
掌门下一代容器发布系统 Triton
CD 平台是掌门的持续交付系统,Triton[1] 作为 CD 平台的核心容器发布组件,自 2020.4 月在 CD 平台上正式上线,支撑了掌门近 1000 个应用从虚机迁移至容器的过程,保障了虚机迁容器过程的稳定性。目前,Triton 除了提供日常的应用容器发布、网络策略配置、Ingress 域名配置等能力之外,也成为其他组件、平台的资源交付基座,比如,大规模的流水线交付[2],压测平台等。Triton 解决了应用生命周期管理的问题,包括开发、部署、运维等,同时打通了微服务治理,极大地帮助研发提升了持续交付的效率。
1. 背景
云原生架构的快速普及带来了企业基础设施和应用架构等技术层面的革新。在 CNCF 2020 年度中国区云原生调查报告里面有一个亮眼的数字,72% 的受访者已经在生产环境当中使用 Kubernetes,同期全球调查报告的数字是 83%。可以看到,在 Kubernetes 的使用率上,中国和全球是持平的。如果看纯容器使用率,则更加惊人,超过 92%。从这些数据来看,我们可以得出结论:Kubernetes 和容器已经完全进入主流市场,成为所有人都在使用的技术。
在此之前,掌门的应用一直跑在虚机里,但是随着应用规模的不断扩大,虚机数量也随之快速增加,我们开始在运维成本、交付效率、应用管理上面临一些痛点:
应用数量不断增加,基础设施的成本随之上升,降本迫在眉睫; 业务飞速发展,内部对资源、环境、应用的交付效率的要求不断提高; 应用数量增长很快,大量应用的管理给运维带来很大压力。
所以,为了能够充分发挥云原生的优势,灵活地应对变化和弹性扩展以提升开发效率,加速迭代并降低成本,掌门于 2020 年 4 月份正式启动容器化项目。
为了最大程度降低迁移容器过程中对开发和业务的影响,我们决定在应用发布中完成从虚机到容器的迁移,以保障迁移过程中服务的稳定性,实现不停服迁移。要实现这个目标,一个全新的、支持容器发布的平台呼之欲出,Triton 就是在这种背景下诞生的。下面将介绍容器发布平台 Triton 的设计原理、实现方案。
2. Triton 设计原理及实现方案
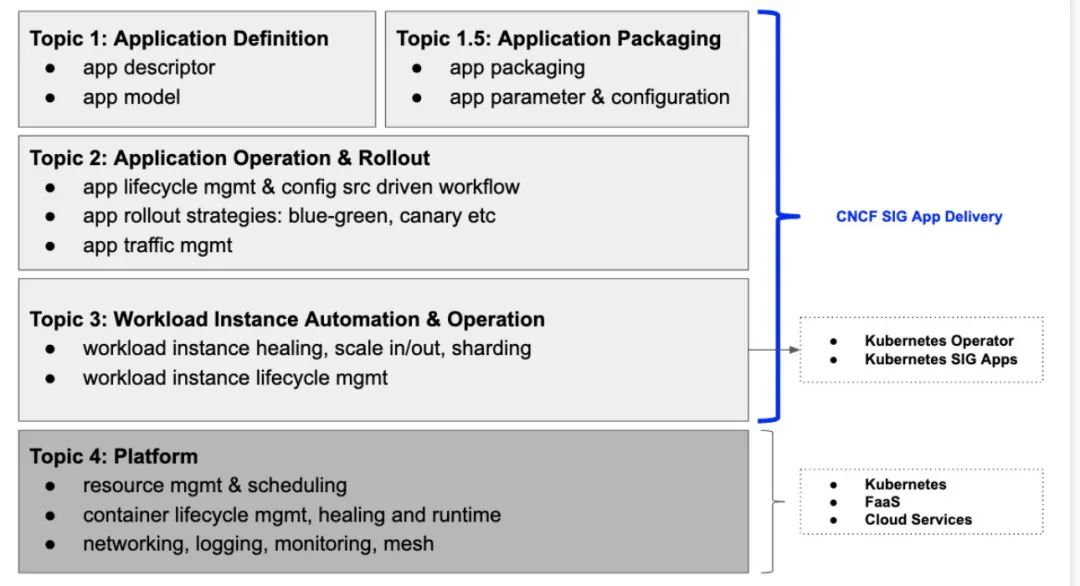
在介绍 Triton 之前我们先看一下 CNCF 对持续交付的定义,涵盖了一个云原生应用的全生命周期流程,图中的一些技术术语在本文中也会用到,比如 workload,rollout,canary等, 这篇文档[3] 中有详细的介绍,需要的话可以查阅。
同时通过这张图,也可以清晰地了解 Triton 在整个持续发布系统中的定位。Topic 1,Topic 1.5 的主要内容是应用模型描述,打包、参数配置;Topic 4 是资源管理,网络,日志/监控等平台侧的功能;而 Triton 聚焦的工作是在 Topic 2 和 Topic 3 ,主要内容是应用生命周期管理,流量管理,workload 管理,提供发布策略,比如蓝绿部署、金丝雀部署等。
了解了 Triton 的定位后,下面将从方案选型,架构设计,UI 交互 3 个维度来详细介绍 Triton 的设计原理和实现方案。
2.1 方案选型
2.1.1 workload 选型
众所周知,不管是无状态的 Deployment 还是有状态的 StatefulSet,kubernetes 都是支持服务的滚动更新的。我们也经常在一些文章中看到有基于原生 Deployment 实现应用的滚动发布和灰度发布,这种方式开发简单容易上手,但是随之带来了很多缺陷,使得我们无法细粒度控制发布的过程,比如不支持发布过程中暂停、继续,以及流量的优雅拉入拉出等能力。
为了实现更丰富的发布策略以及更加细粒度的发布控制,以保障容器发布过程的安全、稳定,Triton 选择 OpenKruise[4] 作为应用的 workload。OpenKruise 是 Kubernetes 的一个标准扩展,它可以配合原生 Kubernetes 使用,并为管理应用容器、sidecar、镜像分发等方面提供更加强大和高效的能力。OpenKruise 提供了很多原生 kubernetes 的增强型资源,CloneSet、Advanced StatefulSet、SidecarSet 等。其中,CloneSet 提供了更加高效、确定可控的应用管理和部署能力,支持优雅原地升级、指定删除、发布顺序可配置、并行/灰度发布等丰富的策略,可以满足更多样化的应用场景,所以 Triton 选择基于 CloneSet 来实现无状态应用的发布流程。
2.1.2 发布流程技术选型
如何定义一种发布流程,并按照流程的定义去实现本次发布?为了寻找一些灵感,在设计 Triton 之前我们调研了目前在云原生领域做得比较好的的一些 CI/CD 组件,像云原生 CI 工具 Tekton,交付工具 Argo 都是设计了一套 CRD (自定义资源),然后在 Operator 中实现相应的逻辑以达到最终的目标状态(Operator 是由 CoreOS 开发的,用来扩展 Kubernetes API,特定的应用程序控制器,其基于 Kubernetes 的资源和控制器概念之上构建,但同时又包含了应用程序特定的领域知识。创建 Operator 的关键是 CRD 的设计)。
