
阿里盒马-如何打造渐进式可扩展、高生产力的前端研发平台
大厂技术 高级前端 Node进阶
点击上方 程序员成长指北,关注公众号
回复1,加入高级Node交流群
本文是 4.10 前端早早聊-前端搞 CI/CD 专场分享的文字整理稿,来自 阿里盒马-夜沉 的分享。
我从 2015 年进入阿里之后就开始了在前端工程化领域的探索,一直非常感兴趣。之前在 B2B 主导负责 JUST 工程体系,后面来到盒马,负责前端工程以及基础体验相关的工作,此次 ReX Dev 研发平台的分享也算是自己对当前盒马工程体系的一个总结。
此次分享主要都是与平台架构相关的设计思考,不会有过多的产品功能相关的部分,这有两个方面的考虑:一是平台正在高速迭代之中,部分产品能力还在打磨;另一方面,不同团队的业务场景不同,对工程化的诉求会有较大差别,分享的借鉴意义并不大。
在这篇文章中,我会尽可能的详细介绍 ReX Dev 在设计过程中对一些架构问题的思考,希望对你有所帮助。
背景介绍
盒马中后台技术现状
我们团队是盒马 B 端的前端团队,主要负责盒马的中后台相关业务。在聊具体的架构之前,我们先看一下盒马的中后台技术现状。
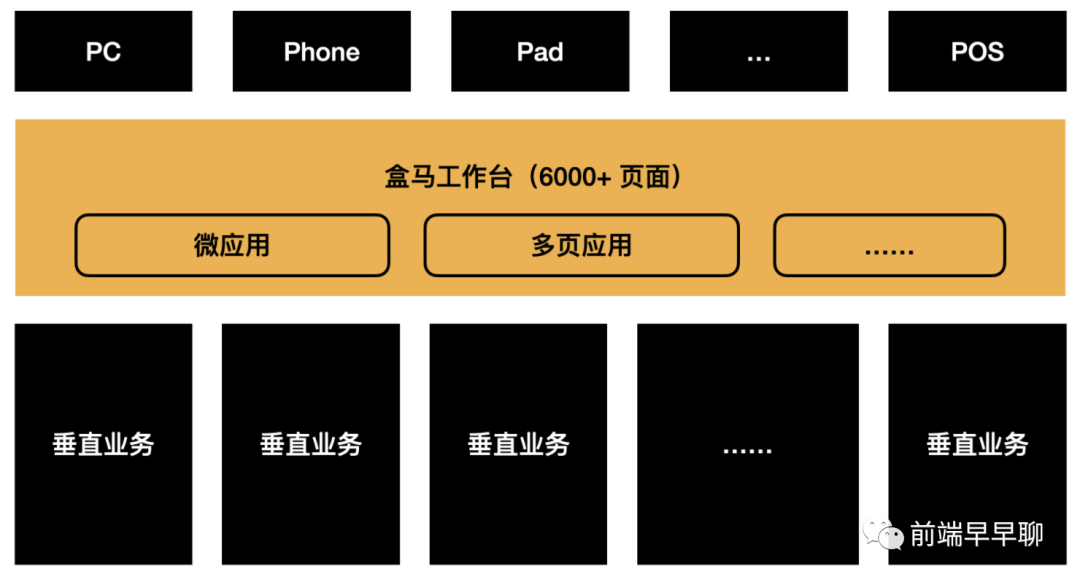
从上图可以看出,盒马工作台是中后台的核心系统,小二用户通过不同的终端访问盒马工作台,这个工作台之下有从供应商到门店、从商品到物流等数十条垂直业务线。
中后台工程特征
从前端工程化的角度,盒马的中后台场景主要有以下特征:
页面基数大:有 6000+ 存量页面,3000+ 活跃维护页面(半年内),这导致了前端侧会有巨大的并发开发量,对新旧应用的研发效率要求非常高,我们需要考虑建设非常高效的研发平台; 页面离散化、模式化:由于盒马的垂直业务线多、业态复杂,这大量的页面的背后是页面的离散化,当然也呈现出了模式化特征,模式化的页面让我们有机会去尝试 LowCode/NoCode 等技术; 存在多种应用类型:由于一些历史及特殊场景的原因,盒马有多种前端应用研发,它们各有自己所适合的场景,比如微应用、多页应用、单体应用等等,此外考虑未来的业务变化,很可能还会有新的应用形态产生,因此对研发流程有较高的扩展性诉求。
为应对以上工程上的诉求,我们需要一套高生产力、可扩展的研发平台。
由于盒马现有的研发流程是基于原 B2B 的 just-flow 系统定制的,目前平台的可维护性、稳定性都存在较大问题,同时涉及平台归属问题,也不适合针对盒马场景做大规模重构,因此我们决定构建盒马自己的研发平台 ReX Dev。
产品定位与演进策略
ReX Dev 的平台定位为:盒马前端应用的高生产力研发平台。这意味着这个平台只针对盒马(及关联业务)服务,只考虑前端应用,并要求高生产力。确定定位能明确平台的能力边界,聚焦产品要解决的核心问题。
作为一个服务于前端应用开发者的平台,不能只考虑单纯的效率提升,还要考虑研发模式的演进。就盒马而言,多达 3000+ 活跃维护页面(还在不断增长),目前主要的维护方式还是前端参与大部分研发,即前端作为业务资源进行直接支持。
然而,这会存在以下问题:
业务在不断发展过程中,有大量技术债务的偿还,对前端的资源的诉求只增不减,单纯的资源型支持方式已难以满足业务发展; 大量模式化的页面也很难带来特别的技术挑战,大部分人只是重复的写模式化的页面,对业务支持同学的价值感、成就感都偏低,也导致人才的流失。
因此,我们需要推动研发模式的改变。
盒马这种业务形态聚焦、页面模式化、页面量大的中后台场景,为 LowCode/NoCode 带来了比较大的机会。一旦当研发从 ProCode 向 LowCode/NoCode 演进时,应用的交付成本能降低到一定程度,我们就能让那些模式化、特定垂直场景的业务交给非专业前端开发人员维护,比如外包、后端,甚至是非开发类的角色。
未来,我们产品的演进目标是通过推动研发模式的改变,让盒马前端团队从【资源型前端】向【服务型前端】而转变,从授人以鱼到授人以渔:

技术分层架构
要达到以上目标,需要 ReX Dev 平台不断演进迭代,这背后需要有一个稳健的架构支撑。具体而言,ReX Dev 采用如下分层架:
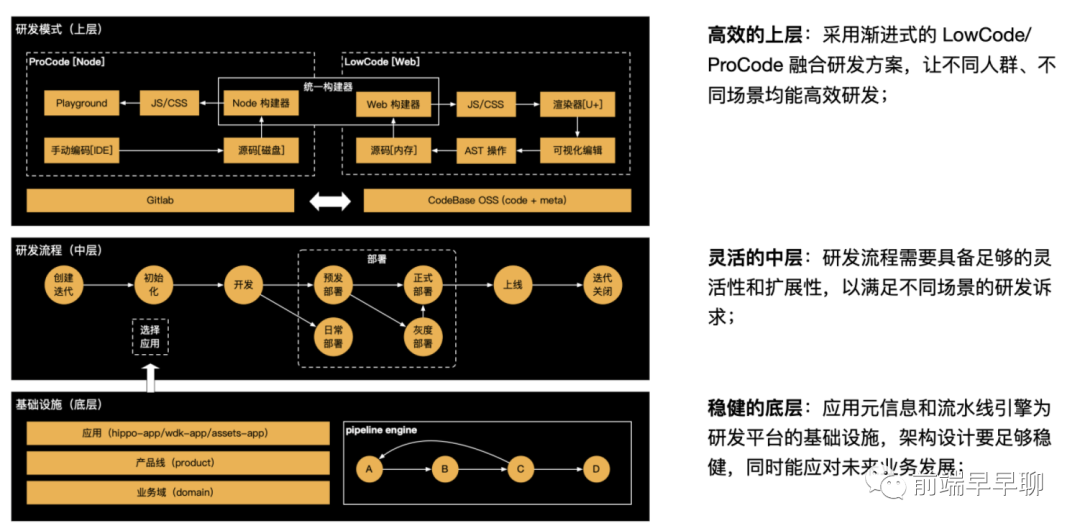
设计如上架构时,主要考虑了以下几点:
平台的底层要足够稳健,应用的元信息模型能适应未来的业务发展,不因底层模型约束上层业务发展,同时研发流程需要流水线支持,要有强大且灵活的流水线引擎; 考虑业务在持续变化的,我们的研发流程一定要足够的灵活,能满足不同场景的扩展需求,即使未来有新的应用形态出现时也能快速的支持; 研发流程只能解决协同效率,而要提升研发效率,推动研发模式转变,因此首先在研发平台上层需要提供就是更高效的 LowCode 研发能力。
总结下来就是稳健的底层、灵活的中层、高效的上层,接下来我们会从这三层分别展开。
稳健的底层
研发平台的底层,也就是研发平台的核心,如果我们看一个极简的 CI/CD 模型,它其实主要由两分部组成:应用与迭代循环。研发平台的核心能力就是为满足这两个部分存在的,因此我们有两大目标:
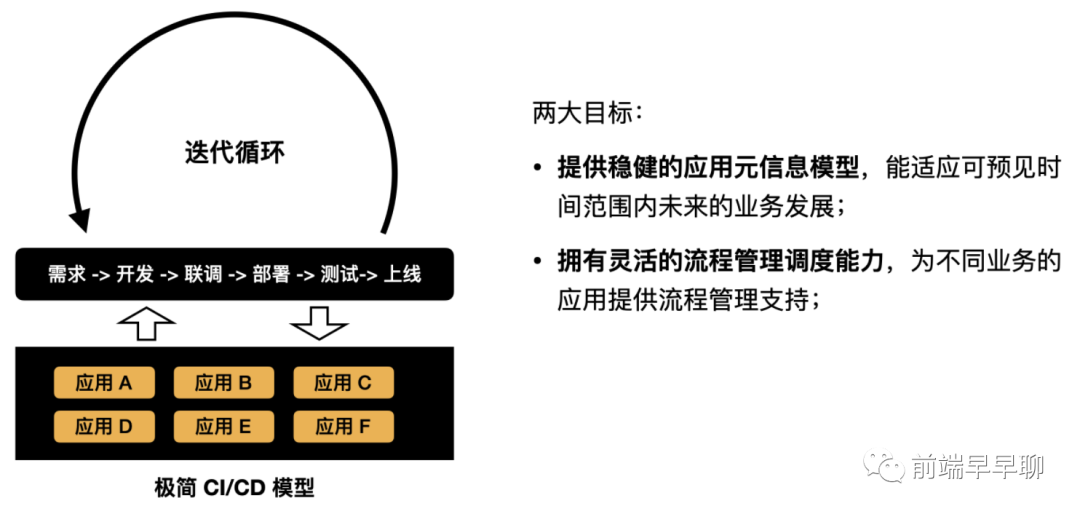
针对应用,有要稳健的应用元信息模型;针对迭代循环,要有灵活的流程调度能力。
元信息架构设计
如下图所示,为了便于管理,我们一般会将应用元信息按 domain/product/app 这三层进行抽象(不同平台可能名称不同但结构是相似的):
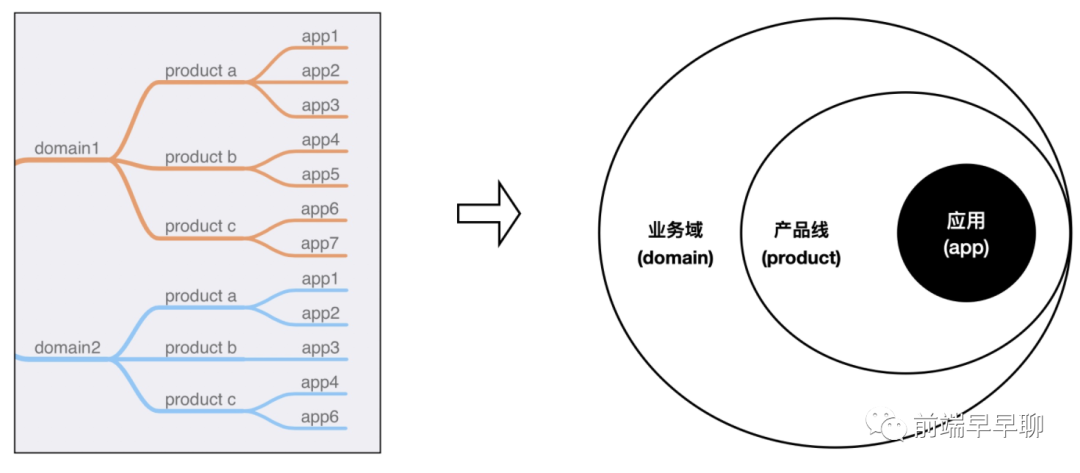
在传统的设计中,一般会对 domain+product+app 这三者进行唯一约束,这是一种比较严谨的做法,在早期我们也是按这种方式设计的。
但经过实际的业务落地之后,发现这种唯一性约束会带来较大的灵活性问题:盒马的业务在不断发展过程中,产品线是会持续发生变化的,而这种唯一性约束会被相关工程方案形成间接依赖,导致后面要切换产品线时成本非常高,甚至要进行数据订正。
因此,我们在这种信息架构基础之上,让 app 只与 domain 形成依赖,构建唯一约束,而与 product 是弱依赖的关系(product 灵活可变):
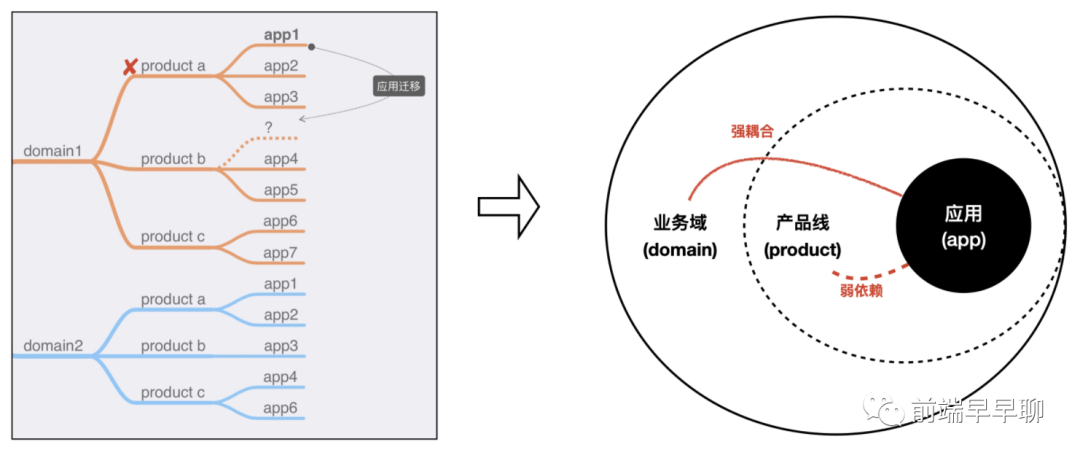
基于这种关联关系,我们能做到一键转移应用至其它产品线,而不会对应用的研发造成任何影响。
元信息模型的设计,看起来虽然很简单,但由于它属于基础的数据结构,会被上层依赖,设计上一旦考虑不周会导致重构成本大幅上升,因此要特别慎重考虑。我建议在设计时,一定要面向未来考虑,思考未来变与不变的部分。
这里可能有人会问,为何 app 不直接全局唯一,而还是要依赖 domain?这主要是综合考虑变化的可能性,以及冲突带来的成本问题:
盒马这类业务,app 的数量非常大,不同 domain 下的 app 非常容易冲突重名,全局唯一只会导致用户在 app 的 name 上自行添加前缀,管理和理解成本都会非常高; 一般来说,跨 domain 的应用迁移并不多见,几乎很少会有一个 app 同时负责于多个 domain 的,同时 domain 也比较稳定,因此 app+domain 的约束综合管理成本最低。
流水线引擎设计
除了元信息之外,底层架构另外一个重要的部分就是流水线调度引擎。作为底层的一部分,我们希望设计一个通用化的流水线调度引擎,它要能做到:
实现任意异步任务的调度执行,支持执行节点状态共享、输入输出管道化 支持灵活的任务流程定制,任务可串行、并行执行 支持全链路异常捕获,任务重试与调度恢复,实时的任务日志
下面是一个典型的迭代流程:
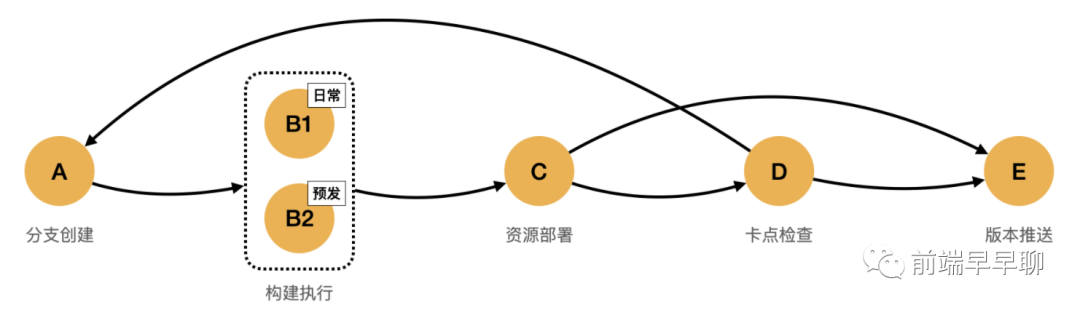
要引擎应该如何设计呢?下面我们分别来看它的关键设计。
流水线状态机
从上图可以看出,流程本质上就是一个有向图,流程的流转本质上就是一个有限状态机。当然,不同于传统的状态机模型,流水线执行节点本身是异步的,而异步节点内部本身又带有多个状态,这使得流水线的状态机模型更像一种分形结构:一个状态节点又可以拆分成若干个子状态。
下面是对状态节点的一个简单抽象,它就像一个 Promise 一样,包含 3 个状态。将流水节点定义为 stages,执行动作定义为 actions,那么执行引擎就是 run() 函数:
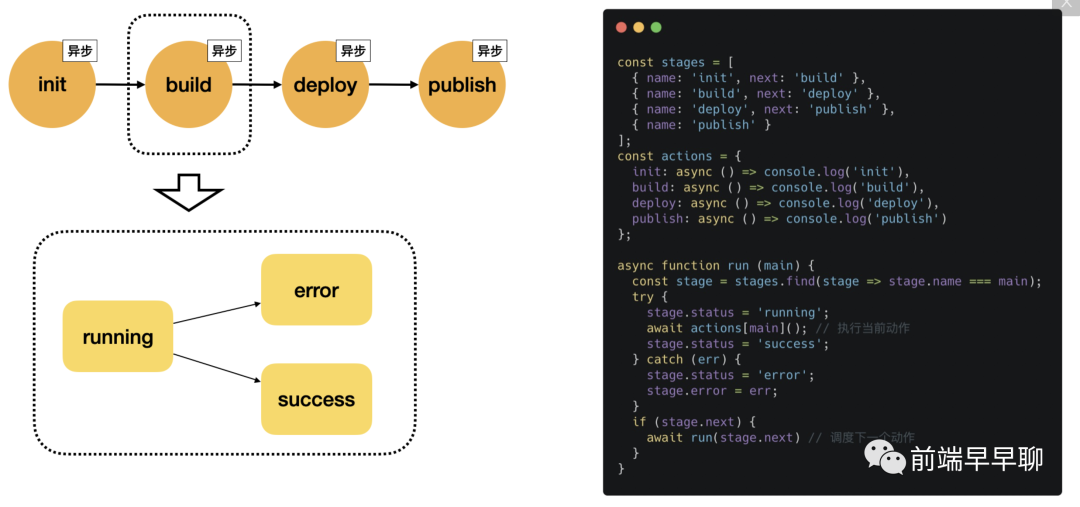
可以看到,这个执行引擎逻辑非常简单:读取当前状态,执行对应的动作,获取下一个状态,然后递归执行相同的逻辑。
上下文与管道
