
聊聊 APM 及介绍下我们的内部实现
以下文章来源于武培轩,回复资源获取资料
最近几个月,我们在公司开发了 APM 系统,借这个契机,给大家分享一下。当然,我不是来介绍项目的,而是借我们的项目给大家介绍 APM 系统相关内容。
本文来说说什么是 APM 系统,也就是大家平时说的监控系统,以及怎么实现一个 APM 系统。因为一些特殊的原因,我在文中会使用 Dog 作为我们的系统名称进行介绍。
我们为 Dog 规划的目标是接入公司的大部分应用,预计每秒处理 500MB-1000MB 的数据,单机每秒 100MB 左右,使用多台普通的 AWS EC2。
因为本文的很多读者供职的公司不一定有比较全面的 APM 系统,所以我尽量照顾更多读者的阅读感受,会在有些内容上啰嗦一些,希望大家可以理解。我会在文中提到 prometheus、grafana、cat、pinpoint、skywalking、zipkin 等一系列工具,如果你没有用过也不要紧,我会充分考虑到这一点。
本文预设的一些背景:Java 语言、web 服务、每个应用有多个实例、以微服务方式部署。另外,从文章的可阅读性上考虑,我假设每个应用的不同实例分布在不同的 IP 上,可能你的应用场景不一定是这样的。
APM 简介
APM 通常认为是 Application Performance Management 的简写,它主要有三个方面的内容,分别是 Logs(日志)、Traces(链路追踪) 和 Metrics(报表统计)。以后大家接触任何一个 APM 系统的时候,都可以从这三个方面去分析它到底是什么样的一个系统。
有些场景中,APM 特指上面三个中的 Metrics,我们这里不去讨论这个概念
这节我们先对这 3 个方面进行介绍,同时介绍一下这 3 个领域里面一些常用的工具。
1、首先 Logs 最好理解,就是对各个应用中打印的 log 进行收集和提供查询能力。
Logs 系统的重要性不言而喻,通常我们在排查特定的请求的时候,是非常依赖于上下文的日志的。
以前我们都是通过 terminal 登录到机器里面去查 log(我好几年都是这样过来的),但是由于集群化和微服务化的原因,继续使用这种方式工作效率会比较低,因为你可能需要登录好几台机器搜索日志才能找到需要的信息,所以需要有一个地方中心化存储日志,并且提供日志查询。
Logs 的典型实现是 ELK (ElasticSearch、Logstash、Kibana),三个项目都是由 Elastic 开源,其中最核心的就是 ES 的储存和查询的性能得到了大家的认可,经受了非常多公司的业务考验。
Logstash 负责收集日志,然后解析并存储到 ES。通常有两种比较主流的日志采集方式,一种是通过一个客户端程序 FileBeat,收集每个应用打印到本地磁盘的日志,发送给 Logstash;另一种则是每个应用不需要将日志存储到磁盘,而是直接发送到 Kafka 集群中,由 Logstash 来消费。
Kibana 是一个非常好用的工具,用于对 ES 的数据进行可视化,简单来说,它就是 ES 的客户端。

我们回过头来分析 Logs 系统,Logs 系统的数据来自于应用中打印的日志,它的特点是数据量可能很大,取决于应用开发者怎么打日志,Logs 系统需要存储全量数据,通常都要支持至少 1 周的储存。
每条日志包含 ip、thread、class、timestamp、traceId、message 等信息,它涉及到的技术点非常容易理解,就是日志的存储和查询。
使用也非常简单,排查问题时,通常先通过关键字搜到一条日志,然后通过它的 traceId 来搜索整个链路的日志。
题外话,Elastic 其实除了 Logs 以外,也提供了 Metrics 和 Traces 的解决方案,不过目前国内用户主要是使用它的 Logs 功能。
2、我们再来看看 Traces 系统,它用于记录整个调用链路。