于是我们采用云原生的方式设计容器发布,原生为云而设计,在云上运行,充分利用和发挥云平台的弹性+分布式优势。我们设计了一种 CRD 来描述一次容器发布的完整流程,这样每次发布只需要创建 CRD 资源,就能定义好本次的发布流程,后续只需要在此资源基础上修改即可。经过内部讨论,最终该 CRD 被命名为 DeployFlow,即发布流的意思,关于 DeployFlow 的详细介绍请继续阅读下面的架构设计。
2.2 架构设计
在解决了 workload 和发布流程的技术选型后,DeployFlow 这个 CRD 的设计就成为了我们要去聚焦的核心工作。下图展示了 Triton 的主要设计架构,可以看到在 Kubernetes 和 OpenKruise 的基础之上,完成一次发布需要的配置由 CRD 定义,发布流程相关的逻辑控制通过 Operator 实现,同时 Triton 提供 REST、GRPC API 和前端 UI 实现交互。
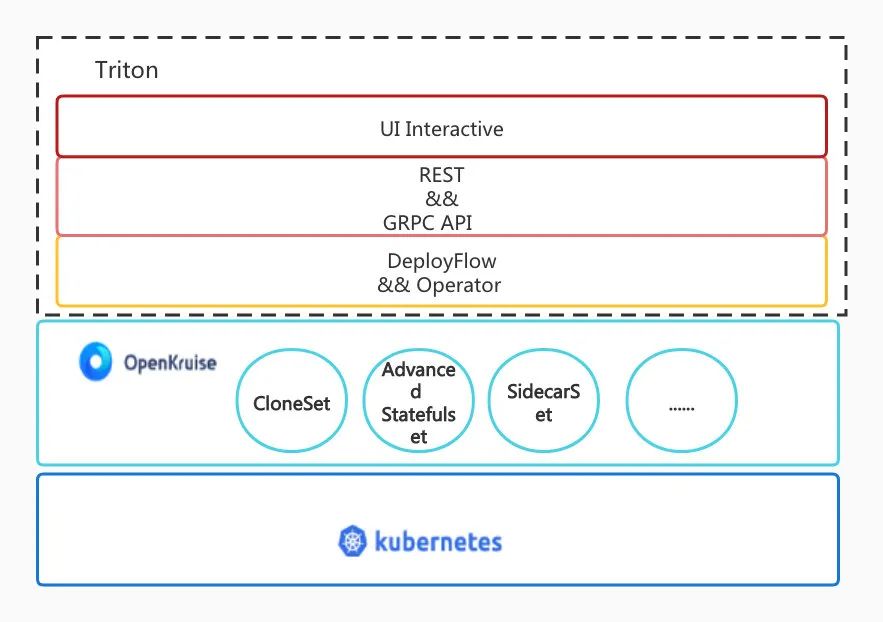
2.2.1 DeployFlow 和 Operator 实现
首先介绍下 DeployFlow 这个 CRD,通过 DeployFlow 我们定义了一次发布中需要的配置以及发布过程中需要的状态展示。
// DeployFlow is the Schema for the deploys API
type DeployFlow struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec DeployFlowSpec `json:"spec,omitempty"`
Status DeployFlowStatus `json:"status,omitempty"`
}
Spec 字段的内容分为两部分,一部分是与应用相关的信息,比如 AppID、GroupId、副本数量、AppName等,另一部分是指定发布策略,比如是 create还是 update 操作,是 scale in 还是 scale out,不同的操作对应不同的发布策略,详细的字段解释可以通过下面代码来理解。
type DeployFlowSpec struct {
// Important: Run "make" to regenerate code after modifying this file
AppID int `json:"appID"`
GroupID int `json:"groupID"`
AppName string `json:"appName"`
......
