ECCV 2020 | 腾讯优图8篇论文,涵盖目标跟踪、行人重识别、人脸识别等领域
小白学视觉
共 4193字,需浏览 9分钟
·
2020-07-28 16:42
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
01
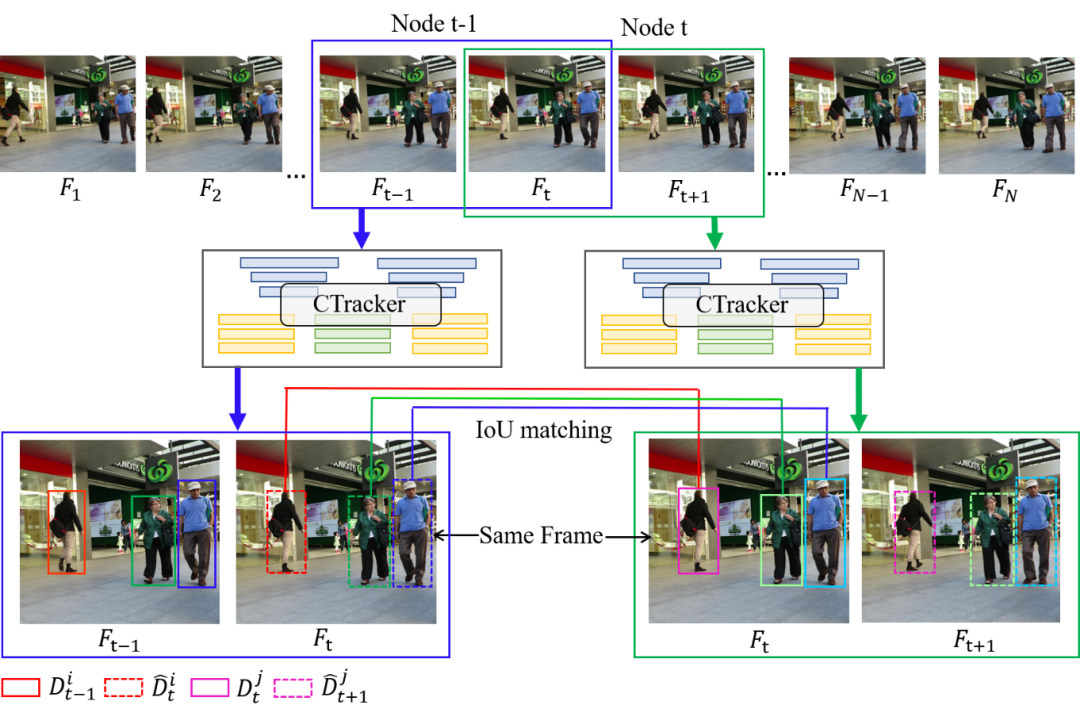
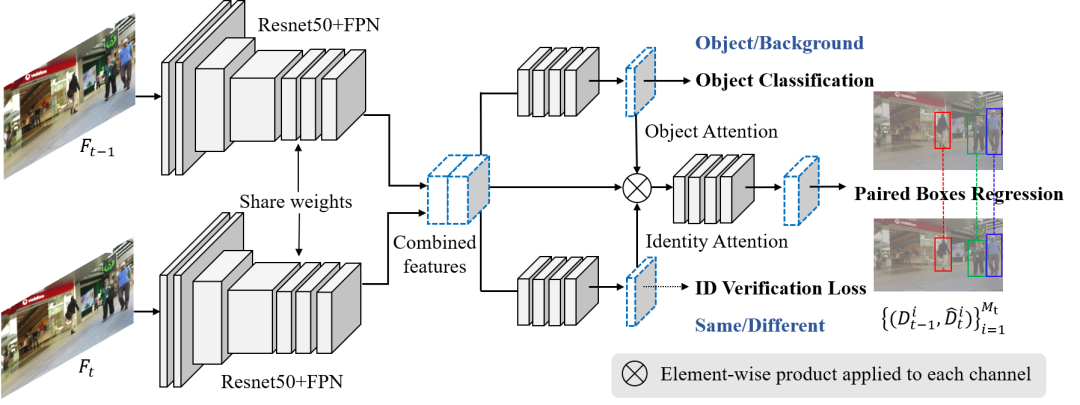
