
Systrace 学习笔记

和你一起终身学习,这里是程序员Android
经典好文推荐,通过阅读本文,您将收获以下知识点:
一、Systrace 简介
二、Systrace 预备知识
三、Why 60 fps
四、SystemServer 解读
五、SurfaceFlinger 解读
六、Input 解读
七、Vsync 解读
八、Vsync-App :基于 Choreographer 的渲染机制详解
九、MainThread 和 RenderThread 解读
十、Binder 和锁竞争解读
十一、Triple Buffer 解读
十二、CPU Info 解读
前言
本文为学习systrace所做笔记、心得,学习资源为高兄的Systrace系列文章:Android Systrace 基础知识。
一、Systrace 简介
Systrace 是什么?
Android4.1 中新增的性能数据采样和分析工具,它可以按模块、按服务、按系统等来手收集数据,使开发者可以根据systrace展示的数据来对系统进行优化。
Systrace使用流程:
手机准备好你要进行抓取的界面
点击开始抓取(命令行的话就是开始执行命令)
手机上开始操作(不要太长时间)
设定好的时间到了之后,会将生成 Trace.html 文件,使用 Chrome 将这个文件打开进行分析
二、 Systrace 预备知识
状态不同的线程:
绿色 --> 运行中 Running
对于在CPU上执行的进程,需要查看其运行时间、是否跑在该跑的核上、频率是否够等。
蓝色 --> 可运行 Runnable
对于在等待序列中的进程,需要查看是否有过多任务在等待、等待时间是否过长等。
白色 --> 休眠中 Sleeping
这里一般是在等事件驱动。
橘色 --> 不可中断的睡眠态_IO_Block Uninterruptible Sleep | WakeKill - Block I/O
线程在I / O上被阻塞或等待磁盘操作完成。
紫色 --> 不可中断的睡眠态 Uninterruptible Sleep
线程在另一个内核操作(通常是内存管理)上被阻塞。
进程唤醒信息分析:
抓住从Sleeping --> Runnable的进程,利用systrace找到是谁唤醒的它,又是为什么花了这么久才唤醒。
信息区数据解析:
点击不同的位置,选择不同的slice信息展示。
快捷键使用:
W : 放大 Systrace , 放大可以更好地看清局部细节
S : 缩小 Systrace, 缩小以查看整体
A : 左移
D : 右移
M : 高亮选中当前鼠标点击的段(这个比较常用,可以快速标识出这个方法的左右边界和执行时间,方便上下查看)
数字键1 : 切换到 Selection 模式 , 这个模式下鼠标可以点击某一个段查看其详细信息, 一般打开 Systrace 默认就是这个模式 , 也是最常用的一个模式 , 配合 M 和 ASDW 可以做基本的操作
数字键2 : 切换到 Pan 模式 , 这个模式下长按鼠标可以左右拖动, 有时候会用到
数字键3 : 切换到 Zoom 模式 , 这个模式下长按鼠标可以放大和缩小, 有时候会用到
数字键4 : 切换到 Timing 模式 , 这个模式下主要是用来衡量时间的,比如选择一个起点, 选择一个终点, 查看起点和终点这中间的操作所花费的时间.
三、Why 60 fps
软件的渲染率和硬件的刷新率要一起搭配,才能做到用户使用时足够流畅。
为什么手机的屏幕刷新率不能太高呢?