前面介绍的 Logs 系统使用的是开发者打印的日志,所以它是最贴近业务的。而 Traces 系统就离业务更远一些了,它关注的是一个请求进来以后,经过了哪些应用、哪些方法,分别在各个节点耗费了多少时间,在哪个地方抛出的异常等,用来快速定位问题。
经过多年的发展,Traces 系统虽然在服务端的设计很多样,但是客户端的设计慢慢地趋于统一,所以有了 OpenTracing 项目,我们可以简单理解为它是一个规范,它定义了一套 API,把客户端的模型固化下来。当前比较主流的 Traces 系统中,Jaeger、SkyWalking 是使用这个规范的,而 Zipkin、Pinpoint 没有使用该规范。限于篇幅,本文不对 OpenTracing 展开介绍。
下面这张图是我画的一个请求的时序图:
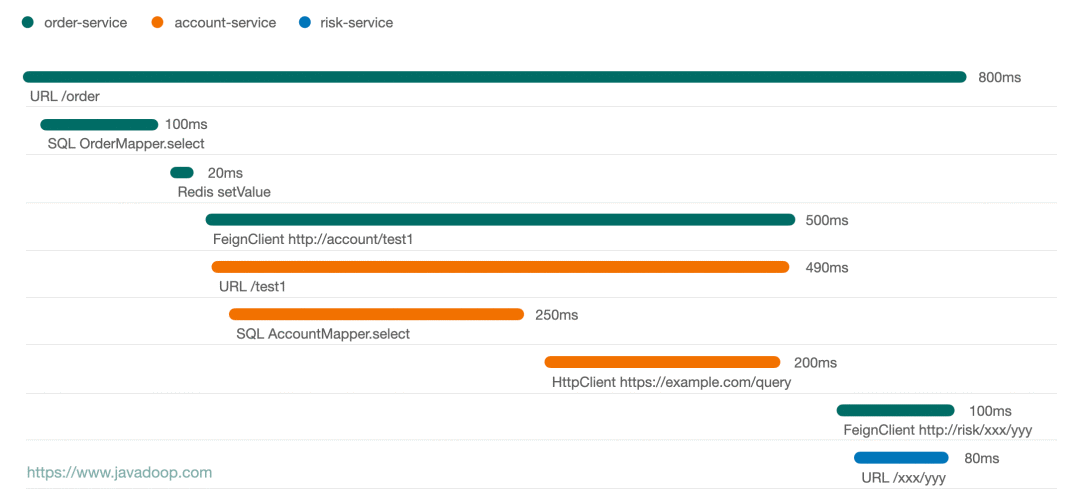
从上面这个图中,可以非常方便地看出,这个请求经过了 3 个应用,通过线的长短可以非常容易看出各个节点的耗时情况。通常点击某个节点,我们可以有更多的信息展示,比如点击 HttpClient 节点我们可能有 request 和 response 的数据。
下面这张图是 Skywalking 的图,它的 UI 也是蛮好的:

SkyWalking 在国内应该比较多公司使用,是一个比较优秀的由国人发起的开源项目,已进入 Apache 基金会。
另一个比较好的开源 Traces 系统是由韩国人开源的 Pinpoint,它的打点数据非常丰富,这里有官方提供的 Live Demo,大家可以去玩一玩。

最近比较火的是由 CNCF(Cloud Native Computing Foundation) 基金会管理的 Jeager:

当然也有很多人使用的是 Zipkin,算是 Traces 系统中开源项目的老前辈了:

上面介绍的是目前比较主流的 Traces 系统,在排查具体问题的时候它们非常有用,通过链路分析,很容易就可以看出来这个请求经过了哪些节点、在每个节点的耗时、是否在某个节点执行异常等。
虽然这里介绍的几个 Traces 系统的 UI 不一样,大家可能有所偏好,但是具体说起来,表达的都是一个东西,那就是一颗调用树,所以我们要来说说每个项目除了 UI 以外不一样的地方。
首先肯定是数据的丰富度,你往上拉看 Pinpoint 的树,你会发现它的埋点非常丰富,真的实现了一个请求经过哪些方法一目了然。
但是这真的是一个好事吗?值得大家去思考一下。两个方面,一个是对客户端的性能影响,另一个是服务端的压力。
其次,Traces 系统因为有系统间调用的数据,所以很多 Traces 系统会使用这个数据做系统间的调用统计,比如下面这个图其实也蛮有用的:

另外,前面说的是某个请求的完整链路分析,那么就引出另一个问题,我们怎么获取这个“某个请求”,这也是每个 Traces 系统的不同之处。
比如上图,它是 Pinpoint 的图,我们看到前面两个节点的圆圈是不完美的,点击前面这个圆圈,就可以看出来原因了:
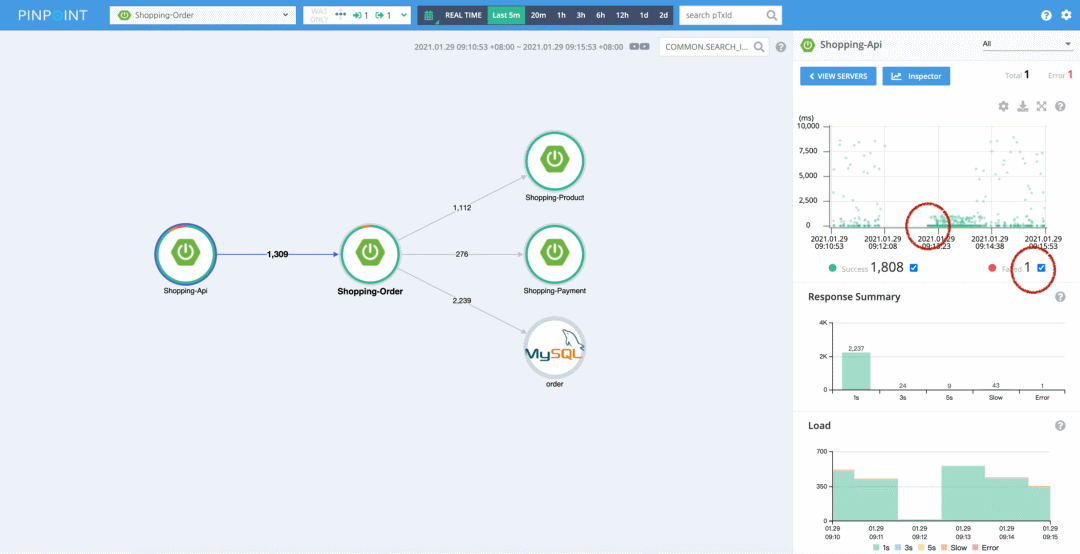
图中右边的两个红圈是我加的。我们可以看到在 Shopping-api 调用 Shopping-order 的请求中,有 1 个失败的请求,我们用鼠标在散点图中把这个红点框出来,就可以进入到 trace 视图,查看具体的调用链路了。限于篇幅,我这里就不去演示其他 Traces 系统的入口了。
还是看上面这个图,我们看右下角的两个统计图,我们可以看出来在最近 5 分钟内 Shopping-api 调用 Shopping-order 的所有请求的耗时情况,以及时间分布。在发生异常的情况,比如流量突发,这些图的作用就出来了。
对于 Traces 系统来说,最有用的就是这些东西了,当然大家在使用过程中,可能也发现了 Traces 系统有很多的统计功能或者机器健康情况的监控,这些是每个 Traces 系统的差异化功能,我们就不去具体分析了。
3、最后,我们再来讨论 Metrics,它侧重于各种报表数据的收集和展示。
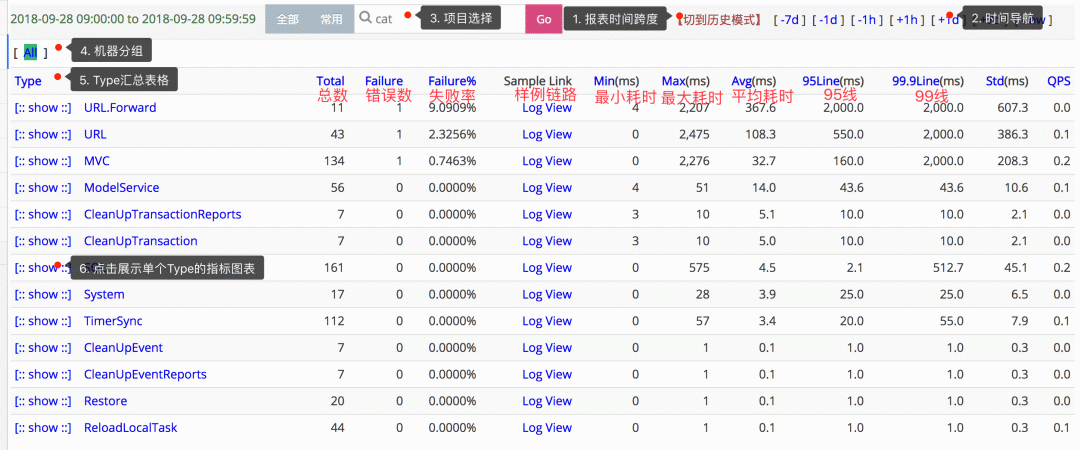
在 Metrics 方面做得比较好的开源系统,是大众点评开源的 Cat,下面这个图是 Cat 中的 transaction 视图,它展示了很多的我们经常需要关心的统计数据:
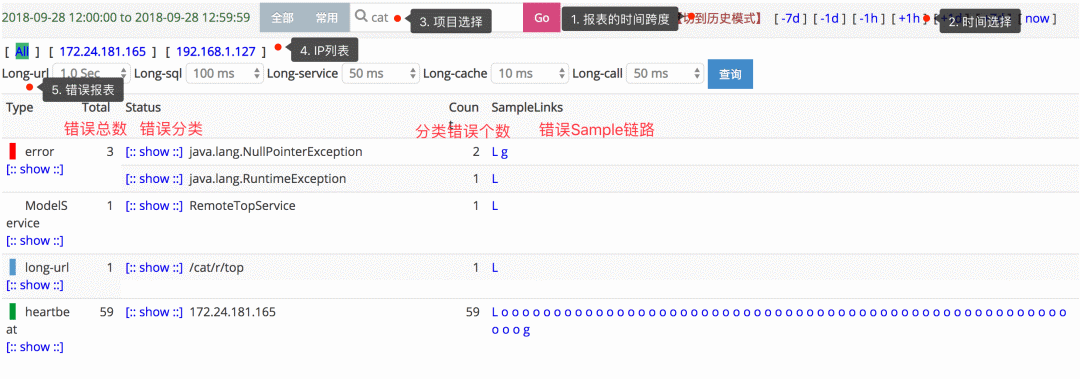
下图是 Cat 的 problem 视图,对我们开发者来说就太有用了,应用开发者的目标就是让这个视图中的数据越少越好。
本文之后的内容主要都是围绕着 Metrics 展开的,所以这里就不再展开更多的内容了。
另外,说到 APM 或系统监控,就不得不提 Prometheus+Grafana 这对组合,它们对机器健康情况、URL 访问统计、QPS、P90、P99 等等这些需求,支持得非常好,它们用来做监控大屏是非常合适的,但是通常不能帮助我们排查问题,它看到的是系统压力高了、系统不行了,但不能一下子看出来为啥高了、为啥不行了。
科普:Prometheus 是一个使用内存进行存储和计算的服务,每个机器/应用通过 Prometheus 的接口上报数据,它的特点是快,但是机器宕机或重启会丢失所有数据。
Grafana 是一个好玩的东西,它通过各种插件来可视化各种系统数据,比如查询 Prometheus、ElasticSearch、ClickHouse、MySQL 等等,它的特点就是酷炫,用来做监控大屏再好不过了。
Metrics 和 Traces
因为本文之后要介绍的我们开发的 Dog 系统从分类来说,侧重于 Metrics,同时我们也提供 tracing 功能,所以这里单独写一小节,分析一下 Metrics 和 Traces 系统之间的联系和区别。
使用上的区别很好理解,Metrics 做的是数据统计,比如某个 URL 或 DB 访问被请求多少次,P90 是多少毫秒,错误数是多少等这种问题。而 Traces 是用来分析某次请求,它经过了哪些链路,比如进入 A 应用后,调用了哪些方法,之后可能又请求了 B 应用,在 B 应用里面又调用了哪些方法,或者整个链路在哪个地方出错等这些问题。
不过在前面介绍 Traces 的时候,我们也发现这类系统也会做很多的统计工作,它也覆盖了很多的 Metrics 的内容。
所以大家先要有个概念,Metrics 和 Traces 之间的联系是非常紧密的,它们的数据结构都是一颗调用树,区别在于这颗树的枝干和叶子多不多。在 Traces 系统中,一个请求所经过的链路数据是非常全的,这样对排查问题的时候非常有用,但是如果要对 Traces 中的所有节点的数据做报表统计,将会非常地耗费资源,性价比太低。而 Metrics 系统就是面向数据统计而生的,所以树上的每个节点我们都会进行统计,所以这棵树不能太“茂盛”。
我们关心的其实是,哪些数据值得统计?首先是入口,其次是耗时比较大的地方,比如 db 访问、http 请求、redis 请求、跨服务调用等。当我们有了这些关键节点的统计数据以后,对于系统的健康监控就非常容易了。
我这里不再具体去介绍他们的区别,大家看完本文介绍的 Metrics 系统实现以后,再回来思考这个问题会比较好。
Dog 在设计上,主要是做一个 Metrics 系统,统计关键节点的数据,另外也提供 trace 的能力,不过因为我们的树不是很”茂盛“,所以链路上可能是断断续续的,中间会有很多缺失的地带,当然应用开发者也可以加入手动埋点来弥补。
Dog 因为是公司内部的监控系统,所以对于公司内部大家会使用到的中间件相对是比较确定的,不需要像开源的 APM 一样需要打很多点,我们主要实现了以下节点的自动打点:
http 入口:通过实现一个 Filter 来拦截所有的请求 MySQL: 通过 Mybatis Interceptor 的方式 Redis: 通过 javassist 增强 RedisTemplate 的方式 跨应用调用: 通过代理 feign client 的方式,dubbo、grpc 等方式可能需要通过拦截器 http 调用: 通过 javassist 为 HttpClient 和 OkHttp 增加 interceptor 的方式 Log 打点: 通过 plugin 的方式,将 log 中打印的 error 上报上来
打点的技术细节,就不在这里展开了,主要还是用了各个框架提供的一些接口,另外就是用到了 javassist 做字节码增强。
这些打点数据就是我们需要做统计的,当然因为打点有限,我们的 tracing 功能相对于专业的 Traces 系统来说单薄了很多。
Dog 简介
下面是 DOG 的架构图,客户端将消息投递给 Kafka,由 dog-server 来消费消息,存储用到了 Cassandra 和 ClickHouse,后面再介绍具体存哪些数据。
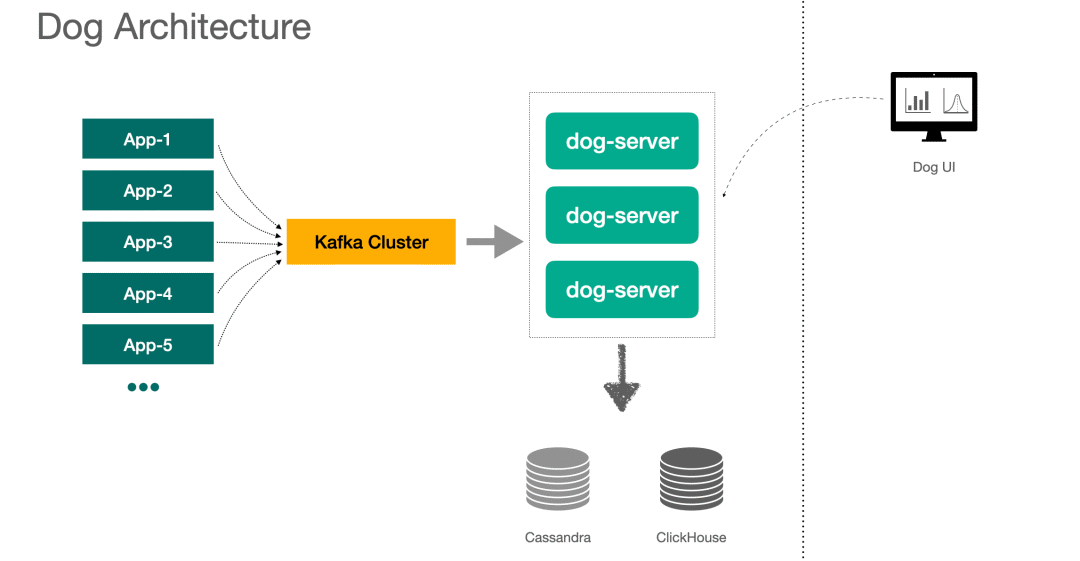
1、也有 APM 系统是不通过消息中间件的,比如 Cat 就是客户端通过 Netty 连接到服务端来发送消息的。
2、Server 端使用了 Lambda 架构模式,Dog UI 上查询的数据,由每一个 Dog-server 的内存数据和下游储存的数据聚合而来。
下面,我们简单介绍下 Dog UI 上一些比较重要的功能,我们之后再去分析怎么实现相应的功能。
注意:下面的图都是我自己画的,不是真的页面截图,数值上可能不太准确
下图示例 transaction 报表:
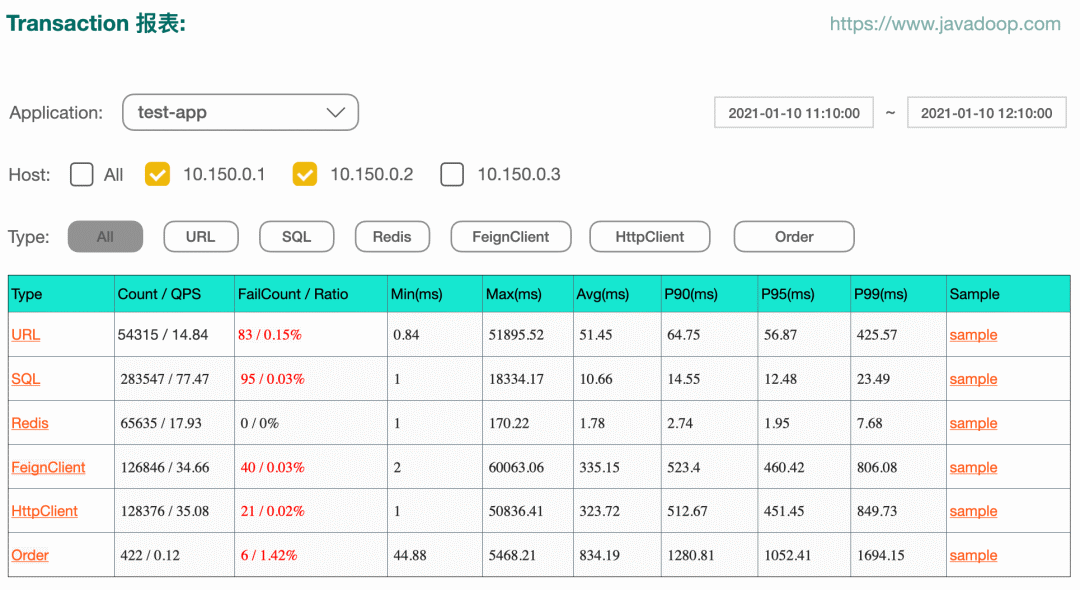
点击上图中 type 中的某一项,我们有这个 type 下面每个 name 的报表。比如点击 URL,我们可以得到每个接口的数据统计:

当然,上图中点击具体的 name,还有下一个层级 status 的统计数据,这里就不再贴图了。Dog 总共设计了 type、name、status 三级属性。上面两个图中的最后一列是 sample,它可以指引到 sample 视图:

Sample 就是取样的意思,当我们看到有个接口失败率很高,或者 P90 很高的时候,你知道出了问题,但因为它只有统计数据,所以你不知道到底哪里出了问题,这个时候,就需要有一些样本数据了。我们每分钟对 type、name、status 的不同组合分别保存最多 5 个成功、5 个失败、5 个慢处理的样本数据。
点击上面的 sample 表中的某个 T、F、L 其实就会进入到我们的 trace 视图,展示出这个请求的整个链路:
通过上面这个 trace 视图,可以非常快速地知道是哪个环节出了问题。当然,我们之前也说过,我们的 trace 依赖于我们的埋点丰富度,但是 Dog 是一个 Metrics 为主的系统,所以它的 Traces 能力是不够的,不过大部分情况下,对于排查问题应该是足够用的。
对于应用开发者来说,下面这个 Problem 视图应该是非常有用的:
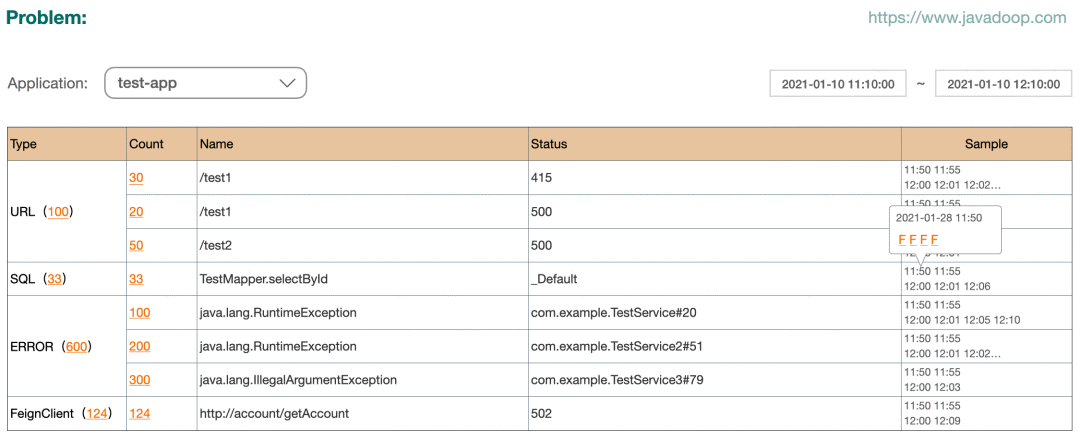
它展示了各种错误的数据统计,并且提供了 sample 让开发者去排查问题。
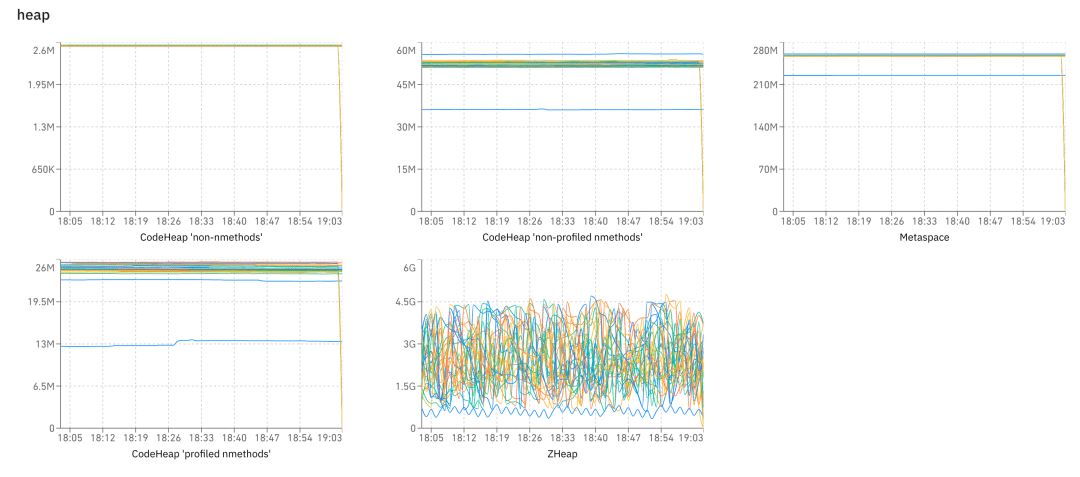
最后,我们再简单介绍下 Heartbeat 视图,它和前面的功能没什么关系,就是大量的图,我们有 gc、heap、os、thread 等各种数据,让我们可以观察到系统的健康情况。
这节主要介绍了一个 APM 系统通常包含哪些功能,其实也很简单对不对,接下来我们从开发者的角度,来聊聊具体的实现细节问题。
客户端数据模型
大家都是开发者,我就直接一些了,下图介绍了客户端的数据模型:

对于一条 Message 来说,用于统计的字段是 type, name, status,所以我们能基于 type、type+name、type+name+status 三种维度的数据进行统计。
Message 中其他的字段:timestamp 表示事件发生的时间;success 如果是 false,那么该事件会在 problem 报表中进行统计;data 不具有统计意义,它只在链路追踪排查问题的时候有用;businessData 用来给业务系统上报业务数据,需要手动打点,之后用来做业务数据分析。
Message 有两个子类 Event 和 Transaction,区别在于 Transaction 带有 duration 属性,用来标识该 transaction 耗时多久,可以用来做 max time, min time, avg time, p90, p95 等,而 event 指的是发生了某件事,只能用来统计发生了多少次,并没有时间长短的概念。
Transaction 有个属性 children,可以嵌套 Transaction 或者 Event,最后形成一颗树状结构,用来做 trace,我们稍后再介绍。
下面表格示例一下打点数据,这样比较直观一些:
简单介绍几点内容:
type 为 URL、SQL、Redis、FeignClient、HttpClient 等这些数据,属于自动埋点的范畴。通常做 APM 系统的,都要完成一些自动埋点的工作,这样应用开发者不需要做任何的埋点工作,就能看到很多有用的数据。像最后两行的 type=Order 属于手动埋点的数据。 打点需要特别注意 type、name、status 的维度“爆炸”,它们的组合太多会非常消耗资源,它可能会直接拖垮我们的 Dog 系统。type 的维度可能不会太多,但是我们可能需要注意开发者可能会滥用 name 和 status,所以我们一定要做 normalize(如 url 可能是带动态参数的,需要格式化处理一下)。 表格中的最后两条是开发者手动埋点的数据,通常用来统计特定的场景,比如我想知道某个方法被调用的情况,调用次数、耗时、是否抛异常、入参、返回值等。因为自动埋点是业务不想关的,冷冰冰的数据,开发者可能想要埋一些自己想要统计的数据。 开发者在手动埋点的时候,还可以上报更多的业务相关的数据上来,参考表格最后一列,这些数据可以做业务分析来用。比如我是做支付系统的,通常一笔支付订单会涉及到非常多的步骤(国外的支付和大家平时使用的微信、支付宝稍微有点不一样),通过上报每一个节点的数据,最后我就可以在 Dog 上使用 bizId 来将整个链路串起来,在排查问题的时候是非常有用的(我们在做支付业务的时候,支付的成功率并没有大家想象的那么高,很多节点可能出问题)。
客户端设计
上一节我们介绍了单条 message 的数据,这节我们覆盖一下其他内容。
首先,我们介绍客户端的 API 使用:
public void test() {
Transaction transaction = Dog.newTransaction("URL", "/test/user");
try {
Dog.logEvent("User", "name-xxx", "status-yyy");
// do something
Transaction sql = Dog.newTransaction("SQL", "UserMapper.insert");
// try-catch-finally
transaction.setStatus("xxxx");
transaction.setSuccess(true/false);
} catch (Throwable throwable) {
transaction.setSuccess(false);
transaction.setData(Throwables.getStackTraceAsString(throwable));
throw throwable;
} finally {
transaction.finish();
}
}
上面的代码示例了如何嵌套使用 Transaction 和 Event,当最外层的 Transaction 在 finally 代码块调用 finish() 的时候,完成了一棵树的创建,进行消息投递。
我们往 Kafka 中投递的并不是一个 Message 实例,因为一次请求会产生很多的 Message 实例,而是应该组织成 一个 Tree 实例以后进行投递。下图描述 Tree 的各个属性:
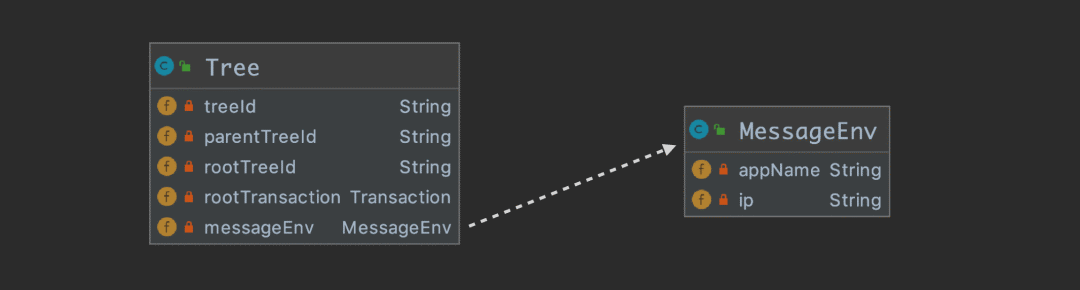
Tree 的属性很好理解,它持有 root transaction 的引用,用来遍历整颗树。另外就是需要携带机器信息 messageEnv。
treeId 应该有个算法能保证全局唯一,简单介绍下 Dog 的实现:{encode(ip)}-{自增id}。
下面简单介绍几个 tree id 相关的内容,假设一个请求从 A->B->C->D 经过 4 个应用,A 是入口应用,那么会有:
1、总共会有 4 个 Tree 对象实例从 4 个应用投递到 Kafka,跨应用调用的时候需要传递 treeId, parentTreeId, rootTreeId 三个参数;
2、A 应用的 treeId 是所有节点的 rootTreeId;
3、B 应用的 parentTreeId 是 A 的 treeId,同理 C 的 parentTreeId 是 B 应用的 treeId;
4、在跨应用调用的时候,比如从 A 调用 B 的时候,为了知道 A 的下一个节点是什么,所以在 A 中提前为 B 生成 treeId,B 收到请求后,如果发现 A 已经为它生成了 treeId,直接使用该 treeId。
大家应该也很容易知道,通过这几个 tree id,我们是想要实现 trace 的功能。
介绍完了 tree 的内容,我们再简单讨论下应用集成方案。
集成无外乎两种技术,一种是通过 javaagent 的方式,在启动脚本中,加上相应的 agent,这种方式的优点是开发人员无感知,运维层面就可以做掉,当然开发者如果想要手动做一些埋点,可能需要再提供一个简单的 client jar 包给开发者,用来桥接到 agent 里。另一种就是提供一个 jar 包,由开发者来引入这个依赖。
两种方案各有优缺点,Pinpoint 和 Skywalking 使用的是 javaagent 方案,Zipkin、Jaeger、Cat 使用的是第二种方案,Dog 也使用第二种手动添加依赖的方案。
通常来说,做 Traces 的系统选择使用 javaagent 方案比较省心,因为这类系统 agent 做完了所有需要的埋点,无需应用开发者感知。
最后,我再简单介绍一下 Heartbeat 的内容,这部分内容其实最简单,但是能做出很多花花绿绿的图表出来,可以实现面向老板编程。
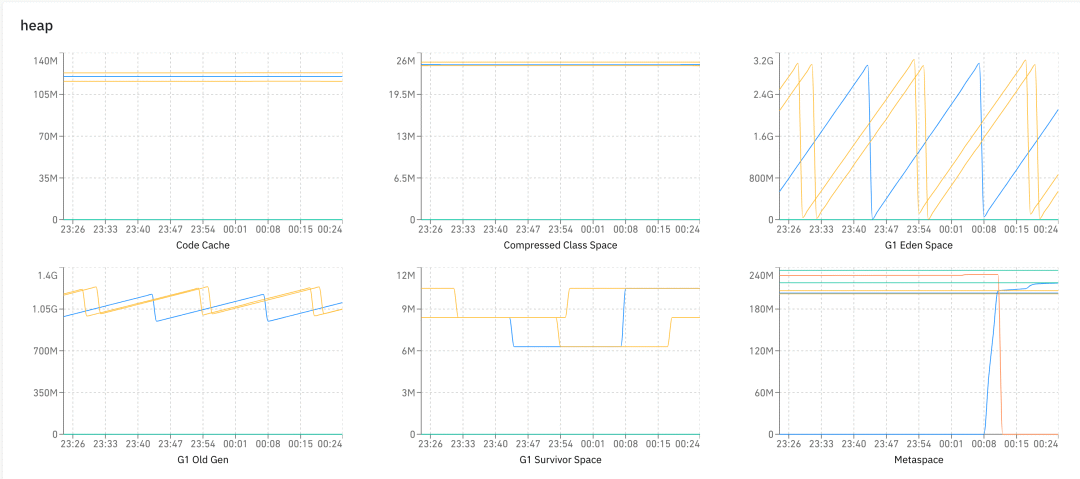
前面我们介绍了 Message 有两个子类 Event 和 Transaction,这里我们再加一个子类 Heartbeat,用来上报心跳数据。
我们主要收集了 thread、os、gc、heap、client 运行情况(产生多少个 tree,数据大小,发送失败数)等,同时也提供了 api 让开发者自定义数据进行上报。Dog client 会开启一个后台线程,每分钟运行一次 Heartbeat 收集程序,上报数据。
再介绍细一些。核心结构是一个 Map\<String, Double>,key 类似于 “os.systemLoadAverage”, “thread.count” 等,前缀 os,thread,gc 等其实是用来在页面上的分类,后缀是显示的折线图的名称。
关于客户端,这里就介绍这么多了,其实实际编码过程中,还有一些细节需要处理,比如如果一棵树太大了要怎么处理,比如没有 rootTransaction 的情况怎么处理(开发者只调用了 Dog.logEvent(...)),比如内层嵌套的 transaction 没有调用 finish 怎么处理等等。
Dog server 设计
下图示例了 server 的整体设计,值得注意的是,我们这里对线程的使用非常地克制,图中只有 3 个工作线程。

首先是 Kafka Consumer 线程,它负责批量消费消息,从 kafka 集群中消费到的是一个个 Tree 的实例,接下来考虑怎么处理它。
在这里,我们需要将树状结构的 message 铺平,我们把这一步叫做 deflate,并且做一些预处理,形成下面的结构:
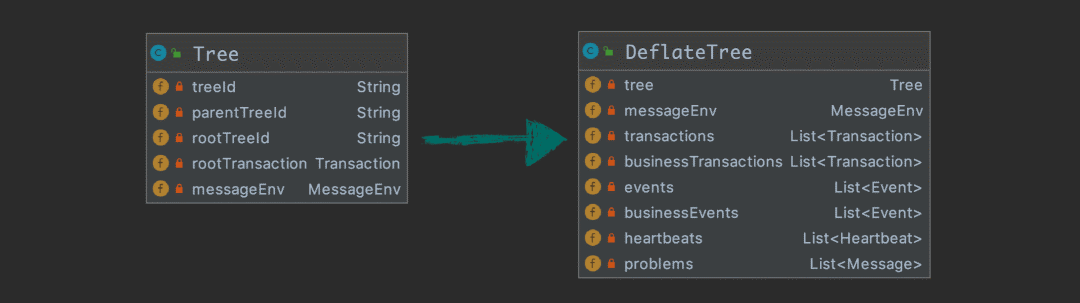
接下来,我们就将 DeflateTree 分别投递到两个 Disruptor 实例中,我们把 Disruptor 设计成单线程生产和单线程消费,主要是性能上的考虑。消费线程根据 DeflateTree 的属性使用绑定好的 Processor 进行处理,比如 DeflateTree 中 List<Message> problmes 不为空,同时自己绑定了 ProblemProcessor,那么就需要调用 ProblemProcessor 来处理。
科普时间:Disruptor 是一个高性能的队列,性能比 JDK 中的 BlockingQueue 要好
这里我们使用了 2 个 Disruptor 实例,当然也可以考虑使用更多的实例,这样每个消费线程绑定的 processor 就更少。我们这里把 Processor 绑定到了 Disruptor 实例上,其实原因也很简单,为了性能考虑,我们想让每个 processor 只有单线程使用它,单线程操作可以减少线程切换带来的开销,可以充分利用到系统缓存,以及在设计 processor 的时候,不用考虑并发读写的问题。
这里要考虑负载均衡的情况,有些 processor 是比较耗费 CPU 和内存资源的,一定要合理分配,不能把压力最大的几个任务分到同一个线程中去了。
核心的处理逻辑都在各个 processor 中,它们负责数据计算。接下来,我把各个 processor 需要做的主要内容介绍一下,毕竟能看到这里的开发者,应该真的是对 APM 的数据处理比较感兴趣的。
Transaction processor
transaction processor 是系统压力最大的地方,它负责报表统计,虽然 Message 有 Transaction 和 Event 两个主要的子类,但是在实际的一颗树中,绝大部分的节点都是 transaction 类型的数据。
下图是 transaction processor 内部的一个主要的数据结构,最外层是一个时间,我们用分钟时间来组织,我们最后在持久化的时候,也是按照分钟来存的。第二层的 HostKey 代表哪个应用以及哪个 ip 来的数据,第三层是 type、name、status 的组合。最内层的 Statistics 是我们的数据统计模块。

另外我们也可以看到,这个结构到底会消耗多少内存,其实主要取决于我们的 type、name、status 的组合也就是 ReportKey 会不会很多,也就是我们前面在说客户端打点的时候,要避免维度爆炸。
最外层结构代表的是时间的分钟表示,我们的报表是基于每分钟来进行统计的,之后持久化到 ClickHouse 中,但是我们的使用者在看数据的时候,可不是一分钟一分钟看的,所以需要做数据聚合,下面展示两条数据是如何做聚合的,在很多数据的时候,都是按照同样的方法进行合并。

你仔细想想就会发现,前面几个数据的计算都没毛病,但是 P90, P95 和 P99 的计算是不是有点欺骗人啊?其实这个问题是真的无解的,我们只能想一个合适的数据计算规则,然后我们再想想这种计算规则,可能算出来的值也是差不多可用的就好了。
另外有一个细节问题,我们需要让内存中的数据提供最近 30 分钟的统计信息,30 分钟以上的才从 DB 读取。然后做上面介绍的 merge 操作。
讨论:我们是否可以丢弃一部分实时性,我们每分钟持久化一次,我们读取的数据都是从 DB 来的,这样可行吗?
不行,因为我们的数据是从 kafka 消费来的,本身就有一定的滞后性,我们如果在开始一分钟的时候就持久化上一分钟的数据,可能之后还会收到前面时间的消息,这种情况处理不了。
比如我们要统计最近一小时的情况,那么就会有 30 分钟的数据从各个机器中获得,有 30 分钟的数据从 DB 获得,然后做合并。
这里值得一提的是,在 transaction 报表中,count、failCount、min、max、avg 是比较好算的,但是 P90、P95、P99 其实不太好算,我们需要一个数组结构,来记录这一分钟内所有的事件的时间,然后进行计算,我们这里讨巧使用了 Apache DataSketches,它非常好用,这里我就不展开了,感兴趣的同学可以自己去看一下。
到这里,大家可以去想一想储存到 ClickHouse 的数据量的问题。app_name、ip、type、name、status 的不同组合,每分钟一条数据。
Sample Processor
sample processor 消费 deflate tree 中的 List<Transaction> transactions 和 List<Event> events 的数据。
我们也是按照分钟来采样,最终每分钟,对每个 type、name、status 的不同组合,采集最多 5 个成功、5 个失败、5 个慢处理。
相对来说,这个还是非常简单的,它的核心结构如下图:

结合 Sample 的功能来看比较容易理解:
Problem Processor
在做 deflate 的时候,所有 success=false 的 Message,都会被放入 List<Message> problmes 中,用来做错误统计。
Problem 内部的数据结构如下图:

大家看下这个图,其实也就知道要做什么了,我就不啰嗦了。其中 samples 我们每分钟保存 5 个 treeId。
顺便也再展示下 Problem 的视图:
关于持久化,我们是存到了 ClickHouse 中,其中 sample 用逗号连接成一个字符串,problem_data 的列如下:
event_date, event_time, app_name, ip, type, name, status, count, sample
Heartbeat processor
Heartbeat 处理 List<Heartbeat> heartbeats 的数据,题外话,正常情况下,一颗树里面只有一个 Heartbeat 实例。
前面我也简单提到了一下,我们 Heartbeat 中用来展示图表的核心数据结构是一个 Map<String, Double> 。
收集到的 key-value 数据如下所示:
{
"os.systemLoadAverage": 1.5,
"os.committedVirtualMemory": 1234562342,
"os.openFileDescriptorCount": 800,
"thread.count": 600,
"thread.httpThreadsCount": 250,
"gc.ZGC Count": 234,
"gc.ZGC Time(ms)": 123435,
"heap.ZHeap": 4051233219,
"heap.Metaspace": 280123212
}
前缀是分类,后缀是图的名称。客户端每分钟收集一次数据进行上报,然后就可以做很多的图了,比如下图展示了在 heap 分类下的各种图:
Heartbeat processor 要做的事情很简单,就是数据存储,Dog UI 上的数据是直接从 ClickHouse 中读取的。
heartbeat_data 的列如下:
event_date, event_time, timestamp, app_name, ip, name, value
MessageTree Processor
前面我们多次提到了 Sample 的功能,这些采样的数据帮助我们恢复现场,这样我们可以通过 trace 视图来跟踪调用链。
要做上面的这个 trace 视图,我们需要上下游的所有的 tree 的数据,比如上图是 3 个 tree 实例的数据。
之前我们在客户端介绍的时候说过,这几个 tree 通过 parent treeId 和 root treeId 来组织。
要做这个视图,给我们提出的挑战就是,我们需要保存全量的数据。
大家可以想一想这个问题,为啥要保存全量数据,我们直接保存被 sample 到的数据不就好了吗?
这里我们用到了 Cassandra 的能力,Cassandra 在这种 kv 的场景中,有非常不错的性能,而且它的运维成本很低。
我们以 treeId 作为主键,另外再加 data 一个列即可,它是整个 tree 的实例数据,数据类型是 blob,我们会先做一次 gzip 压缩,然后再扔给 Cassandra。
Business Processor
我们在介绍客户端的时候说过,每个 Message 都可以携带 Business Data,不过只有应用开发者自己手动埋点的时候才会有,当我们发现有业务数据的时候,我们会做另一个事情,就是把这个数据存储到 ClickHouse 中,用来做业务分析。
我们其实不知道应用开发者到底会把它用在什么场景中,因为每个人负责的项目都不一样,所以我们只能做一个通用的数据模型。
回过头来看这个图,BusinessData 中我们定义了比较通用的 userId 和 bizId,我们认为它们可能是每个业务场景会用到的东西。userId 就不用说了,bizId 大家可以做来记录订单 id,支付单 id 等。
然后我们提供了 3 个 String 类型的列 ext1、ext2、ext3 和两个数值类型的列 extVal1 和 extVal2,它们可以用来表达你的业务相关的参数。
我们的处理当然也非常简单,将这些数据存到 ClickHouse 中就可以了,表中主要有这些列:
event_data, event_time, user, biz_id, timestamp, type, name, status, app_name、ip、success、ext1、ext2、ext3、ext_val1、ext_val2
这些数据对我们 Dog 系统来说肯定不认识,因为我们也不知道你表达的是什么业务,type、name、status 是开发者自己定义的,ext1, ext2, ext3 分别代表什么意思,我们都不知道,我们只负责存储和查询。
这些业务数据非常有用,基于这些数据,我们可以做很多的数据报表出来。因为本文是讨论 APM 的,所以该部分内容就不再赘述了。
其他
ClickHouse 需要批量写入,不然肯定是撑不住的,一般一个 batch 至少 10000 行数据。
我们在 Kafka 这层控制了,一个 app_name + ip 的数据,只会被同一个 dog-server 消费,当然也不是说被多个 dog-server 消费会有问题,但是这样写入 ClickHouse 的数据就会更多。
还有个关键的点,前面我们说了每个 processor 是由单线程进行访问的,但是有一个问题,那就是来自 Dog UI 上的请求可怎么办?这里我想了个办法,那就是将请求放到一个 Queue 中,由 Kafka Consumer 那个线程来消费,它会将任务扔到两个 Disruptor 中。比如这个请求是 transaction 报表请求,其中一个 Disruptor 的消费者会发现这个是自己要干的,就会去执行这个任务。
小结
如果你了解 Cat 的话,可以看到 Dog 在很多地方和 Cat 有相似之处,或者直接说”抄“也行,之前我们也考虑过直接使用 Cat 或者在 Cat 的基础上做二次开发。但是我看完 Cat 的源码后,就放弃了这个想法,仔细想想,只是借鉴 Cat 的数据模型,然后我们自己写一套 APM 其实不是很难,所以有了我们这个项目。
行文需要,很多地方我都避重就轻,因为这不是什么源码分析的文章,没必要处处谈细节,主要是给读者一个全貌,读者能通过我的描述大致想到需要处理哪些事情,需要写哪些代码,那就当我表述清楚了。
 觉得不错,请点个在看呀
觉得不错,请点个在看呀