
浅谈Java SPI原理与其在JDBC/Flink中的应用
点击上方蓝色字体,选择“设为星标”




API vs SPI
API(Application Programming Interface)的概念对我们来说已经是见怪不怪了。在日常开发过程中,我们需要调用平台/框架提供的API,而我们的下游应用也需要调用上游提供的API。一句话:API站在应用的角度定义了功能如何实现。
但是,如果我们作为服务提供方,想要丰富现有的系统,加入一些原本不具备的相对完整的能力,若是直接hack代码的话,不仅要新建或改动很多API,还需要重新构建相关的模块,并且可能无法很好地保证新模块与旧有模块的统一性。而Java 6引入了SPI(Service Provider Interface,服务提供者接口),可以非常方便地帮助我们实现插件化开发。顾名思义,SPI仍然遵循基于接口编程的思想,服务提供方通过实现SPI定义的接口来扩展系统,SPI机制后续完成发现与注入的职责。也就是说,SPI是系统为第三方专门开放的扩展规范以及动态加载扩展点的机制。
API和SPI之间的不同可以藉由下图来说明。
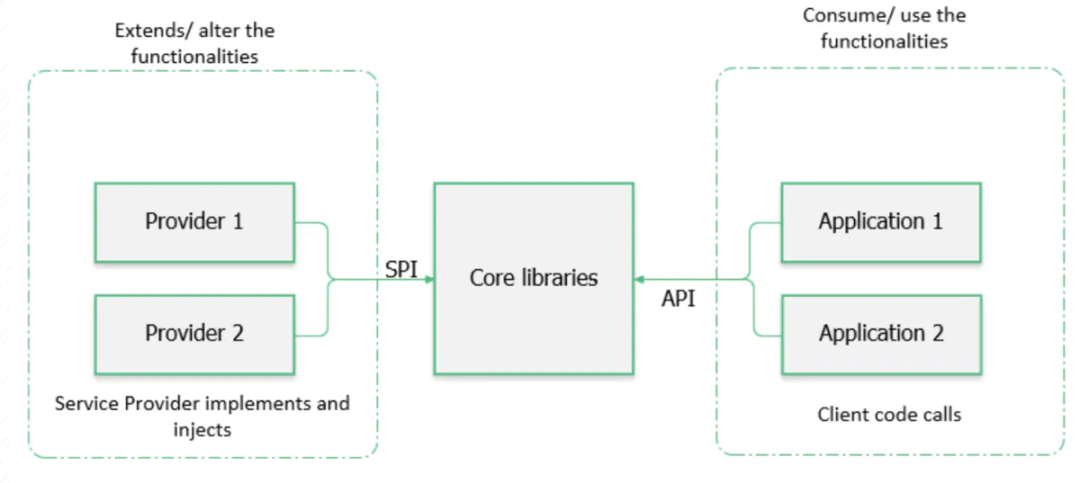
SPI实现原理
当我们作为服务提供方利用SPI机制时,需要遵循SPI的约定:
先编写好服务接口的实现类,即服务提供类;
然后在classpath的META-INF/services目录下创建一个以接口全限定名命名的UTF-8文本文件,并在该文件中写入实现类的全限定名(如果有多个实现类,以换行符分隔);
最后调用JDK中的java.util.ServiceLoader组件中的load()方法,就会根据上述文件来发现并加载具体的服务实现。简单看一下ServiceLoader的源码。首先列举几个重要的属性,注释写得很清楚,就不多废话了。
private static final String PREFIX = "META-INF/services/";
// The class or interface representing the service being loaded
private final Class service;
// The class loader used to locate, load, and instantiate providers
private final ClassLoader loader;
// The access control context taken when the ServiceLoader is created
private final AccessControlContext acc;
// Cached providers, in instantiation order
private LinkedHashMap providers = new LinkedHashMap<>();
// The current lazy-lookup iterator
private LazyIterator lookupIterator; 从load()方法开始向下追溯:
public static ServiceLoader load(Class service) {
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
public static ServiceLoader load(Class service,
ClassLoader loader)
{
return new ServiceLoader<>(service, loader);
}
private ServiceLoader(Class svc, ClassLoader cl) {
service = Objects.requireNonNull(svc, "Service interface cannot be null");
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
reload();
}
public void reload() {
providers.clear();
lookupIterator = new LazyIterator(service, loader);
}LazyIterator是一个懒加载服务提供类的迭代器(ServiceLoader本身也是实现了Iterable接口的),维护在lookupIterator中。在实际应用中,我们需要调用ServiceLoader#iterator()方法获取加载到的服务提供类的结果,该方法的代码如下。
public Iterator iterator() {
return new Iterator() {
Iterator> knownProviders
