
探索性数据分析,Python 中这 4 个方法更快、真棒!
大家好,常用探索性数据分析方法很多,比如常用的 Pandas DataFrame 方法有 .head()、.tail()、.info()、.describe()、.plot() 和 .value_counts()。
今天我给大家分享几种更快的探索性数据分析方法,它们可以进一步加速 EDA,欢迎收藏学习,喜欢点赞支持,文末提供技术交流群
我们以一个学生考试成绩的例子,创建一个如下所示的 DataFrame 并继续操作。
import pandas as pd
import numpy as np
df = pd.DataFrame( {
"Student" : ["Mike", "Jack", "Diana", "Charles", "Philipp", "Charles", "Kale", "Jack"] ,
"City" : ["London", "London", "Berlin", "London", "London", "Berlin", "London", "Berlin"] ,
"Age" : [20, 40, 18, 24, 37, 40, 44, 20 ],
"Maths_Score" : [84, 80, 50, 36, 44, 24, 41, 35],
"Science_Score" : [66, 83, 51, 35, 43, 58, 71, 65]} )
df
在 Pandas 中创建 groupby() 对象
在许多情况下,我们希望将数据集拆分为多个组并对这些组进行处理。Pandas 方法 groupby() 用于将 DataFrame 中的数据分组。
与其一起使用 groupby() 和聚合方法,不如创建一个 groupby() 对象。理想的情况是,我们可以在需要时直接使用此对象。
让我们根据列“City”将给定的 DataFrame 分组
df_city_group = df.groupby("City")
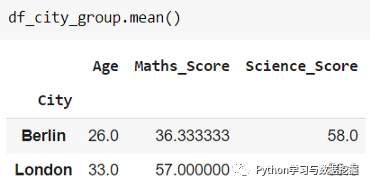
我们创建一个对象 df_city_group,该对象可以与不同的聚合相结合,例如 min()、max()、mean()、describe() 和 count()。一个例子如下所示。
 要获取“City”是Berlin的 DataFrame 子集,只需使用方法 .get_group()
要获取“City”是Berlin的 DataFrame 子集,只需使用方法 .get_group()
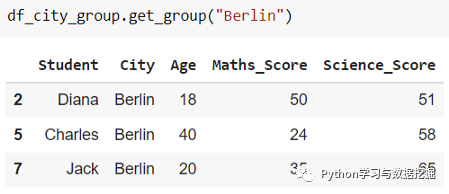 这不需要为每个组创建每个子 DataFrame 的副本,比较节省内存。
这不需要为每个组创建每个子 DataFrame 的副本,比较节省内存。
另外,使用 .groupby() 进行切片比常规方法快 2 倍!!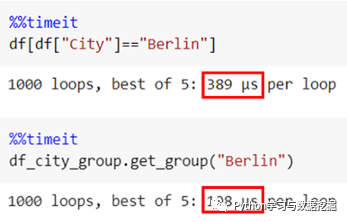
使用 .nlargest()
通常,我们根据特定列的值了解 DataFrame 的 Top 3 或 Top 5 数据。例如,从考试中获得前 3 名得分者或从数据集中获得前 5 名观看次数最多的电影。使用 Pandas .nlargest() 是最简单的方式。
df.nlargest(N, column_name, keep = ‘first’ )
使用 .nlargest() 方法,可以检索包含指定列的 Top ‘N’ 值的 DataFrame 行。
在上面的示例中,让我们获取前 3 个“Maths_Score”的 DataFrame 的行。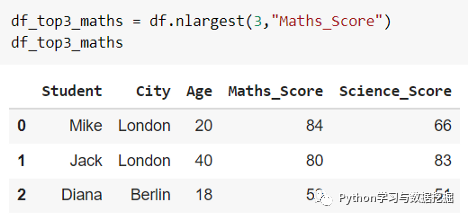 如果两个值之间存在联系,则可以修改附加参数和可选参数。它需要值“first”、“last”和“all”来检索领带中的第一个、最后一个和所有值。这种方法的优点是,你不需要专门对 DataFrame 进行排序。
如果两个值之间存在联系,则可以修改附加参数和可选参数。它需要值“first”、“last”和“all”来检索领带中的第一个、最后一个和所有值。这种方法的优点是,你不需要专门对 DataFrame 进行排序。
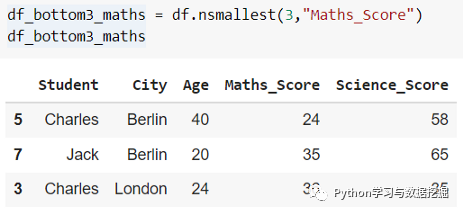
使用 .nsmallest()
与Top 3 或5 类似,有时我们也需要DataFrame 中的Last 5 条记录。例如,获得评分最低的 5 部电影或考试中得分最低的 5 名学生。使用 Pandas .nsmallest() 是最简单的方式
df.nsmallestst(N, column_name, keep = ‘first’ )
使用 .nsmallest() 方法,可以检索包含指定列的底部“N”个值的 DataFrame 行。
在同一个示例中,让我们获取 DataFrame“df”中“Maths_Score”最低的 3 行。
逻辑比较
比较运算符 <、>、<=、>=、==、!= 及其包装器 .lt()、.gt()、.le()、.ge()、.eq() 和 .ne() 分别在以下情况下非常方便将 DataFrame 与基值进行比较,这种比较会产生一系列布尔值,这些值可用作以后的指标。
基于比较对 DataFrame 进行切片
可以基于与值的比较从 DataFrame 中提取子集。
根据两列的比较在现有 DataFrame 中创建一个新列。
所有这些场景都在下面的示例中进行了解释
# 1. Comparing the DataFrame to a base value
# Selecting the columns with numerical values only
df.iloc[:,2:5].gt(50)
df.iloc[:,2:5].lt(50)
# 2. Slicing the DataFrame based on comparison
# df1 is subset of df when values in "Maths_Score" column are not equal or equal to '35'
df1 = df[df["Maths_Score"].ne(35)]
df2 = df[df["Maths_Score"].eq(35)]
# 3. Creating new column of True-False values by comparing two columns
df["Maths_Student"] = df["Maths_Score"].ge(df["Science_Score"])
df["Maths_Student_1"] = df["Science_Score"].le(df["Maths_Score"])
总结
在使用 Python 进行数据分析时,我发现这些方法非常方便,它确实让数据分析变得更快。欢迎大家尝试这些,如果你有那些更棒的方法,欢迎评论区留言!
相关阅读: