“复现人类智能,AI 的下一步是融合语言与工具智能。”
编者按:2023 年 8 月14日,第七届 GAIR 全球人工智能与机器人大会在新加坡乌节大酒店正式开幕。论坛由 GAIR 研究院、雷峰网、世界科技出版社、科特勒咨询集团联合主办。大会共开设 10 个主题论坛,聚焦大模型时代下的AIGC、Infra、生命科学、教育,SaaS、web3、跨境电商等领域的变革创新。此次大会是在大模型技术爆炸时代,国内首个出海的AI顶级论坛,也是中国人工智能影响力的一次跨境溢出。
在第一天的“GPT时代的杰出贡献者”专场上,周伯文以“复杂场景下的生成式 AI”为题发表了主题演讲。周伯文是清华大学讲席教授、电子工程系长聘教授,衔远科技创始人,IEEE/CAAI Fellow 。同时也是前京东集团高级副总裁、技术委员会主席。
他提到,今天 AI 已经体现出掌握人类语言的能力,下一步,如要复现人类智能,周伯文认为 AI 应适配到更加复杂的场景,其中如何系统地学习和使用工具就变得非常重要。
Tools for AI or AI for Tools ?这是一个哲学问题。以 AI 为中心、工具的存在是为了让 AI 更好;那么以工具为中心、 AI 的存在是为了让工具更容易被使用。如何抉择是人类与 AI 谁占主导。人与 AI 的关系走向何方,最终将取决于 AI 技术金字塔尖的引领者对这一问题的博弈思考。
以下为周伯文教授的现场演讲内容,雷峰网作了不改变原意的编辑及整理:
网上有个段子说,大模型在吟诗作画,人在苦哈哈干活。笑话背后反映了一个问题,我们需要考虑一些真实、复杂的场景,让 AI 去干更苦的事情。
从智力的角度讲,我认为人之所以为人,重要一点是因为人会使用工具,会创造工具,并且通过工具来完成各类复杂场景的任务。当然,AI 本身也是人类创造的一种工具。Next big question 是,AI 能否像人一样,用好工具。
过去的几十年中,我们终于把人类对于语言的理解能力教会了 AI ,有了今天的 ChatGPT 等大模型。那么下一个问题就是,我们是否能够将语言和工具结合起来,教给AI。
因为学会了语言和工具的结合,人类走到了今天,AI 能否复现人类智能,我对这个问题的回答是“YES”,因为基于基础模型的语言与推理能力,我们看到了AI融合语言与工具智能的能力。这之中一定会有非常多挑战,也需要对这个问题做一些更详尽的学术定义(to define the problem properly),在接下来的报告中我将给大家展开。
LLMs可以做很多事情,未来可以把所有工作基于一个 LLM 连接起来,这是一个方向。但是在这个方向之前还缺乏系统的思考,我想给出我们最新的研究和框架性思考,以及三个基础研究方向。
我们缺乏对工具的定义,工具非常多样,可以分为:一类是确定性工具,像时钟、计算器、秒表等;一类基于 API 能力的工具,本质上是将一个功能直接函数化;一类是有专长的神经网络,或者说是 其他的Foundation Models,这也是未来 AI 要去使用的工具;还有一类是与物理世界进行交互,像机器人、传感器等。
另外一种区分方法是从工具的互动角度分,包括能与物理世界互动的工具、把世界抽象成一个图形界面的GUI工具,和把世界抽象成 API工具 ,所谓的“软件正在吞噬世界”。
这些不同方式都定义了人和 AI 要去交互的工具。而最核心的一点是,所有的这些工具及他们的组合,在大模型时代,我们都可以将它看作 是Token序列而已。
在 OpenAI 推出 ChatGPT 之前,还推出过一个非常重要的工作,叫做 WebGPT。问ChatGPT一个足够复杂的问题,图片展示的是它生成的答案,这个答案跟 ChatGPT 看到的不太一样。它不仅是语言模型,逐个字地给出答案,而是不但生成了答案,还给出了内容出处,也就是作为一个 AI 系统,是如何形成的这个答案。这个操作基本上就解决掉了目前看到的知识幻觉的问题,不像 ChatGPT 的答案不能准确给出它的答案从哪里来。
WebGPT 如何做到的呢?其实很简单,开发出一个集成环境,让人回答问题。在回答的过程中,让大模型学会人的搜索动作、鼠标拖拽、上下浏览等动作,这个过程中大模型学会的就不只是文字,而是学会了人的行为序列。在这种复杂场景中,大模型学会之后,就可以生成可以理解的回答。
