
ZooKeeper的选举机制和同步机制超详细讲解,面试经常问到!

前言
zookeeper相信大家都不陌生,很多分布式中间件都利用zk来提供分布式一致性协调的特性。dubbo官方推荐使用zk作为注册中心,zk也是hadoop和Hbase的重要组件。其他知名的开源中间件中也都出现了zk的身影。
有很多童鞋认识zk很久了,知道其基本理念,知道如何使用。但当面试时问到集群zk之间的选举和数据同步机制时,就陷入了盲区。
其实很多的分布式中间件的选举和同步,都和zk有异曲同工之妙。这篇文章我就来重点聊下关于zk集群之间的选举和同步机制。
ZK集群的部署
首先我们来看下半数运行机制:
集群至少需要三台服务器,且官方文档强烈建议使用奇数个服务器,因为zookeeper是通过判断大多数节点的的存活来判断整个服务集群是否可用的,比如3个节点,它的一半是1.5,向上取整就是2。挂掉了2个就是表示整个集群挂掉。而用偶数4个的话,挂掉2个也表示不是大部分存活,因此也会挂掉。所以用4台服务器的话 ,从使用资源上来说,并不划算。
配置语法:
server.<节点ID>=:<数据同步端口>:<选举端口>
节点ID:为1到125之间的数字,写到对应服务节点的{dataDir}/myid文件中。 IP地址:节点的远程IP地址,可以相同,生产环境建议用不同的机器,否则无法达到容错的目的。 数据同步端口:主从同步时数据复制端口。 选举端口:主从节点选举端口。
假设现在有3个zookeeper节点,我们要为其编写config配置,也要编写3份,分别放在不同的服务器上,其配置如下:
initLimit=10
syncLimit=5
dataDir=/data/zk_data
clientPort=2181
# 集群配置
server.1=192.168.1.1:2888:3888
server.2=192.168.1.2:2888:3888
server.3=192.168.1.3:2888:3888
其中dataDir参数指定的是一个目录,用来存放zk的数据,里面有个文件myid,3台机器上myid文件里面分别存放1,2,3。对应各自节点ID。
配置好3个配置文件后,分别启动,这样我们一个3个节点的集群zookeeper就搭建好了。
./bin/zkServer.sh start conf/zoo.cfg
ZK集群中的角色
zookeeper集群中公共有三种角色,分别是leader,follower,observer。
| 角色 | 描述 |
|---|---|
| leader | 主节点,又名领导者。用于写入数据,通过选举产生,如果宕机将会选举新的主节点。 |
| follower | 子节点,又名追随者。用于实现数据的读取。同时他也是主节点的备选节点,并拥有投票权。 |
