的是图中Decoder的下面部分,本文把它称为是Decoder_encoder,也就是对下联的输入进行编码的意思。
本文参考人们吟诗作对的方式,认为下联的每个字的选择生成,和当前字前面的句子以及上联信息相关。所以Decoder_encoder部分我们选用了LSTM,生成前序向量;之后为了联系上联,我们想到上联中每个字实际应该侧重点各有不同,所以引入了Attention模型,将上联生成的句子进行Attention权值重分配,使得上联对下联每个字的影响权值各不相同。
比如“白日依山尽”为了生成”黄“字,显然”白“字的权值更应该大一些。前序序列的编码向量和Attention下的上联向量,本文将其进行纵向连接,也就是图上显示那样。两种颜色的拼接,将作为Decoder第二部分的输入。
其次是attention计算结构,如图6所示。
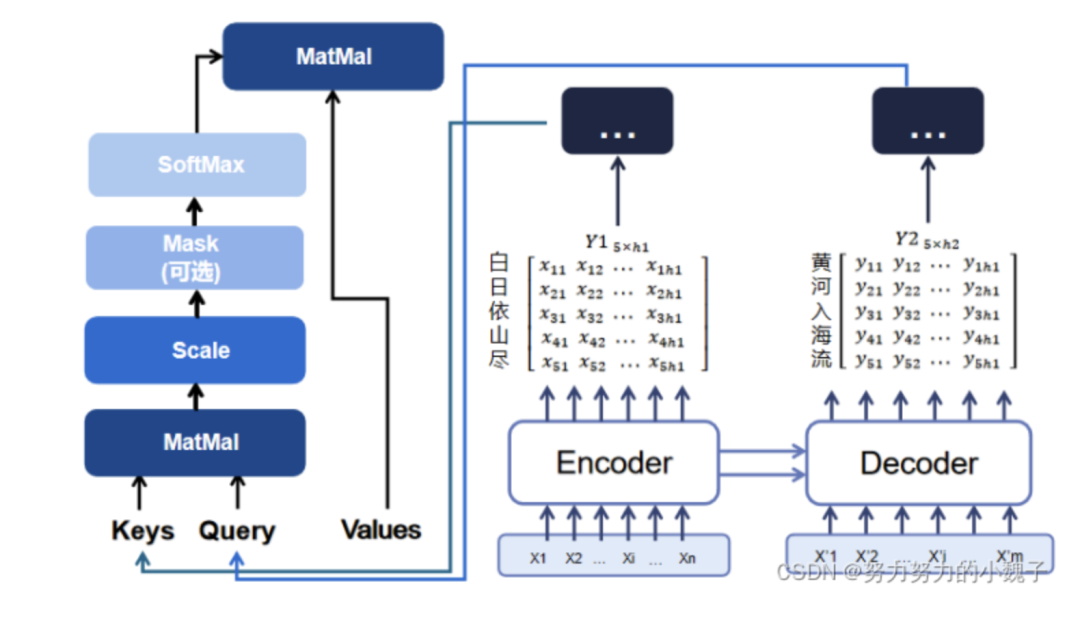
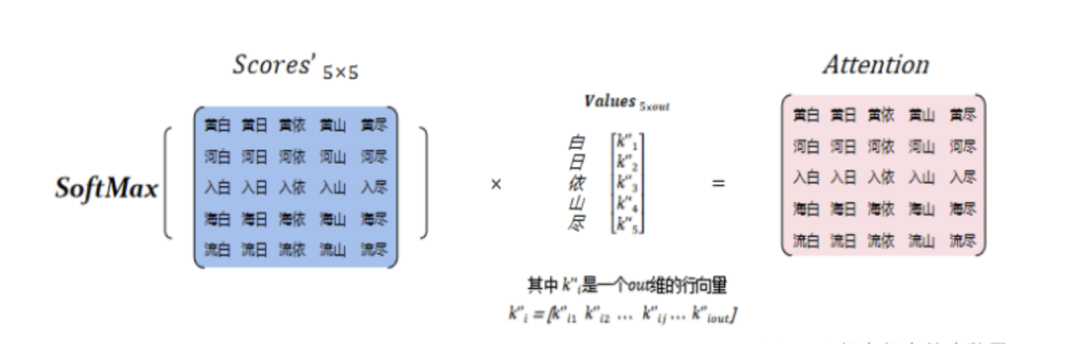