通过状态机模型,我们可以将流水线执行起来了。在真实世界中,流水线的节点是分布式执行的,它们往往是独立的,很可能是在不同机器、不同进程中执行。因此,就需要解决各个节点之间数据状态的通信问题。
为了便于通信,我们需要提供两种模型:上下文状态共享与管道化支持。
上下文可以解决多个节点数据共享问题,适合持久存储的数据; 管道解决了两个相邻节点之间的通信问题,上一个节点的输出是当前节点的输入;
下图提供了一个状态节点的上下文及管道数据的流转过程:
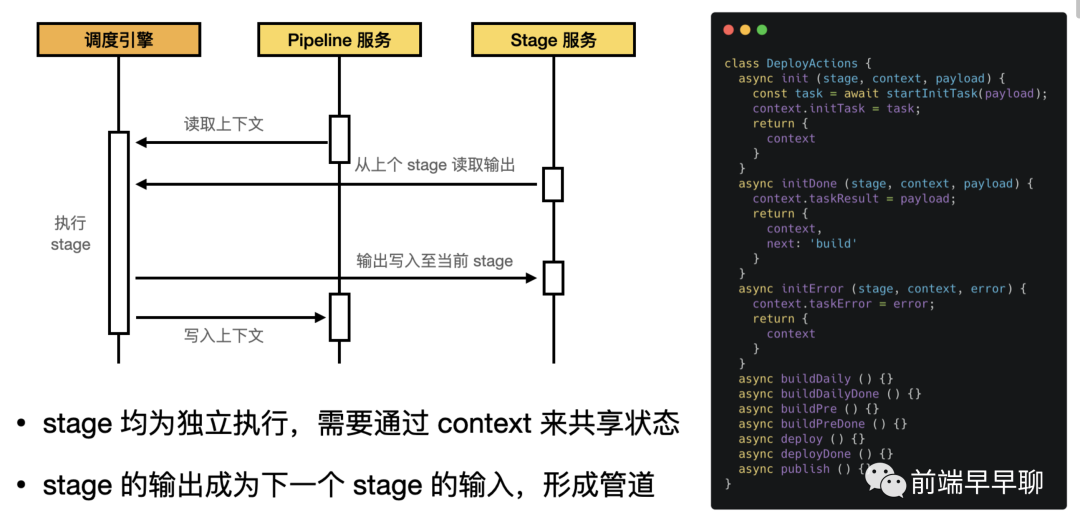
在右侧的代码中,一个状态节点会接收 context 和 payload 作为参数,经过处理后会返回 context 和 payload,它的外层代码类似如下结构:
async function runStageAction (pipeline, stage, payload) {
// read context
const context = await pipeline.readContext();
// run action
const result = await stage.runCurrentAction(context, payload);
// write context
await pipeline.saveContext(result.context);
// schedule next action
stage.scheduleNext(result.payload);
}
在最后一步,调度器会触发下一个 stage action 的执行,传入的参数即为当前 action 的输出。
异常自动恢复
由于流水线引擎是流水线服务的核心模块,在设计上为保障稳定性,流水线引擎本身只会做任务的调度,具体的执行会派发到相应的执行服务上。因此,流水线的异常会分为两种情况:
流水线节点执行的异常,这个会比较常见,一般都是执行逻辑错误或三方依赖存在问题; 流水线调度异常,这一般会很少见,只会出现在服务器故障、重启等场景才会发生。
对于前者,我们在流水线节点设计了 stageError 函数,它会在节点出错时被调用,这允许流程开发者可以自行决定错误处理逻辑。
而调度异常,通过引入 DTS 定时任务机制,定时对调度失败的任务进行检查,就可以在出现问题时进行流程重新调度。
流程实时日志
由于流水线节点的执行往往是在后台异步进行的,如果节点执行异常排查将会非常困难,因此我们需要记录节点执行的详细日志,有些节点执行时间较长,还需要实时日志展示。
我们基于原 just 的实时日志进行了简单封装,在节点执行前后进行日志记录:
async function execute (stage, action, context, payload) {
const logger = createRealtimeLogger();
const executor = loadExecutor(logger);
// start log
await logger.start();
// execute stage action
const result = await executor.execute(stage, context, payload);
// end log
await logger.end();
return result;
}
在 execute 中调用 this.logger 以及向 logger 写入日志流,都会将日志实时同步至日志服务上。
流水线引擎架构
基于以上设计,我们可以将整个流水线引擎架构总结成下图:
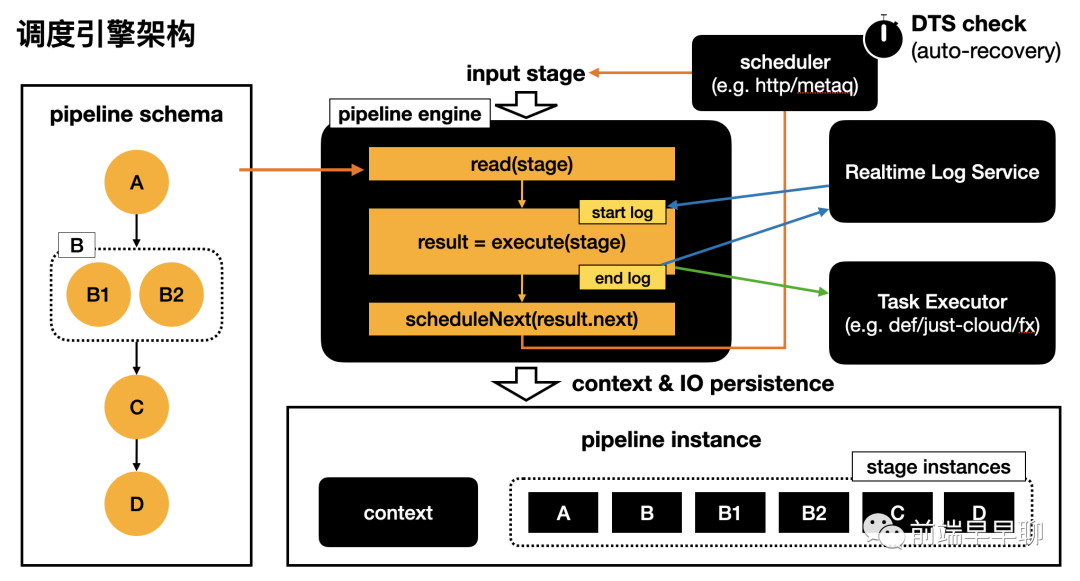
上图中的要点如下:
pipeline schema 定义了流水线的状态机模型,它是一个有向图; pipeline engine 基于 pipeline schema 执行输入的 stage 实例任务,它是一个读取、执行、调度的循环; execute 函数的具体执行由 Task Executor 服务执行,在 execute 前后通过 realtime log service 进行实时日志的输出; pipeline engine 在执行过程中会持续向 pipeline & stage instance 中写入相应的 context 和 I/O 数据,进行数据持久化; scheduler 调度器通过 metaq/http 等方式进行流程的分布式调度,并通过 DTS 进行检查和自动恢复。
