
BPF 之巅:洞悉 Linux 系统和应用性能

以下内容节选自《BPF之巅:洞悉Linux系统和应用性能》一书!

▊ BPF 和 eBPF 是什么
BPF 是 Berkeley Packet Filter(伯克利数据包过滤器)的缩写,这项冷门技术诞生于 1992 年,其作用是提升网络包过滤工具的性能。2013 年,Alexei Starovoitov 向 Linux 社区提交了重新实现 BPF 的内核补丁,经过他和 Daniel Borkmann 的共同完善, 相关工作在 2014 年正式并入 Linux 内核主线。此举将 BPF变成了一个更通用的执行引擎,其可以完成多种任务,包括用来创建先进的性能分析工具。
精确地解释 BPF 的作用比较困难,因为它能做的事情实在太多了。简单来说,BPF 提供了一种在各种内核事件和应用程序事件发生时运行一段小程序的机制。如果你熟悉 JavaScript,可能会看到一些相似之处 :JavaScript 允许网站在浏览器中发生某事件(比如鼠标单击)时运行一段小程序,这样就催生了各式各样基于 Web 的应用程序。BPF 则允许内核在系统和应用程序事件(如磁盘 I/O 事件)发生时运行一段小程序,这样就催生了新的系统编程技术。该技术将内核变得完全可编程,允许用户(包括非专业内核 开发人员)定制和控制他们的系统,以解决现实问题。
BPF 是一项灵活而高效的技术,由指令集、存储对象和辅助函数等几部分组成。由于它采用了虚拟指令集规范,因此也可将它视作一种虚拟机实现。这些指令由 Linux 内核的 BPF 运行时模块执行,具体来说,该运行时模块提供两种执行机制 :一个解释器和一个将 BPF 指令动态转换为本地化指令的即时(JIT)编译器。在实际执行之前,BPF 指令必须先通过验证器(verifer)的安全性检查,以确保 BPF 程序自身不会崩溃或者损坏内核(当然这不会阻止最终用户编写出不合逻辑的程序—那些虽可执行但没意义的程序)。
目前 BPF 的三个主要应用领域分别是网络、可观测性和安全。本书主要关注可观测性(跟踪)。
扩展后的 BPF 通常缩写为 eBPF,但官方的缩写仍然是 BPF,不带“e”,所以在本 书中,笔者用 BPF 代表扩展后的 BPF。事实上,在内核中只有一个执行引擎,即 BPF(扩展后的 BPF),它同时支持扩展后的 BPF 和“经典”的 BPF 程序。
▊ 跟踪、嗅探、采样、剖析和可观测性分别是什么
这些全都是用来对分析技术和工具进行分类的术语。
跟踪(tracing)是基于事件的记录—这也是 BPF工具所使用的监测方式。你可能已经使用过一些特定用途的跟踪工具。例如,Linux 下的 strace(1),可以记录和打印系统调用(system call)事件的信息。有许多工具并不跟踪事件,而是使用固定的计数器统计监测事件的频次,然后打印出摘要信息 ;Linux top(1) 便是这样的一个例子。跟踪工具的一个显著标志是,它具备记录原始事件和事件元数据的能力。但是这类数据的数量不少,因此可能需要经过后续处理生成摘要信息。BPF 技术,催生了可编程的跟踪工具的出现,这些工具可以在事件发生时,通过运行一段小程序来进行定制化的实时统计摘要生成或其他动作。
strace(1) 的名字中有“trace”(跟踪)字样,但并非所有跟踪工具的名字中都带 “trace”。例如,tcpdump(8) 是一个专门用于网络数据包的跟踪工具。(也许它应该被命 名为 tcptrace ?)Solaris 操作系统有它自己的 tcpdump 版本,称为 snoop(1M)(嗅探器);之所以起这个名字,是因为它是用来嗅探网络数据包的。笔者先前在 Solaris 系统上开发 和发布了许多跟踪工具,在那里我(有一丝后悔)普遍使用了“嗅探器”来命名那些工具。这也是为什么现在会有下面这些工具:execsnoop(8)、opensnoop(8)、biosnoop(8) 等。嗅探、 事件记录和跟踪,通常指的是一回事。这些工具将在后面的章节中加以介绍。
除了工具的名称,“tracing”一词也经常用于描述将 BPF 应用于可观测性方面的用途。Linux 内核开发人员尤其喜欢这么表达。
采样(sampling)工具通过获取全部观测量的子集来描绘目标的大致图像 ;这也被 称作生成性能剖析样本或 profiling。有一个 BPF 工具就叫 profile(8),它基于计时器来对运行中的代码定时采样。例如,它可以每 10 毫秒采样一次,换句话说,它可以每秒采样 100 次(在每个 CPU 上)。采样工具的一个优点是,其性能开销比跟踪工具小,因为 只对大量事件中的一部分进行测量。采样的缺点是,它只提供了一个大致的画像,会遗漏事件。
可观测性(observability)是指通过全面观测来理解一个系统,可以实现这一目标的工具就可以归类为可观测性工具。这其中包括跟踪工具、采样工具和基于固定计数器的工具。但不包括基准测量(benchmark)工具,基准测量工具在系统上模拟业务负载,会更改系统的状态。本书中的 BPF 工具就属于可观测性工具,它们使用 BPF 技术进行 可编程型跟踪分析。
▊ 初识 BCC:快速上手
让我们直接切入主题,快速上手来看一些工具的输出吧。下面这个工具会跟踪每 个新创建的进程,并且为每次进程创建打印一行信息。这个叫 execsnoop(8) 的工具来自 BCC 项目,它通过跟踪 execve(2) 系统调用来工作。execve(2) 是 exec(2) 系统调用的一 个变体(也因而得名)。第 4 章会介绍 BCC 工具的安装,再往后的章节会更详细地介绍相关工具。
# execsnoop | |||
PCOMM | PID | PPID | RET ARGS |
run | 12983 | 4469 | 0 ./run |
bash | 12983 | 4469 | 0 /bin/bash |
svstat | 12985 | 12984 | 0 /command/svstat /service/httpd |
perl | 12986 | 12984 | 0 /usr/bin/perl -e $l=<>;$l=~/(\d+) sec/;print $1||0 |
ps | 12988 | 12987 | 0 /bin/ps --ppid 1 -o pid,cmd,args |
grep | 12989 | 12987 | 0 /bin/grep org.apache.catalina |
sed | 12990 | 12987 | 0 /bin/sed s/^ *//; |
cut | 12991 | 12987 | 0 /usr/bin/cut -d -f 1 |
xargs | 12992 | 12987 | 0 /usr/bin/xargs |
echo | 12993 | 12992 | 0 /bin/echo |
mkdir | 12994 | 12983 | 0 /bin/mkdir -v -p /data/tomcat |
mkdir | 12995 | 12983 | 0 /bin/mkdir -v -p /apps/tomcat/webapps |
^C | |||
# |
上面的输出显示了在执行跟踪的过程中,系统创建了哪些进程 :其中有些进程运行 时间太短,因而使用其他工具可能无法捕获到相关信息。在输出中都能看到大量标准的 UNIX 工具:ps(1)、grep(1)、sed(1)、cut(1) 等。但是在这里你无法看到这个命令的打印速度。execsnoop(8) 带上命令行参数 -t 后,会增加一列时间戳输出 :
# execsnoop -t
TIME(s) | PCOMM | PID | PPID | RET ARGS |
0.437 | run | 15524 | 4469 | 0 ./run |
0.438 | bash | 15524 | 4469 | 0 /bin/bash |
0.440 | svstat | 15526 | 15525 | 0 /command/svstat /service/httpd |
0.440 | perl | 15527 | 15525 | 0 /usr/bin/perl -e $l=<>;$l=~/(\d+) sec/;prin... |
0.442 | ps | 15529 | 15528 | 0 /bin/ps --ppid 1 -o pid,cmd,args |
[...] | ||||
0.487 | catalina.sh | 15524 | 4469 | 0 /apps/tomcat/bin/catalina.sh start |
0.488 | dirname | 15549 | 15524 | 0 /usr/bin/dirname /apps/tomcat/bin/catalina.sh |
1.459 | run | 15550 | 4469 | 0 ./run |
1.459 | bash | 15550 | 4469 | 0 /bin/bash |
1.462 | svstat | 15552 | 15551 | 0 /command/svstat /service/nflx-httpd |
1.462 | perl | 15553 | 15551 | 0 /usr/bin/perl -e $l=<>;$l=~/(\d+) sec/;prin... |
[...] |
上述输出进行了截断(用 [...] 表示),但时间戳那列信息还是显示了一个新的线索 :新进程的批量创建之间有 1 秒的间隔,而且这个模式不断重复。通过浏览输出可以发现,每秒会批量创建 30 个新的进程,然后停顿 1 秒,继续批量创建 30 个新的进程。
上述输出结果取自笔者在 Netflix 公司调查真实性能问题时使用 execsnoop(8) 的过程。这台服务器的作用是进行微基准测试,但问题是每次基准测试的结果差异很大,影响了 可信度。笔者在系统空闲时运行了 execsnoop(8),事实证明并非如我所想!每秒都有很 多进程被创建出来,这些进程对基准测试造成了干扰。最终,我们发现,因为有一个服 务的配置不正确,导致它每秒都会被拉起、失败,然后再被拉起,如此反复。当把这个 服务彻底禁止之后,就没有新的进程被创建出来了(同样可以使用 execsnoop(8) 进行验 证),基准测试的数值也稳定了下来。
execsnoop(8) 的输出可以用来辅助支撑一个性能分析方法论:业务负载画像(workloadcharacterization),本书中涉及的其他 BPF 工具的功能也都支持该方法论。业务负载画像 方法论其实很简单,就是给当前业务负载定性。理解了业务负载,很多时候就足够解决 问题了,这避免了深入分析延迟问题,也不需要进行下钻分析(drill-down analysis)。在本案例中,业务负载就是这些不断有进程的创建。
请你尝试在自己的系统上运行 execsnoop(8),并且让它运行 1 小时,看看是否有所发现?
execsnoop(8) 会在每个进程创建时打印信息,而其他一些 BPF 工具则可以高效地计 算摘要统计信息。另一个可以快速上手的工具是 biolatency(8),它可以绘制块设备 I/O(disk I/O)的延迟直方图。
下面是在一台生产环境中的数据库服务器上运行 biolatency(8) 的输出,该数据库对 延迟非常敏感,因为该服务的服务质量目标(service level agreement)只有几毫秒。
# biolatency -m
Tracing block device I/O... Hit Ctrl-C to end.
