
全网首发:PowerBI 原生瀑布图终极解决方案

瀑布图,在分析中是非常重要的图。在 Power BI 中的原生瀑布图使用起来有些问题,本文来探讨如果基于原生瀑布图的高级使用方法和限制。
默认表现
在 Power BI 中的瀑布图的默认表现是这样的,如果设置:
则表现为:
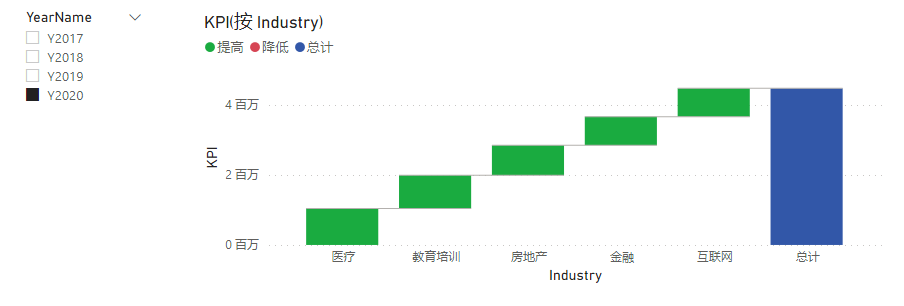
这个表现可以理解。
再尝试另一种设置:
这里的更改是:加入了细目。什么意思呢?不要紧,看看表现再说,如下:
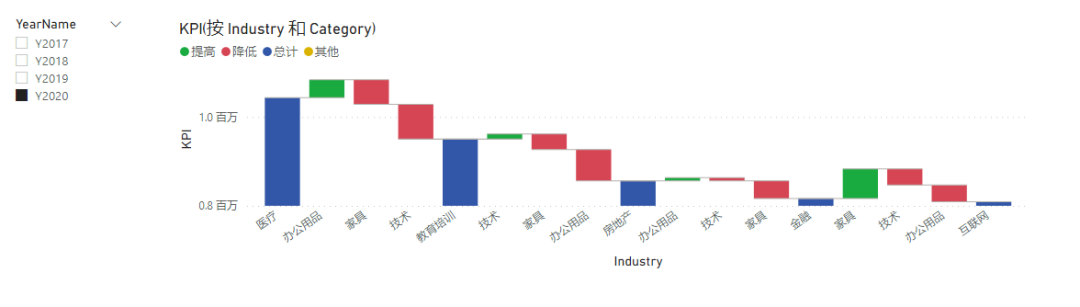
可以看出来:
每个类别形成了对比,类别是立地的柱子。
每个细目是类别之间对比的项目。
细目的排序是按照差异从正数的大到负数的小来排列的,无法自定义。
这三条规律一定要记住,这是原生瀑布图不改变的内部逻辑,我们要改进瀑布图的表现时,也必须满足这个逻辑,不然无法与之适应。
再考虑一下不加入细目的情况,再看一次:
可以看出来:
每个类别形成积累效应
可以自定义顺序(图表右上角可设置)
总计柱子默认生成
规律总结
可以再做一些实验,就能得到以下重要规律:
【第一类规律】如果不放入细目,类别作为积累项,立地柱子默认生成
类别可以自定义顺序
立地柱子默认生成,文本不可改
【第二类规律】如果放入细目,类别将成为对比项,且立地成柱
类别可以自定义顺序
类别作为立地柱子
细目作为差异积累项,按大小排列,顺序不可改
这两类规律非常重要。
业务诉求
现在我们提出业务上的表现诉求,再来想办法看看上述规律是否可以来满足,要求如下:
有首尾两个立地柱子,表示开始和结束
立地柱子可以自定义名字以及这两个柱子的顺序
内部的绿色或红色差异项表示差异积累
差异项可以自定义顺序
如果用 Zebra BI 的瀑布图来实现这个诉求,其效果大致如下:
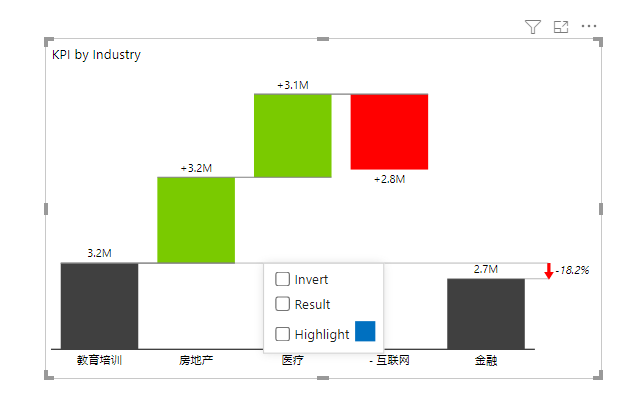
Zebra BI 是可以直接在界面设置柱子的正负以及是否立地的,而且非常简单,这有利于我们理解瀑布图最轻松的设置方式。而 Power BI 原生的瀑布图是做不到的。
通过与规律对比,我们发现有一条是一定做不到的,那就是:
差异项可以自定义顺序
这点是原生瀑布图做不到的。
那么,我们就得到了一个结论:
如果不考虑差异项可以自定义顺序的场景,是可以用原生 Power BI 瀑布图做出的。
下面给出终极方案,该方案是全网首发滴。
终极方案
通过上述研究,按照规律我们可以做出设计了。先来看一个效果:
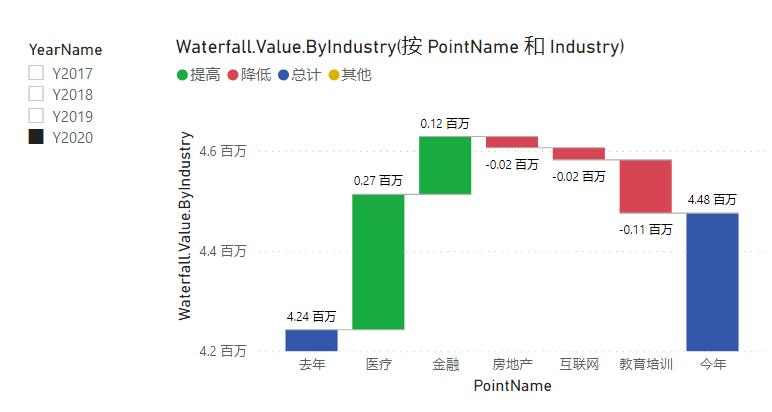
没有错,这正是我们需要的。这里的业务场景是:
用去年和今年分别作为瀑布图的首柱和末柱
来对首柱到末柱是如何变化的按照差异项来对比
中间是每个差异项
差异项的贡献从大到小排序
注意:差异项是无法自定义排序的。
差异项无法自定义排序而是默认排序,是原生瀑布图的最大限制。
假设我们接受这个限制,那么设计这样的瀑布图的通用方法是什么呢。如下给出。
第一步:DAX 自定义首末类别柱
用 DAX 自定义首末类别柱如下:
// 定义计算表如下
Waterfall-Begin-End-ACPY =
SELECTCOLUMNS(
{
( 1 , "Start" , "去年" ) ,
( 2 , "End" , "今年" )
} ,
"OrderBy" , [Value1] , "PointCode" , [Value2] , "PointName" , [Value3] )这个用来作为首末端点。
第二步:DAX 自定义差异细项
用 DAX 自定义差异细项如下:
Waterfall-Body-ByIndustry =
DISTINCT( Customer[Industry] )这个用来作为首末端点之间的内容。
第三步:DAX 自定义度量值
这是最精妙的一步,这里存在一个非常非常重要的技巧,我们先来看 DAX 实现,如下:
Waterfall.Value.ByIndustry =
VAR vPoint = SELECTEDVALUE( 'Waterfall-Begin-End-ACPY'[PointCode] )
VAR vItem = SELECTEDVALUE( 'Waterfall-Body-ByIndustry'[Industry] )
RETURN
SWITCH( TRUE() ,
vPoint = "Start" && vItem <> BLANK() , CALCULATE( [KPI.PY] , TREATAS( { vItem } , 'Customer'[Industry] ) ) ,
vPoint = "End" && vItem <> BLANK() , CALCULATE( [KPI] , TREATAS( { vItem } , 'Customer'[Industry] ) ) ,
vPoint = "Start" , [KPI.PY],
vPoint = "End" , [KPI]
)这里蕴含了一个技巧非常重要,我们不细细拆解这个技巧的原理,我们将其规律描述如下:
用 SWITCH TRUE 结构做判断框架
对首柱与差异项的穷举组合,计算,视为 A
对末柱与差异项的穷举组合,计算,视为 B
则:B - A 是差异项的值
再对首柱和末柱分别计算
这套规律非常重要,这恰好是 Power BI 瀑布图内部在对比计算时依照的规律。
作图如下
有了上述三步,我们就可以作图如下:
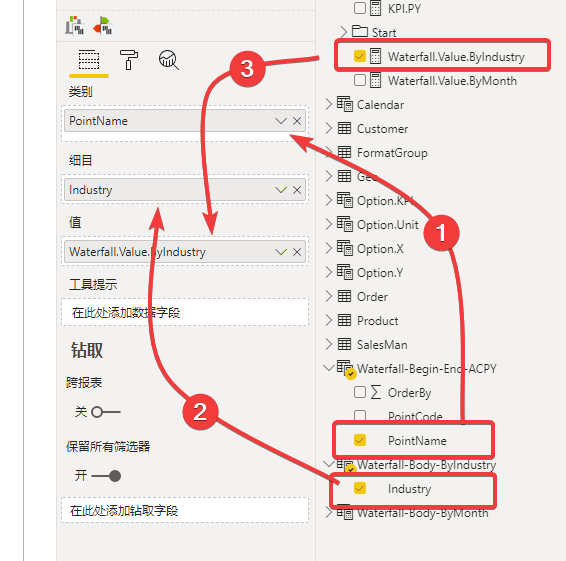
则可以得到效果:
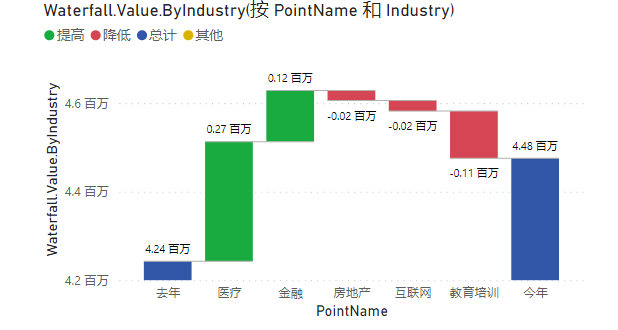
非常好。
不完美的地方
我们刚说明了限制:差异项无法自定义排序而是默认排序,是原生瀑布图的最大限制。
这在做以时间维度做差异项的时候就有些不完美,如下:
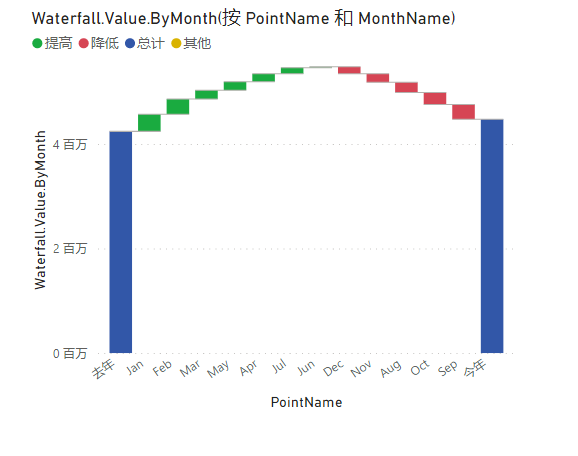
它的差异项并非是按照月份来排序的,而是按照贡献度来排序的。
也就是说:
Power BI 的原生瀑布图在设计的时候就是考虑到它对贡献度的分析。
总结
本文彻底给出了 Power BI 中原生瀑布图的行图规律以及如何利用这些规律制作高级瀑布图以及其适用范围。
结论是:
可以完美支持以贡献度分析为主的瀑布结构
不能支持按照自定义细项排序的瀑布结构
对于此规律和结构的了解非常重要,它将回答什么图可以做,什么图不可以做,那对于不完美怎么办呢?答案是推荐使用 Zebra BI 来解决即可。
你可以复制粘贴本文 DAX 直接使用或者系统化学习《BI真经》。
PowerBI 实现价格数量混合模型分析企业增长原因

国内独家:零售分析自动化大型模板套件 + 线下超级精英密训

PowerBI 灵异事件,你迟早会遇到,骨灰玩家问题

全网首发 Power BI DAX 纯原生高性能分页矩阵

DAX Pro - 全新升级,打造自己的模板库

DAX 设计模式(第二版)中文在线学习正式开放
在订阅了BI佐罗讲授的《BI真经》之《BI进行时》课程区,除了可以下载本文案例,还可以观看视频讲解。
让数据真正成为你的力量
Create value through simple and easy with fun by PowerBI
Excel BI | DAX Pro | DAX 权威指南 | 线下VIP学习
扫码与PBI精英一起学习,验证码:data2021
PowerBI MVP 带你正确而高效地学习 PowerBI
点击“阅读原文”,即刻开始
↙