Action string `json:"action"`
// +nullable
UpdateStrategy *DeployUpdateStrategy `json:"updateStrategy,omitempty"`
// +nullable
NonUpdateStrategy *DeployNonUpdateStrategy `json:"nonUpdateStrategy,omitempty"`
}
DeployUpdateStrategy 代表了本次发布是一次更新操作,也就是会使 CloneSet 中的 UpdateRevision 字段发生变化,一般 create、update rollback 就是采用 DeployUpdateStrategy 的字段定义。
DeployNonUpdateStrategy 代表本次发布不会触发资源更新,也就是 UpdateRevision 不会发生变化,一般 scale in、scale out、restart 等操作要采用 DeployNonUpdateStrategy。
不同的发布策略肯定有不同的字段,但大部分的策略都是可以共用的,所以在此之上我们抽象出一个基础发布策略 BaseStrategy,由于 BaseStrategy 中的字段太多,我们这里放一张 CRD 的 schema 资源视图,然后再选择其中重要的字段进行解释。
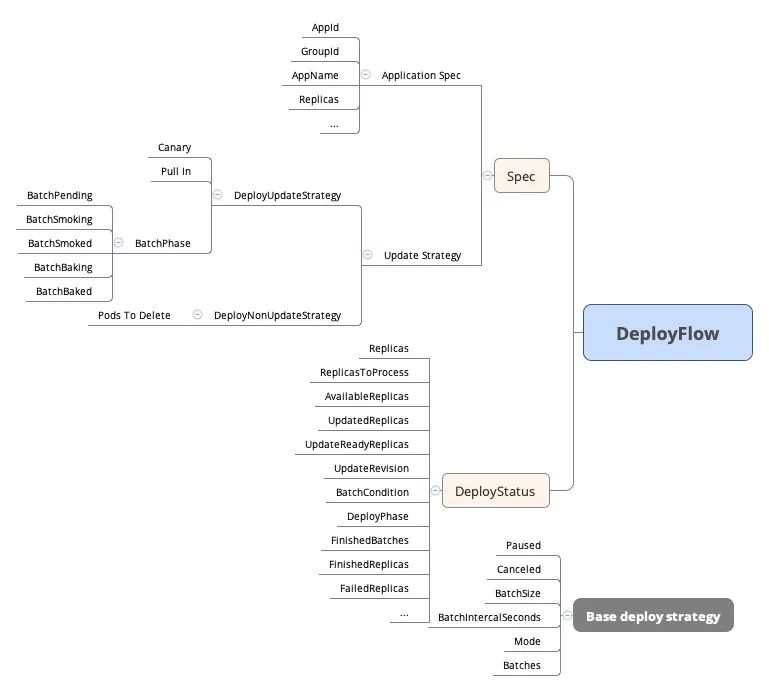
先介绍 DeployPhase 字段,DeployPhase 表示一次发布过程中,DeployFlow 所经历的阶段。
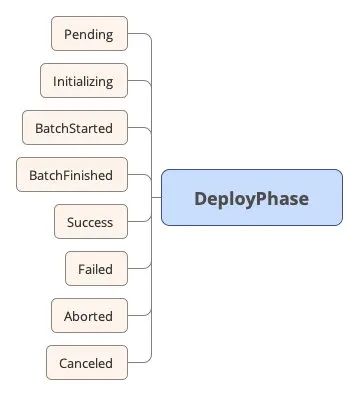
字段的意思都比较好理解,这里就不展开讲 了。
在 BaseStrategy 中有个比较重要的字段 - BatchSize ,表示批次大小。这意味着 DeployFlow 支持分批次发布,用户可以自定义每个批次最大发布的副本数量,DeployFlow 会计算出本次发布的总批次是多少从而提前给出发布概览。
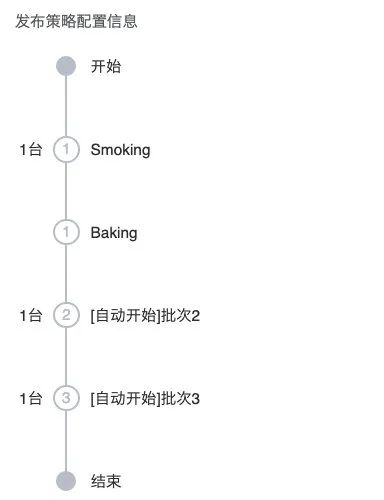
从 BaseStrategy 的 paused、canceled 字段就可以知道,在发布过程中可以随时暂停、继续或者取消本次发布。Mode 表示 DeployFlow 不同批次之间的触发方式,分为 auto 和 manual 两种,当选择 auto 模式的时候,通过字段 BatchIntervalSeconds 可以设置不同批次之间的时间间隔,如果选择手动模式则每个批次之间需要手工触发。
