
请你实现一个 npm install
现在写代码我们一般不会全部自己实现,更多是基于第三方的包来进行开发,这体现在目录上就是 src 和 node_modules 目录。
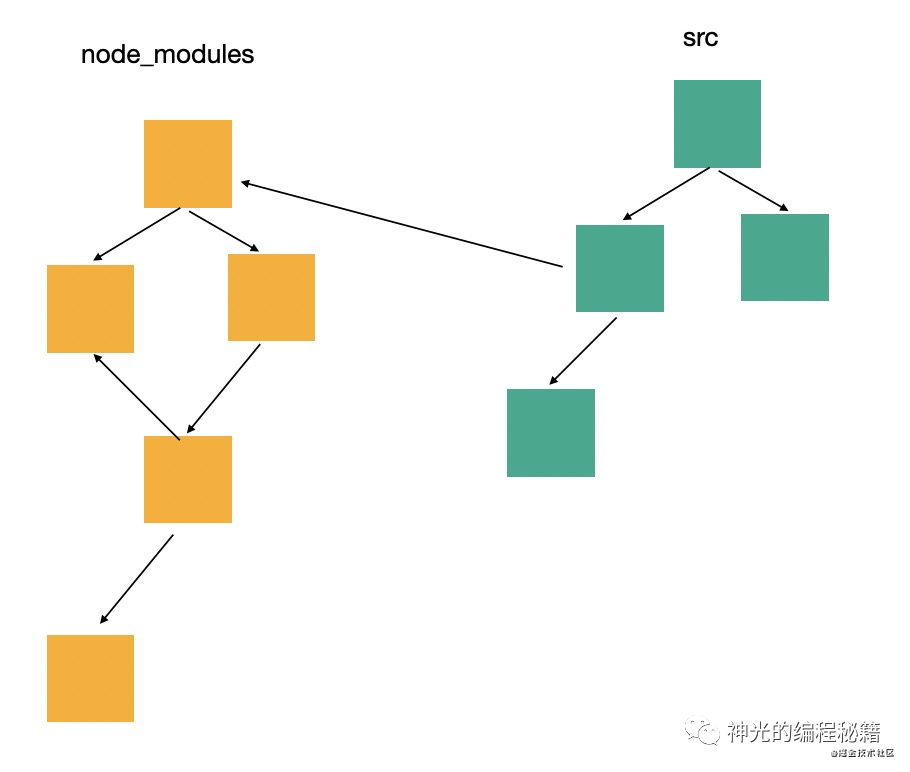
src 和 node_modules(第三方包) 的比例不同项目不一样。
运行时查找第三方包的方式也不一样:
在 node 环境里面,运行时就支持 node_modules 的查找。所以只需要部署 src 部分,然后安装相关的依赖。
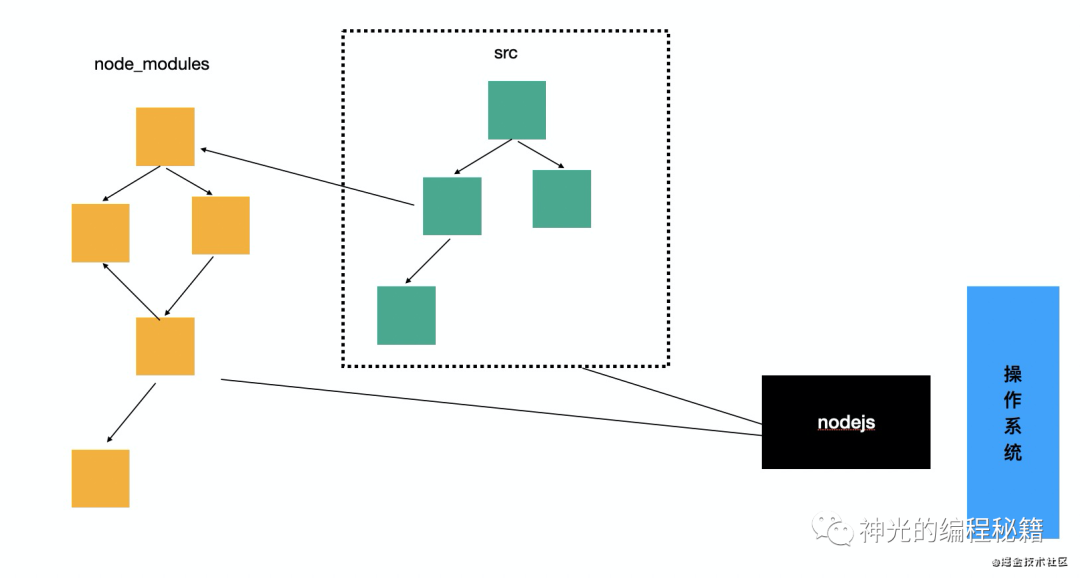
在浏览器环境里面不支持 node_modules,需要把它们打包成浏览器支持的形式。
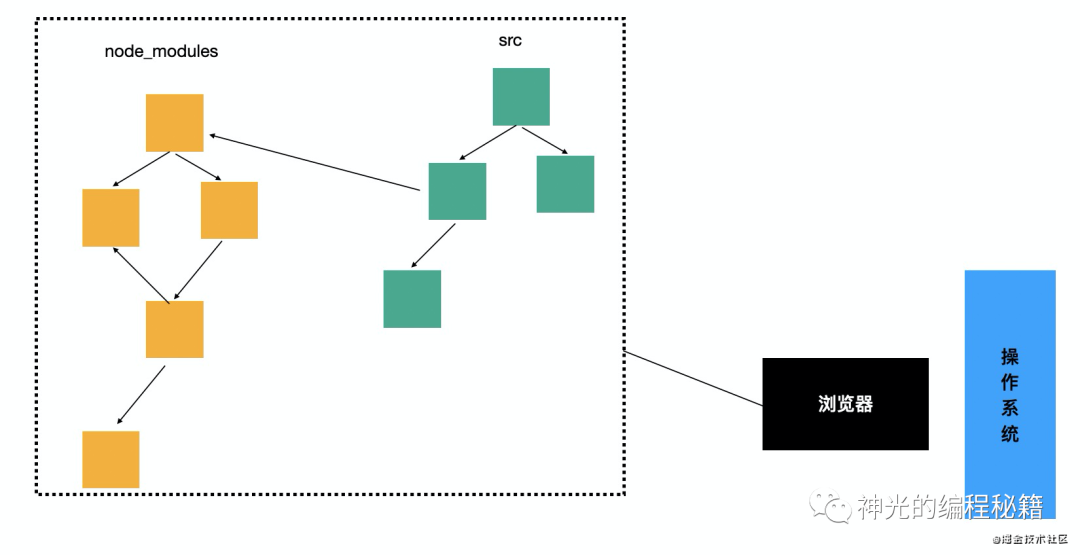
跨端环境下,它是上面哪一种呢?
都不是,不同跨端引擎的实现会有不同,跨端引擎会实现 require,可以运行时查找模块(内置的和第三方的),但是不是 node 的查找方式,是自己的一套。
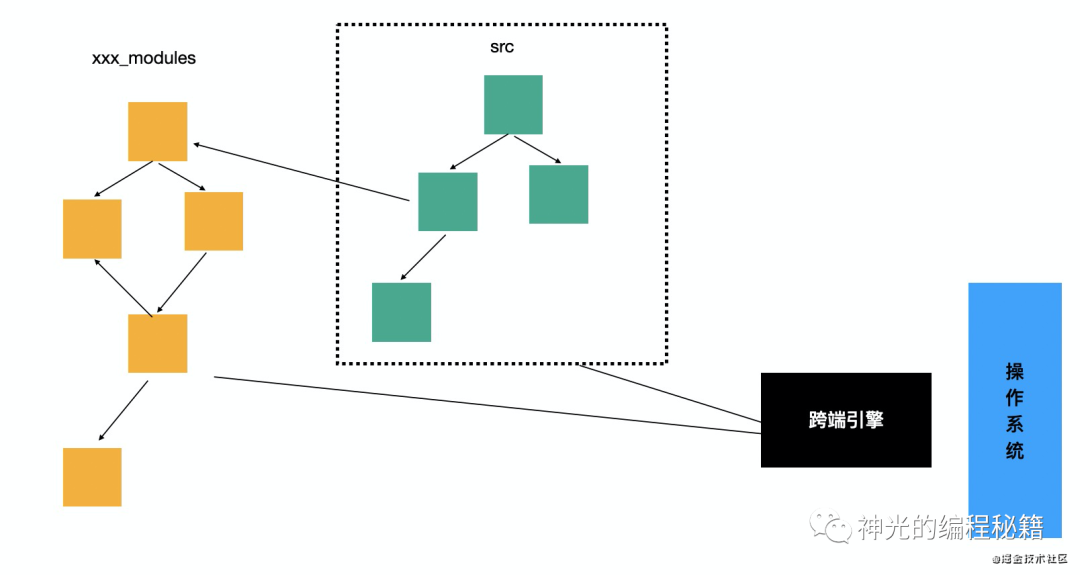
和 node 环境下的模块查找类似,但是目录结构不一样,所以需要自己实现 xxx install。
思路分析
npm 是有自己的 registry server 来支持 release 的包的下载,下载时是从 registry server 上下载。我们自己实现的话没必要实现这一套,直接用 git clone 从 gitlab 上下载源码即可。
依赖分析
要实现下载就要先确定哪些要下载,确定依赖的方式和打包工具不同:
打包工具通过 AST 分析文件内容确定依赖关系,进行打包 依赖安装工具通过用户声明的依赖文件 (package.json / bundle.json)来确定依赖关系,进行安装
这里我们把包的描述文件叫做 bundle.json,其中声明依赖的包:
{
"name": "xxx",
"dependencies": {
"yyyy": "aaaa/bbbb#release/1111"
}
}
通过分析项目根目录的 bundle.json 作为入口,下载每一个依赖,分析 bundle.json,然后继续下载每一个依赖项,递归这个过程。这就是依赖分析的过程。
这样依赖分析的过程中进行包的下载,依赖分析结束,包的下载也就结束了。这是一种可行的思路。
但是这种思路存在问题,比如:版本冲突怎么办?循环依赖怎么办?
解决版本冲突
版本冲突是多个包依赖了同一个包,但是依赖的版本不同,这时候就要选择一个版本来安装,我们可以简单的把规则定为使用高版本的那个。
解决循环依赖
包之间是可能有循环依赖的(这也是为什么叫做依赖图,而不是依赖树),这种问题的解决方式就是记录下处理过的包,如果同个版本的包被分析过,那么久不再进行分析,直接拿缓存。
这种思路是解决循环依赖问题的通用思路。
我们解决了版本冲突和循环依赖的问题,还有没有别的问题?
版本冲突时会下载版本最高的包,但是这时候之前的低版本的包已经下载过了,那么就多了没必要的下载,能不能把这部分冗余下载去掉。
依赖分析和下载分离
多下载了一些低版本的包的原因是我们在依赖分析的过程中进行了下载,那么能不能依赖分析的时候只下载 bundle.json 来做分析,分析完确定了依赖图之后再去批量下载依赖?
从 gitlab 上只下载 bundle.json 这一个文件需要通过 ssh 协议来下载,略微复杂,我们可以用一种更简单的思路来实现:
git clone --depth=1 --branch=bb xxx
加上 --depth 以后 git clone 只会下载单个 commit,速度会很快,虽然比不上只下载 bundle.json,但是也是可用的(我试过下载全部 commit 要 20s 的时候,下载单个 commit 只要 1s)。
这样我们在依赖分析的时候只下载一个 commit 到临时目录,分析依赖、解决冲突,确定了依赖图之后,再去批量下载,这时候用 git clone 下载全部的 commit。最后要把临时目录删除。
这样,通过分离依赖分析和下载,我们去掉了没必要的一些低版本包的下载。下载速度会得到一些提升。
全局缓存
当本地有多个项目的时候,每个项目都是独立下载自己的依赖包的,这样对于一些公用的包会存在重复下载,解决方式是全局缓存。
分析完依赖进行下载每一个依赖包的时候,首先查找全局有没有这个包,如果有的话,直接复制过来,拉取下最新代码。如果没有的话,先下载到全局,然后复制到本地目录。
通过多了一层全局缓存,我们实现了跨项目的依赖包复用。
代码实现
为了思路更清晰,下面会写伪代码
依赖分析
依赖分析会递归处理 bundle.json,分析依赖并下载到临时目录,记录分析出的依赖。会解决版本冲突、循环依赖问题。
const allDeps = {};
function installDeps(projectDir) {
const bundleJsonPath = path.resolve(projectDir, 'bundle.json');
const bundleInfo = JSON.parse(fs.readFileSync(bundleJsonPath));
const bundleDeps = bundleInfo.dependencies;
for (let depName in bundleDeps) {
if(allDeps[depName]) {
if (allDeps[depName] 和 bundleDeps[depName] 分支和版本一样) {
continue;// 跳过安装
}
if (allDeps[depName] 和 bundleDeps[depName] 分支和版本不一样){
if (bundleDeps[depName] 版本 < allDeps[depName] 版本 ) {
continue;
} else {
// 记录下版本冲突
allDeps[depName].conflit = true;
}
}
}
childProcess.exec(`git clone --depth=1 ${临时目录/depName}`);
allDeps[depName] = {
name: depName
url: xxx
branch: xxx
version: xxx
}
installDeps(`${临时目录/depName}`);
}
}
下载
下载会基于上面分析出的 allDeps 批量下载依赖,首先下载到全局缓存目录,然后复制到本地。
function batchInstall(allDeps) {
allDeps.forEach(dep => {
const 全局目录 = path.resolve(os.homedir(), '.xxx');
if (全局目录/dep.name 存在) {
// 复制到本地
childProcess.exec(`cp 全局目录/dep.name 本地目录/dep.name`);
} else {
// 下载到全局
childProcess.exec(`git clone --depth=1 ${全局目录/dep.name}`);
// 复制到本地
childProcess.exec(`cp 全局目录/dep.name 本地目录/dep.name`);
}
});
}
这样,我们就完成了依赖的分析和下载,实现了全局缓存。
总结
我们首先梳理了不同环境(浏览器、node、跨端引擎)对于第三方包的处理方式不同,浏览器需要打包,node 是运行时查找,跨端引擎也是运行时查找,但是用自己实现的一套机制。
然后明确了打包工具确定依赖的方式是 AST 分析,而依赖下载工具则是基于包描述文件 bundl.json(package.json) 来分析。然后我们实现了递归的依赖分析,解决了版本冲突、循环依赖问题。
为了减少没必要的下载,我们做了依赖分析和下载的分离,依赖分析阶段只下载单个 commit,后续批量下载的时候才全部下载。下载方式没有实现 registry 的那套,而是直接从 gitlab 来 git clone。
为了避免多个项目的公共依赖的重复下载,我们实现了全局缓存,先下载到全局目录,然后再复制到本地。
npm install、yarn install 的实现流程细节会更多一些,但是整体流程类似。希望这篇文章能帮你梳理清楚思路:不同环境是怎么处理第三方包的,xxx install 的依赖分析和下载的流程是什么样的。