流水线产品化
以上只是流水线调度引擎的架构实现,基于这套引擎,我们可以通过不同层次的产品封装实现许多上层能力,比如:
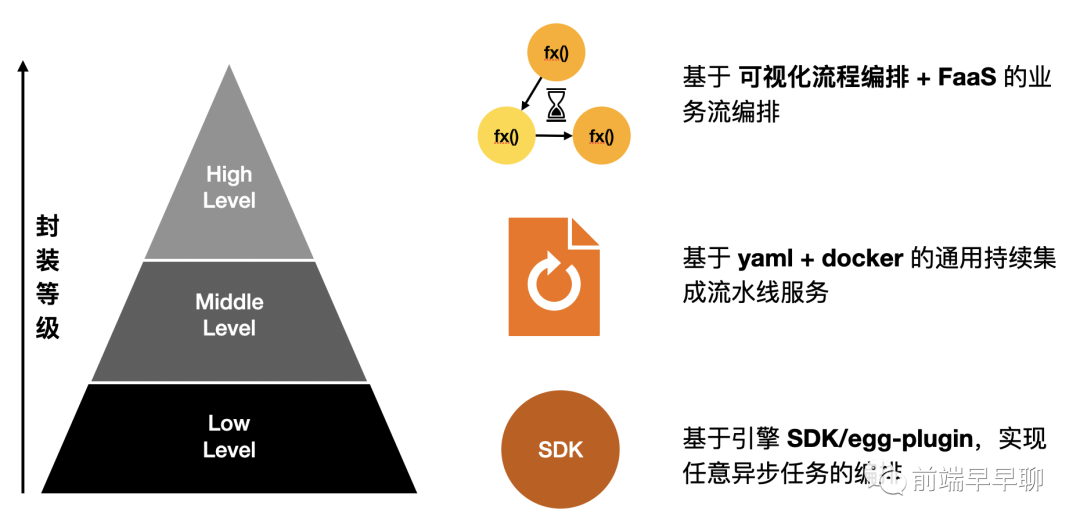
目前,我们还未做 High Level 的封装,只 Low Level 的形式为如下场景提供了流程调度的支持:
灵活的中层
有了稳健的元信息架构和强大的流水线调度引擎,我们就可以在此之上建设各类应用的研发流程了,这就是中层的职责:为不同场景下的 CI/CD 流程提供灵活、低成本的定制能力。
下图展示了当前盒马不同应用的迭代流程:
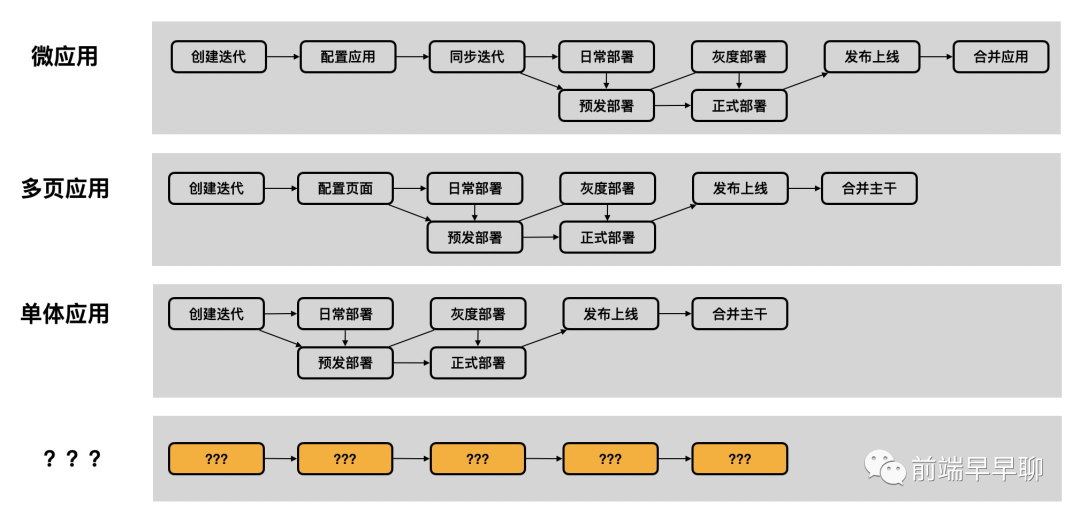
在当下我们有三种应用类型需要支持,同时考虑到未来新应用类型的接入,应该用怎样的架构去支撑呢?
流程抽象:定制的基础
要让流程可扩展,首先要进行流程的抽象。对于一个迭代,可以将它大致划分为如下几个阶段:
创建迭代:主要是创建迭代实例和开发分支,所有流程基本都一样; 配置迭代:这一步是为了让迭代在正式开发之前,做资源的初始化,比如环境配置、代码配置等,不同应用类型可能会不同; 开发迭代:包含实际的编码、调试以及相关的卡片检查等,不同应用类型差异会比较大,同时线上线下都有; 部署迭代:将开发的代码部署至相应的环境中,用于联调、灰度、正式发布等,不同应用流程差异也会比较大; 上线迭代:在完成正式部署之后,更新迭代的状态,这一步基本不需要定制;
因此,可以将一个迭代研发流程抽象成如下形式:
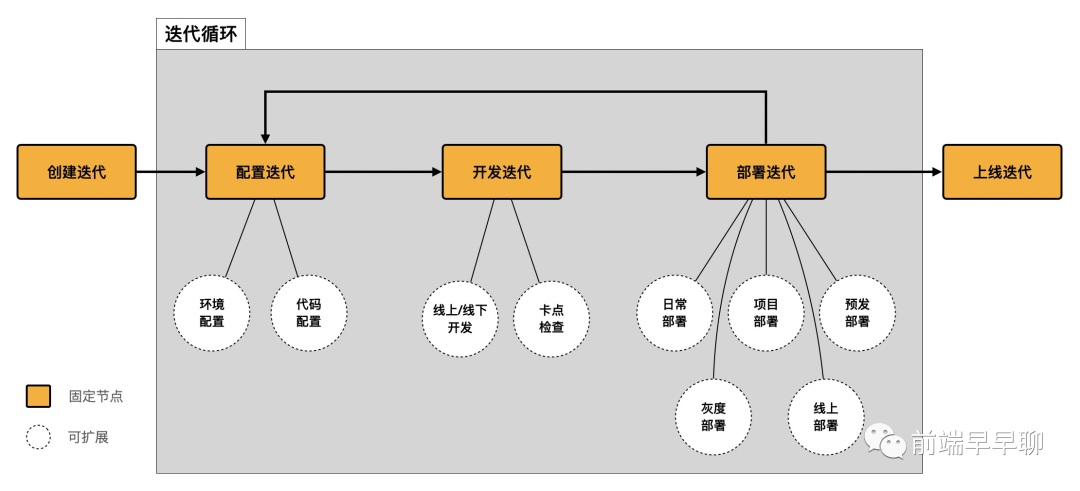
基于这种抽象,各类应用流程的定制方案示意如下:
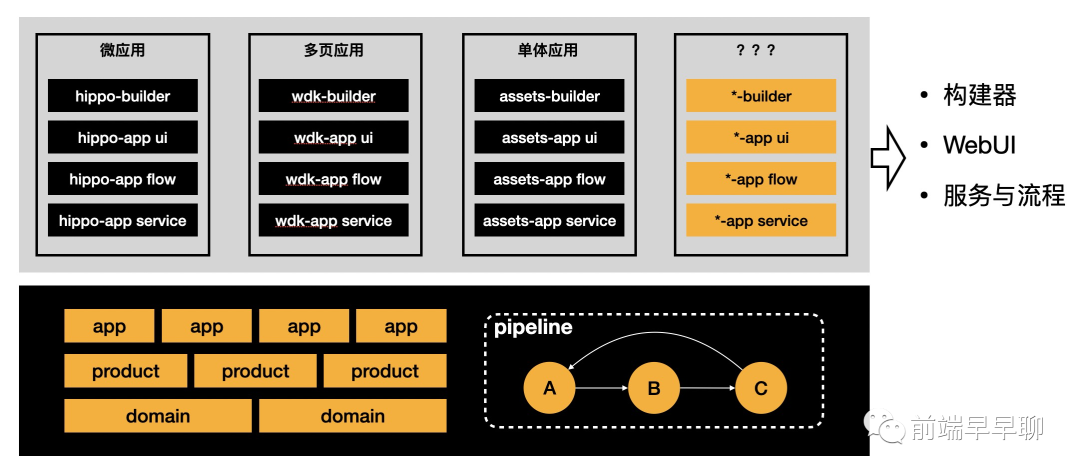
在上图的流程定制方案中,每一种应用类型都有一个定制包,它们是对抽象流程的扩展和实现。每一个定制包都包含以下几个部分:
构建器:负责将应用的源码编译成待发布的产物,会作为应用的依赖安装; WebUI:即应用在研发流程中对应的操作界面,每种应用都能定制自己的 UI,操作效率会更高; 部署流程:即应用的 CI/CD 部署流程,它们基于流水线引擎定制; 应用服务:即应用的基础服务以及内部逻辑封装,比如微应用和单体应用的创建服务是不同的; 流程卡点:即应用研发流程的检查卡点,比如 CR、封网、Lint、安全检查等;
以上定制中,构建器部分非常简单,本质上就是不同构建工具的封装(如各种 *pack),就不做单独说明了;部署流程是基于前面的流水线调度引擎定制的,它天然就是可扩展的,这里也不再赘述。
因此,接下来流程的扩展我们主要围绕 应用服务、WebUI、流程卡点 的扩展来介绍。
服务扩展基础:SPI
对服务的扩展,理想情况下要做到无侵入的执行逻辑替换。要这样这种能力有多种方式,但就研发流程这类场景而言,可以考虑将服务实现逻辑外置,由三方系统实现,流程本身只做服务的调用,要实现这种模式的最佳方案就是 SPI。
维基百科对 的定义为:
Service provider interface (SPI) is an API intended to be implemented or extended by a third party. It can be used to enable framework extension and replaceable components.
传统的 API 模式,Server 端负责接口定义和服务实现,在 SPI 模式下,Server 端只负责接口定义和接口调用,服务实现由三方服务提供,如下图所示:
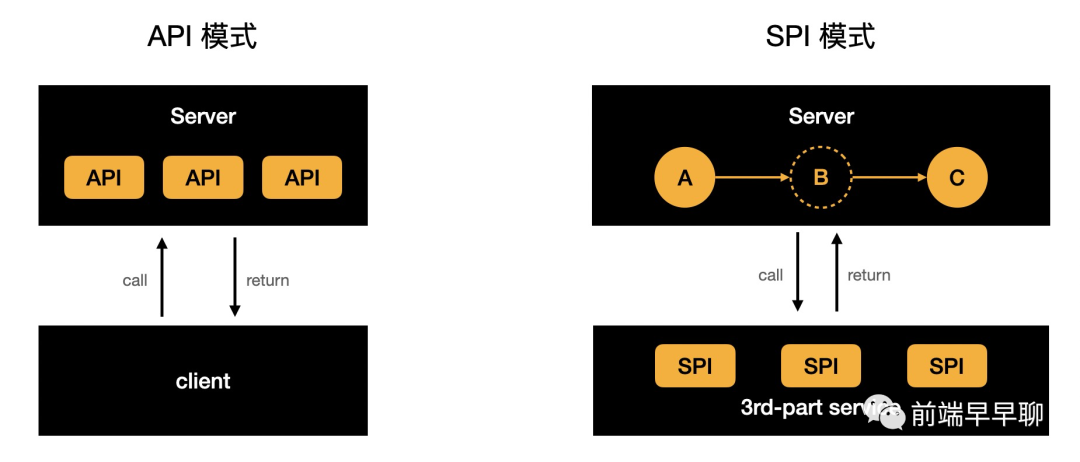
这种范式,其实在 JS 语言里大量存在,你可以认为 SPI 就是某种类型的 callback。在 ReX Dev 平台的具体实践中,以微应用服务扩展为例,其服务扩展架构如下:
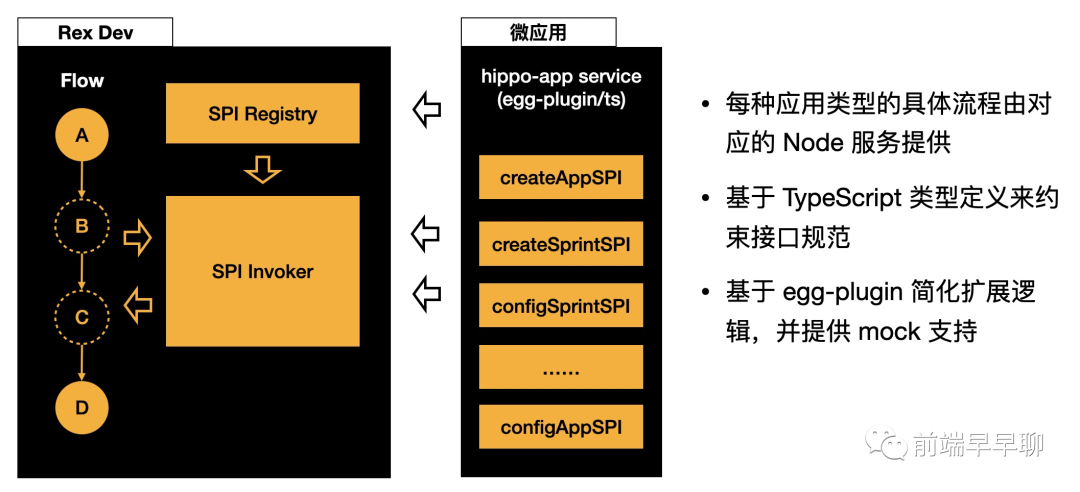
在上图中:
ReX Dev 负责研发流程的节点抽象和接口定义,包含创建应用、创建迭代、配置、部署等多个环节; 微应用扩展包以独立的 FaaS 应用封装,基于统一的 egg-plugin 提供相关 SPI 的实现; 微应用服务的元信息会向 ReX Dev 的 SPI Registry 注册,在具体的节点执行时,通过 SPI Invoker 来调用。
这样,无论 ReX Dev 要扩展多少流程,其本身的核心架构和服务稳定性是不会受影响的。
WebUI 扩展
与服务侧扩展 SPI 类似,WebUI 的扩展架构是相似的。本质都是基础的 WebUI 框架提供扩展槽位,具体的应用流程提供扩展模块,我们将这些提供具体功能的扩展组件称为 FPC(Feature Provider Component):
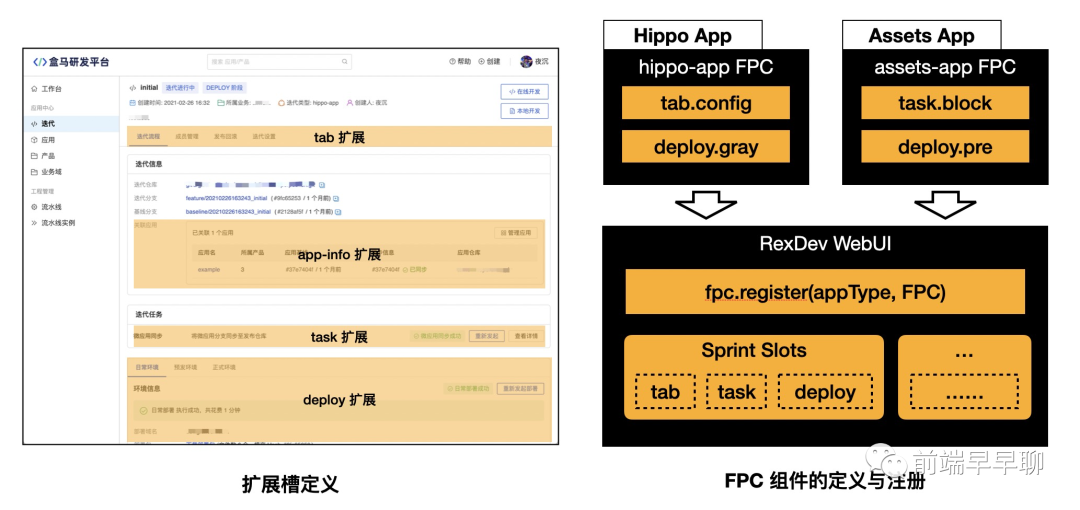
这种设计方案,在之前 B2B 工程平台 JUST Flow 和 JUST WebUI 中也早已经过实践,被证明是一种解决 UI 扩展时相对灵活的方案。
流程卡点扩展
常见的研发流程卡点包含 CodeReview、Lint、安全检查、封网、测试等,这些卡点都有一个共同的特点,即:卡点逻辑一般由三方系统实现,卡点的触发和检查由研发流程负责。
这样的话,任意流程都可能会对接某个三方服务进行卡点检查,为避免重复实现卡点逻辑,我们需要一个通用的卡点模型,让三方系统可以快速封装,同时研发流程也可以低成本接入。我们需要做以下抽象:
统一卡点模型,包含数据模型和卡点接口,所有三方系统都按相同接口封装; 定义标准卡点事件,所有卡点都只绑定标准卡点事件,比如 gitcommit、build; 提供事件触发 SDK,让研发流程在合适的时机触发标准事件。
基于这种抽象,卡点扩展方案如下:
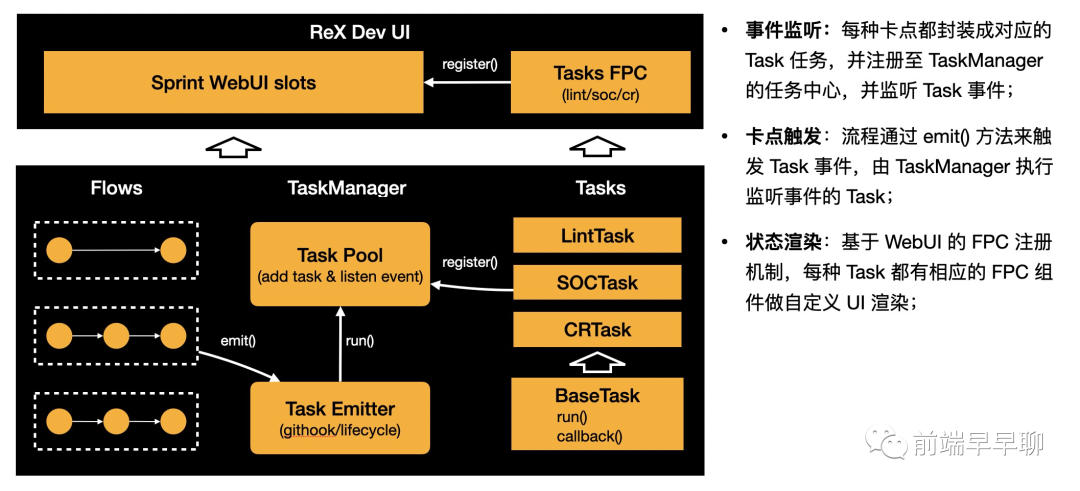
在上图中,所有的卡点任务都基于 BaseTask 进行封装,有 run() 和 callback() 方法,每个卡点都会注册至统一的 Task Pool 中,当研发流程触发标准事件时,会从 Task Pool 中寻找匹配的 Task 并执行,同时 Task 实例将与当前流程关联。
另外,每个卡点 Task 实例往往都需要有 UI 操作行为(比如 CodeReview 提交、封网申请),因此每个卡点任务都会有对应的 UI 模块来实现,这个通过上一节提到的 FPC 就可以实现。
对流程定制的思考
在这一章中,我们介绍 ReX Dev 如何通过合理的架构设计实现不同流程扩展,同时不影响自身的稳定性。一般来说,只有当研发模式有重大区别时,才应该采用这种扩展形式。毕竟,开新的流程本身有一些的开发工作量,同时也会有长尾和碎片化的风险,带来架构治理问题。
除了流程定制外,其实可以考虑以下替代方案:

高效的上层
研发流程覆盖了项目的全生命周期,而其中最为关键的就是编码,也是一个项目开发过程中最为核心的部分。要在上层提效,关键是如何提升编码效率。
在盒马的业务场景下,模式化、轻量化的应用体系,让低代码、甚至无代码开发成为了可能,下面我们来分析不同的研发模式的适用人群与场景:
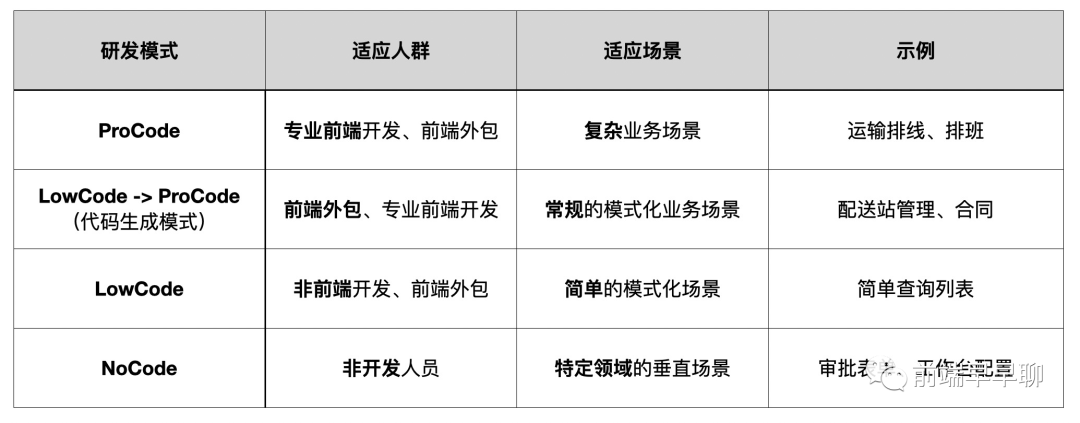
从 ProCode -> LowCode -> NoCode,其适用场景是越来越窄的,带来的研发效率提升也会更明显。当代码越来越少时,以前在 ProCode 上附加的卡点检查可能也不需要了,比如 Lint、CodeReview 等,又会进一步促进开发效率。
传统的单一开发模式下,NoCode/LowCode/ProCode 的技术方案一般都是独立实现的,这导致了单一模式困境:业务早期可基于 LowCode/NoCode 快速实现,但后期需求迭代导致页面复杂度上升,导致 LowCode/NoCode 平台难以支持,最后要么是将应用基于 ProCode 实现一遍,要么是向 LowCode/NoCode 平台不断的增加功能。
LowCode/NoCode 平台功能并不是越多越好,因为它们面向的人群是非专业的前端开发者,它的优势是简单,膨胀的功能会带来复杂度,并损害原有用户的开发体验。明确一个 LowCode/NoCode 平台的定位与能力圈是非常重要的,保持足够的简单才会让它在特定场景下足够的高效。
盒马的选择:渐进式研发
