
如何用python来做假设检验, 求假设检验、置信区间、效应量
我们再在进行数据分析时,简单的数据分析不能深刻的反映一组数据得总体情况,倘若我们用统计学角度来分析数据则会解决一些平常解决不了得问题.
本编文章将会给大家讲解 假设检验、置信区间、效应量.
其中假设检验包括:t检验,w检验,卡方检验,f检验 ,我将会一一在这篇文章中介绍并用python代码来进行对应实操. (话不多说,整起!)
无论是什么检验第一步永远是 设立假设! 就像我们初中学的一样已知一个非负数来求解.我们可以先认为它等于0,经过推到发现我们做得想法是错误的,从而推出该数是大于0的!
我们通常第一步都会给出假设(零假设:H0 备择假设:H1)
假设检验的规则如下:H0: 零假设总是表述为研究没有改变,没有效果,不起作用等,这里就是不满足标准。(w检验和f检验另说!) H1: 则与零假设保持相反 接下里我会为大家举俩个列子:
例1:H0:在知乎上不同账号下浏览量没有显著区别 H1在知乎上不同账号下的流量量有显著区别 例2:H0:煤气排放量不满足国家排放标准 H1:煤气排放量满足国家排放标准
以下是建设检验具体步骤

好了话不多说了,我们开始实操!ps:一下所有检验均为a=0.05下:
卡方检验
卡方检验是假设检验中的一类方法,用于比较两个分类变量的关联性 但不能表示强弱,基本思想是比较理论频数与实际频数的吻合程度。俩个分类变量中其中一个必须是二分类不能都是多分类 例:男女对动物的喜爱程度,不同性别下投选候选班长(小米,小王,小李) 等 二分类:男女,不同性别 多分类:动物,候选班长
例题 下面是abi啤酒挑战赛的数据,我希望知道平台和菜系是否存在某种关系
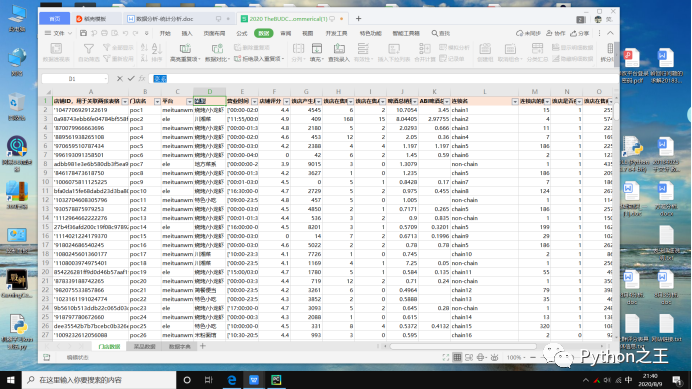
我们通过数据可以发现菜系和平台都是字符型,这里我们使用一个交叉表来整理数据计算频数:
import pandas as pd
import numpy as pd
data=pd.read_excel(r"") #读取数据文件
a=pd.crosstab(index=data["平台"],columns=data["菜系"],margins=True) #使用交叉表来处理数据
print(a)

我们可以发现不同平台下的各类菜系的频数如图所示,我想知道平台和菜系是否存在某种关系?接下来我们导入统计学库scipy : from scipy import stats Python提供的库能快速的解决很多问题,那么scipy也是如此,卡方分布在scipy中含有特定的api,我们只需写上函数即可知道结果。
代码如下:
from scipy import stats #导入统计学库
b=stats.chi2_contingency(a)[0:3] #该函数返回4个参数,但我们只要前3个! 分别是t,p,自由度
 它返回的结果是元组格式(a:t值,b:p值,c:自由度) 当p值小于0.05,则我们拒绝原假设 当p值大于0.05,则我们接受原假设 如图所示我们可以看到 p值为1.400*10的负33次方<0.05,则我们拒绝原假设,接受备择假设 既平台跟菜系有关系(但不知道是什么关系)
它返回的结果是元组格式(a:t值,b:p值,c:自由度) 当p值小于0.05,则我们拒绝原假设 当p值大于0.05,则我们接受原假设 如图所示我们可以看到 p值为1.400*10的负33次方<0.05,则我们拒绝原假设,接受备择假设 既平台跟菜系有关系(但不知道是什么关系)
要比较两类关系的强弱我们需要用到t检验和其他检验,接下来我们来讲t检验从而引出w检验和f检验
T检验
在说t检验之前,我们需要进一步完善假设检验的概念,
假设检验主要分为:1、单尾检验 2、双尾检验
这俩种检验存在一下差异:一、检验目的不同:双尾检验(也就是双侧检验)是要检验样本平均数和总体平均数,或样本成数有没有显著差异。而单尾检验(也就是单侧检验)目的是检验样本所取自的总体参数值是否大于或小于某个特定值
二、用法不同1、研究目的是想判断两个数据的均值是否不同, 需要用双尾检验。2、研究目的是仅仅想知道一个数据的均值是不是高于(或低于)另一个数据, 则可以采用单尾检验。实际操作中要根据研究的目的和假设来选择单尾检验还是双尾检验,如果假设中有一参数和另一参数方向性的比较,比如"大于"、“好于”、"差于"等,一般选择单尾检验。如果只是检验两参数之间是否有差异,就选择双尾检验。1、如果问题是:中学生中,男女生的身高是否存在性别差异, 因为实际的差异可能是男生平均身高比女生高,也可能是男生平均比女生矮。这两种情况都属于存在性别差异。需要用双尾检验。2、如果问题为:中学生中,男生的身高是否比女生高,这个时候需要采用单尾检验。

我们先说单侧检验
一、单样本检验案例:汽车引擎
“超级引擎”是一家专门生产汽车引擎的公司,根据政府发布的新排放要求,引擎排放平均值要低于20ppm。某公司制造出10台引擎供测试使用,每一台的排放水平如下:15.6 16.2 22.5 20.5 16.4 19.4 16.6 17.9 12.7 13.9 Q:怎么知道,该公司生产的引擎是否符合政府规定呢?
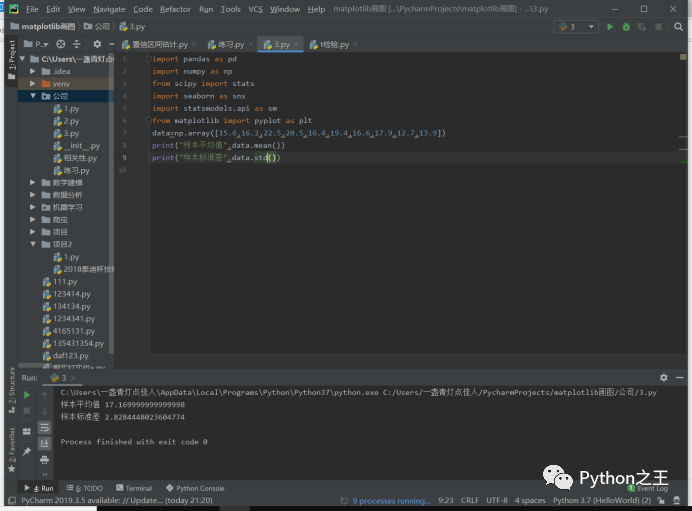 我们建立一个array的数组将数据存入,并记入tm的平均数和 标准差:(方差的1/2方) 平均数:可以反映这组数据平均情况 标准差:可以反映这组数据的离散情况(方差)越小越稳定
我们建立一个array的数组将数据存入,并记入tm的平均数和 标准差:(方差的1/2方) 平均数:可以反映这组数据平均情况 标准差:可以反映这组数据的离散情况(方差)越小越稳定
接下来回的我们的问题 设立零假设和备选假设
零假设H0:平均值u>=20,也就是该公司引擎排放不满足标准;备选假设H1:平均值u<20,也就是公司引擎排放满足标准。
t检验需要一个前提:样本必须是正态分布或近似正态分布,所以我们需要检验该样本是否满足正态分布 正态分布检验:W检验
Stats.shapiro() w检验
H0:属于正态分布 H1:不属于正态分布
from scipy import stats #导入统计学模块库
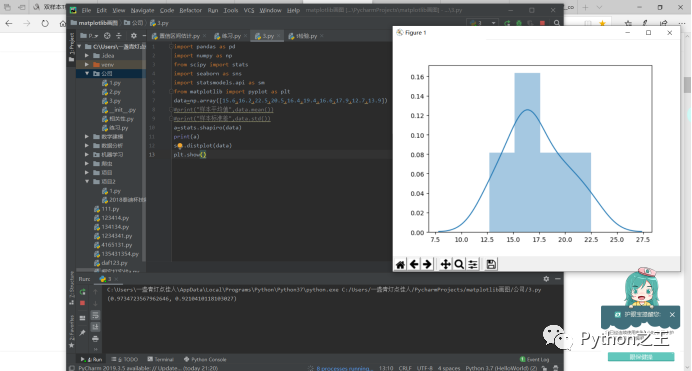
stats.shapiro(data) #将参数data传入其中即可得到结果 1、统计数 2、p值
#(0.973,0.921) p=0.921>0.05 接受原假设则它属于正态分布
我们可以发现该组数据符合正态分布,同时我们也可以用seaborn来进行绘图观看!
接下来我们导入scipy中的api来进行单样本t检验!
from scipy import stats
stats.ttest_1samp(a,b) #a : 数据集(data) b:满足条件(20)
我们得到如下答案:

因为是单尾检验,但是导入的是双尾api这里就要进行运算:双尾=单尾*2,我们用的到的 p值/2 得到 0.00745 即p=0.00745<0.05 则接受备择假设:我们达到了政府排放的需求
接下来我们用置信区间来表达我们的平均值范围:
置信区间上限a=总体平均值- |t| 标准误差 置信区间下限b=总体平均值+|t| 标准误差**
我们需要计算 标准误差和t值
t值计算
自由度=n-1 在0.95下在t值表查询具体的t值** df=10-1=9
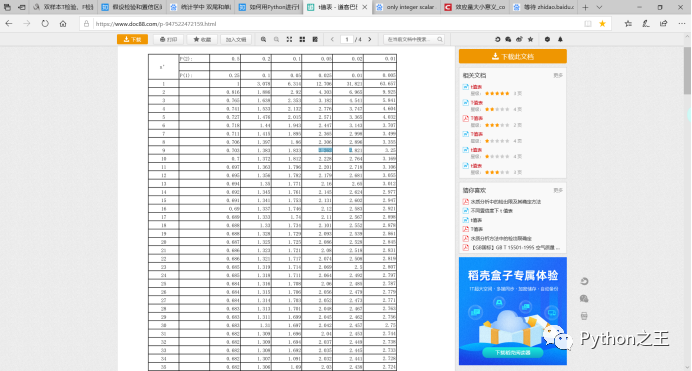
因为样本量为10则自由度=n-1=9,(1-95%=0.05)既在9和0.05那列寻找t值:2.262
标准误差:
from scipy import stats
stats.sem(data) # data 为数据集,该函数只能计算一个数据集下的标准误差!
我们用这段代码来进行分析: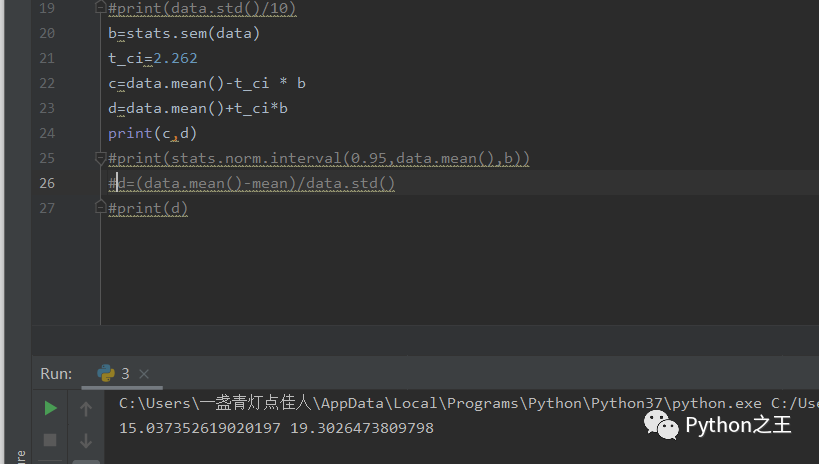
通过得到t值和标准差b来进行公式计算得到置信区间的下界和上节,如图所示:可以得到平均值最大、最小跳动在这个范围里
我们拒绝了原假设则说明我们的统计有差异,差异有多大呢?此处的差异就是效应量
效应量
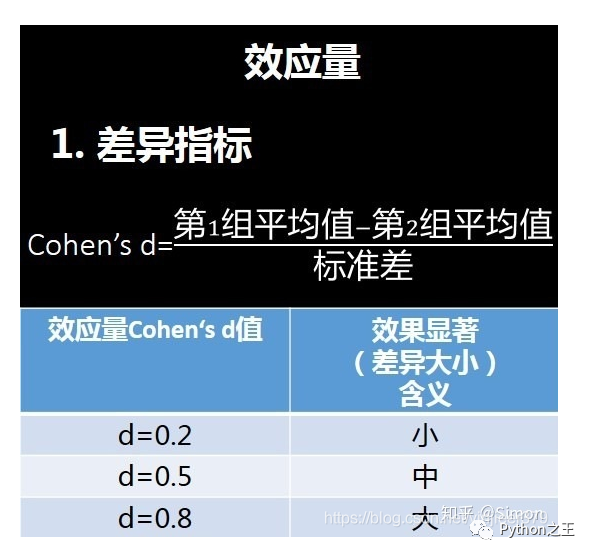
效应量:当假设检验具有统计显著的结论时,需要进一步研究是否具有实际有意义,即实验结果是否“效果显著”,衡量效果显著用Cohen’s d指标。#它表示:样本均值1和样本均值2差距了几个标准差,差距的大小衡量标准是:0.2以内为小;0.5以内为中;0.8以内为大。
接下里我们用代码来计算效应量:
d=(data.mean()-20)/data.std()
# d=-0.94 即我们与原假设差0.94个标准差!
从而给出分析报告