结果很有意思,OpenAI 只标注了 6000 个例子,就可以训练出非常好的 WebGPT。这种让大模型学会使用工具的训练就可以解决现在大语言模型非常不擅长的点,比如时效问题分析,复杂计算等。解决这些复杂问题,只需要大模型学会在合适的时间,好用合适的工具组合,如何学会如何把结果融合在一起,这也就是为什么 AI 的下一步要学会系统性使用工具。
我认为 AI 的进一步发展取决于领军人物怎么看这个事情。AI 如何使用工具有两种不同的视角。一种视角是以 AI 为中心,另一种视角是 AI 辅助,这两种代表人对于 AI 和工具的思考。第一个思考是以 AI 为中心,工具是为了让 AI 回答的更好,AI 自己决定用什么工具。另一种对比思路是世界围绕工具展开, AI 是为了辅助更好理解人的决策。这两种不同模式决定开发不同的系统。
在不同的场景也许需要使用不同的观点来看待这个问题。但是目前的 AI 和工具融合缺少一个完整框架,在学术界中的认知中,一个比较完备的框架由以下四方面组成:控制器、工具集、环境和感知器。
控制器(Controller)的任务是提出一个可执行方案以满足人提出的要求。控制器负责决定工具的行为序列,怎样在合适的时间调用合适的工具去理解任务,返回结果,并执行下一步。
工具集(Tool Set)顾名思义,是工具的集合,有不同功能。这个工具集是完全异构异质的,从确定性工具、到API,到其他模型、再到机器人与机械臂等。
进而工具与环境(Environment)进行交互,在环境中操作。
接下来有一个感知器(Percevier),感知器负责感知使用工具后环境发生的变化,接收外部的信号,包括人类的反馈去纠正行为,最后给到控制器一个结果。
用数学语言来表示,可以将其分解成一系列的马尔科夫决策过程,去求解最佳行为序列。从贝叶斯公式展开,其核心部分取决于两点:给定了 Feedback(变量1),Histories(变量2),再给 Human Instruction(变量3) ,去决定在这个时间最好的行动是什么。
这里的行动包括两个信息:调用什么工具、返回什么信息,将其分解为两个子问题就是:第一,要基于目标去选择合适的工具,第二是在选定工具后决定行动。最终的目标则是选择一系列的行动,最大化这个概率。和 ChatGPT 对比,ChatGPT 是输出文字序列,由这个框架输出行为序列。
这个框架核心要解决三个问题:理解用户的意图或者任务本身(Intent Understanding),理解工具库与工具本身的表征(Tool Understanding),以及要有完整的推理和规划能力(Planning and Reasoning)
同样,在这点上也有不同的视角看待这个问题。站在大语言模型研究的视角看,会认为一切都是大语言模型的衍生物,只要去训练越来越多的大语言模型,问题自然会解决。但是从强化学习的角度看,这只是一个强化学习的过程,语言模型只是一个强有力的架构。但无论如何看待这个问题,都归根到如何去建立一个更好的基础模型,不过这个模型和ChatGPT 相比,无论从任务、能力,还是架构,可能都需要完全不同的思考与设计,我认为这是一个非常重大的研究机会。
意图理解指的是控制器如何理解人的意图并接受任务, 大语言模型在自然语言理解,推理,情感分析等方面做的非常好。即使对于从未见过的任务,在基础很强的基础模型上,通过指令微调也可以很快学会。所以在很大程度上我们认为,这是一个可以解决的问题,只要模型足够强,有足够多的高质量指令集,问题就可以解决。
不过也有两点挑战,一点是如何理解模糊指令,当用户的描述非常宽泛时,或者是对同一问题不同用户有不同表述时,如何准确地理解指令。另一点是如何解决意图耦合带来的理论上的无限指令空间。这些地方仍有空间去研究,但已经不是大的问题。
工具理解是一个复杂的任务。举例来说,如果工具是一系列 API,要教会控制器去使用 API 。比如有一个天气的API,它只有两个变量,一个是城市,一个是日期,可以返回的是温度、风、降雨量等信息,用户可以问它上海明天的天气怎么样,或者伦敦未来两天会不会下雨,再或者洛杉矶未来一周平均气温是多少。要将用户的意图转换成一系列的 API 调用,以完成复杂场景。