对于盒马而言,立志于将盒马前端团队从资源型支持,转到服务型前端团队,需要让资深前端开发人员专注在复杂场景的 ProCode 开发上,然后通过 LowCode/NoCode 让外包、后端、非技术人员来完成应用交付。我们希望一个应用,能按 NoCode -> LowCode -> ProCode 的方式支持,一种模式无法满足就降级下一种模式,我们称之为渐进式研发模式。
渐进式研发模式在最大优势在于,通过不同研发模式的优雅降级,让研发模式在适用范围里保持简单,避免平台功能膨胀和复杂度的上升。
下图展示了盒马渐进式研发模式的转换与应用框架的封装逻辑:
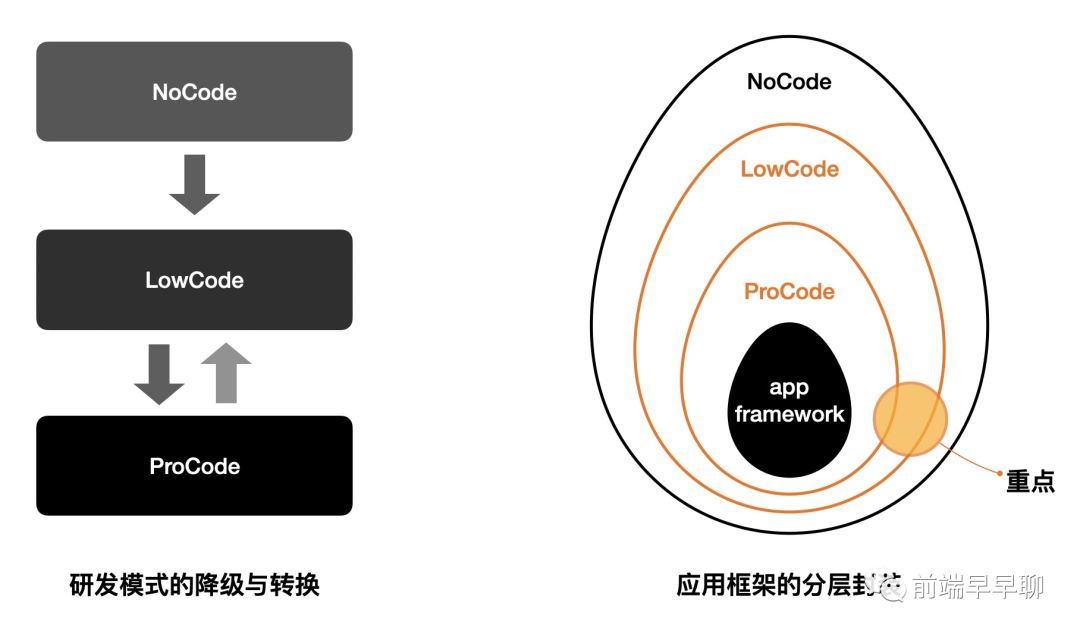
在上图中:
NoCode 可降级至 LowCode,LowCode 可降级至 ProCode,同时有限的 ProCode 可逆向转换为 LowCode; 所有的研发模式,底层都是基于同一个应用框架不断封装来实现的,LowCode 基于 ProCode 封装,NoCode 基于 LowCode 模式封装;
限于篇幅,我们将会重点介绍 ProCode -> LowCode 的降级和逆向转换逻辑。
LowCode/ProCode 互转方案
在阿里集团内部,最流行的 LowCode 方案都是基于 Schema LowCode 模式的。Schema LowCode 就是指 LowCode 可视化搭建的底层是基于一套 schema 或 DSL 实现的,通过操作 schema 来实现 UI 的编辑。
而盒马选择的是 JSX-AST LowCode 模式。JSX 本身提供了一套 XML 风格的声明式语法,我们通过操纵 JSX 编译后的 AST 来实现 UI 的编辑,相比 schema 化最大的优势是它可以实现 100% 的逆向转换。
具体对比如下图所示:

盒马之所有做以下选择,有几个主要原因:
盒马的应用交互形态相对模式化,可以在应用层做 JSX 的模式化约束; 渐进式研发是我们的核心理念,我们会更倾向整个研发模式是可以优雅降级的; 在 JSX-AST 这个领域里,我们有足够的前期技术积累,有相对成熟的方案;
JSX-AST LowCode 实现机制
基于 JSX-AST 的 LowCode,需要解决一个关键问题:寻找一个 UI 元素背后的 AST 节点,并对其进行 AST Patch,实现即时编辑的效果。
具体原理其实并不复杂,大致转换流程如下所示:
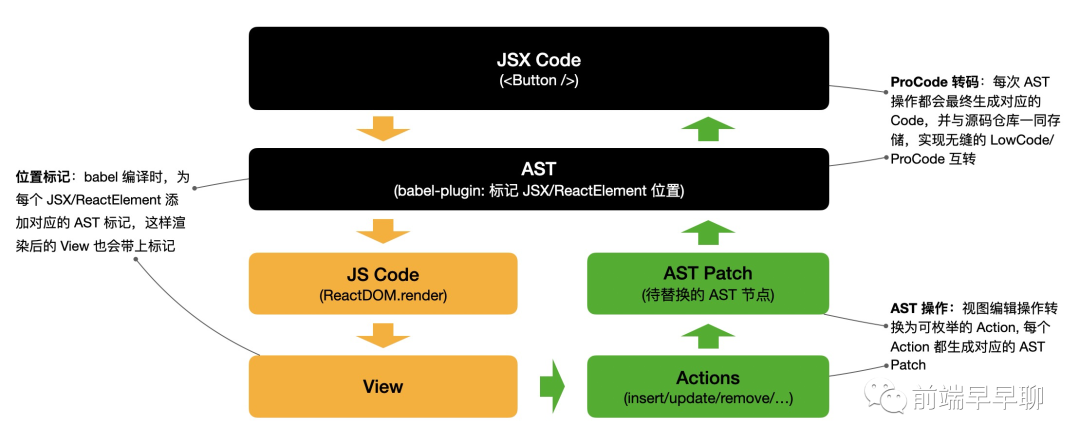
在编辑态下,JSX 在编译成 AST 时会经过特定 babel-plugin 的处理,为 JSX 元素添加特定的标记(记录 AST 节点、源码位置等信息),当操作 UI 时会根据这些标记寻找到目标 AST 节点,并将生成的 Patch 替换原来的 AST,然后经过重新编译和渲染,修改过的 UI 就会实时生效,同时 AST 也会回写生成 JSX Code。
以上,就是可逆转换的 ProCode/LowCode 方案。
应用层约束与降级处理
了解了 JSX-AST 原理之后,你可能会好奇,JSX 语法其实是非常灵活的,这会导致实际的 AST 结构非常复杂,最后让 UI 难以通过可视化的方式来编辑,盒马是怎样应对的?
的确,要基于 JSX-AST 来实现 LowCode 搭建,这个问题是必须面对的。事实上,要解决这个问题有两个选择:
一种是通过定义一套类 JSX 的 DSL,实现对 UI 的强约束,比如不支持在 JSX 中写 JS 条件表达式和循环语句,这在阿里集团内部有很多方案; 另一种是不扩展 JSX,依然保持原生写法,但通过特定的应用层写法的约束来避免 JSX 过于自由;
定义 DSL 虽然并不复杂,但它毕竟是一个方言,一旦引入方言就需要全套的工程支持(IDE 插件、babel 插件、各类工程支持等),对第三方输出时也非常不友好。综合考虑盒马的现状,我们认为 DSL 的方案过重,并不适合盒马场景。
最终,我们采用了方案二,对 JSX 的约束写法如下:
// @lowcode: 1.0 # 表示启动低代码支持,将会做【严格模式】检查
// 模块引用
import React from 'react';
import styled from 'styled-components';
