
讲讲很重要的正态分布
转自:机器之心
我们从高中就开始学正态分布,现在做数据分析、机器学习还是离不开它,那你有没有想过正态分布有什么特别之处?为什么那么多关于数据科学和机器学习的文章都围绕正态分布展开?本文作者专门写了一篇文章,试着用易于理解的方式阐明正态分布的概念。
什么是概率分布?
什么是正态分布?
为什么变量如此青睐正态分布
如何用 Python 查看查看特征的分布?
其它分布变一变也能近似正态分布
什么是概率分布?
如果我们想准确地预测变量,那么首先我们要了解目标变量的基本行为。 我们先要确定目标变量可能输出的结果,以及这个可能的输出结果是离散值(孤立值)还是连续值(无限值)。简单点解释就是,如果我们要评估骰子的行为,那么第一步是要知道它可以取 1 到 6 之间的任一整数值(离散值)。 然后下一步是开始为事件(值)分配概率。因此,如果一个值不会出现,则概率为 0%。
什么是正态概率分布?
平均值——样本中所有点的平均值。
标准差——表示数据集与样本均值的偏离程度。
为什么这么多变量近似正态分布?
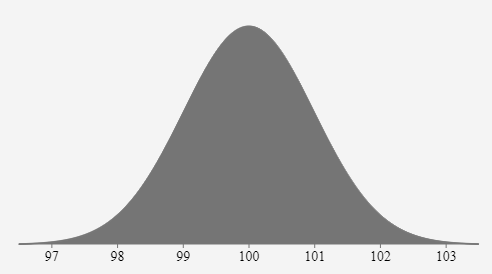
平均值是曲线的中心。这是曲线的最高点,因为大多数点都在平均值附近; 曲线两侧点的数量是相等的。曲线中心的点数量最多; 曲线下的面积是变量能取的所有值的概率和; 因此曲线下面的总面积为 100%。
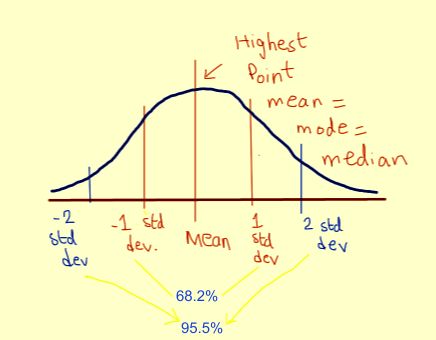
约有 68.2% 的点落在 ±1 个标准差的范围内 约有 95.5% 的点落在 ±2 个标准差的范围内 约有 99.7% 的点落在 ±3 个标准差的范围内。

如果你用计算好的概率密度函数绘制概率分布曲线,那么给定范围的曲线下的面积就描述了目标变量在该范围内的概率。 概率分布函数是根据多个参数(如变量的平均值或标准差)计算得到的。 我们可以用概率分布函数求出随机变量在一个范围内取值的相对概率。举个例子,我们可以记录股票的日收益,把它们分到合适的桶中,然后找出未来收益概率在 20~40% 的股票。 标准差越大,样本波动越大。
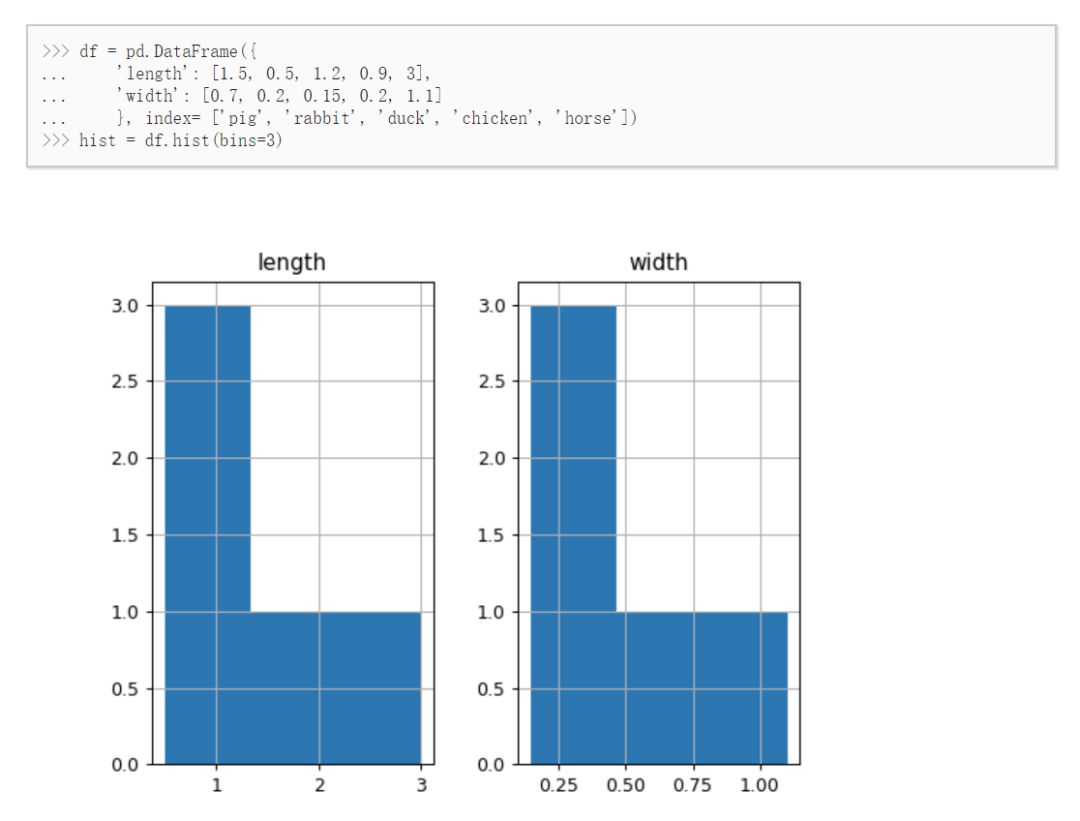
如何用 Python 找出特征分布?
AxB 服从正态分布; A+B 服从正态分布。
变量还是乖乖地变成正态分布吧
Z 分数 计算平均值 计算标准差

scipy.stats.boxcox(x, lmbda=None, alpha=None)
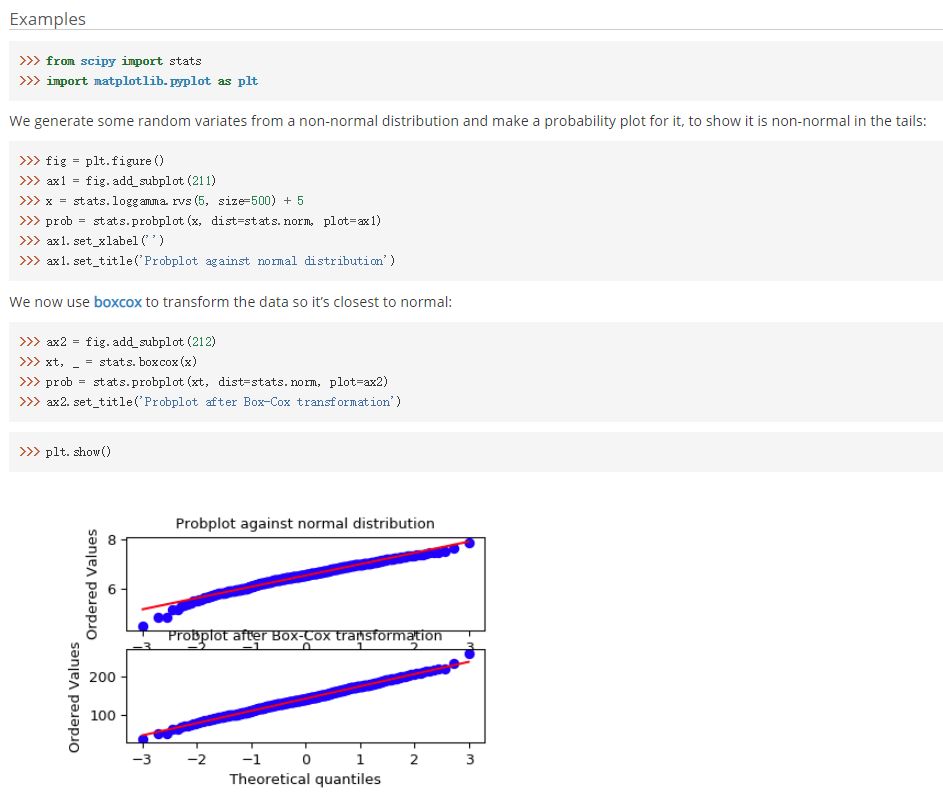
sklearn.preprocessing.PowerTransformer(method=’yeo-johnson’, standardize=True, copy=True)





评论