
Hudi 指南 | Apache Flink 1.12 集成 Hudi 运行指南
1. 准备工作
1. 编译包下载
•下载Flink 1.12.2包:https://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.12.2/flink-1.12.2-bin-scala_2.11.tgz•Hudi编译:https://github.com/apache/hudi•git clone https://github.com/apache/hudi.git && cd hudi•mvn clean package -DskipTests注意:默认是用scala-2.11编译的 如果我们用的是flink1.12.2-2.12版本,可以自己编译成scala-2.12版本的 mvn clean package -DskipTests -Dscala-2.12 包的路径在packaging/hudi-spark-bundle/target/hudi-spark-bundle_2.12-..*-SNAPSHOT.jar•上述包打好后其他步骤可参考官网步骤:https://hudi.apache.org/docs/flink-quick-start-guide.html(注意:官网使用的是Flink 1.11.x版本,测试时报如下错误
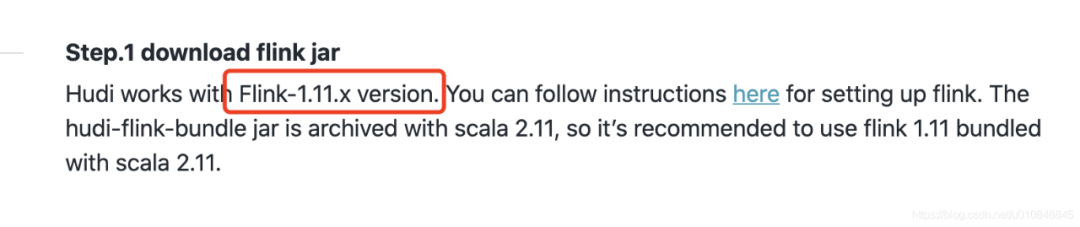

•建议使用Flink1.12.2 + Hudi 0.9.0-SNAPSHOT(master)版本。
2. Batch写
2.1 环境启动
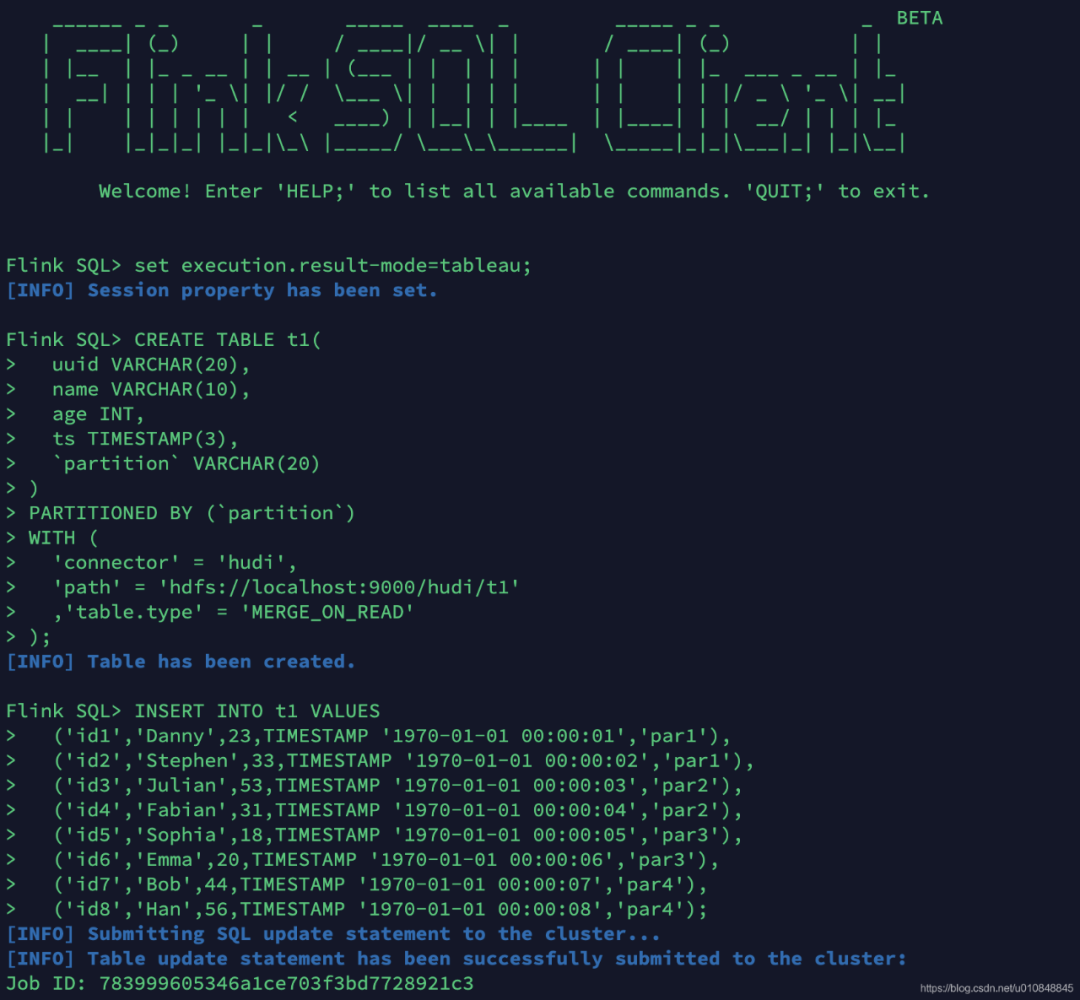
启动flink-sql客户端,提前把hudi-flink-bundle_2.12-0.9.0-SNAPSHOT.jar(笔者使用flink scala2.12版本,如果是scala2.11版本需要编译成hudi-flink-bundle_2.11-0.9.0-SNAPSHOT.jar)拷贝到 $FLINK_HOME/lib目录下
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`./bin/sql-client.sh embedded
2.2 创建表结构
CREATE TABLE t1(uuid VARCHAR(20),name VARCHAR(10),age INT,ts TIMESTAMP(3),`partition` VARCHAR(20))PARTITIONED BY (`partition`)WITH ('connector'= 'hudi','path'= 'hdfs://localhost:9000/hudi/t1','table.type'= 'MERGE_ON_READ');
2.3 插入数据
INSERT INTO t1 VALUES('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'),('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'),('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'),('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'),('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'),('id6','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'),('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'),('id8','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4');
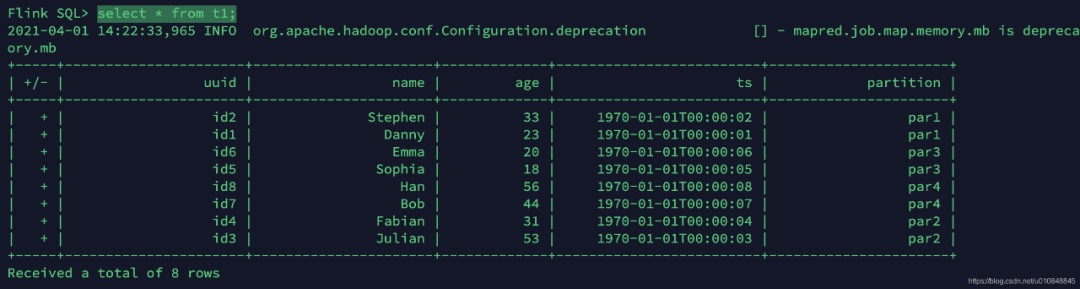
2.4 查询数据
设置查询模式为tableau
-- sets up the result mode to tableau to show the results directly in the CLIset execution.result-mode=tableau;
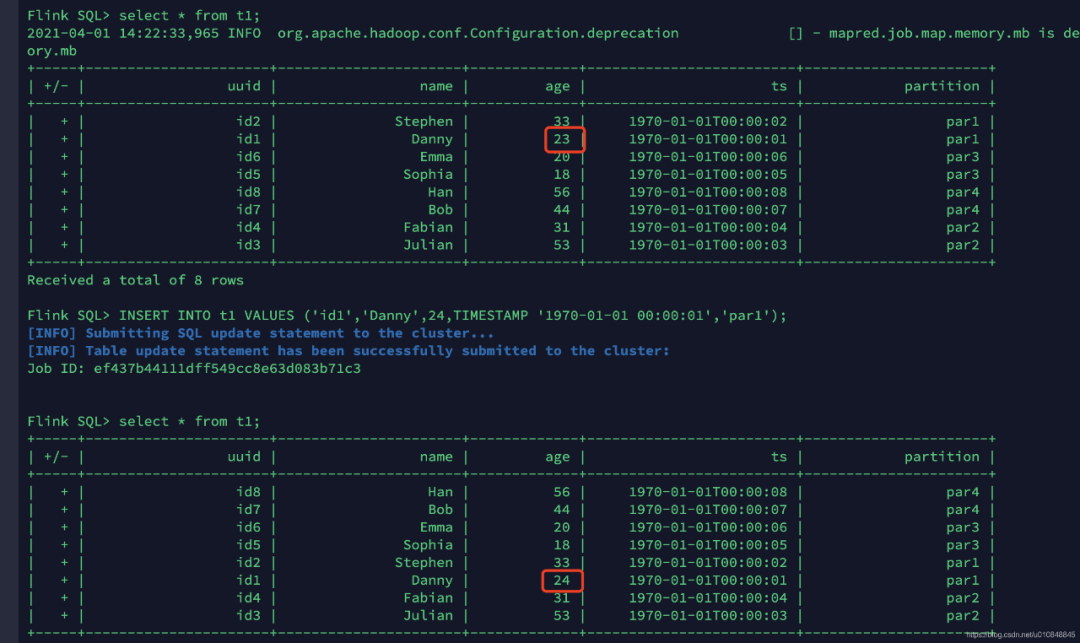
2.5 更新数据
INSERT INTO t1 VALUES ('id1','Danny',24,TIMESTAMP '1970-01-01 00:00:01','par1');id1的数据age由23变为了24