import { If, ForEach, observer } from '@alilfe/hippo-app';
import { Layout, SearchForm, Table } from '@alife/hippo';
import Model from './model';
// 常量定义
const { Page, Content, Header, Section } = Layout;
const { Item } = SearchForm;
// 样式定义
const StyleContainer = styled.div`
height: 100%;
`;
// 视图定义(名称固定为 View,拥有固定的参数:$page/$model)
function View({ $page, $model }) {
return (
<StyleContainer>
<Page page={$page}>
<Header>
{/* If 条件表达式:if value = ? then ? */}
<If value={!$model.loading}>
<HeaderDetail model={$model.detail} />
If>
Header>
<Content>
<Section>
<SearchForm model={$model.section1.form} onSearch={$model.search}>
<Item name="p1" title="条件1" component="input" />
<Item name="p2" title="条件2" component="input" />
<Item name="p3" title="条件3" component="input" />
SearchForm>
Section>
<Section>
{/* ForEach 循环组件:通过 FaCC 的方式对 <Item /> 进行迭代 */}
<ForEach items={$model.data.list} keyName="key">
{($item, i) => (
<div className="list-item">
<div className="header">
<div className="title">{$item.title}div>
<div className="extra">
<Button onClick={(v) => $model.show(v, $item)}>加载Button>
div>
div>
div>
)}
ForEach>
<Pagination
current={$model.page.pageNo}
onChange={$model.changePage}
/>
Section>
Content>
Page>
StyleContainer>
)
}
// 导出视图
export default observer(Model)(View);
除了 JSX 外,还需要约束应用层,具体体现在三个方面:
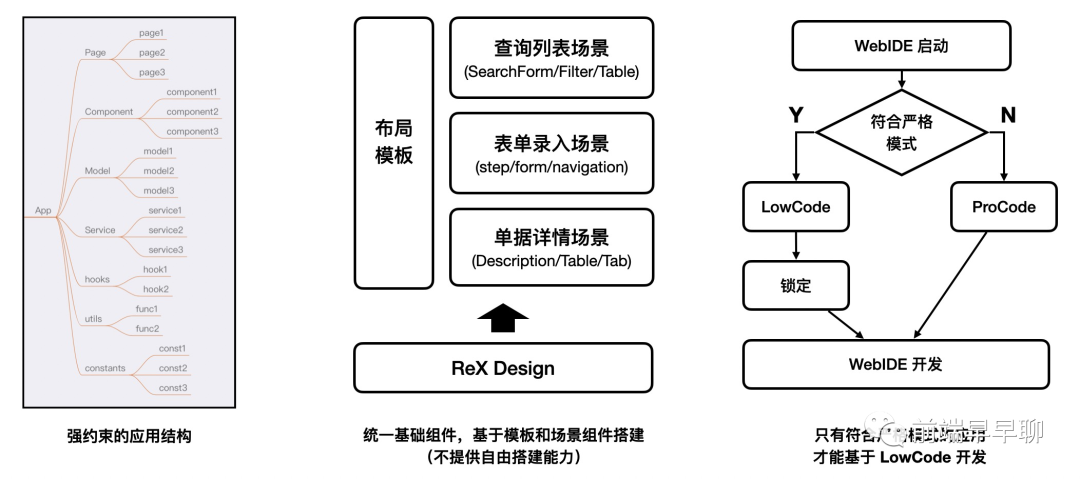
总结下来,就是:
应用结构要强约束,过于自由的结构会给 LowCode 带来非常大的管理和解析成本; 适用场景要约束,我们不提供自由搭建能力,只针对高频的场景提供快速搭建,保证 UI 结构的收敛; 采用严格模式对代码风格和写法进行强约束,只有符合严格模式的应用才能进行 LowCode 搭建模式;
通过以上约束,可以让应用变得非常规范,能极大降低 JSX-AST LowCode 模式背后的实现复杂度;同时,如何用户需要用 ProCode 开发,只需要遵循这套规范,写后的代码依然可以用 LowCode 搭建。
统一 Node/Web 构建方案
要实现多种研发模式的融合开发,除了应用层的统一外,还需要在工程方案上保持一致性,即无论是 LowCode 还是 ProCode,其底层的构建机制应该是统一的,这样就保证。
由于 LowCode 搭建产品是基于 Web 的,因此 Web 侧需要提供一套与 Node 侧一致的构建方案。目前,ProCode 侧的构建器还是基于 webpack 实现的,经过一系统的调研和方案选择之外,我们还是采用了基于 webpack 的 Web 端构建方案。
