
昨晚,我们的消费者居然停止消费kafka集群数据了
JAVA葵花宝典
共 4085字,需浏览 9分钟
·
2021-06-19 11:06
来源 | https://juejin.im/post/6874957625998606344
笔者所在的是一家金融科技公司,但公司内部并没有采用在金融支付领域更为流行的 RabbitMQ ,而是采用了设计之初就为日志处理而生的 Kafka ,所以我一直很好奇Kafka的高可用实现和保障。从Kafka部署后,系统内部使用的Kafka一直运行稳定,没有出现不可用的情况。

- Kafka 的多副本冗余设计 -
首先简单了解Kafka的几个概念:
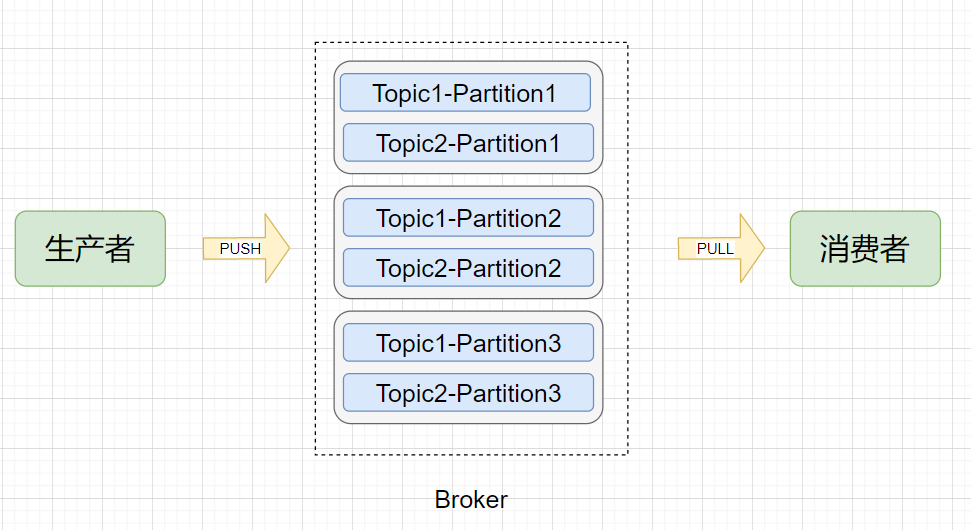
物理模型
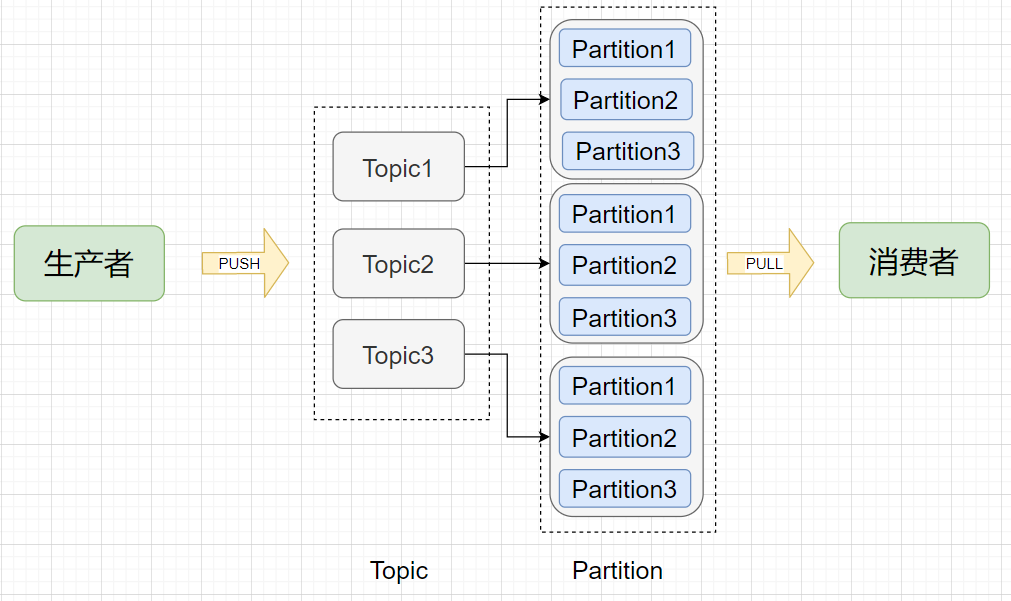
逻辑模型
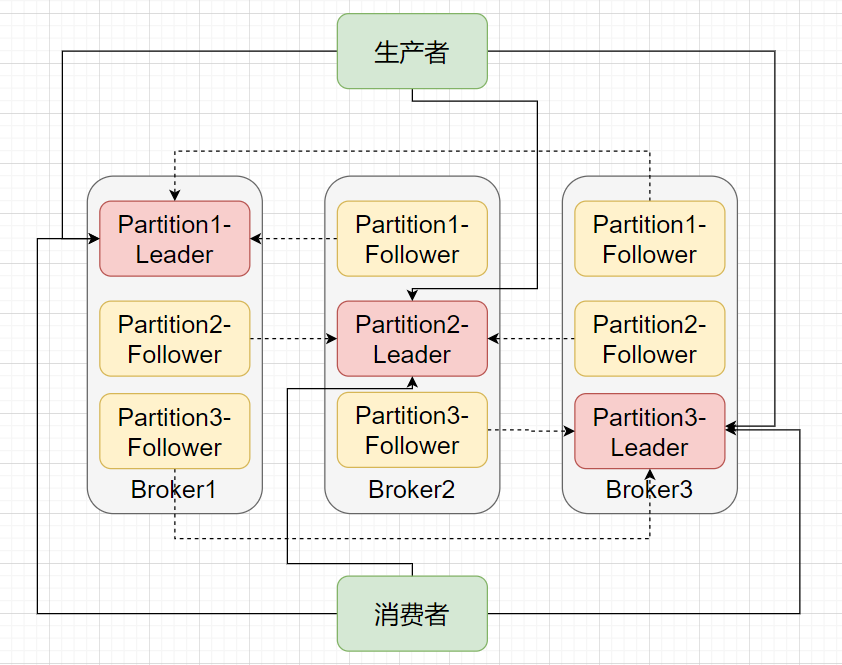
- Ack 参数决定了可靠程度 -
Asks这个参数是生产者客户端的重要配置,发送消息的时候就可设置这个参数。该参数有三个值可配置:0、1、All 。
- 解决问题 -
我在开发测试环境配置的 Broker 节点数是3, Topic 是副本数为3, Partition 数为6, Asks参数为1。
评论