
Serverless 可观测性的过去、现在与未来

背景
1. Serverless 将成为下一个十年云的默认编程范式
更多案例请参考函数计算用户案例。
广告时间:欢迎加入云原生Serverless 团队(函数计算,Serverless工作流,Serverless应用引擎),以公共云、集团、开源社区三位一体的方式打造业界领先的Serverless 产品体系。职位需求见JD,招聘长期有效,有兴趣的同学可以发送简历至 dehui.kdh@alibaba-inc.com。
2. 可观测性成为 Serverless 发展的绊脚石?
组件分布化:Serverless 架构的应用往往粘合多个云服务,请求需要流经多款云产品,一旦端到端延时变长或表现不符合预期,问题定位十分复杂,需要依次去各个产品侧逐步排查。
调度黑盒化:Serverless 平台承担着请求调度、资源分配的责任,实时弹性扩容会带来不可避免的冷启动,Serverless 的资源伸缩是无需开发者参与也不受开发者控制的。冷启动会影响端对端延时,这次请求有没有遇到冷启动,冷启动的时间都消耗在哪些步骤,有没有可优化的空间都是开发者急于知道的问题。
执行环境黑盒化:开发者习惯于在自己的机器上执行自己的代码,出了问题登录机器查看异常现场,查看执行环境的 CPU/内存/IO 情况。面对 Serverless 应用,机器不是自己的,登也登不上,看也看不了,开发者眼前一片漆黑。
