
3月31日美团春招推荐算法岗面试题分享!
公众号福利
👉回复【100题】领取《名企AI面试100题》PDF
👉回复【干货资料】领取NLP、CV、ML等AI方向干货资料
👉回复【往期招聘】查看往期内推招聘

拉至文末,找小助手进群看公开课~


问题1:为什么分类问题损失不使用MSE而使用交叉熵
1、均方误差作为损失函数,这时所构造出来的损失函数是非凸的,不容易求解,容易得到其局部最优解;而交叉熵的损失函数是凸函数;
2、均方误差作为损失函数,求导后,梯度与sigmoid的导数有关,会导致训练慢;而交叉熵的损失函数求导后,梯度就是一个差值,误差大的话更新的就快,误差小的话就更新的慢点。

问题2:BN的作用,除了防止梯度消失这个作用外
(1)加快收敛速度:在深度神经网络中中,如果每层的数据分布都不一样的话,将会导致网络非常难收敛和训练,而如果把 每层的数据都在转换在均值为零,方差为1 的状态下,这样每层数据的分布都是一样的训练会比较容易收敛。
(2)控制梯度爆炸防止梯度消失:以sigmoid函数为例,sigmoid函数使得输出在[0,1]之间,实际上当x道了一定的大小,经过sigmoid函数后输出范围就会变得很小。
(3)BN算法防止过拟合:在网络的训练中,BN的使用使得一个minibatch中所有样本都被关联在了一起,因此网络不会从某一个训练样本中生成确定的结果,即同样一个样本的输出不再仅仅取决于样本的本身,也取决于跟这个样本同属一个batch的其他样本,而每次网络都是随机取batch,这样就会使得整个网络不会朝这一个方向使劲学习。一定程度上避免了过拟合。
问题3:训练时出现不收敛的情况怎么办,为什么会出现不收敛
从数据角度:
是否对数据进行了预处理,包括分类标注是否正确,数据是否干净
是否对数据进行了归一化
考虑样本的信息量是否太大,而网络结构是否太简单
考虑标签是否设置正确
从模型角度:
尝试加深网络结构
Learning rate是否合适(太大,会造成不收敛,太小,会造成收敛速度非常慢)
错误初始化网络参数
train loss 不断下降,test loss不断下降,说明网络仍在学习;
train loss 不断下降,test loss趋于不变,说明网络过拟合;
train loss 趋于不变,test loss不断下降,说明数据集100%有问题;
train loss 趋于不变,test loss趋于不变,说明学习遇到瓶颈,需要减小学习率或批量数目;
train loss 不断上升,test loss不断上升,说明网络结构设计不当,训练超参数设置不当,数据集经过清洗等问题。
问题4:LR与决策树的区别
1、逻辑回归通常用于分类问题,决策树可回归、可分类。
2、逻辑回归是线性函数,决策树是非线性函数。
3、逻辑回归的表达式很简单,回归系数就确定了模型。决策树的形式就复杂了,叶子节点的范围+取值。两个模型在使用中都有很强的解释性,银行较喜欢。
4、逻辑回归可用于高维稀疏数据场景,比如ctr预估;决策树变量连续最好,类别变量的话,稀疏性不能太高。
5、逻辑回归的核心是sigmoid函数,具有无限可导的优点,常作为神经网络的激活函数。
6、在集成模型中,随机森林、GBDT以决策树为基模型,Boosting算法也可以用逻辑回归作为基模型。
问题5:有哪些决策树算法
ID3、C4.5、CART树的算法思想
ID3算法的核心是在决策树的每个节点上应用信息增益准则选择特征,递归地构架决策树。
C4.5算法的核心是在生成过程中用信息增益比来选择特征。
CART树算法的核心是在生成过程用基尼指数来选择特征。
基于决策树的算法有随机森林、GBDT、Xgboost等。
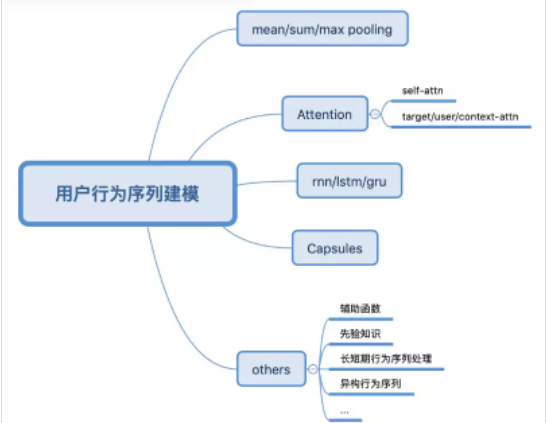
问题6:了解哪些行为序列建模方式
参考:https://zhuanlan.zhihu.com/p/138136777
问题7:Leetcode_91题:解码方法
思路:动态规划
class Solution:
def numDecodings(self, s: str) -> int:
n = len(s)
f = [1] + [0] * n
for i in range(1, n + 1):
if s[i - 1] != \'0\':
f[i] += f[i - 1]
if i > 1 and s[i - 2] != \'0\' and int(s[i-2:i]) <= 26:
f[i] += f[i - 2]
return f[n]
问题8:智力题:红蓝颜料比例问题
题目描述:两个桶分别装了一样多的红色和蓝色的颜料。先从蓝色桶里舀一杯倒入红色中,搅拌不均匀。再从有蓝色的红色桶中舀一杯倒入蓝色桶里,问两个桶中蓝:红与红:蓝的大小关系?
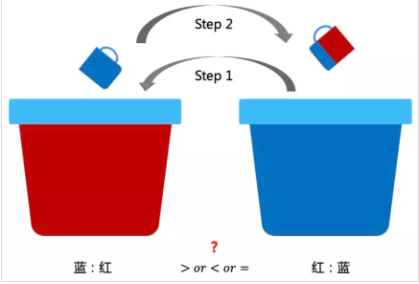
第二步舀的时候,因为不均匀,所以无法知道具体有多少比例的红色和蓝色,可以换一个角度来考虑。因为是用的相同大小的杯子,所以两次操作后,两边的桶里的总体颜色是一样多的。假设红色里面混了一部分蓝色的颜料体积为X升,那么就有X升的红色颜料到了蓝色的桶里,所以两边的比例是一样的。
9、智力题:两个人数数,谁先数到20算谁赢。
要求:每次只能数1或者2个数,采取什么策略可以保证必胜,先手和后手都可以选择。
要想获胜的规律就是要抢到19这个数
因为是两个人参与,所以关键数是19,当数到19时,对方就只能数20了,所以可以反推一下,要想获胜的话,在二十个数里,要想方设法地抢到19,16,13,10,7,4,1这几个公差为3的整数,也就是说在这个游戏里,要想获胜的话,就要抢到1这个数,即谁先数谁就获胜。

私我回复"414"进直播群