以“白日依山尽,黄河入海流”为例。
本文设Encoder的输出维度为h1,设Decoder编码encode层的输出维度为h2,Attention后的输出维度为out。
因此,Encoder对“白日依山尽”进行编码获得大小为[5,h1]的隐藏层输出Y1,此时Y1。Decoder对“黄河入海流”进行编码获得大小为[5, h2]的隐藏层输出Y2。
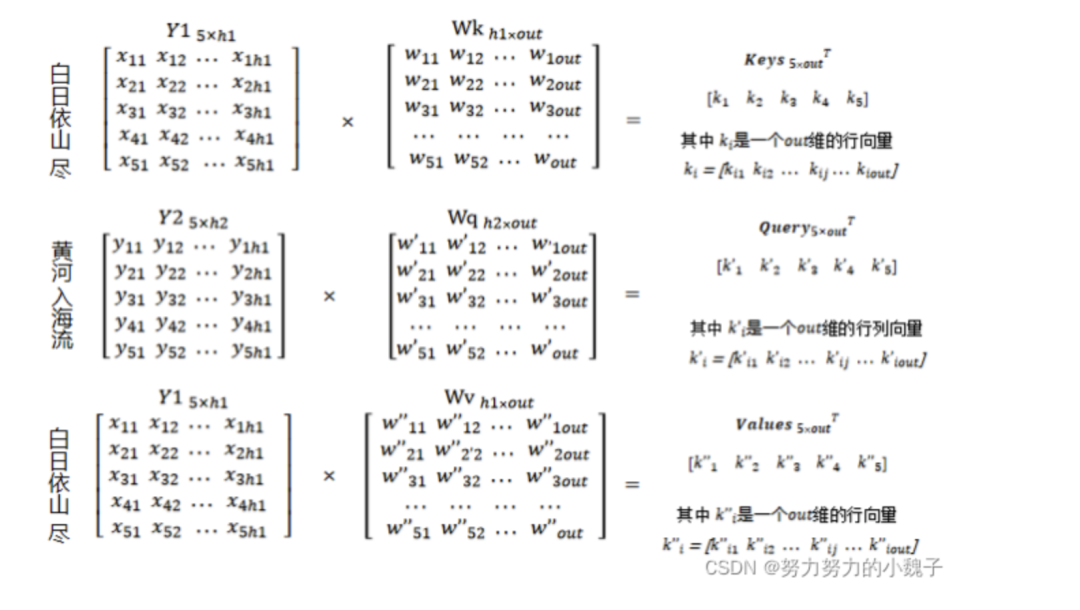
之后,我们需要随机生成权重矩阵Wq、(大小为[h2, out])、Wk、Wv(大小为[h1, out]),将Wq和Y2相乘生成大小为[5,out]的Query值;同理,Wk和Wv与Y1相乘生成大小为[5, out]的Keys和Values值,如图7所示。
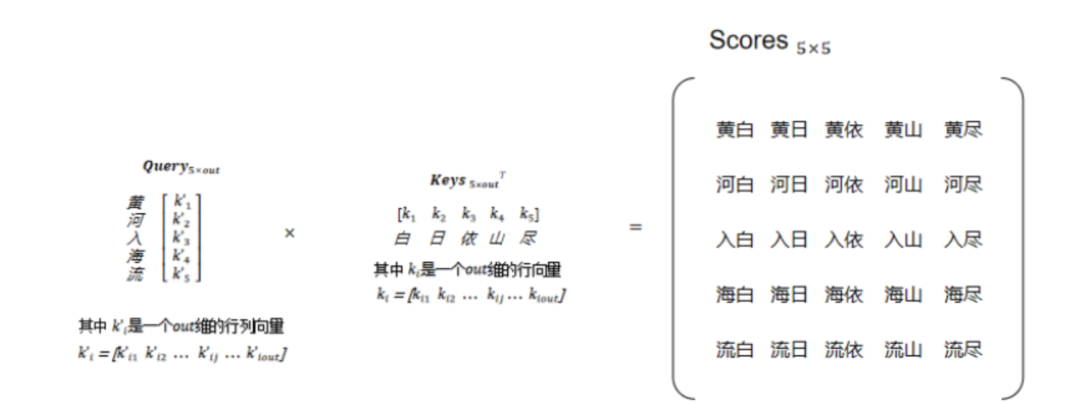