限于手机电池、硬软件的技术,目前移动设备上使用的60HZ,也就是60帧每秒,虽然在硬件和软件上,都能做到120HZ的刷新率,但是单位时间内高刷新次数也会带来高消耗,而移动端设备是不可能随时充着电的,所以手机屏幕的刷新率现在还不能太高,当然未来肯定能行。
四、 SystemServer 解读
窗口动画:
启动流程:点击App时,首先Launcher会启动一个StartingWindow,等App中启动页面的第一帧绘制好了,就会马上从Launcher切换回App的窗口动画。

ActivityManagerService:
AMS 相关的 Trace 一般会用 TRACE_TAG_ACTIVITY_MANAGER 这个 TAG,在 Systrace 中的名字是 ActivityManager。
WindowManagerService:
一般会用 TRACE_TAG_WINDOW_MANAGER 这个 TAG,在 Systrace 中 WindowManagerService 在 SystemServer 中多在 对应的 Binder 中出现。
Input:
主要是由 InputReader 和 InputDispatcher 这两个 Native 线程组成。
Binder:
SystemServer 由于提供大量的基础服务,所以进程间的通信非常繁忙,且大部分通信都是通过 Binder 。
HandlerThread:
BackgroundThread,许多对性能没有要求的任务,一般都会放到 BackgroundThread 中去执行。
ServiceThread:
ServiceThread 继承自 HandlerThread。
UIThread、IoThread、DisplayThread、AnimationThread、FgThread、SurfaceAnimationThread都是继承自 ServiceThread,分别实现不同的功能,根据线程功能不同,其线程优先级也不同。
每个 Thread 都有自己的 Looper 、Thread 和 MessageQueue,互相不会影响。Android 系统根据功能,会使用不同的 Thread 来完成。
五、 SurfaceFlinger 解读
SurfaceFlinger:
作用:合成图像的,将APP要画的图像处理后显示在硬件上;
触发:收到vsync信号后,开始已帧的形式绘图;
流程:当VSYNC 信号到达 --> 遍历层列表,以寻找新的缓冲区 --> 有新的缓冲区,获取该缓冲区;没有,使用以前获取的缓冲区 --> 收集完毕后,询问HWC如何合成。
流程图如下:

App --> BufferQueue:
App与BufferQueue交互流程:收到vsync信号后,应用主线程(UI Thread)被唤醒,主线程处理完数据后,会唤醒应用渲染线程RenderThread同步数据,RenderThread会从BufferQueue取出一个Buffer,然后往Buffer写入具体的 drawcall,完成后再将有数据的Buffer还给BufferQueue。
BufferQueue --> Surface Flinger:
思考后认为,App是不断往BufferQueue里面丢数据的,而vsync信号的发送与前面无关,就是系统提醒Surface Flinger可以画图了,那Surface Flinger就马上去BufferQueue取数据,然后画图。
Surface Flinger --> HWC:
这部分在文章中说明程度不够,目前只知道HWC是会根据SurfaceFlinger提供的信息来提供显示的方案——用于确定通过可用硬件来合成缓冲区的最有效方法。
六 Input 解读
当用户点开手机屏幕后,会做什么?用户会点击进入想看的页面、滑动切换的页面、点击后退按钮返回上一个以及按下Home键返回桌面,这些事件在安卓系统中都是以Message的形式传递,而上述这些操作,都属于InputMessage范畴,都是Input事件。
Input事件包含:
触摸事件(Down、Up、Move)
Key 事件(Home Key 、 Back Key)
本节主要描述当用户按下屏幕后,触发的流程是怎么样的。
流程中主要和这些内容有关:InputReader、InputDispatcher、OutboundQueue、WaitQueue、PendingInputEventQueue、deliverInputEvent和InputResponse 。
流程如下:
用户按下屏幕 --> InputReader读取Input事件,将其放入InboundQueue中,唤醒InputDispatcher线程 --> InputDispatcher从InboundQueue取出事件,依次对注册了Input事件的所有App(进程)做出以下操作:1. 派发给的OntboundQueue,2. 记录到各个App的WaitQueue --> InputDispatcher通过直接唤醒、Binder的方式将主线程UI Thread唤醒 --> UI Thread处理完成后,会将WaitQueue 里面的Input事件删除。
可以通过指令:adb shell dumpsys input获得一些重要的信息,如Device、InputReader、Inputdispatcher等等。
七、Vsync 解读
Vsync是什么?