由于 DeployFlow 是分批次发布,所以每个批次需要有阶段显示 - BatchPhase ,以表示当前的批次所处的阶段,我们来详细解释每种阶段的含义。
BatchPending: 表示当前批次的 pod 正在准备资源,比如此时 pod 正在被调度中,image 在下载中,对应 Kubernetes 中的 pod 处于 Pending,ContainerCreating 状态。
BatchSmoking: 表示当前批次的 pod 正在启动过程中,pod 处于 Running 状态,但是 ContainerReady 字段还没有置为 true。
BatchSmoked: 表示当前批次的所有 pod 都已经启动成功,也就是 pod 中的 ContainerReady 字段已经被置为 true,但是 Ready 字段还处于 false。此时如果通过 service 来处理服务流量的话,启动的 pod 并不会被加入到对应 service 的 endpoint,如果是微服务架构,则该 pod 并不会被拉入到微服务的注册中心,从而保证了业务流量的安全。正是拥有了这种机制以及批次间可暂停的能力,我们可以轻松实现应用的金丝雀发布,这个在后面还会详细讲到。
BatchBaking: 表示当前批次的所有 pod 都已经启动成功,正在执行流量拉入操作,也就是将 pod 的 Ready 字段置为 true。
BatchBaked: 表示当前批次的所有 pod 的 Ready 字段都已被置为 true,pod 开始接收生产流量,至此也意味着本批次的结束,可以开始下一批次的操作。
在批次进行过程中,会有 smoke 失败或者 bake 失败的情况,对应的状态就是 SmokeFailed和 BakeFailed。
在 UpdateStrategy 中有一个 canary 字段,意味着 DeployFlow 支持金丝雀发布。其实在讲解了上述 DeployFlow 分批次处理的能力后,在此基础之上实现金丝雀发布是比较简单的。也就是在金丝雀批次处于 BatchSmoked 状态的时候,让发布暂停,在流量拉入之前也可以进行一些 API 验证的操作,开发者在验证没问题之后手工将该批次拉入,拉入金丝雀批次后, DeployFlow 也处于暂停的状态,此时开发者可以观察线上流量的监控,确认没有问题后再执行后面批次的发布。后面的 UI 交互会更加直观地展示该功能,这里我们先通过一张 DeployFlow 的状态流转示意图完整地展示一次发布的过程,我们以本次发布分为两个批次为例,金丝雀批次和普通批次。结合本图与上文的 CRD 解释,相信读者会对 DeployFlow 有一个更加清晰的认知。
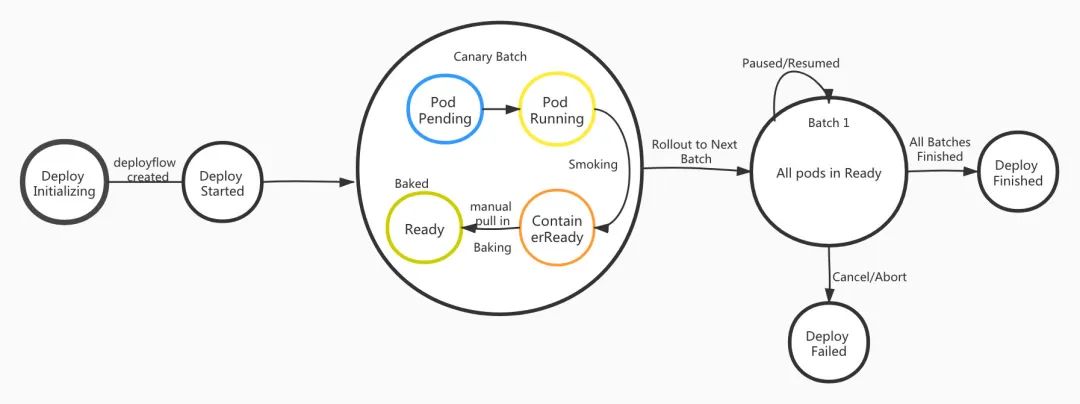