产品非标化:在 Serverless 场景下,开发者无法控制执行环境,无法安装探针,无法使用开源的三方监控平台,调查问题的方式不得不发生改变,传统的调查问题经验无法施展,非常不顺手。
Serverless 下可观测性
可观测性是通过外部表现判断系统内部状态的衡量方式。
--维基百科
1. 可观测性 1.0
函数日志
基本指标
函数日志和指标使用详细信息请参考配置并查看函数日志/监控指标。
2. 可观测性 2.0 - 云原生的可观测

为了回答请求在函数计算的生命历程,串联分布式系统的上下游服务,拥抱开源可观测能力,我们集成了 OpenTracing,支持链路追踪。
为了暴露系统状态,提供应用级别监控,我们集成了 ARMS(Java),内置了 APM 能力。
为了加快端到端定位问题的速度,我们支持了请求级别指标(FCInsights),发布了监控中心,问题发现/调查一站式解决。
为了兼容开发者已有的用户体验,我们拥抱开源,集成 OpenTracing,支持 Grafana Dashboard;我们支持三方监控平台,实现代码几乎零改造接入APM 监控系统。
为了兼容传统开发者的可观测体验,支持探针安装,我们拓展了编程模型,支持函数 LifeCycle,为集成三方监控提供可能。

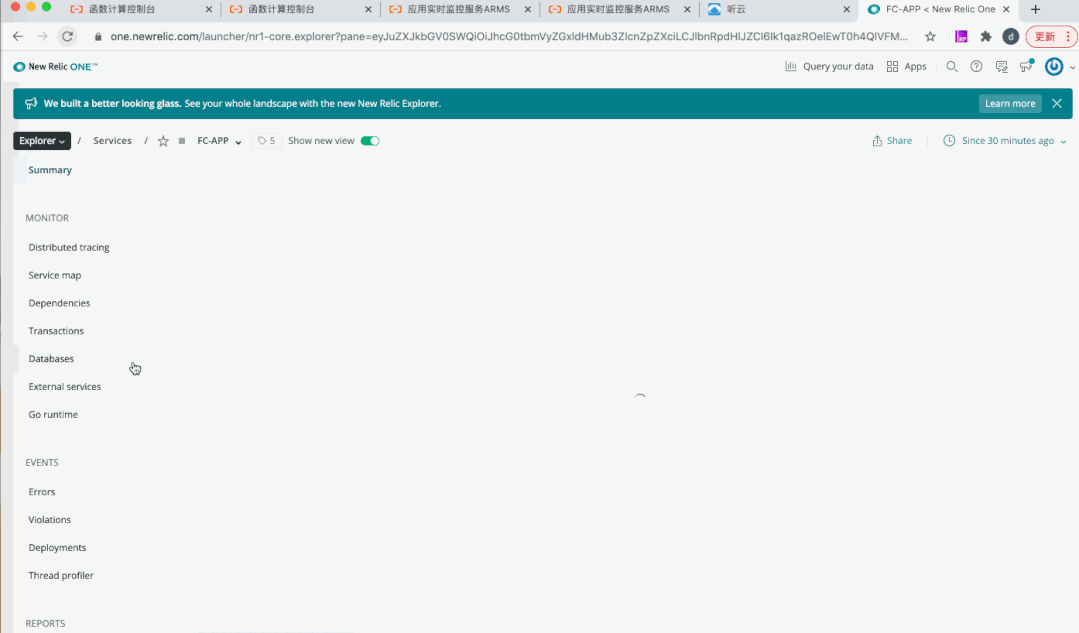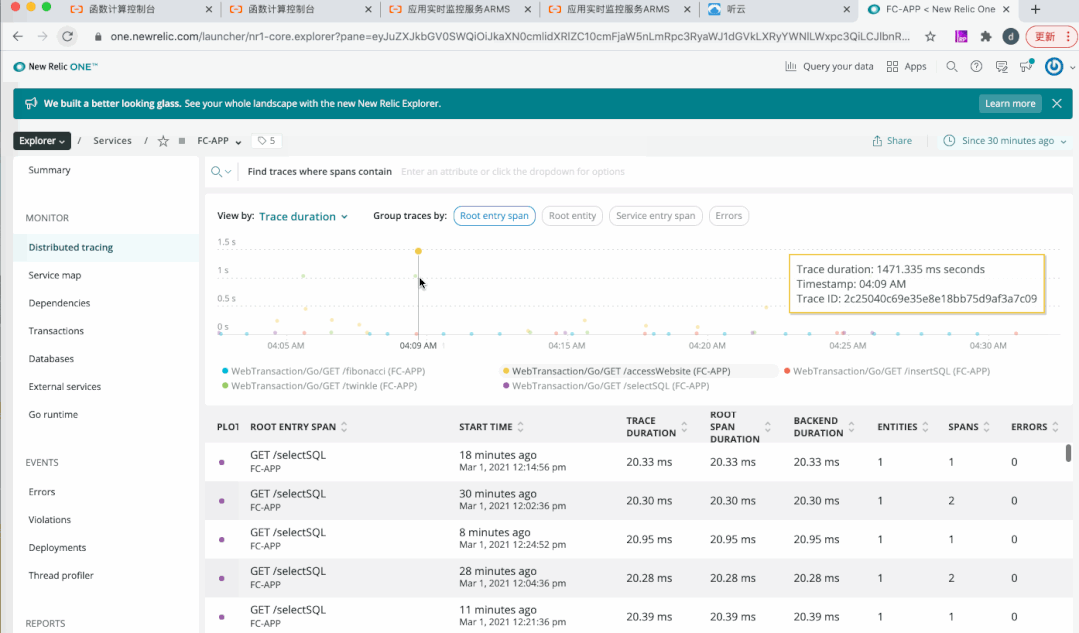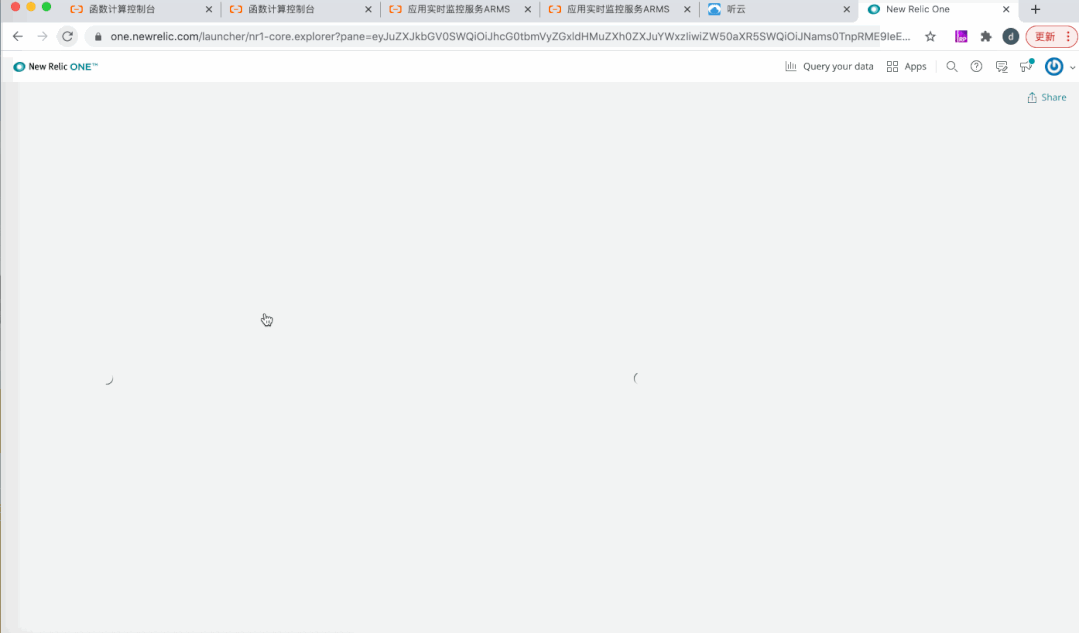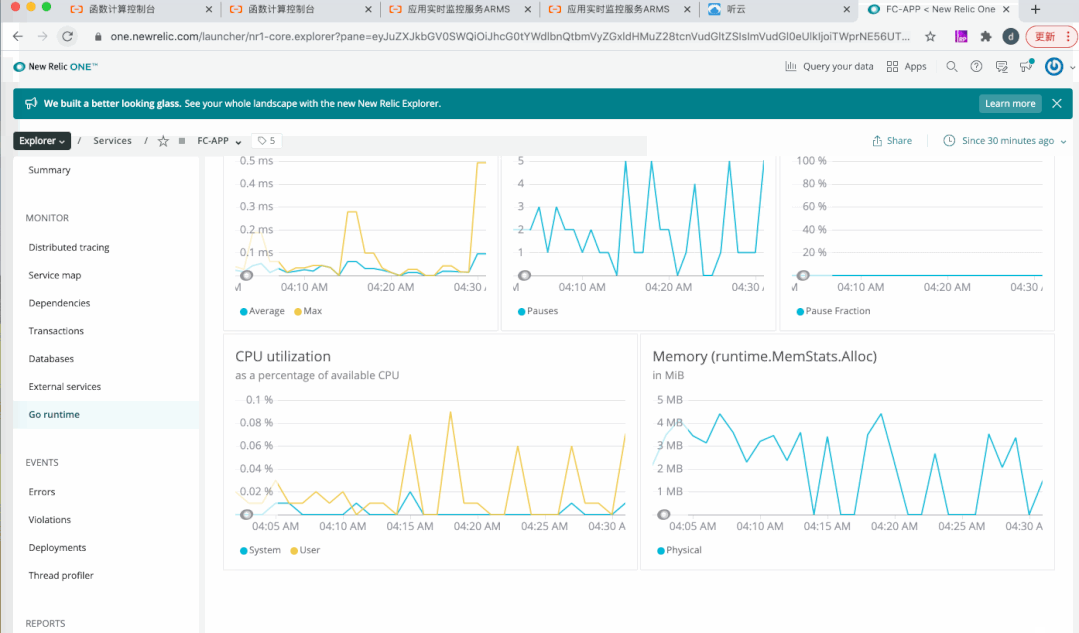
