
神经网络的初始化方法总结 | 又名“如何选择合适的初始化方法”
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
前言 本文介绍了为什么初始化很重要,总结了常用的几种初始化方法:全零或等值初始化、正态初始化、均匀初始化、Xavier初始化、He初始化和Pre-trained初始化,并介绍了几个还活跃的几个初始化方向:数据相关初始化、稀疏权重矩阵和随机正交矩阵初始化。
为什么初始化很重要
1. 全零或等值初始化
由于初始化的值全都相同,每个神经元学到的东西也相同,将导致“对称性(Symmetry)”问题。
2. 正态初始化(Normal Initialization)
均值为零,标准差设置一个小值。
这样的做好的好处就是有相同的偏差,权重有正有负。比较合理。
例:2012年AlexNet使用“均值为零、标准差设置为0.01、偏差为1的高斯(正常)噪声进行初始化”的初始化方法。然而,这种正常的随机初始化方法不适用于训练非常深的网络,尤其是那些使用 ReLU激活函数的网络,因为之前提到的梯度消失和爆炸问题。
3. 均匀初始化(Uniform Initialization)
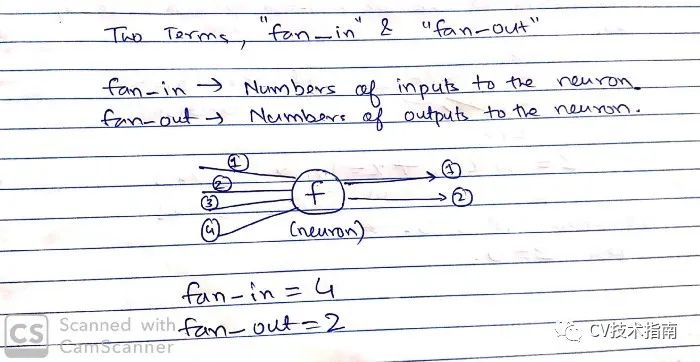
均匀分布的区间通常为【-1/sqrt(fan_in),1/sqrt(fan_in)】
其中fan_in表示输入神经元的数量,fan_out表示输出神经元的数量。
4. Xavier Initialization
来自论文《Understanding the difficulty of training deep feedforward neural networks》
根据sigmoid函数图像的特点
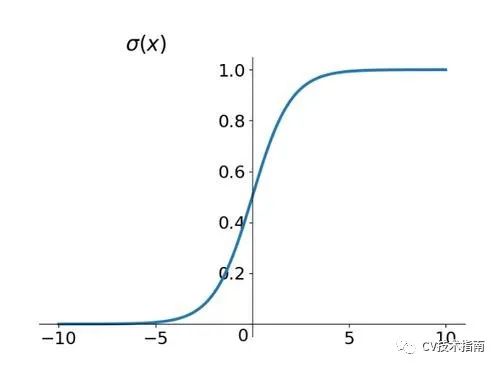
如果初始化值很小,那么随着层数的传递,方差就会趋于0,此时输入值也变得越来越小,在sigmoid上就是在0附近,接近于线性,失去了非线性。
如果初始值很大,那么随着层数的传递,方差会迅速增加,此时输入值变得很大,而sigmoid在大输入值写倒数趋近于0,反向传播时会遇到梯度消失的问题。
针对这个问题,Xavier 和 Bengio提出了“Xavier”初始化,它在初始化权重时考虑了网络的大小(输入和输出单元的数量)。这种方法通过使权重与前一层中单元数的平方根成反比来确保权重保持在合理的值范围内。
Xavier 的初始化有两种变体。
Xavier Normal:正态分布的均值为0、方差为sqrt( 2/(fan_in + fan_out) )。
Xavier Uniform:均匀分布的区间为【-sqrt( 6/(fan_in + fan_out)) , sqrt( 6/(fan_in + fan_out)) 】。
Xavier 初始化适用于使用tanh、sigmoid为激活函数的网络。
5. He Initialization
来自论文《Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification》
激活函数的选择最终在决定初始化方法的有效性方面发挥着重要作用。激活函数是可微的,并将非线性特性引入神经网络,这对于解决机器学习和深度学习旨在解决的复杂任务至关重要。ReLU和leaky ReLU是常用的激活函数,因为它们对消失/爆炸梯度问题相对鲁棒。
Xavier在tanh函数上表现可以,但对 ReLU 等激活函数效果不好,何凯明引入了一种更鲁棒的权重初始化方法--He Initialization。
He Initialization也有两种变体:
He Normal:正态分布的均值为0、方差为sqrt( 2/fan_in )。
He Uniform:均匀分布的区间为【-sqrt( 6/fan_in) , sqrt(6/fan_in) 】
He Initialization适用于使用ReLU、Leaky ReLU这样的非线性激活函数的网络。
He Initialization和Xavier Initialization 两种方法都使用类似的理论分析:它们为从中提取初始参数的分布找到了很好的方差。该方差适用于所使用的激活函数,并且在不明确考虑分布类型的情况下导出。
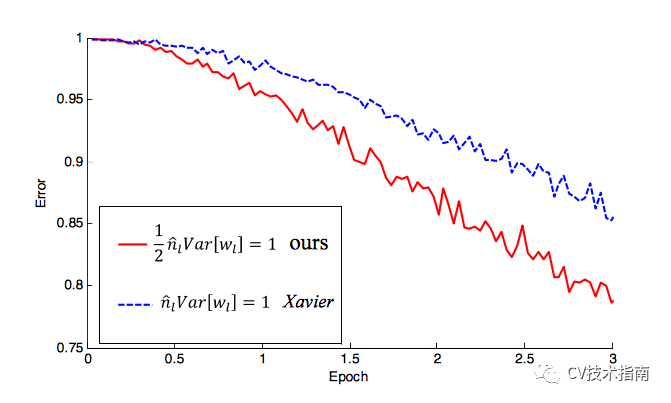
图来自何凯明的论文。
论文展示了何凯明改进的初始化策略(红色)如何比 (P)ReLU 的 Xavier 方法(蓝色)更快地降低错误率。
有关 Xavier 和 He 初始化方法的证明,请参阅 Pierre Ouannes 的文章《如何初始化深度神经网络?Xavier 和 Kaiming 初始化》。
文章链接:https://pouannes.github.io/blog/initialization/
6. Pre-trained
使用预训练的权重作为初始化,相比于其它初始化,收敛速度更快,起点更好。
除了以上的初始化方法外,还包括有LeCun Initialization。方法跟He Initialization和Xavier Initialization类似,但基本没怎么看见用,这里就不列出来了。
权重初始化仍然是一个活跃的研究领域。出现了几个有趣的研究项目,包括数据相关初始化、稀疏权重矩阵和随机正交矩阵初始化。
数据相关初始化
地址:https://arxiv.org/abs/1511.06856
稀疏权重矩阵初始化
地址:https://openai.com/blog/block-sparse-gpu-kernels/
随机正交矩阵初始化
地址:https://arxiv.org/abs/1312.6120
参考资料
1. https://medium.com/comet-ml/selecting-the-right-weight-initialization-for-your-deep-neural-network-780e20671b22
2. https://medium.com/analytics-vidhya/weights-initialization-in-neural-network-d962ac438bdb
3. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification He, K. et al. (2015)
4. Understanding the difficulty of training deep feedforward neural networks
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