然后,对Keys矩阵进行转置变成[out, 5],通过点积方式计算出Query与Keys中各个key的得分Scores,矩阵得到大小为[5, 5],如图8所示。
为了防止产生过大的方差,因此需要对得分矩阵Scores进行缩放,除以维度的平方得到Scores’,大小为[5, 5]。将缩放后的Scores通过SoftMax函数进行概率转换,得到最终Query与Keys中每个Key的权重Probs。
最后,将Probs与Values进行点乘,获得大小为[5, out]的Attention值,如图9所示。
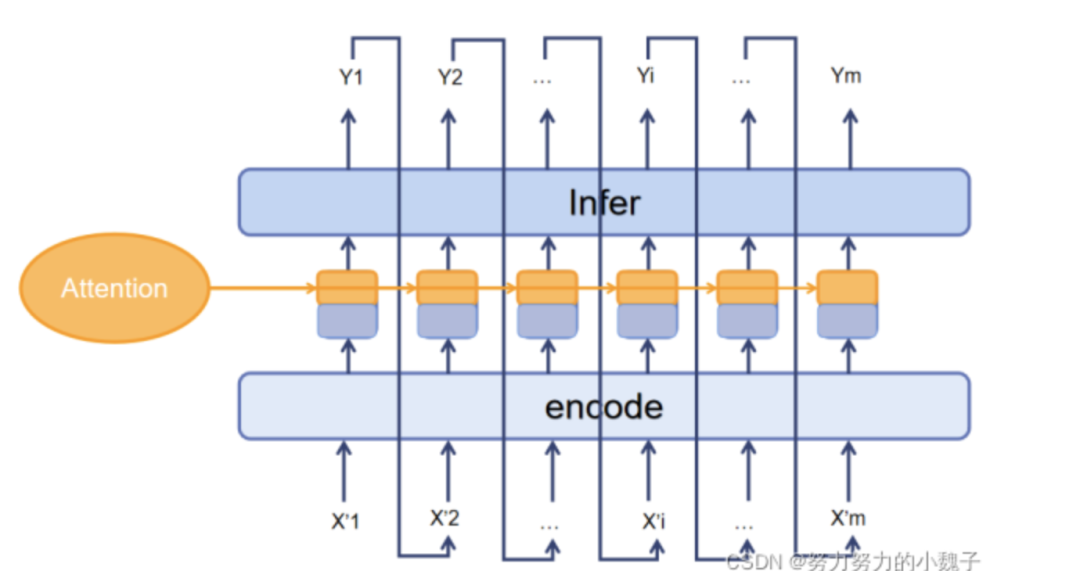
最后介绍的是图中Decoder的第二部分,本文称之为Decoder_infer,用于生成最后的句子。
Decoder_infer和一个SoftMax层相连,是为了让模型在我们的汉字字典里选出最有可能的生成字结果。前面的监督学习和Attention结果相结合已经生成了对应的组合输入向量,这时候我们就可以使用LSTM,将模型的每个神经元的输出打开,结合SoftMax生成最佳生成字,从而生成完整下联。