= providers.entrySet().iterator();
public boolean hasNext() {
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
}
public S next() {
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
} 该方法返回一个标准的迭代器,先从缓存的providers容器中获取,若获取不到,再通过lookupIterator进行懒加载。内部类LazyIterator的部分相关代码如下。
private class LazyIterator implements Iterator {
Class service;
ClassLoader loader;
Enumeration configs = null;
Iterator pending = null;
String nextName = null;
private LazyIterator(Class service, ClassLoader loader) {
this.service = service;
this.loader = loader;
}
// Iterator.hasNext()方法直接调用了此方法
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
pending = parse(service, configs.nextElement());
}
nextName = pending.next();
return true;
}
// Iterator.next()方法直接调用了此方法
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
String cn = nextName;
nextName = null;
Class c = null;
try {
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service,
"Provider " + cn + " not found");
}
if (!service.isAssignableFrom(c)) {
fail(service,
"Provider " + cn + " not a subtype");
}
try {
S p = service.cast(c.newInstance());
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service,
"Provider " + cn + " could not be instantiated",
x);
}
throw new Error(); // This cannot happen
}
// ......
} 注意观察hasNextService()和nextService()两个方法:前者在前文所述SPI定义文件中逐个寻找对应的服务提供类并加载资源,后者则通过反射创建服务提供类的实例,并缓存下来,直到完成整个发现与注入的流程,所以是懒加载的。由此也可得知,SPI机制内部一定会遍历所有的扩展点并将它们全部加载(主要缺点)。
下面以JDBC和Flink为例简单说说SPI的实际应用。
JDBC中的SPI
JDBC是为用户通过Java访问数据库提供的统一接口,而数据库千变万化,因此借助SPI机制可以灵活地实现数据库驱动的插件化。
在使用旧版JDBC时,我们必须首先调用类似Class.forName("com.mysql.jdbc.Driver")的方法,通过反射来手动加载数据库驱动。但是在新版JDBC中已经不用写了,只需直接调用DriverManager.getConnection()方法即可获得数据库连接。看一下java.sql.DriverManager的静态代码块中调用的loadInitialDrivers()方法的部分代码:
private static void loadInitialDrivers() {
// ......
AccessController.doPrivileged(new PrivilegedAction() {
public Void run() {
ServiceLoader loadedDrivers = ServiceLoader.load(Driver.class);
Iterator driversIterator = loadedDrivers.iterator();
try{
while(driversIterator.hasNext()) {
driversIterator.next();
}
} catch(Throwable t) { }
return null;
}
});
// ......