02
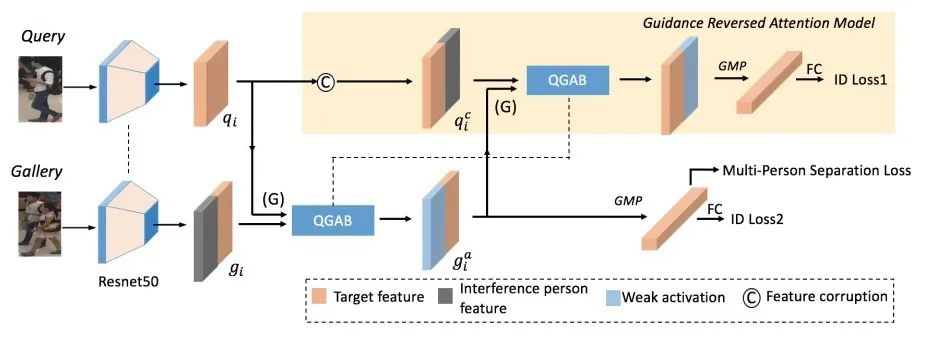
03
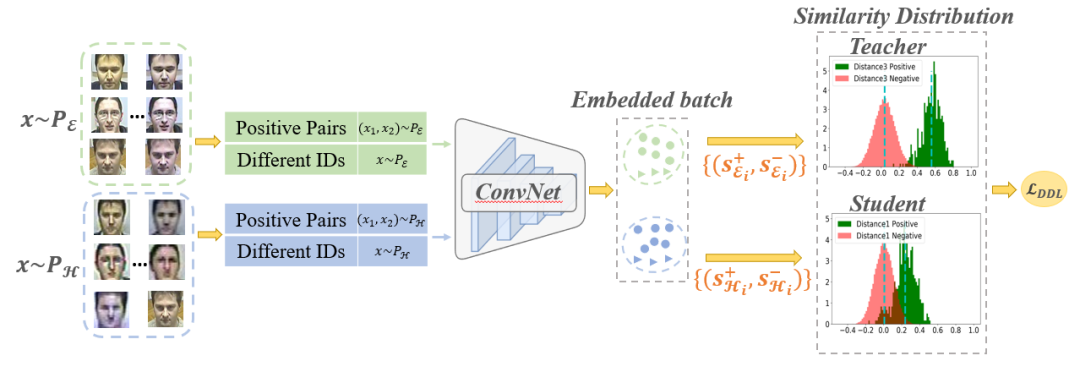
04
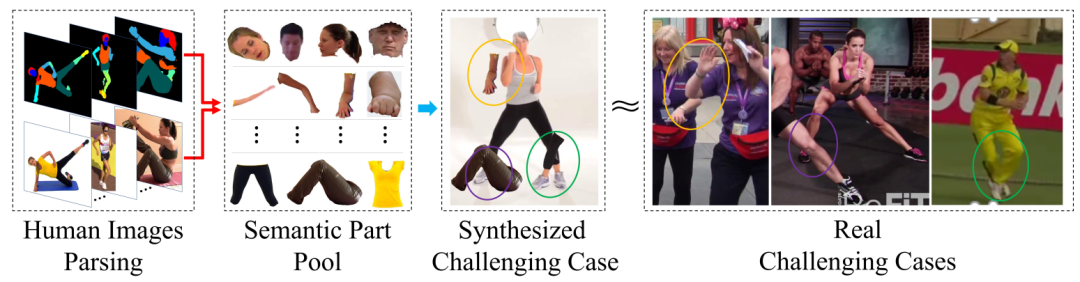
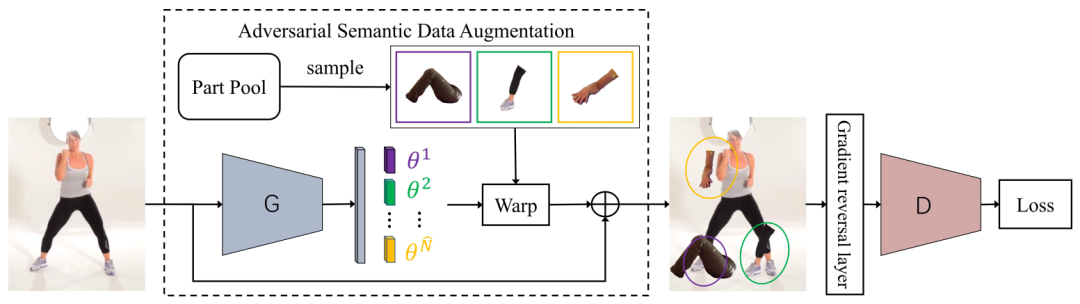
05
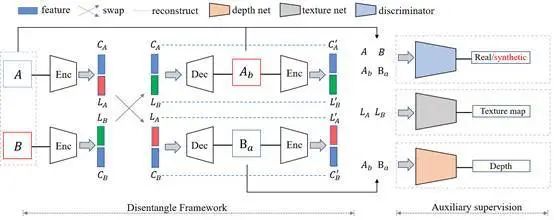
06
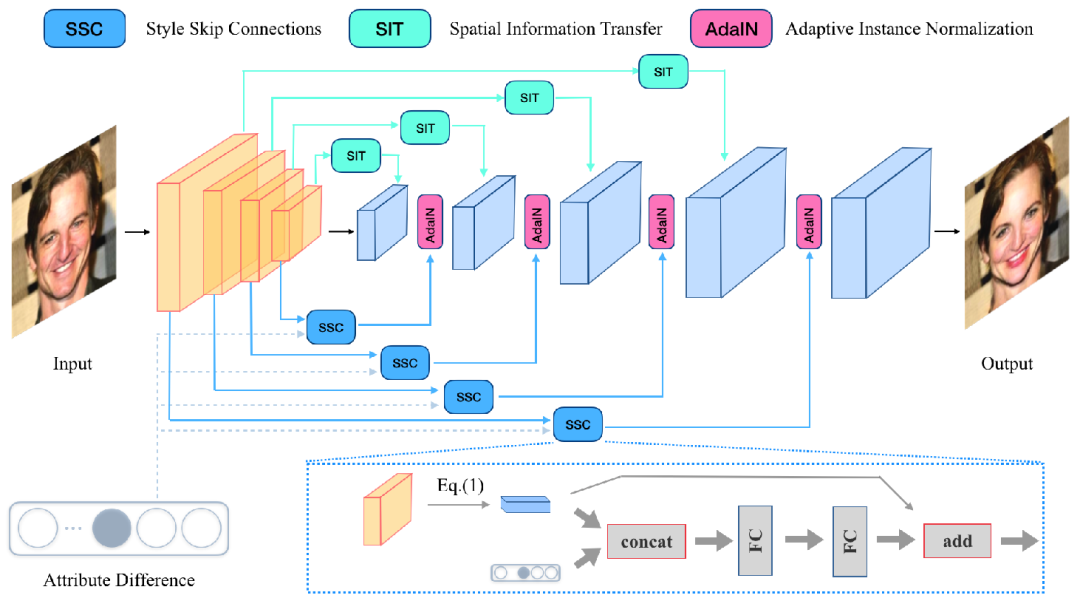
07
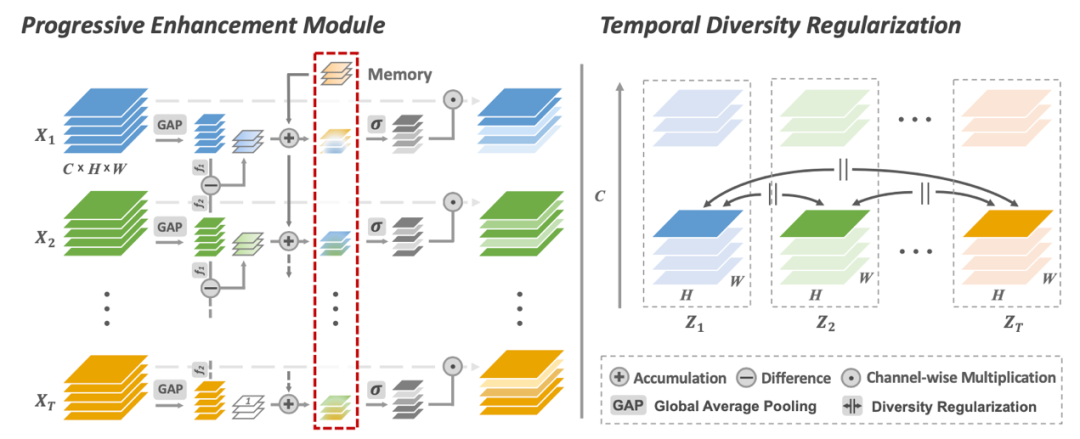

08
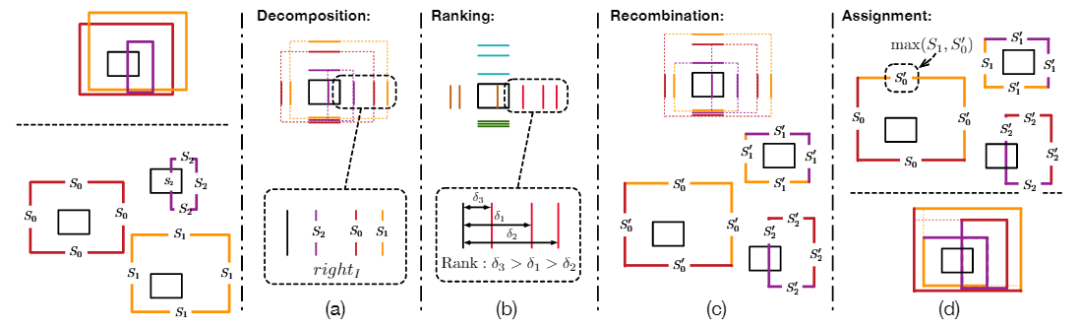
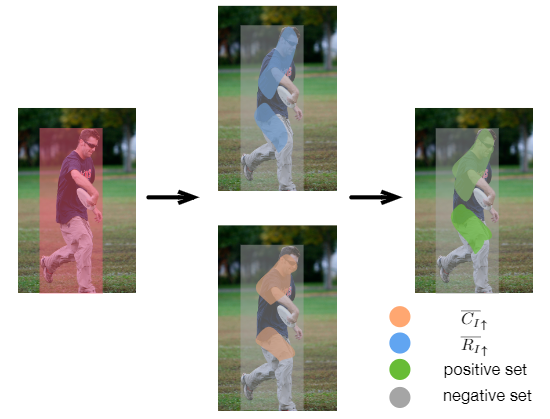
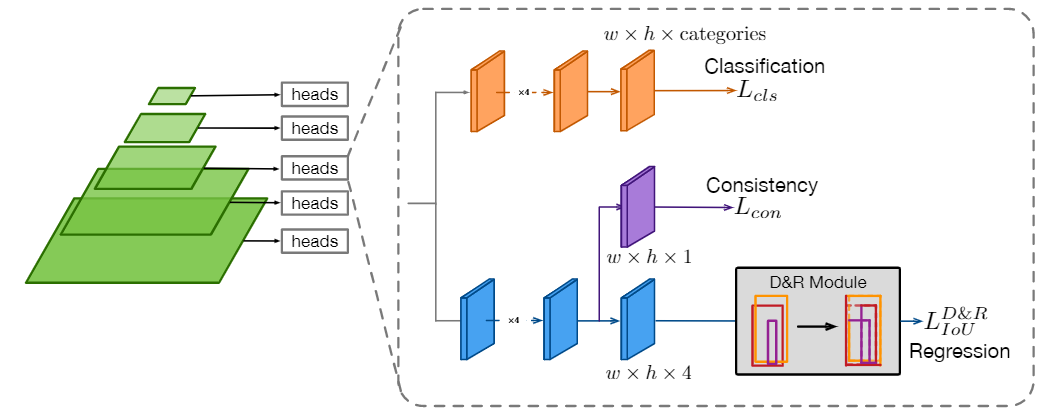
Dive Deeper Into Box for Object Detection
 End
End
评论

共 4193字,需浏览 9分钟
·
2020-07-28 16:42
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
01
02
03
04
05
06
07
08
Dive Deeper Into Box for Object Detection
End