双样本t检验
双样本t检验用途很广:不同账号下不同浏览量是否有关系、男女消费水平是否有明显显著水平差异 等…
双样本t检验跟单样本不同,他需要满足一下几个标准 两样本均来自于正态总体 两样本相互独立 满足方差齐性,方差齐次性指的是样本的方差在一个数量级水平上(通过方差齐性检验:F检验)
因为两个样本是需要相互独立的,所以这里就需要使用f检验来观看是否满足方差齐性,不满足也是可以的,python的api已经考虑过这个问题了,你只需要只能满不满足在输入参数即可
接下来我会用下面的例子来进行一一讲述:
例:在知乎不同网名下相同文章的浏览量是否有显著差异
H0:没有差异 H1:有差异
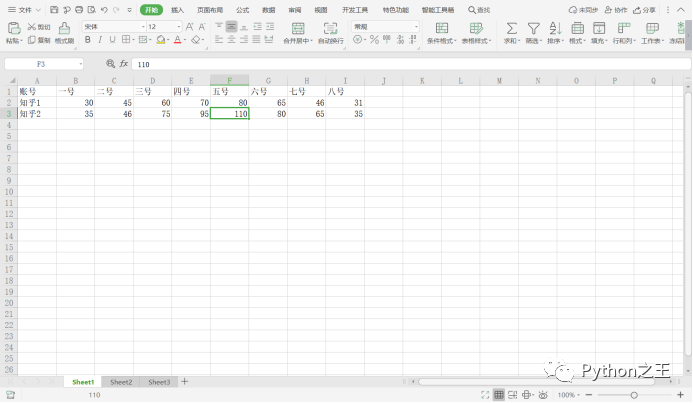 这是我这是我自己建立的一张表,来分析知乎一和知乎二名字和浏览量是否有显著性差异
这是我这是我自己建立的一张表,来分析知乎一和知乎二名字和浏览量是否有显著性差异
首先我们第一步要分析是否满足正态分布:w检验


我们导入对应的api 得到p值分别分 0.62,0.59 >0.05既为正太分布 满足正态分布
F检验
H0:俩样本具有齐次性 H1:俩样本不具有齐次性
from scipy import stats
leneneTestRes=stats.levene(data.iloc[0,1:].values,data.iloc[1,1:].values)
print(leneneTestRes)
#
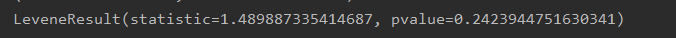 p=0.242>0.05,则接受原假设,俩样本方差具有齐次性
p=0.242>0.05,则接受原假设,俩样本方差具有齐次性
接下来使用双样本t检验:
 P=0.244>0.05,接受原假设,不同名字下浏览量没有差异
P=0.244>0.05,接受原假设,不同名字下浏览量没有差异
没有差异下,就可以不用看效应量了.
完整代码如下: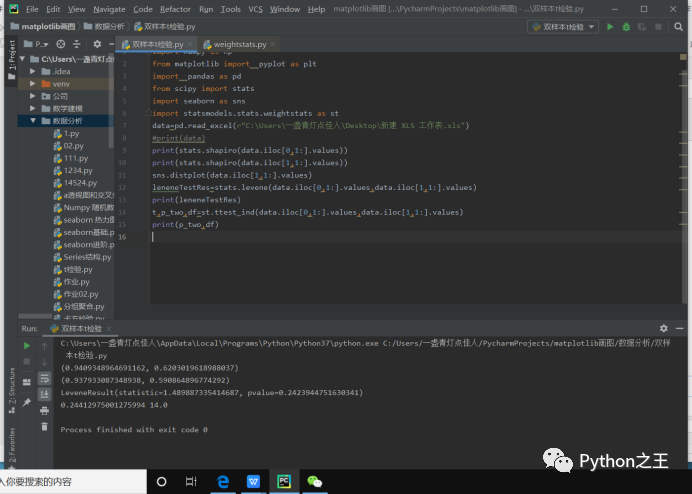


Python“宝藏级”公众号【Python之王】专注于Python领域,会爬虫,数分,C++,tensorflow和Pytorch等等。
近 2年共原创 100+ 篇技术文章。创作的精品文章系列有:
日常收集整理了一批不错的 Python 学习资料,有需要的小伙可以自行免费领取。
获取方式如下:公众号回复资料。领取Python等系列笔记,项目,书籍,直接套上模板就可以用了。资料包含算法、python、算法小抄、力扣刷题手册和 C++ 等学习资料!