Vsync是信号,用来控制App渲染图像、SurfaceFlinger合成图像的节奏。Vsync可以由硬件或软件产生,主要是由硬件HWC生成。
Vsync的流程:
HWC产生Vsync --> DispSync将Vsync生成Vsync-app和Vsync-sf --> 收到信号后,launcher的UI Thread负责将图像放入缓存,SF的UI Thread负责将缓存中的数据展示
从 App 绘制到屏幕显示,分为下面几个阶段:
第一阶段:App 在收到 Vsync-App 的时候,在主线程进行 measure、layout、draw(构建 DisplayList , 里面包含 OpenGL 渲染需要的命令及数据) 。这里对应的 Systrace 中的主线程 doFrame 操作;

image.png
第二阶段:CPU 将数据上传(共享或者拷贝)给 GPU, 这里 ARM 设备 内存一般是 GPU 和 CPU 共享内存。这里对应的 Systrace 中的渲染线程的 flush drawing commands 操作;

image.png
第三阶段:通知 GPU 渲染,真机一般不会阻塞等待 GPU 渲染结束,CPU 通知结束后就返回继续执行其他任务,使用 Fence 机制辅助 GPU CPU 进行同步操作;
第四 阶段:swapBuffers,并通知 SurfaceFlinger 图层合成。这里对应的 Systrace 中的渲染线程的 eglSwapBuffersWithDamageKHR 操作;
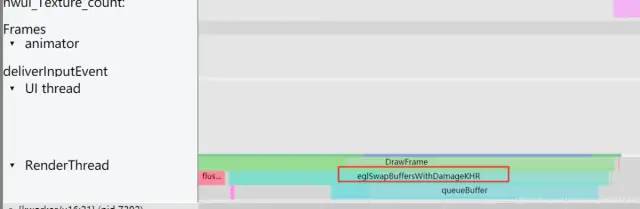
image.png
第五阶段:SurfaceFlinger 开始合成图层,如果之前提交的 GPU 渲染任务没结束,则等待 GPU 渲染完成,再合成(Fence 机制),合成依然是依赖 GPU,不过这就是下一个任务了.这里对应的 Systrace 中的 SurfaceFlinger 主线程的 onMessageReceived 操作(包括 handleTransaction、handleMessageInvalidate、handleMessageRefresh)SurfaceFlinger 在合成的时候,会将一些合成工作委托给 Hardware Composer,从而降低来自 OpenGL 和 GPU 的负载,只有 Hardware Composer 无法处理的图层,或者指定用 OpenGL 处理的图层,其他的 图层偶会使用 Hardware Composer 进行合成;
第六阶段 :最终合成好的数据放到屏幕对应的 Frame Buffer 中,固定刷新的时候就可以看到了。
收到Vsync信号时,会发生什么?

App和SF同时收到Vsync信号(在vsync-offset = 0时);
App开始对这一帧的Buffer进行渲染,SF开始对上一帧的Buffer进行合成;
Vsync Offset是什么?
Vsync Offset是指,让App和SF收到Vsync信号有一个时间间隔,而非同时收到。
为什么要有Vsync Offset?
因为如果Offset默认为0,那么SF收到Vsync信号后,合成的是上一帧App绘制的数据,如果我们让Offset不为0,那么可以做到当App绘制完这一帧的数据后,再让SF去合成这一帧的数据,用户就能提前看到一帧的动画。但是难以确定Offset的时间,很难做到合成绘制当前帧动画。
HW_Vsync
参考博主的文章,可以知道HW_Vsync并不会一直开启,而会使用DispSync线程模拟硬件信号,通过3到32个HW_Vsync模拟出SW_Vsync,只要收到的Present Fence没有超过误差,HW_VSYNC 就会关掉,使用SW_Vsync,不然会继续接收HW_VSYNC 计算 SW_VSYNC 的值,直到误差小于threshold。
不是每次申请 Vsync 都会由硬件产生 Vsync,只有此次请求 vsync 的时间距离上次合成时间大于 500ms,才会通知 hwc,请求 HW_VSYNC。
八、 Vsync-App :基于 Choreographer 的渲染机制详解
Choreographer 扮演 Android 渲染链路中承上启下的角色:
承上:负责接收和处理 App 的各种更新消息和回调,等到 Vsync 到来的时候统一处理。比如集中处理 Input(主要是 Input 事件的处理) 、Animation(动画相关)、Traversal(包括 measure、layout、draw 等操作) ,判断卡顿掉帧情况,记录 CallBack 耗时等
启下:负责请求和接收 Vsync 信号。接收 Vsync 事件回调(通过 FrameDisplayEventReceiver.onVsync );请求 Vsync(FrameDisplayEventReceiver.scheduleVsync) .