值得注意的是,这一部分的模型在训练完成后,下联需要以一个链式的方式进行使用。如下图10所示。
本文使用python keras框架下编程。实验数据来源于一位名叫冯重朴_梨味斋散叶的博主的新浪博客,选用数据集中长度大小为7的对联作为本实验数据。下面将展示实验模型和实验结果。
相关代码,70万条对联数据集
获取方式:
关注微信公众号 datayx 然后回复 对联 即可获取。
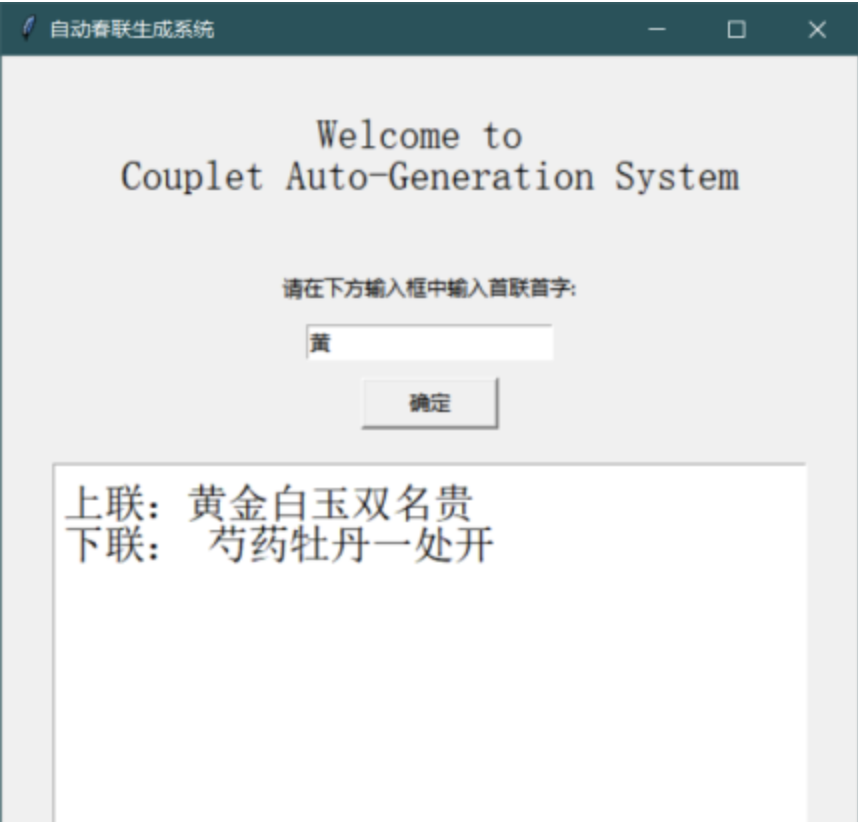
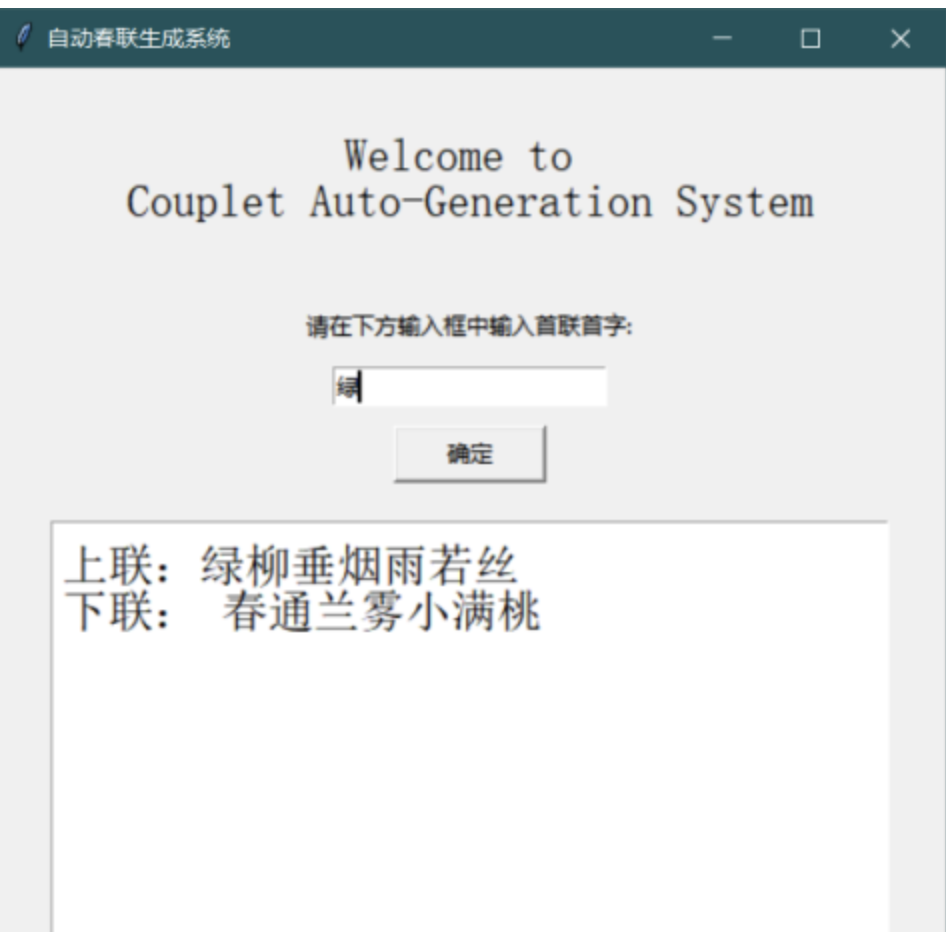
对联体验链接
https://ai.binwang.me/couplet/


机器学习算法AI大数据技术
搜索公众号添加: datanlp
长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx