
每日一题:树模型为什么不需要归一化?
关注"Python学习与数据挖掘",
设为“置顶或星标”,第一时间送达干货
树模型为什么不需要归一化?
既然树形结构(如决策树、RF)不需要归一化,那为何非树形结构比如Adaboost、SVM、LR、Knn、KMeans之类则需要归一化呢?
对于线性模型,特征值差别很大时,比如说LR,我有两个特征,一个是(0,1)的,一个是(0,10000)的,运用梯度下降的时候,损失等高线是椭圆形,需要进行多次迭代才能到达最优点。
但是如果进行了归一化,那么等高线就是圆形的,促使SGD往原点迭代,从而导致需要的迭代次数较少。
除了归一化,我们还会经常提到标准化,那到底什么是标准化和归一化呢?
标准化:特征均值为0,方差为1
公式:
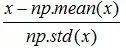
归一化:把每个特征向量(特别是奇异样本数据)的值都缩放到相同数值范围,如[0,1]或[-1,1]。
最常用的归一化形式就是将特征向量调整为L1范数(就是绝对值相加),使特征向量的数值之和为1。
而L2范数就是欧几里得之和。
data_normalized = preprocessing.normalize( data , norm="L1" )
公式:
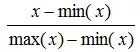
每日一题精选常考面试题,利用零碎时间为职业保驾护航,建议大家独立思考答题。
(长按三秒,即可进入)
后台已放置一份精心整理的技术干货,查看即可获取! 后台回复关键字:进群,带你进入高手如云的交流群! 推荐阅读
评论