九、MainThread 和 RenderThread 解读
主线程和渲染线程一帧的工作流程:
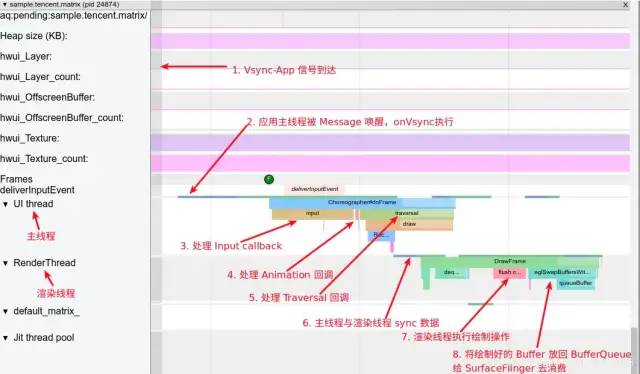
image.png
主线程处于 Sleep 状态,等待 Vsync 信号
Vsync 信号到来,主线程被唤醒,Choreographer 回调 FrameDisplayEventReceiver.onVsync 开始一帧的绘制
处理 App 这一帧的 Input 事件(如果有的话)
处理 App 这一帧的 Animation 事件(如果有的话)
处理 App 这一帧的 Traversal 事件(如果有的话)
主线程与渲染线程同步渲染数据,同步结束后,主线程结束一帧的绘制,可以继续处理下一个 Message(如果有的话,IdleHandler 如果不为空,这时候也会触发处理),或者进入 Sleep 状态等待下一个 Vsync
渲染线程首先需要从 BufferQueue 里面取一个 Buffer(dequeueBuffer) , 进行数据处理之后,调用 OpenGL 相关的函数,真正地进行渲染操作,然后将这个渲染好的 Buffer 还给 BufferQueue (queueBuffer) , SurfaceFlinger 在 Vsync-SF 到了之后,将所有准备好的 Buffer 取出进行合成(这个流程在讲 SurfaceFlinger 的时候会提到)
硬件加速是什么:
硬件加速是指在计算机中通过把计算量非常大的工作分配给专门的硬件硬件)来处理以减轻中央处理器的工作量之技术。
就是CPU把工作分给GPU和APU了。
硬件加速流程:
1.CPU从文件系统里读出原始数据(DirectSHow的源滤镜),分离出压缩的视频数据(分离器)。放在系统内存中。GPU、APU不运行。
2.CPU把压缩音视频数据交给GPU、APU, 这时总线上开始忙了,压缩数据从系统内存拷贝到显卡上的显存里和声卡上的声存里(如果有的话)。
3.CPU要求GPU、APU开始硬件解码,CPU不运行,GPU、APU开始忙。当然CPU会定期查询一下GPU、APU忙的怎么样了。
4.GPU、APU开始用自己的电路解码视频数据(已经在显、声存里了),解压后的数据还是放在显声存里面。
5.音视频数据刚解码完成以后还不能立刻拿去播放,因为还需要后期处理,如deinterlace, 3:2pulldown,多普勒效应,等等。GPU、APU再用自己的后期处理电路来进行处理。
6.后期处理以后的未压缩数据拿去播放, GPU再开始忙视频的缩放,亮度,gamma等事情。CPU还是闲。
7.GPU、APU终于忙完了,下面的视频数据在哪里?通知CPU,GPU、APU先歇会。CPU又开始忙了,回到第1步。
CPU拿到视频、音频数据后,拷贝给GPU、APU拿去做处理和显示,并且CPU会不断监听GPU和APU的进度。
软件绘制:
安卓系统默认开启硬件加速,我们可以针对某个App,关闭App的硬件加速。关闭后,CPU不会再将数据传递给GPU渲染,而是会直接调用 libSkia 来进行渲染,systrace中软件加速如图所示:
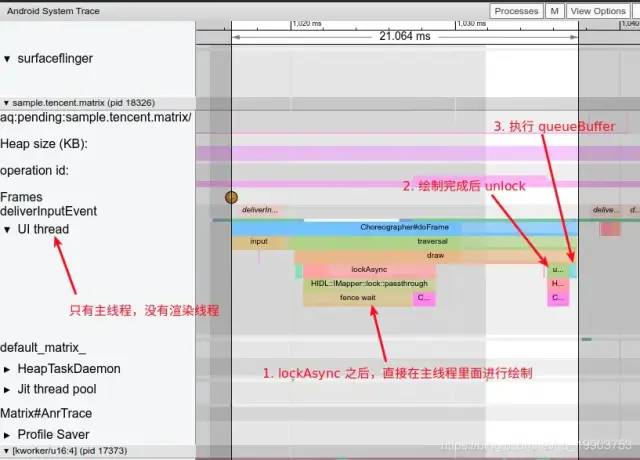
与硬件加速对比,主线程执行的时间变长了,更容易出现卡顿,同时帧与帧之间的空闲间隔也变短了,使得其他 Message 的执行时间被压缩。
硬件加速时,主线程和渲染线程的分工:
主线程负责处理进程 Message、处理 Input 事件、处理 Animation 逻辑、处理 Measure、Layout、Draw ,更新 DIsplayList ,但是不涉及 SurfaceFlinger 打交道;
渲染线程负责渲染渲染相关的工作,一部分工作也是 CPU 来完成的,一部分操作是调用 OpenGL 函数来完成的。
当启动硬件加速后,在 Measure、Layout、Draw 的 Draw 这个环节,Android 使用 DisplayList 进行绘制而非直接使用 CPU 绘制每一帧。DisplayList 是一系列绘制操作的记录,抽象为 RenderNode 类,这样间接的进行绘制操作的优点如下
DisplayList 可以按需多次绘制而无须同业务逻辑交互
特定的绘制操作(如 translation, scale 等)可以作用于整个 DisplayList 而无须重新分发绘制操作
当知晓了所有绘制操作后,可以针对其进行优化:例如,所有的文本可以一起进行绘制一次
可以将对 DisplayList 的处理转移至另一个线程(也就是 RenderThread)
主线程在 sync 结束后可以处理其他的 Message,而不用等待 RenderThread 结束
十、Binder 和锁竞争解读
Binder是什么?
Binder是解决安卓系统中进程通讯的工具。
Systrace中,和Binder相关的进程通信是怎么表现的?
在打开systrace图像右上角View Options的Flow events后,可以看到binder跨进程通讯的步骤,下面两张图显示了,开启binder调用 --> 获得对端进程响应 --> binder调用返回的流程。
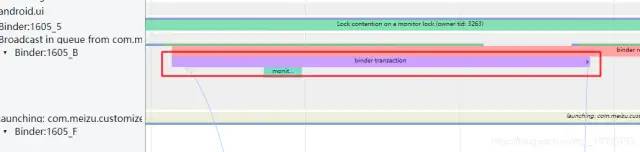
Systrace显示锁的信息:
在systrace中我们可以看到一些线程下面的执行方法:monitor contention with owner xxxxx。
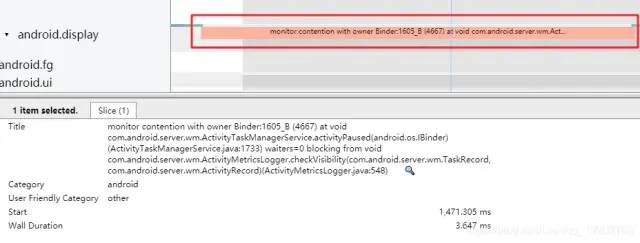
点开这类方法,可以发现执行这段方法的线程是会处于一段sleeping的状态的,原因是拿不到锁资源,在锁池等待其他线程释放锁资源。
在Slive信息中,我们可以发现该线程正在和锁持有的对象Binder:1605_B (4667)竞争着,并且在这个线程去竞争前,总共还有waiters = 0个线程也在锁池等待,而锁目前主人正在执行的同步方法是com.android.server.wm.ActivityTaskManagerService.activityPaused(android.os.IBinder),代码位于(ActivityTaskManagerService.java:1733),而该线程正在等待的同步方法是void com.android.server.wm.ActivityMetricsLogger.checkVisibility(com.android.server.wm.TaskRecord, com.android.server.wm.ActivityRecord),代码位于(ActivityMetricsLogger.java:548)。
十一、Triple Buffer 解读
掉帧:
App端掉帧:当App进程的UI Thread和Render Thread在收到Vsync信号后,执行所花的时间超过16.6毫秒,那么在App端就发生了掉帧,不过由于triple buffer的存在,可能不会掉帧;
SurfaceFlinger端判断掉帧:如果在vsync信号来到的时候,SF的Buffer里面是0,那么就是掉帧了,而且这是用户能看得到的掉帧,也可以在systrace上看到Vsync-sf在收到信号后没有发生变化;
逻辑掉帧:在画面显示时,不仅仅只是和每一帧显示的数据有关,还和相邻帧的步长有关系,如果相邻帧的步长没有规范到一个固定的范围内,用户也会感觉到明显的卡顿而systrace看不出来。
triple buffer:
在triple buffer中有3个buffer可以使用,CPU、GPU和SF各用一个,当triple buffer发生掉帧后,是可以减少后续掉帧的情况的,流程图如下所示。

triple buffer的作用:
缓解掉帧;
减少主线程和渲染线程等待时间;
降低 GPU 和 SurfaceFlinger 瓶颈。
十二、CPU Info 解读
在systrace中,可以通过展开CPU那一栏的方式,查看CPU在运行时的状态、频率变化情况、任务执行情况、大小核的调度情况、CPU Boost 调度情况。
CPU的核心架构:
非大小核架构,只有2个或4个核心的时候,会用同样的核心;
大小核架构,八个核心中由大核和小核组成,如4个小核心 + 4个大核心;
大中小核架构,八个核心中由大核、中核和小核组成,如4个小核心 + 3个中核心 + 1个大核心;
绑核:
将固定线程绑定在某个核心上,如将重要的、工作量大的线程绑定在大核,不重要、工作量小的线程绑定在小核。
绑核的三种方式:
配置 CPUset,按照类型将某一类任务限制到具体的CPU或CPU组中运行;
配置 affinity,使用指令设置任务跑在具体的CPU核心上;
调度算法。
锁频:
将CPU的核心锁定频率,方式:设置最高频率 = 最低频率
CPU状态:
如图所示,CPU状态有4种。

下面是摘抄的其他平台的支持 C0-C4 的处理器的状态和功耗状态,Android 中不同的平台表现不一致,大家可以做一下参考
C0 状态(激活)
这是 CPU 最大工作状态,在此状态下可以接收指令和处理数据
所有现代处理器必须支持这一功耗状态
C1 状态(挂起)
可以通过执行汇编指令“ HLT (挂起)”进入这一状态
唤醒时间超快!(快到只需 10 纳秒!)
可以节省 70% 的 CPU 功耗
所有现代处理器都必须支持这一功耗状态
C2 状态(停止允许)
处理器时钟频率和 I/O 缓冲被停止
换言之,处理器执行引擎和 I/0 缓冲已经没有时钟频率
在 C2 状态下也可以节约 70% 的 CPU 和平台能耗
从 C2 切换到 C0 状态需要 100 纳秒以上
C3 状态(深度睡眠)
总线频率和 PLL 均被锁定
在多核心系统下,缓存无效
在单核心系统下,内存被关闭,但缓存仍有效可以节省 70% 的 CPU 功耗,但平台功耗比 C2 状态下大一些
唤醒时间需要 50 微妙
原文链接:https://blog.csdn.net/qq_19903753/article/details/108108972
友情推荐:
至此,本篇已结束。转载网络的文章,小编觉得很优秀,欢迎点击阅读原文,支持原创作者,如有侵权,恳请联系小编删除,欢迎您的建议与指正。同时期待您的关注,感谢您的阅读,谢谢!
点个在看,方便您使用时快速查找!