具体如下:
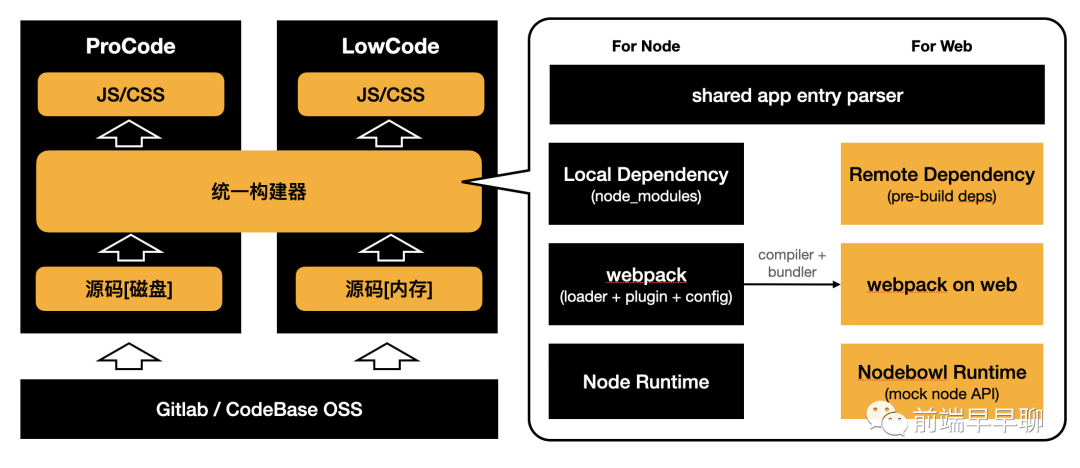
以上构建器设计方案中:
ProCode 与 LowCode 遵循相似的构建模型,即从目标位置(磁盘/内存)读取 JS/CSS,经过构建后生成目标代码; 通过将 webpack 及相关插件、配置编译成 bundle,再结合 Nodebowl Runtime 实现在 web 端运行 webpack; 通过依赖的预构建方案,实现依赖的远程编译和加载,让 web 侧可以与 local 开发一样自由的添加、删除依赖;
LowCode/ProCode 融合研发小结
最后,总结一下 LowCode/ProCode 融合研发方案:
选择最合适的方案:没有最好的方案,只有最合适的,基于 JSX-AST 的 LowCode/ProCode 互转方案,更符合我们对渐进式研发的理念,也许你的场景 Schema 模式也够用了; 确定清晰的边界:LowCode 的高效在于特定细分领域的业务开发,对于不符合 LowCode 的场景采用 ProCode 是更高效的选择,也有利于平台保持简单; 避免从零搭建应用:避免让用户从零开始搭建应用,而是通过模板、脚手架、数据模型这类“半成品”开始(就像盒马售卖的“快手菜”,通过半成品让一个不会做饭的小白也能做好一道菜)。
思考与总结
为了追求技术的普适性,本次分享聚焦 ReX Dev 研发平台背后的产品思考与技术实现,对于产品功能的介绍并不多,因为分享盒马的应用如何创建、如何部署意义并不大,讨论如何实现部署流程才是关键。
工欲善其事,必先利其器。个人认为团队在任何时期都需要在支持好业务的同时,考虑如何提升团队的整体研发效率,这类基础性的投入不在于资源的多,而在于持续、稳定的投入。工程化就如同软件架构一样,需要持续的演进、面向未来而不断优化。
由于前端工程是一个复杂的系统性工作,因此作为架构师在进行工程体系的设计时,需要面向未来做长远的考虑,如果是当前识别到的架构问题,一定要在早期解决掉,避免因为架构设计问题给未来的人留坑,这在我这近年来做前端工程化时深有体会。
就我自己的经验,在做前端工程化的架构设计时,有以下几个原则:
做好分层设计,无论你的产品是全家桶式,还是自由组合式的,核心架构的分层一定要做好。分层设计的核心在于将稳定的部分放在最底层,它应该能应对未来业务 3~5 年的变化,上层方案需要足够的聚焦,解决特定场景的问题。 拥抱社区趋势,除非有足够的资源保障和更先进的理念,否则工程方案最好是基于社区方案封装或改造,社区的趋势决定了未来方向,自己造轮子最大的问题是可能后面无人维护,最后成为团队的技术债务。 产品上收敛,架构上灵活,做前端工程非常忌讳碎片化,强调方案的统一和收敛,但同时又要兼顾灵活性,因此不能把架构设计的过死,基于一个预设的场景做约束,而是在底层上保持一定的灵活性,将约束放在最上层的产品功能上。面对需求应该做到:底层架构上“都能支持”,但在产品上“选择不支持”。
具体到 ReX Dev 平台,其分层设计是贯穿始终的,比如整个研发平台的产品分层、流水线引擎的设计分层到研发模式的分层;同时在选择 ProCode/LowCode 互转方案时,我们抛弃了 DSL 的方案,而采用原生 JSX,也是考虑到未来 DSL 的可维护性;我们在架构上提供了灵活的流程扩展支持,但在具体的流程设计上,我们的首要原则其实是收敛的,避免碎片化。
前端工程化是一个非常具有场景化特征的技术领域,不同的前端团队技术形态的不同,导致背后的工程方案也千差万别。统一工程平台,本质上是统一和收敛技术形态,就阿里集团而言,内部存在大量的工程平台,往往不同 BU 都有一套,这是各个 BU 在技术形态上的差异导致的。
作为工程领域的架构师,是自建研发平台还是基于存量平台扩展定制,就需要你综合团队现状、未来发展、投入产出比等多个方面仔细思考了。
最后,按早早聊的规矩,给大家推荐一本书《架构整洁之道》:

- 这是底线 -
我组建了一个氛围特别好的 Node.js 社群,里面有很多 Node.js小伙伴,如果你对Node.js学习感兴趣的话(后续有计划也可以),我们可以一起进行Node.js相关的交流、学习、共建。下方加 考拉 好友回复「Node」即可。
“分享、点赞、在看” 支持一波👍