挑战在于,当一系列工具调用和其他如模型、传感器组合的时候,问题就会变得复杂。目前,这个问题还没有特别好的解决办法,例如在ChatGPT中,我们是手动一个个去勾选不同的工具,这是一种启发式选择。如何让模型自动地去选择工具也是一个重要的问题。
涌现能力大家听过很多遍,这个词最早来自于《Science》,一名诺贝尔奖得主 1972 年发布了一篇名为 More Is Different 的文章,标题的三个字指的便是涌现能力。我们把世界知识压缩在模型里,通过不断地学习,让大模型学会语法、语义、简单的数理分析、翻译等,这背后是模型等涌现能力。
但是在非常复杂的推理情况下光有涌现能力是远远不够的。
比如如下的两类任务,在 Type 1 中可见,做情感分析、主题聚类、翻译,大模型可以做的非常好。但是在 Type 2 中,问大模型“Elon Mask 两个字母的末位字母拼在一起是什么”,这类需要简单推理的问题时,大模型没有回答出来。这说明,在规划和推理能力方面,具备涌现能力的大模型还有许多路要走。
提升规划推理能力的一种做法是,通过思维链一步步分解任务。将思维链与多模态知识推理结合时,就可以做复杂多模态场景下的知识推理。
比如学习小狗识别,当图片中元素非常多时,如何帮助大模型在复杂场景中实现识别?思维链的解决方案是这样:先识别是否是动物,再看动物是否有皮毛,第三圈定有皮毛的动物和黑色的鼻子,第四是坐在地上。
通过一步一步教导大模型,学会不同的属性,将思维链和多模态结合在一起,可以完成更复杂场景的分析。所以当把 LLM 放在复杂工具里面,它的推理能力如何分析,我们在上述提出的框架里将其分为两类:静态规划和动态推理。
在静态规划中,控制器做出的规划是恒定的,不需要与环境交互。在动态推理中,模型会和环境进行交互,并且给控制器反馈,制定下一步计划。
如开电视、关烤箱之类的动作属于静态规划,理解完意图去执行即可。难点在于如何使用 LLM 生成静态计划,以及找到适合的行动并执行它们。
如果让护理机器人完成给老人刮胡子涂乳液的任务,一个预训练任务模型(Pre-Trained Masked LLM)就会在所有可选的行为里选择,每一个 Action 都是模型的 Token,模型选择最合适的 Action。对机器人来说,第一步是先找到乳液,第二步把乳液放在右手,通过这个过程学会静态规划。
更复杂一点,机器人不但要做这个行为,还要对行为的结果产生预期,一个比较有代表性的工作是 ReAct,ReAct 让大模型以交错的方式进行 "思考 "和 "行动"。
加入 ReAct 的关键改变在于,大模型采取关键动作的时候,它会去思考我现在已经做了什么?下一步目标是什么?下一步要怎么做?通过这样分解成一步一步的思考之后,就有更高的概率选择合适的动作。做完动作后,又会去思考刚才的动作造成了什么后果,这种反思让 LLM 接下来的行为更准确。
与外在环境进行交互的推理是具身智能非常重要的理论基础。在这里用一个例子解释,看下图左侧的人机对话:
LLM 回答 OK 之后,它理解自己要产生一个 Token,这个 Token是一个 Action,Action 的含义是去桌子那边,当机器人走到桌子边,LLM 调用了另一个工具——摄像头,当摄像头获得数据并分析后,它发现里边有可乐、水,还有一个巧克力棒。LLM 开始思考,它收到的任务是“喝”,桌子上有可乐有水,它需要进一步确认消除歧义,于是它继续主动对话。
人:可乐。
机器人将“可乐”作为一个输入,继续向下采取行动。它的下一个 Action 是拿起可乐,Action 驱动机械臂去做“拿起”的动作,但是第一次失败了。这是 LLM 继续反馈,反馈信息:Action 失败,于是下一个 Action 是再拿一次。
以上这一系列复杂的动作依照我们 LLM 和 Tool 的理念,生成了一系列 Action,Action 和环境互动,每个互动的结果会帮助控制器(Controller)判断下一步做什么。这些内容听起来复杂,但还远远达不到解决复杂任务的场景。
我认为在未来,要完成复杂场景下的任务需要非常多的子步骤,每个子步骤涉及非常多工具,这个工具来自更大的工具集。人在复杂场景要用到许多工具,这对 LLM 的挑战就在于,要理解不同工具间的相互作用。
另外,工具不一定按顺序执行,会并行执行,产生叠加效应 。最后一种是从单机解决问题到多机协作,由多个工具可共同负责一项任务。
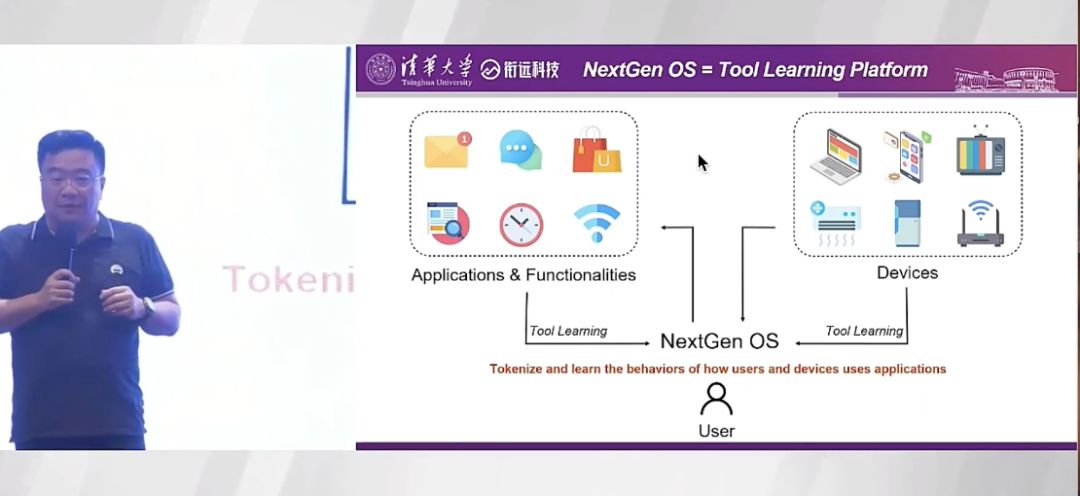
很多人认为 LLM 是未来的操作系统(OS),但我认为,仅仅从语言处理和生成的角度讲,它不足以成为未来的 OS。
未来的 OS 应该融合了语言能力的工具平台。现在的 OS 是 在设备上Enable各种APP与功能 ,而在 LLM 的眼里,无论是 APP、功能还是设备本身,都是工具。LLM 的核心逻辑是理解任务后决定在什么平台以及什么样的复杂场景下唤醒什么工具,根据工具的返回结果再采取下一个行为。
所以,未来的 OS 一定是NextGen OS = a tool-learning platform with a human language interface
Nothing more,nothing less。这也是为什么我们对工具和语言结合十分感兴趣的原因,欢迎大家考虑加入我们清华大学电子系协同交互智能中心和我们一起开展这些智能前沿研究,衔远科技也在招聘多名LLM和多模态算法工程师!谢谢大家!
[1] Qin Y, Hu S, Lin Y, et al. Tool learning with foundation models[J]. arXiv preprint arXiv:2304.08354, 2023.
[2] Mialon G, Dessì R, Lomeli M, et al. Augmented language models: a survey[J]. arXiv preprint arXiv:2302.07842, 2023.
[3] Nakano R, Hilton J, Balaji S, et al. Webgpt: Browser-assisted question-answering with human feedback[J]. arXiv preprint arXiv:2112.09332, 2021.
[4] Yao S, Zhao J, Yu D, et al. React: Synergizing reasoning and acting in language models[J]. arXiv preprint arXiv:2210.03629, 2022.
[5] Ahn M, Brohan A, Brown N, et al. Do as i can, not as i say: Grounding language in robotic affordances[J]. arXiv preprint arXiv:2204.01691, 2022.
[6] Huang, Wenlong, et al. “Language models as zero-shot planners: Extracting actionable knowledge for embodied agents.” International Conference on Machine Learning. PMLR, 2022.
[7] Huang, Wenlong, et al. “Inner monologue: Embodied reasoning through planning with language models.” arXiv preprint arXiv:2207.05608 (2022).
[8] Wei, Jason, et al. "Finetuned language models are zero-shot learners." arXiv preprint arXiv:2109.01652 (2021).
[9] Schick T, Dwivedi-Yu J, Dessì R, et al. Toolformer: Language models can teach themselves to use tools[J]. arXiv preprint arXiv:2302.04761, 2023.