^C
msecs | : count | distribution | ||
0 -> | 1 | : 16335 | |****************************************| | |
2 -> | 3 | : 2272 | |***** | | |
4 -> | 7 | : 3603 | |******** | | |
8 -> | 15 | : 4328 | |********** | | |
16 -> | 31 | : 3379 | |******** | | |
32 -> | 63 | : 5815 | |************** | | |
64 -> | 127 | : 0 | | | | |
128 -> | 255 | : 0 | | | | |
256 -> | 511 | : 0 | | | | |
512 -> | 1023 | : 11 | | | | |
当 biolatency(8) 工具运行时会监测块 I/O 事件,它们的延迟信息通过 BPF 程序进行 计算和统计。当工具停止执行后(用户按下 Ctrl+C 组合键),摘要信息就被打印出来了。笔者使用了命令行参数 -m 来使得统计值以毫秒为单位输出。
上面的输出结果中有一些有趣的细节 :它呈现了双峰分布特征,并且显示了延迟离 群点的存在。第一峰(图中用 ASCII 字符展示)是 0 ~ 1 毫秒这个区间,在跟踪时有共 计 16 335 个 I/O 事件。这个速度相当快,可能是因为命中了存储设备上的缓存或者使用的是闪存设备。第二峰是 32 ~ 63 毫秒这个区间,这相对此类存储设备的预期性能慢了 不少,意味着可能有排队发生。可以用更多的 BPF 工具深入调查进行确认。最后,对于 512 ~ 1023 毫秒区间,有 11 个 I/O 事件。这些极大的延迟称为延迟离群点。现在我们知道了有这样的离群点存在,后面就可以使用其他 BPF 工具来进一步定位。对于数据库 团队,这是需要高优先级研究和解决的问题,因为一旦数据库阻塞在了这些 I/O 请求上, 数据库的延迟服务质量承诺就无法达到了。
震撼全球的 Gregg 大师新作
作为性能分析领域享誉全球的专家,Brendan Gregg 也是BPF项目的核心开发者,同时也是经典畅销著作《性能之巅:洞悉系统、企业与云计算》的作者。
没有人比他更适合来写这样一本利用 BPF 工具进行性能分析的书了!
书中有150多个可以立即使用的分析调试工具及其应用场景,并且提供开发自定义工具的分步指南。
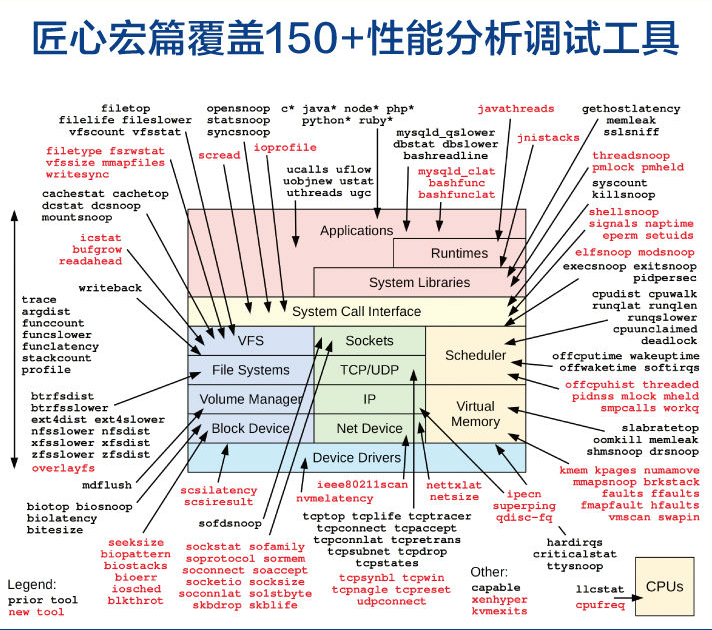
其中有数十个强大的工具是专门为本书而开发,并可下载使用!
了解更多BPF技术内幕,推荐阅读《BPF之巅:洞悉Linux系统和应用性能》一书。


【美】Brendan Gregg 著
孙宇聪 吕宏利 刘晓舟 译
Gregg大师新作,《性能之巅》再续新篇
性能优化的万用金典,150+分析调试工具深度剖析
本书作为全面介绍 BPF 技术的图书,从 BPF 技术的起源到未来发展方向都有涵盖,不仅全面介绍了 BPF 的编程模型,还完整介绍了两个主要的 BPF 前端编程框架 — BCC 和 bpftrace,更给出了一系列实现范例,生动展示了 BPF技术的实际能力和未来发展前景。
(扫码了解本书详情)
▼扫码进入本书交流群▼
与广大群友共同学习成长

如果喜欢本文 欢迎 在看丨留言丨分享至朋友圈 三连 热文推荐
▼点击阅读原文,获取本书详情~