3. Streaming读
3.1 创建表结构
CREATE TABLE t1(uuid VARCHAR(20),name VARCHAR(10),age INT,ts TIMESTAMP(3),`partition` VARCHAR(20))PARTITIONED BY (`partition`)WITH ('connector'= 'hudi','path'= 'hdfs://localhost:9000/hudi/t1','table.type'= 'MERGE_ON_READ','read.streaming.enabled'= 'true','read.streaming.start-commit'= '20210401134557','read.streaming.check-interval'= '4');
说明:这里将 read.streaming.enabled 设置为 true,表明通过 streaming 的方式读取表数据; read.streaming.check-interval 指定了 source 监控新的 commits 的间隔为 4s; table.type 设置表类型为 MERGE_ON_READ。
3.2 查询数据
流表t1表中的数据就是刚刚批模式写入的数据
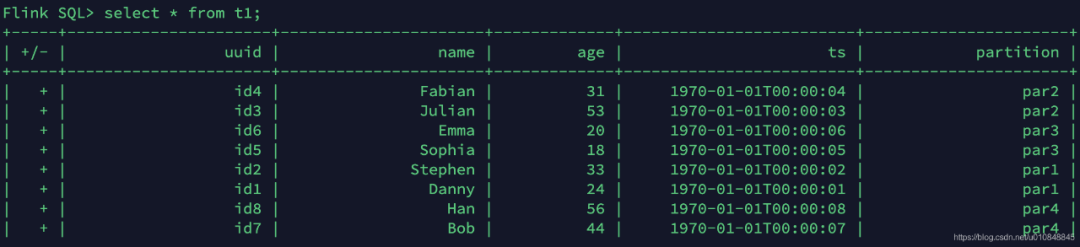
3.3 插入数据
使用批模式插入一条数据
insert into t1 values ('id9','test',27,TIMESTAMP '1970-01-01 00:00:01','par5');3.4 查询数据
几秒后在流表中可以读取到一条新增的数据(前面插入的一条数据)
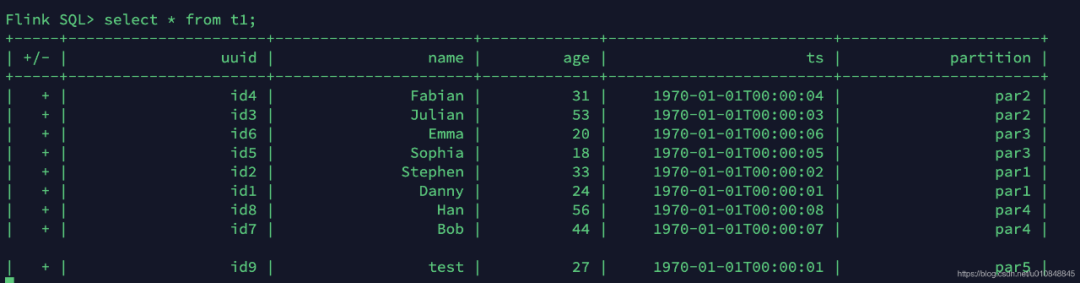
参考
•https://hudi.apache.org/docs/flink-quick-start-guide.html•https://github.com/MyLanPangzi/flink-demo/blob/main/docs/%E5%A2%9E%E9%87%8F%E5%9E%8B%E6%95%B0%E4%BB%93%E6%8E%A2%E7%B4%A2%EF%BC%9AFlink%20+%20Hudi.md•https://mp.weixin.qq.com/s/OtTNBym8Vj_YKvIgTBCuaw