| observer | 次级子节点,又名观察者。用于读取数据,与follower区别在于没有投票权,不能被选为主节点。并且在计算集群可用状态时不会将observer计算入内。 |
关于observer的配置:
只要在集群配置中加上observer后缀即可,示例如下:
server.3=127.0.0.1:2883:3883:observer
其中leader只有一个,剩下的都是follower和observer,但是我们一般生产上不会配置observer,因为observer并没有选举权,可以理解为observer是一个临时工,不是正式员工,没法获得晋升。除此之外,它和follower的功能是一样的。
什么时候需要用到observer呢,因为zk一般读的请求会大于写。当整个集群压力过大时,我们可以增加几个临时工observer来获得性能的提升。在不需要的时候的时候,可以随时撤掉observer。
zk进行连接时,一般我们都会把zk所有的节点都配置上去,用逗号分隔。其实连接集群中的任意一个或者多个都是可以的。只是如果只连一个节点,当这个节点宕机的时候,我们就断开了连接。所以还是推荐配置多个节点进行连接。
如何查看ZK集群中的角色
我们可以利用以下命令来查看zk集群中的角色
./bin/zkServer.sh status conf/zoo.cfg
我在自己机器上搭建了3个节点的伪集群(共用一台机器),配置文件分别命名为zoo1.cfg,zoo2.cfg,zoo3.cfg。使用以上命令查看的结果为:
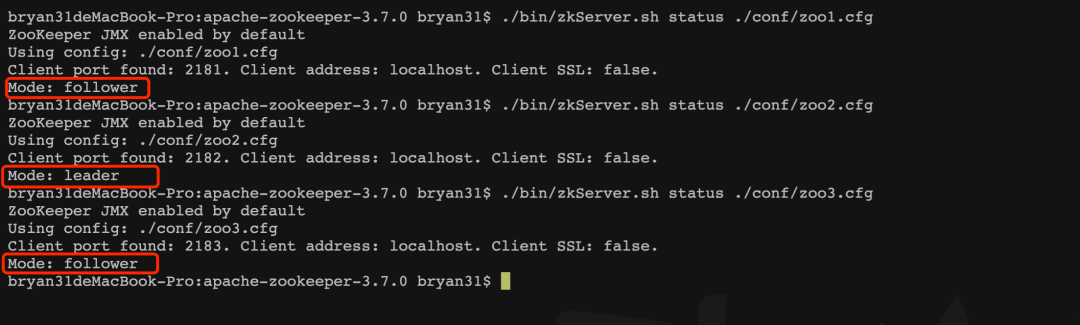
可以看到,其中节点2为leader,其他的为follower。但是如果你按照zoo1.cfg,zoo2.cfg,zoo3.cfg的顺序启动,无论你启动多少遍,节点2总是leader,而这时如果把节点2关掉,进行查看角色,发现节点3成了leader。
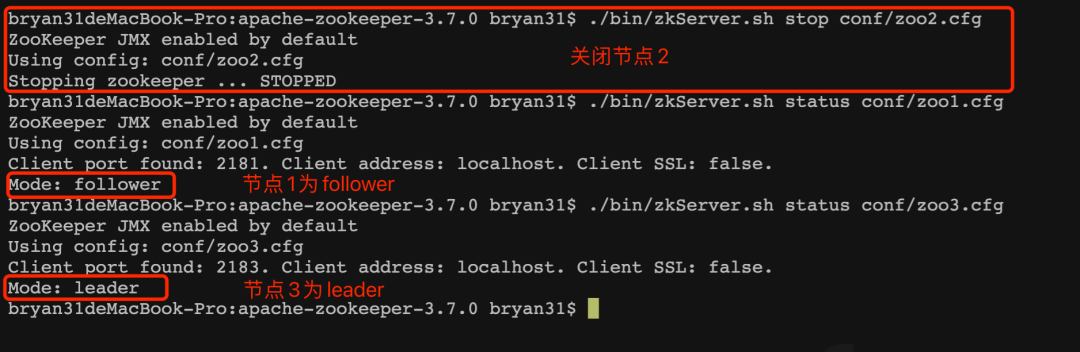
以上这些现象都和zookeeper的选举机制有关
ZK集群的选举机制
我们就拿3个节点的zk作一个简单选举的说明
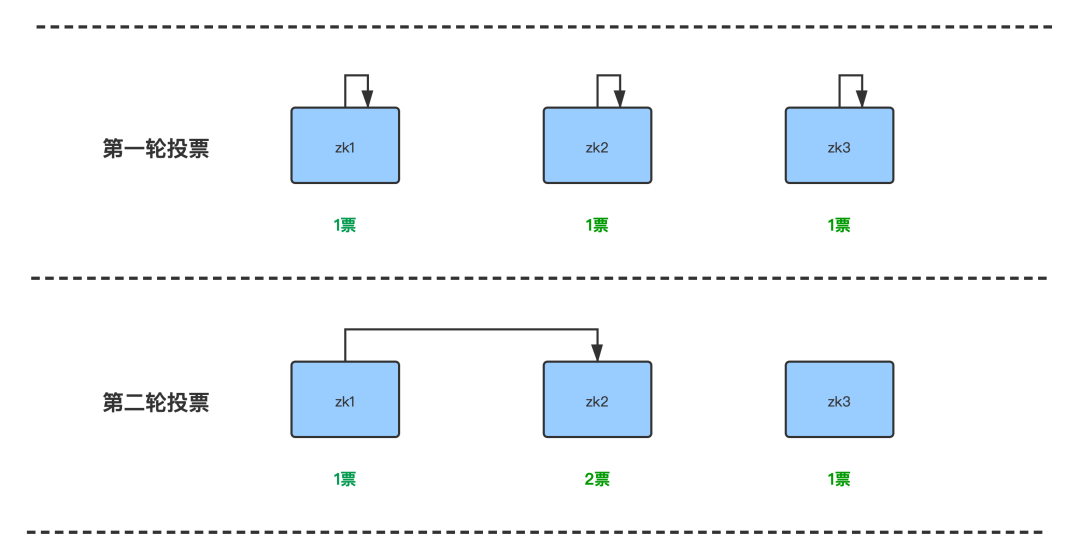
zk会进行多轮的投票,直到某一个节点的票数大于或等于半数以上,在3个节点中,总共会进行2轮的投票:
第一轮,每个节点启动时投票给自己,那这样zk1,zk2,zk3各有一票。 第二轮,每个节点投票给大于自己myid,那这样zk2启动时又获得一票。加上自己给自己投的那一票。总共有2票。2票大于了当前节点总数的半数,所以投票终止。zk2当选leader。
有的童鞋会问,zk3呢,因为zk2已经当选了,投票终止了。所以zk2也不会投票给zk3了。
当然这是一个比较简单版的选举,其实真正的选举还要比较zxid,这个后面会讲到。
zk选举什么时候会被触发呢?一是启动时会被触发,二是leader宕机时会被触发。上面的例子中,如果节点2宕机,根据规则,那获得leader的就应该是zk3了。
ZK集群的数据同步机制
zookeeper的数据同步是为了保证每个节点的数据一致性,大致分为2个流程,一个是正常的客户端数据提交流程,二是集群中某个节点宕机后数据恢复流程。
正常客户端数据提交流程
客户端写入数据提交流程大致为:leader接受到客户端的写请求,然后同步给各个子节点:
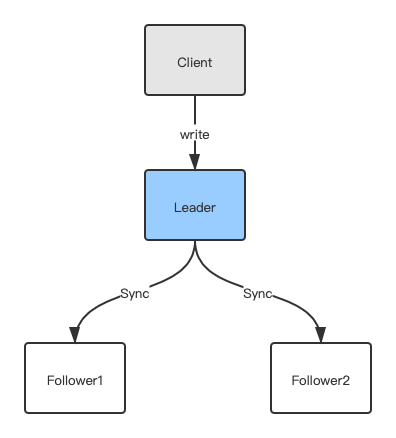
但是有童鞋就产生疑惑了,客户端一般连接的是所有节点,客户端并不知道哪个是leader呀。
的确,客户端会和所有的节点建立链接,并且发起写入请求是挨个遍历节点进行的,比如第一次是节点1,第二次是节点2。以此类推。
如果客户端正好链接的节点的角色是leader,那就按照上面的流程走。那如果链接的节点不是leader,是follower呢,则有以下流程:
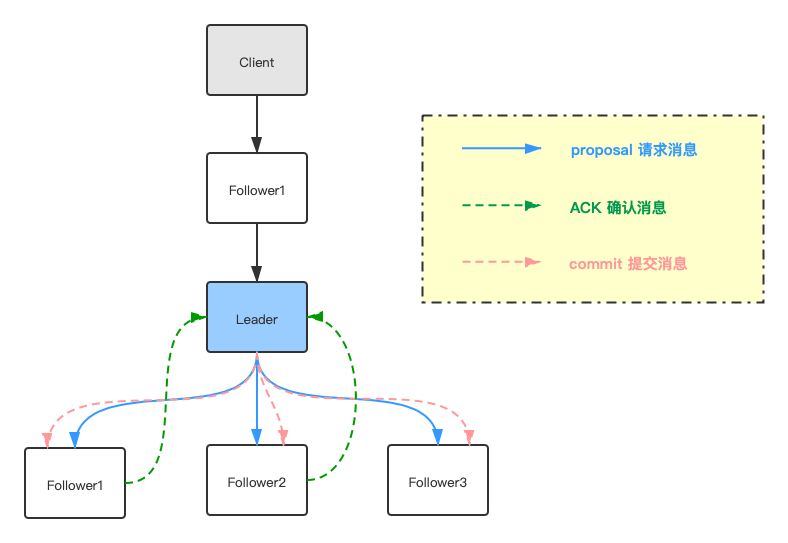
如果Client选择链接的节点是Follower的话,这个Follower会把请求转给当前Leader,然后Leader会走蓝色的线把请求广播给所有的Follower,每个节点同步完数据后会走绿色的线告诉Leader数据已经同步完成(但是还未提交),当Leader收到半数以上的节点ACK确认消息后,那么Leader就认为这个数据可以提交了,会广播给所有的Follower节点,所有的节点就可以提交数据。整个同步工作就结束了。
那我们再来说说节点宕机后的数据同步流程
当zookeeper集群中的Leader宕机后,会触发新的选举,选举期间,整个集群是没法对外提供服务的。直到选出新的Leader之后,才能重新提供服务。
我们重新回到3个节点的例子,zk1,zk2,zk3,其中z2为Leader,z1,z3为Follower,假设zk2宕机后,触发了重新选举,按照选举规则,z3当选Leader。这时整个集群只整下z1和z3,如果这时整个集群又创建了一个节点数据,接着z2重启。这时z2的数据肯定比z1和z3要旧,那这时该如何同步数据呢。
zookeeper是通过ZXID事务ID来确认的,ZXID是一个长度为64位的数字,其中低32位是按照数字来递增,任何数据的变更都会导致低32位数字简单加1。高32位是leader周期编号,每当选举出一个新的Leader时,新的Leader就从本地事务日志中取出ZXID,然后解析出高32位的周期编号,进行加1,再将低32位的全部设置为0。这样就保证了每次选举新的Leader后,保证了ZXID的唯一性而且是保证递增的。
查看某个数据节点的ZXID的命令为:
先进入zk client命令行
./bin/zkCli.sh -server 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183
stat加上数据节点名称
stat /test
执行结果为:
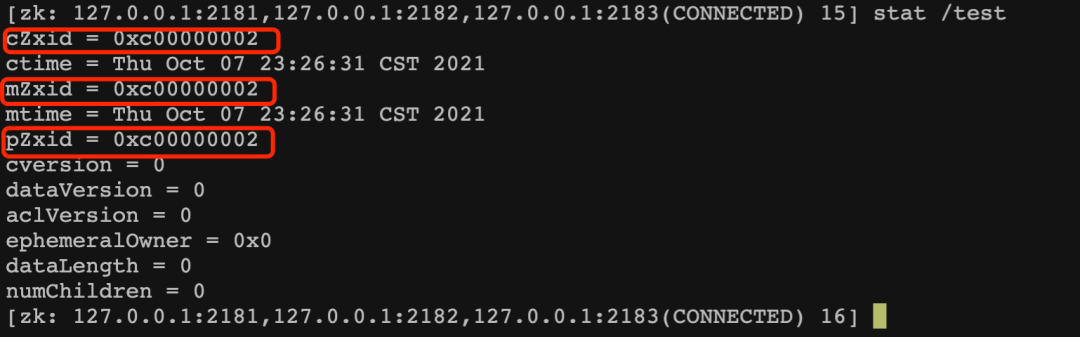
可以看到,有3个ZXID,这3个ZXID各自代表:
cZxid:该节点创建时的事务ID
mZxid:该节点最近一次更新时的事务ID
pZxid:该节点的子节点的最新一次创建/更新/删除的事务ID
查看节点最新ZXID的命令为:
echo stat|nc 127.0.0.1 2181
这个命令需提前在cfg文件后追加:4lw.commands.whitelist=*,然后重启
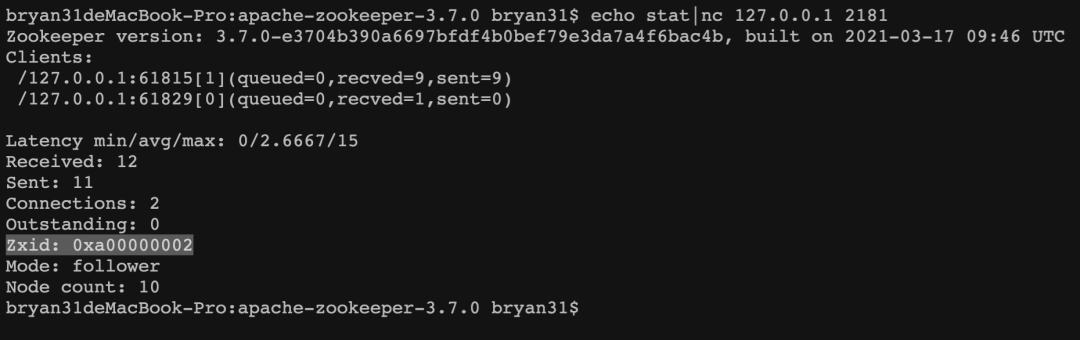
这里的ZXID就是当前节点最后一次事务的ID。
如果整个集群数据为一致的,那么所有节点的ZXID应该一样。所以zookeeper就通过这个有序的ZXID来确保各个节点之间的数据的一致性,带着之前的问题,如果Leader宕机之后,再重启后,会去和目前的Leader去比较最新的ZXID,如果节点的ZXID比最新Leader里的ZXID要小,那么就会去同步数据。
再看ZK中的选举
我们带着ZXID的概念再来看ZK中的选举机制。
假设还是有一个3个节点的集群,zk2为Leader,这时候如果zk2挂了。zk3当选Leader,zk1为Follower。这时候如果更新集群中的一个数据。然后把zk1和zk3都关闭。然后挨个再重启zk1,zk2,zk3。这时候启动后,zk2还能当选为Leader吗?
其实这个问题,换句话说就是:在挨个启动zk节点的时候,zk1和zk3的数据为最新,而zk2的数据不是最新的,按照之前的选举规则的话,zk2是否能顺利当选Leader?
答案为否,最后当选的为zk1。
这是为什么呢。
因为zk2的最新ZXID已经不是最新了,zk的选举过程会优先考虑ZXID大的节点。这时ZXID最大的有zk1和zk3,选举只会在这2个节点中产生,根据之前说的选举规则。在第一轮投票的时候,zk1只要获得1票,就能达到半数了,就能顺利当选为Leader了。
最后
其实zk的选举和同步并不复杂,如果能试着在本地去搭建3个节点的伪集群,去试着跑一下上面的案例。应该就能明白整个过程。zk作为老牌的一致性协调中间件,也是诸多面试的频次很高的问点。如果你能理解本篇的核心内容,再次碰到这类问题的时候,这将不会是你的盲区。
最后,喜欢本篇内容的朋友希望点赞,关注,转发。
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)
