
用Python 从 PDF 抽取 Excel 2.0
前些天向大家介绍了我开发的从PDF抽取表格小工具的使用方法(⬅️点击直达),有同学反馈说有一些问题:
一页PDF有多张表,只能抽取第一个 有些表格线条是透明的,无法抽取 一页一页处理太麻烦,不能一次性抽取
针对以上情况,我在原功能基础上进行了优化,本文依旧不涉及代码,具体实现过程我考虑在B站直播讲解。
这里就将优化部分的使用方法介绍一下
https://huggingface.co/spaces/beihai/PDF-Table-Extractor
单页PDF包含多个表格
这部分已经做了代码优化,前端也有一点点变化
选择具体页码后,自动弹出抽取完成,下载的Excel包含多个sheet页,对应多张表格。
表格线条是否透明
有些 PDF 中的表格线条是透明的,比如下图这种情况
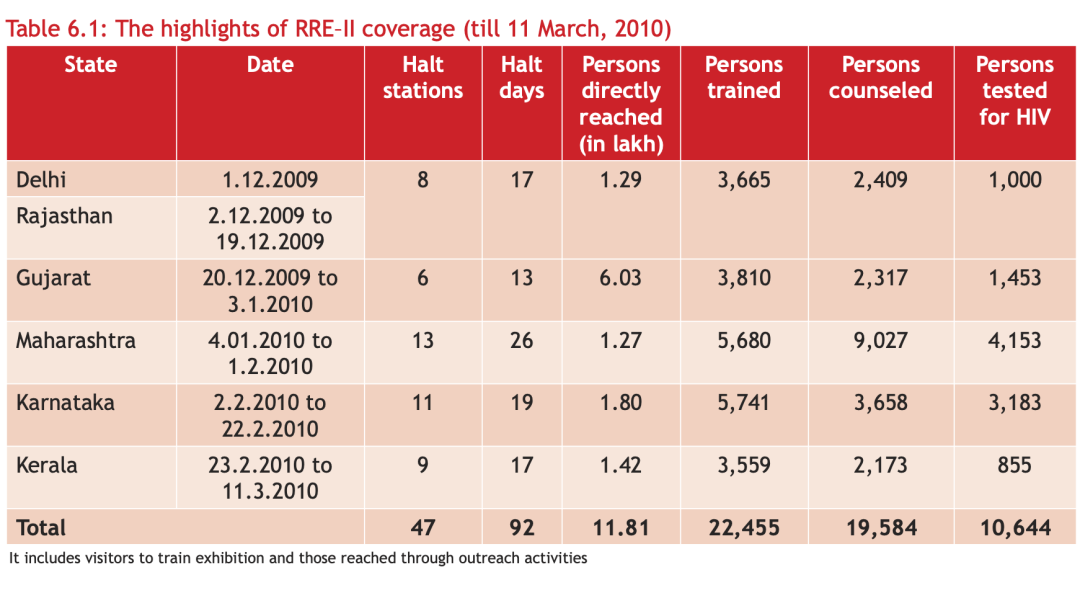
大家可以在线条是否透明下拉框选择 True

一键全页抽取
如果想要抽取一个PDF中所有的表格,在页码处填写 all 即可。
当然,如果页码较多,如此操作会很慢,需要耐心等待。
也可以填页码区间,比如1-3页就填1-3,第十页到最后一页,可以填10-end
 如果某些表格没有被提取,可以重新选择表格线条是否透明重跑一下。
如果某些表格没有被提取,可以重新选择表格线条是否透明重跑一下。
以上。欢迎三连。
另。
直播暂定周日晚,欢迎来波关注,届时会在动态发预告。
推荐阅读
评论