} 可见是利用SPI机制来获取并加载驱动提供类(java.sql.Driver接口的实现类)。以MySQL JDBC驱动为例,在其META-INF/services目录下找到名为java.sql.Driver的文件:
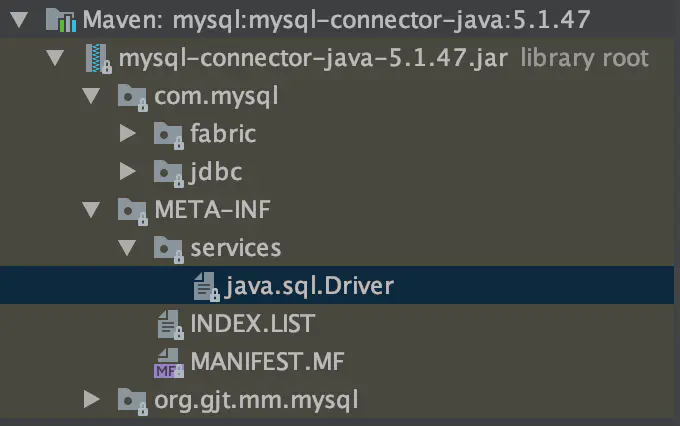
其内容是:
com.mysql.jdbc.Driver
com.mysql.fabric.jdbc.FabricMySQLDriver驱动类都会调用DriverManager#registerDriver()方法注册自身。如果加载了多个JDBC驱动类(比如MySQL、PostgreSQL等等),获取数据库连接时会遍历所有已经注册的驱动实例,逐个调用其connect()方法尝试是否能成功建立连接,并返回第一个成功的连接。具体可参看DriverManager#getConnection()方法。
Flink中的SPI
SPI机制在Flink的Table模块中也有广泛应用——因为Flink Table的类型有很多种,同样非常适合插件化。org.apache.flink.table.factories.TableFactory是Flink为我们提供的SPI工厂接口,在其注释中也说明了这一点。
/**
* A factory to create different table-related instances from string-based properties. This
* factory is used with Java's Service Provider Interfaces (SPI) for discovering. A factory is
* called with a set of normalized properties that describe the desired configuration. The factory
* allows for matching to the given set of properties.
*
* Classes that implement this interface can be added to the
* "META_INF/services/org.apache.flink.table.factories.TableFactory" file of a JAR file in
* the current classpath to be found.
*
* @see TableFormatFactory
*/
@PublicEvolving
public interface TableFactory {
Map requiredContext();
List supportedProperties();
}
以Flink-Hive Connector为例: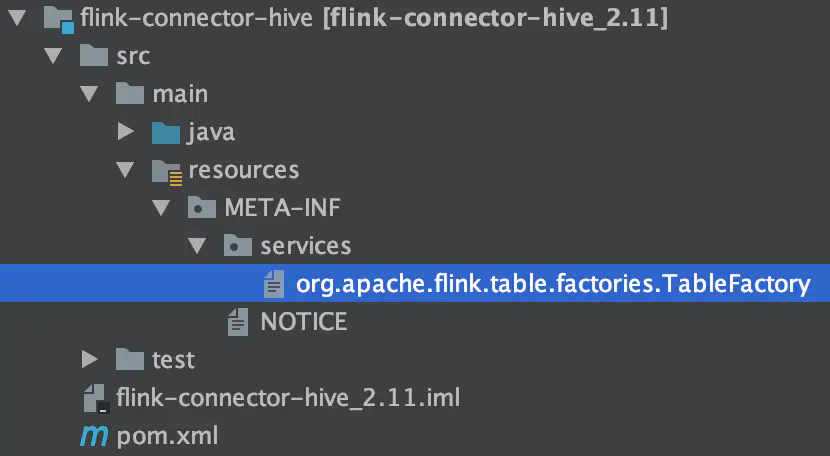
该文件的内容为:
org.apache.flink.table.catalog.hive.factories.HiveCatalogFactory
org.apache.flink.table.module.hive.HiveModuleFactory那么Flink是如何保证正确的TableFactory实现类被加载的呢?一路追踪方法调用链,来到TableFactoryService#findSingleInternal()方法。
private static T findSingleInternal(
Class factoryClass,
Map properties,
Optional classLoader) {
List tableFactories = discoverFactories(classLoader);
List filtered = filter(tableFactories, factoryClass, properties);
if (filtered.size() > 1) {
throw new AmbiguousTableFactoryException(
filtered,
factoryClass,
tableFactories,
properties);
} else {
return filtered.get(0);
}
} 其中,discoverFactories()方法用来发现并加载Table的服务提供类,filter()方法则用来过滤出满足当前应用需要的服务提供类。前者最终调用了ServiceLoader的相关方法,如下:
private static List discoverFactories(Optional classLoader) {
try {
List result = new LinkedList<>();
ClassLoader cl = classLoader.orElse(Thread.currentThread().getContextClassLoader());
ServiceLoader
.load(TableFactory.class, cl)
.iterator()
.forEachRemaining(result::add);
return result;
} catch (ServiceConfigurationError e) {
LOG.error("Could not load service provider for table factories.", e);
throw new TableException("Could not load service provider for table factories.", e);
}
} 

版权声明:
文章不错?点个【在看】吧! ?