1)集成 OpenTracing,支持链路追踪
拥抱开源:完全兼容 OpenTracing 协议,没有附加学习成本。
主动记录:上报请求在函数计算中消耗的端对端时间。
调度透明:暴露代码准备时间与实例启动时间,是首个暴露冷启动延时与具体时间消耗的 FaaS 产品。
承上启下:串起上下游应用,既可以通过 span context 与上游应用连接,又将 span context 传入函数,连接下游服务。

2)集成 ARMS,内置 APM 能力
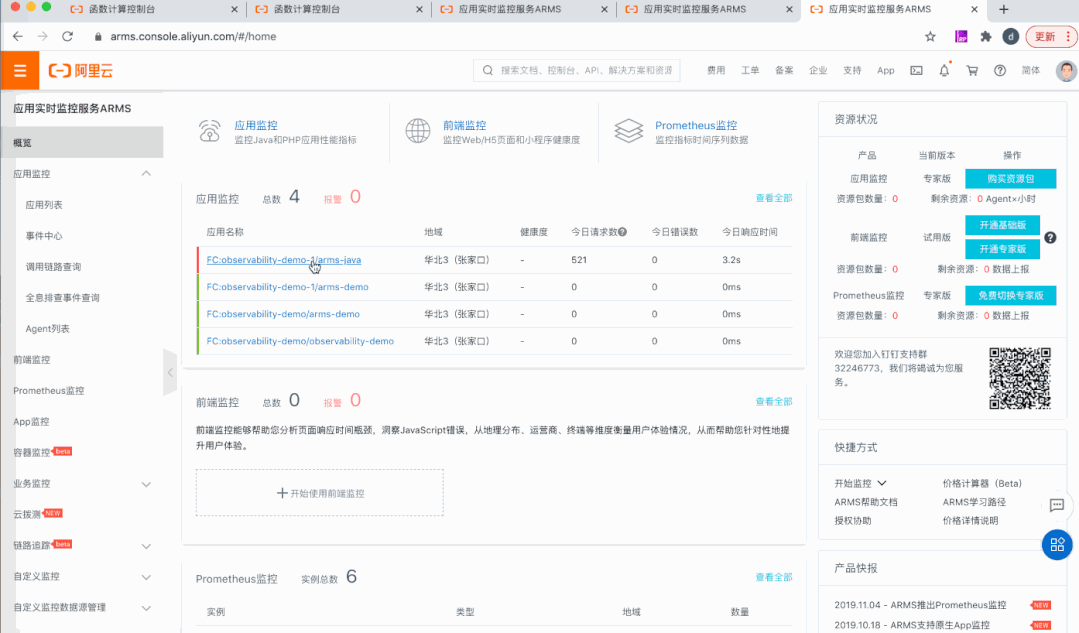