
Go项目推荐之即时通讯服务器 IM
点击上方蓝色“Go语言中文网”关注我们,领全套Go资料,每天学习 Go 语言
简要介绍
im是一个即时通讯服务器,代码全部使用golang完成。主要功能
1.支持tcp,websocket接入
2.离线消息同步
3.单用户多设备同时在线
4.单聊,群聊,以及超大群聊天场景
5.支持服务水平扩展
gim和im有什么区别?gim可以作为一个im中台提供给业务方使用,而im可以作为以业务服务器的一个组件, 为业务服务器提供im的能力,业务服务器的user服务只需要实现user.int.proto协议中定义的GRPC接口,为im服务 提供基本的用户功能即可,其实以我目前的认知,我更推荐这种方式,这种模式相比于gim,我认为最大好处在于 以下两点:
1.im不需要考虑多个app的场景,相比gim,业务复杂度降低了一个维度
2.各个业务服务可以互不影响,可以做到风险隔离
使用技术:
数据库:MySQL+Redis
通讯框架:GRPC
长连接通讯协议:Protocol Buffers
日志框架:Zap
ORM框架:GORM
安装部署
1.首先安装MySQL,Redis
2.创建数据库im,执行sql/create_table.sql,完成初始化表的创建(数据库包含提供测试的一些初始数据)
3.修改config下配置文件,使之和你本地配置一致
4.分别切换到cmd的tcp_conn,ws_conn,logic,user目录下,执行go run main.go,启动TCP连接层服务器, WebSocket连接层服务器,逻辑层服务器,用户服务器
(注意:tcp_conn只能在linux下启动,如果想在其他平台下启动,请安装docker,执行run.sh)
项目目录简介
项目结构遵循 https://github.com/golang-standards/project-layout
cmd: 服务启动入口
config: 服务配置
internal: 每个服务私有代码
pkg: 服务共有代码
sql: 项目sql文件
test: 长连接测试脚本服务简介
1.tcp_conn
维持与客户端的TCP长连接,心跳,以及TCP拆包粘包,消息编解码
2.ws_conn
维持与客户端的WebSocket长连接,心跳,消息编解码
3.logic
设备信息,好友信息,群组信息管理,消息转发逻辑
4.user
一个简单的用户服务,可以根据自己的业务需求,进行扩展
网络模型
TCP的网络层使用linux的epoll实现,相比golang原生,能减少goroutine使用,从而节省系统资源占用
单用户多设备支持,离线消息同步
每个用户都会维护一个自增的序列号,当用户A给用户B发送消息时,首先会获取A的最大序列号,设置为这条消息的seq,持久化到用户A的消息列表, 再通过长连接下发到用户A账号登录的所有设备,再获取用户B的最大序列号,设置为这条消息的seq,持久化到用户B的消息列表,再通过长连接下发 到用户B账号登录的所有设备。
假如用户的某个设备不在线,在设备长连接登录时,用本地收到消息的最大序列号,到服务器做消息同步,这样就可以保证离线消息不丢失。
读扩散和写扩散
首先解释一下,什么是读扩散,什么是写扩散
读扩散
简介:群组成员发送消息时,先建立一个会话,都将这个消息写入这个会话中,同步离线消息时,需要同步这个会话的未同步消息
优点:每个消息只需要写入数据库一次就行,减少数据库访问次数,节省数据库空间
缺点:一个用户有n个群组,客户端每次同步消息时,要上传n个序列号,服务器要对这n个群组分别做消息同步
写扩散
简介:在群组中,每个用户维持一个自己的消息列表,当群组中有人发送消息时,给群组的每个用户的消息列表插入一条消息即可
优点:每个用户只需要维护一个序列号和消息列表
缺点:一个群组有多少人,就要插入多少条消息,当群组成员很多时,DB的压力会增大
消息转发逻辑选型以及特点
普通群组:
采用写扩散,群组成员信息持久化到数据库保存。支持消息离线同步。
超大群组:
采用读扩散,群组成员信息保存到redis,不支持离线消息同步。
核心流程时序图
长连接登录
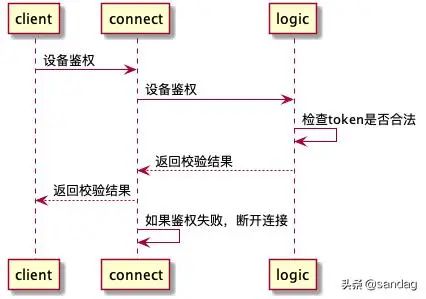
离线消息同步
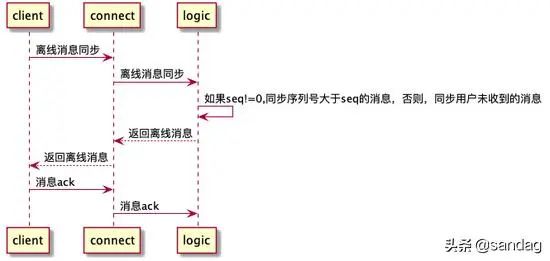
心跳
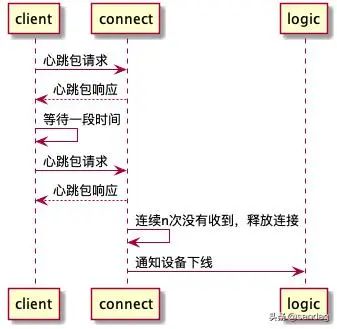
消息单发
c1.d1和c1.d2分别表示c1用户的两个设备d1和d2,c2.d3和c2.d4同理
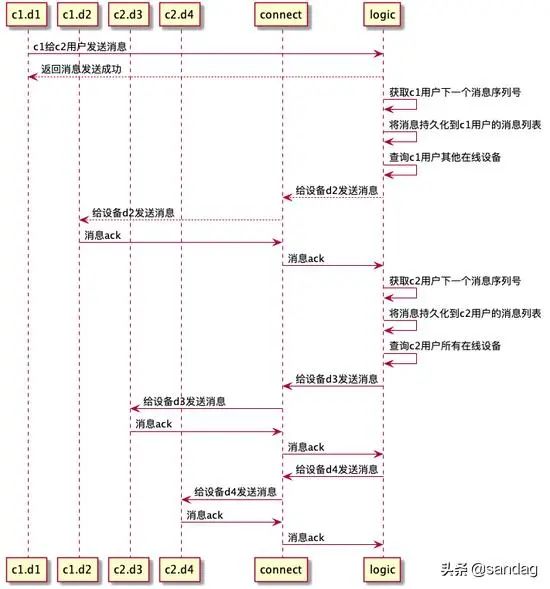
小群消息群发
c1,c2.c3表示一个群组中的三个用户

大群消息群发
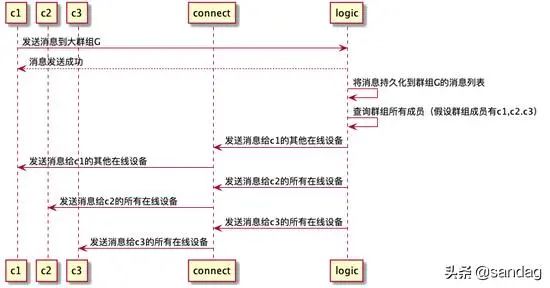
错误处理,链路追踪,日志打印
系统中的错误一般可以归类为两种,一种是业务定义的错误,一种就是未知的错误,在业务正式上线的时候,业务定义的错误的属于正常业务逻辑,不需要打印出来, 但是未知的错误,我们就需要打印出来,我们不仅要知道是什么错误,还要知道错误的调用堆栈,所以这里我对GRPC的错误进行了一些封装,使之包含调用堆栈。
func WrapError(err error) error {if err == nil {return nil}s := &spb.Status{Code: int32(codes.Unknown),Message: err.Error(),Details: []*any.Any{{TypeUrl: TypeUrlStack,Value: util.Str2bytes(stack()),},},}return status.FromProto(s).Err()}// Stack 获取堆栈信息func stack() string {var pc = make([]uintptr, 20)n := runtime.Callers(3, pc)var build strings.Builderfor i := 0; i < n; i++ {f := runtime.FuncForPC(pc[i] - 1)file, line := f.FileLine(pc[i] - 1)n := strings.Index(file, name)if n != -1 {s := fmt.Sprintf(" %s:%d \n", file[n:], line)build.WriteString(s)}}return build.String()}
这样,不仅可以拿到错误的堆栈,错误的堆栈也可以跨RPC传输,但是,但是这样你只能拿到当前服务的堆栈,却不能拿到调用方的堆栈,就比如说,A服务调用 B服务,当B服务发生错误时,在A服务通过日志打印错误的时候,我们只打印了B服务的调用堆栈,怎样可以把A服务的堆栈打印出来。我们在A服务调用的地方也获取 一次堆栈。
func WrapRPCError(err error) error {if err == nil {return nil}e, _ := status.FromError(err)s := &spb.Status{Code: int32(e.Code()),Message: e.Message(),Details: []*any.Any{{TypeUrl: TypeUrlStack,Value: util.Str2bytes(GetErrorStack(e) + " --grpc-- \n" + stack()),},},}return status.FromProto(s).Err()}func interceptor(ctx context.Context, method string, req, reply interface{}, cc *grpc.ClientConn, invoker grpc.UnaryInvoker, opts ...grpc.CallOption) error {err := invoker(ctx, method, req, reply, cc, opts...)return gerrors.WrapRPCError(err)}var LogicIntClient pb.LogicIntClientfunc InitLogicIntClient(addr string) {conn, err := grpc.DialContext(context.TODO(), addr, grpc.WithInsecure(), grpc.WithUnaryInterceptor(interceptor))if err != nil {logger.Sugar.Error(err)panic(err)}LogicIntClient = pb.NewLogicIntClient(conn)}
像这样,就可以获取完整一次调用堆栈。错误打印也没有必要在函数返回错误的时候,每次都去打印。因为错误已经包含了堆栈信息
// 错误的方式if err != nil {logger.Sugar.Error(err)return err}// 正确的方式if err != nil {return err}
然后,我们在上层统一打印就可以
func startServer() {extListen, err := net.Listen("tcp", conf.LogicConf.ClientRPCExtListenAddr)if err != nil {panic(err)}extServer := grpc.NewServer(grpc.UnaryInterceptor(LogicClientExtInterceptor))pb.RegisterLogicClientExtServer(extServer, &LogicClientExtServer{})err = extServer.Serve(extListen)if err != nil {panic(err)}}func LogicClientExtInterceptor(ctx context.Context, req interface{}, info *grpc.UnaryServerInfo, handler grpc.UnaryHandler) (resp interface{}, err error) {defer func() {logPanic("logic_client_ext_interceptor", ctx, req, info, &err)}()resp, err = handler(ctx, req)logger.Logger.Debug("logic_client_ext_interceptor", zap.Any("info", info), zap.Any("ctx", ctx), zap.Any("req", req),zap.Any("resp", resp), zap.Error(err))s, _ := status.FromError(err)if s.Code() != 0 && s.Code() < 1000 {md, _ := metadata.FromIncomingContext(ctx)logger.Logger.Error("logic_client_ext_interceptor", zap.String("method", info.FullMethod), zap.Any("md", md), zap.Any("req", req),zap.Any("resp", resp), zap.Error(err), zap.String("stack", gerrors.GetErrorStack(s)))}return}
这样做的前提就是,在业务代码中透传context,golang不像其他语言,可以在线程本地保存变量,像Java的ThreadLocal,所以只能通过函数参数的形式进行传递,im中,service层函数的第一个参数 都是context,但是dao层和cache层就不需要了,不然,显得代码臃肿。
最后可以在客户端的每次请求添加一个随机的request_id,这样客户端到服务的每次请求都可以串起来了。
func getCtx() context.Context {token, _ := util.GetToken(1, 2, 3, time.Now().Add(1*time.Hour).Unix(), util.PublicKey)return metadata.NewOutgoingContext(context.TODO(), metadata.Pairs("app_id", "1","user_id", "2","device_id", "3","token", token,"request_id", strconv.FormatInt(time.Now().UnixNano(), 10)))}
github
https://github.com/alberliu/im
来源:
https://www.toutiao.com/a6853605017463554572/
推荐阅读
站长 polarisxu
自己的原创文章
不限于 Go 技术
职场和创业经验
Go语言中文网
每天为你
分享 Go 知识
Go爱好者值得关注