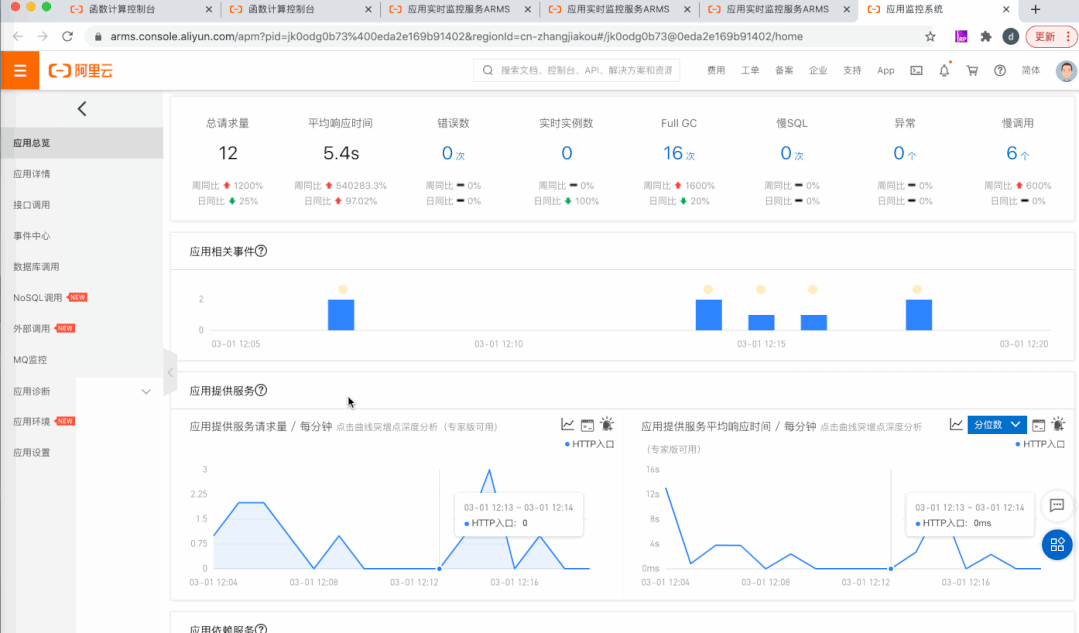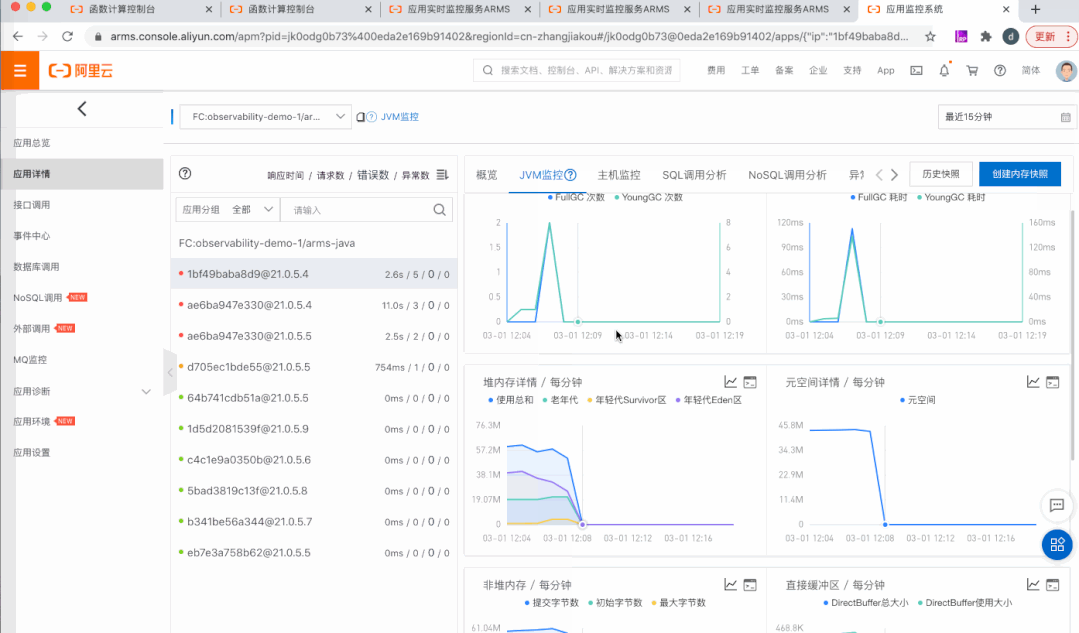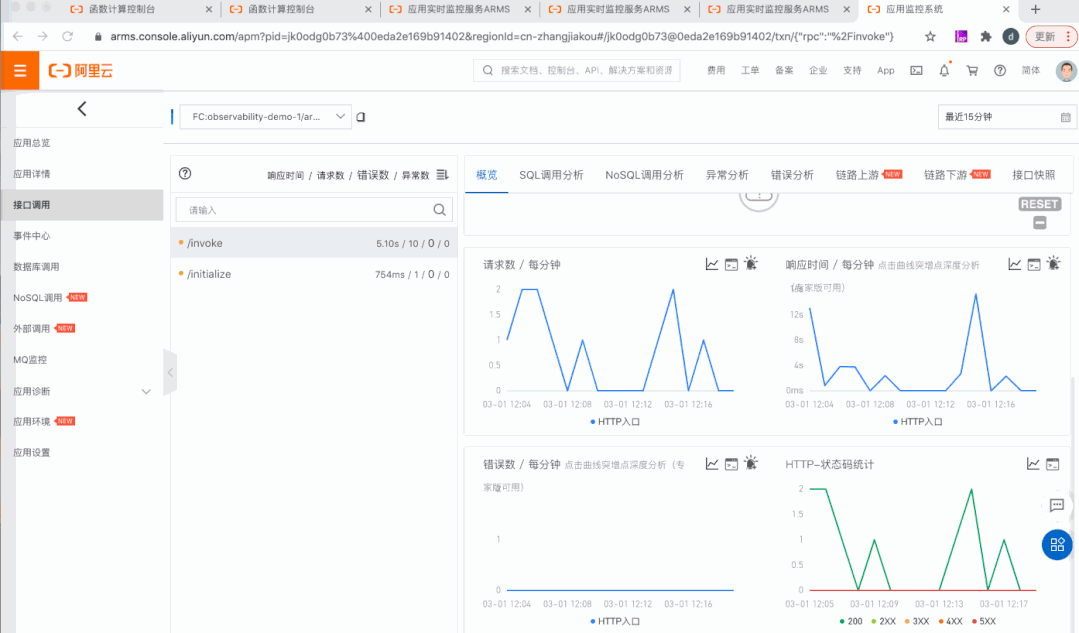
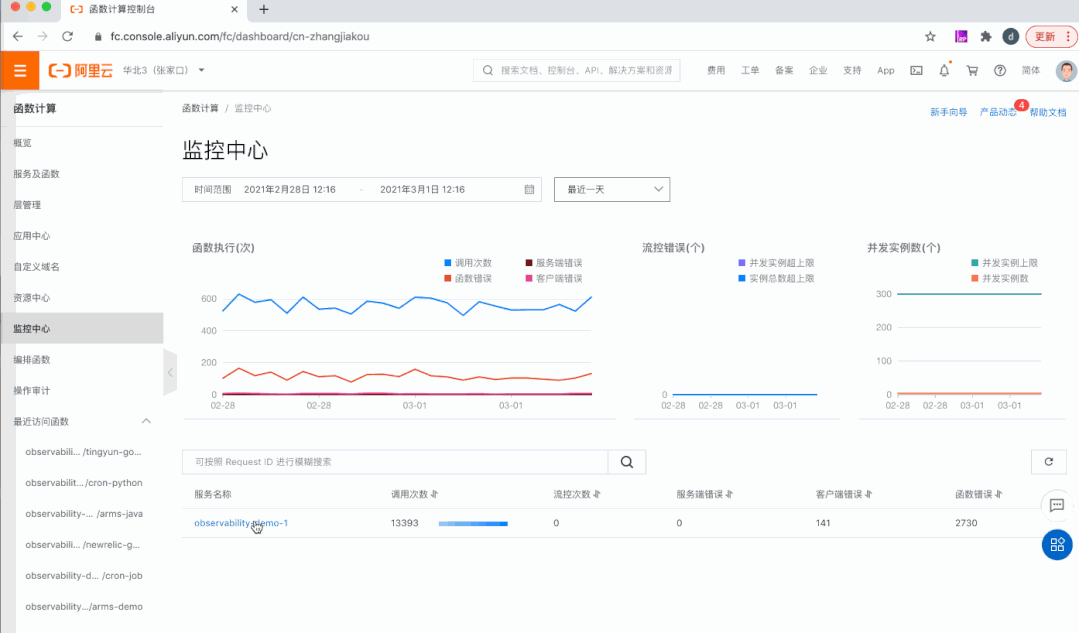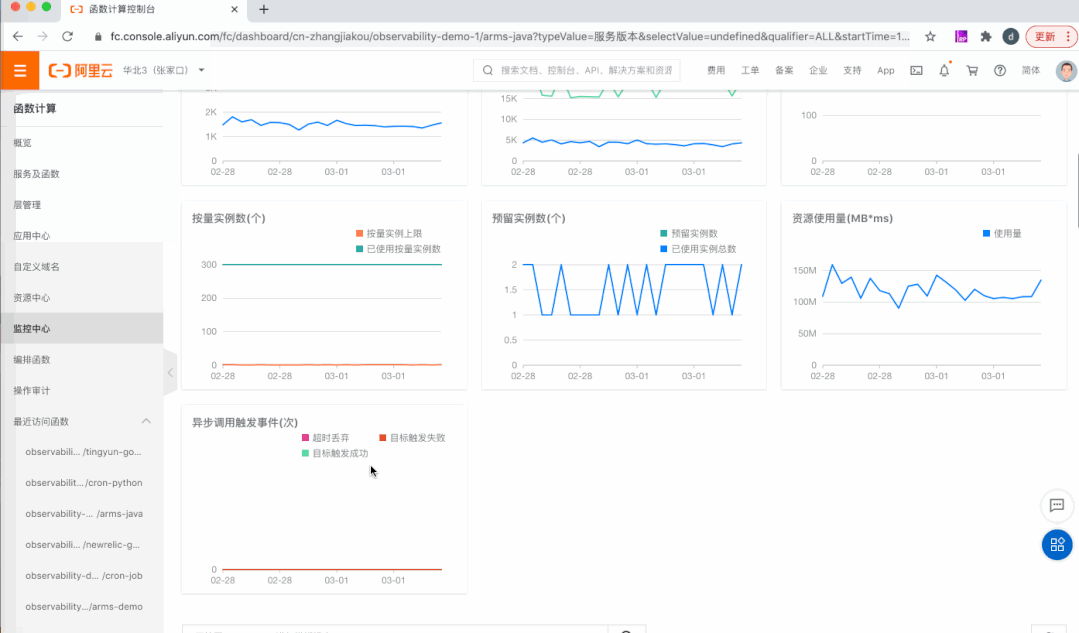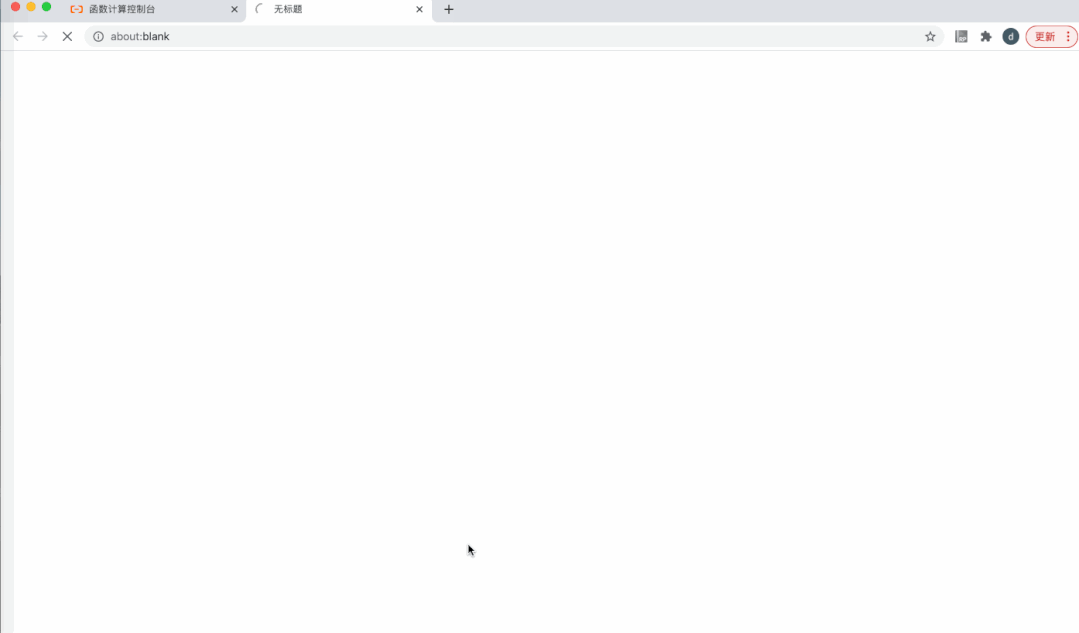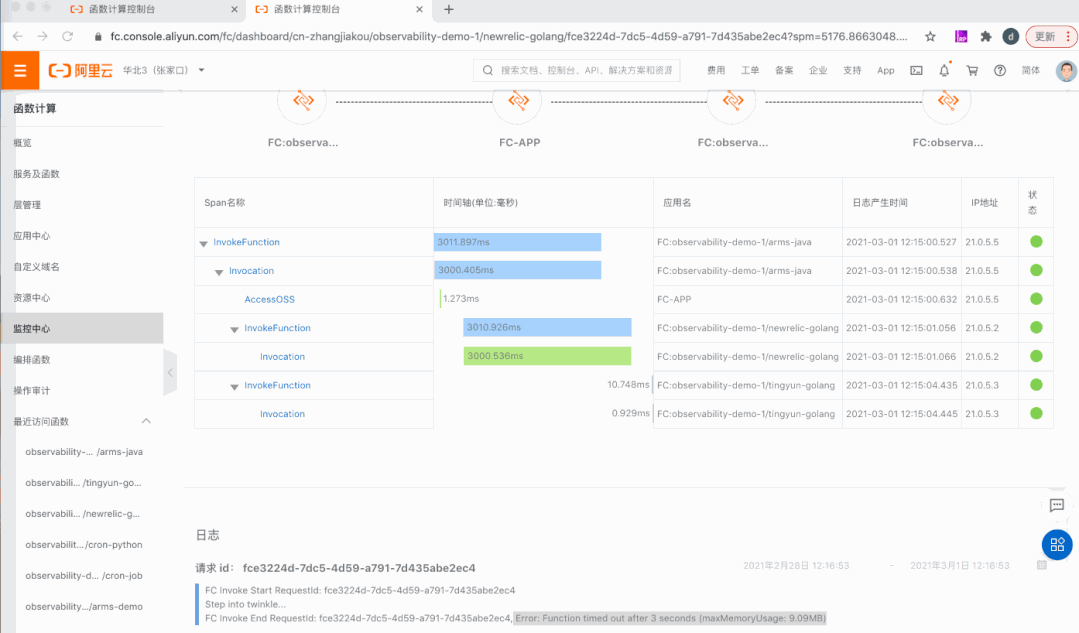
3)发布监控中心(Insights),问题发现调查一站式解决
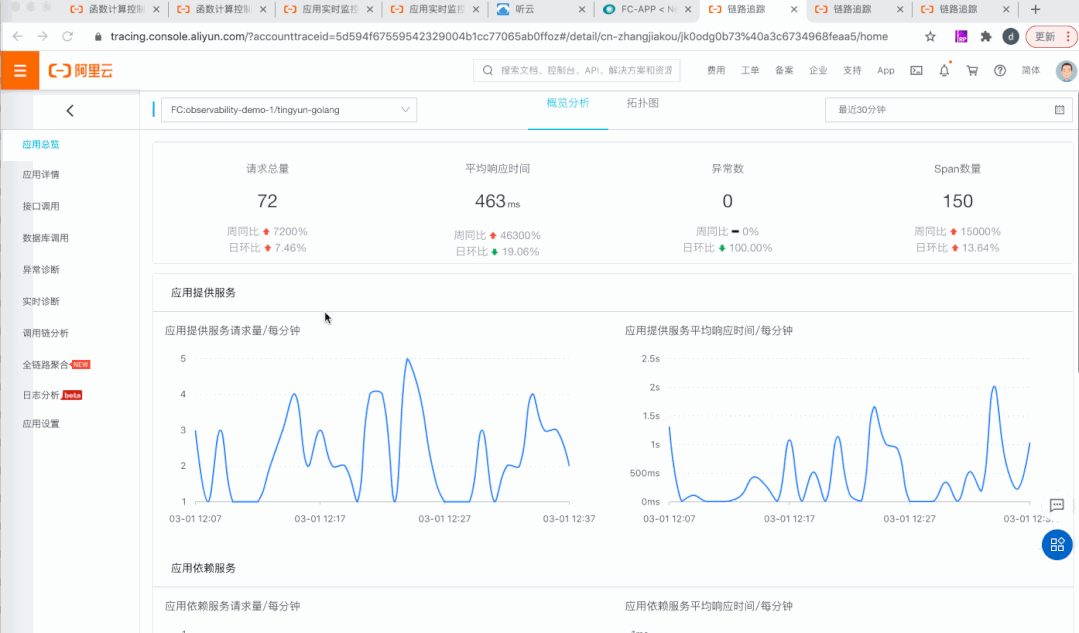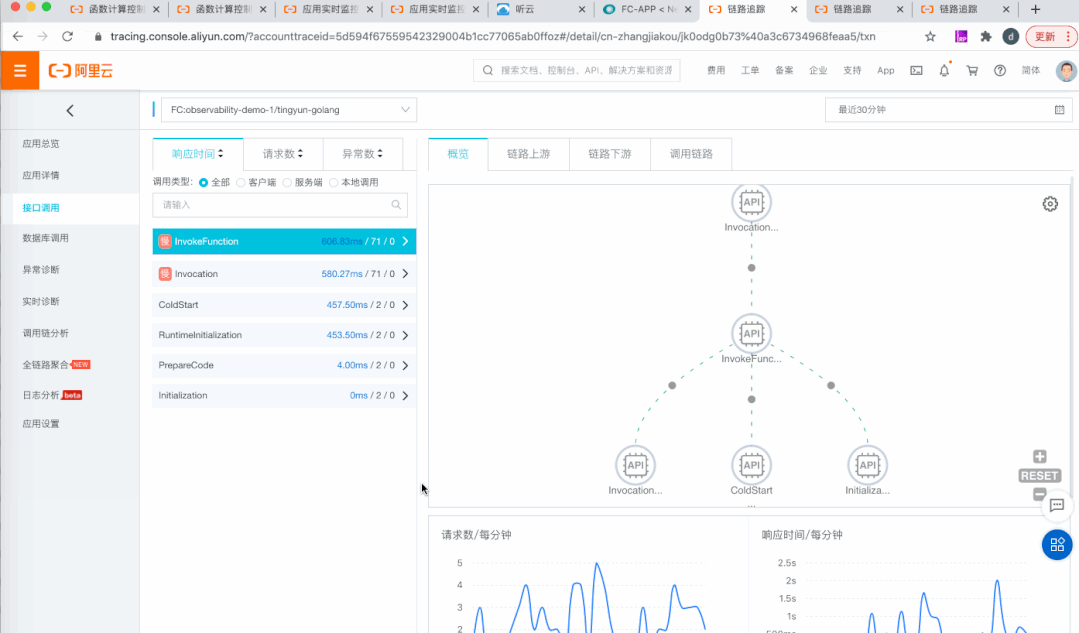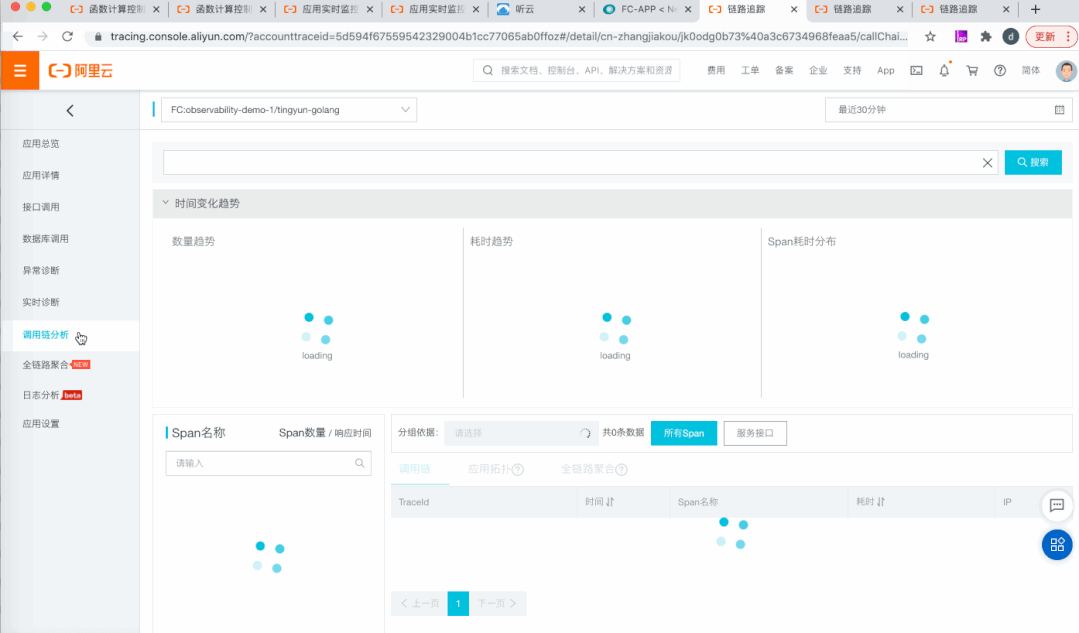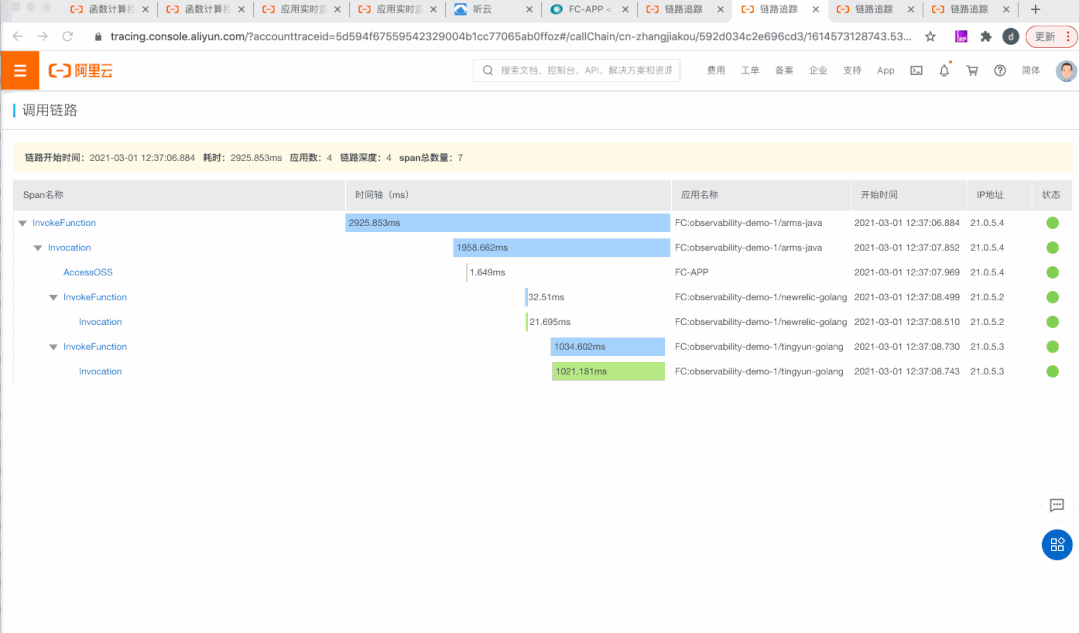
多维度:支持 Region、Service、Function、Qualifier、Request 多维度的指标,展示各个维度下的调用数和错误分布。
多层次:集成 Metrics、Logs、Tracing 的能力,全方位多层次对应用进行监控。
全链路:结合指标、日志、链路等信息,层层递进,抽丝剥茧,真正做到可以在一个站点发现问题,定位问题并解决问题。
4)扩展编程模型,集成三方监控

3. 总结
未来规划
完善监控中心,支持报警配置,预警异常指标。
提供实例级别指标,做到代码问题可定位,环境现场可追溯。
集成开源项目,集成 Prometheus,Opentelemetry,配置 Grafana 大盘。
丰富指标内容,目前还有一些指标是不好透出的,没有暴露的,我们要逐步都暴露出来。
······
Serverless 电子书下载

本书亮点:
从架构演进开始,介绍 Serverless 架构及技术选型构建 Serverless 思维; 了解业界流行的 Serverless 架构运行原理; 掌握 10 大 Serverless 真实落地案例,活学活用。
👇👇 点击“阅读原文”,立即下载!