至此,在 DeployUpdateStrategy 、BaseStrategy 中的核心字段都已经介绍完了,在 DeployNonUpdateStrategy 中还有一个 PodsToDelete 字段,这个字段是在应用缩容、重启操作时起作用的,原生 Kubernetes 对于资源的缩容操作有自己的规则,不能随意选择想要缩容的 pod。但是在 DeployFlow 中,你可以指定 pod 缩容,指定 pod 重启。
通过上面的介绍,读者对 DeployFlow 这个 CRD 的 spec 字段有了一定了解,下面来看下发布过程中我们需要展示的 status 字段。

熟悉 Kubernetes 的同学应该能够从字段的字面意思了解这些字段的含义,这里就不详细展开了。
CRD 设计完成后,Operator 的实现也就是水到渠成的事情了,除了 DeployFlow 的 Operator,Triton 中还重新实现了一些 controller 来满足个性化的需求,比如 Event controller 用来将发布过程中 pod、Cloneset、DeployFlow 等组件的日志发送到 ES 以方便开发者查看发布的情况,ReadinessGates controller 用来控制自定义 ReadinessGate 的拉入拉出操作等。
同时 Triton 提供 REST & GRPC API 来操作 DeployFlow,调用方即使不了解容器和 Kubernetes 的知识,也可以很容易对接到 Triton 上实现发布的功能。
2.3 UI 交互
底层架构以及核心组件 DeployFlow 的设计逻辑虽然稍显复杂,但得益于 Triton 暴露的 REST & GRPC API 以及丰富的 status 字段,使得前端在发布的 UI 交互逻辑上能够做到简洁直观。下面让我们从 UI 入手,看下 Triton 如何进行应用的交付以及对应用的副本实例的规划。
2.3.1 发布入口及发布清单
进入生产发布页面,在容器发布页签,选择需要发布的 group,点击“发布”。
点击后弹出一个发布清单的页面,在这里需要配置本次发布需要的策略以及相关参数。
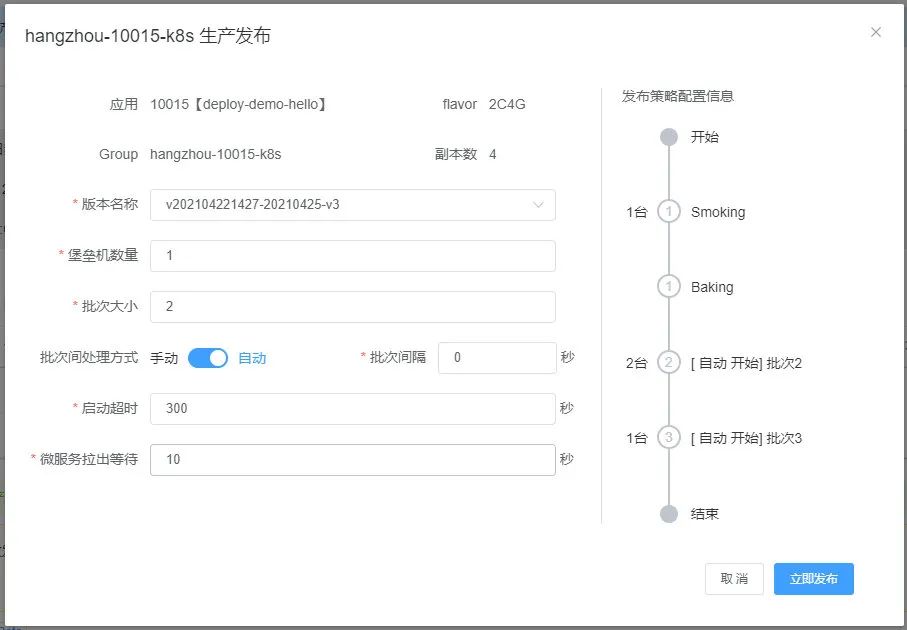
其中有些参数在上面的 CRD 设计篇章中已经有所描述,比如应用描述,批次大小,批次间处理方式,批次间隔等,这里不再赘述。启动超时时间 是开放给开发者自定义应用需要用来启动的时间,比如有些应用尤其是 java 应用,在真正启动之前需要执行一些 warm up 的操作,开发者就可以根据自己应用的实际情况填写该值,避免这类应用启动失败。微服务拉出等待时间 是用来支持微服务 pod 优雅退出的。
那何谓优雅退出,为什么要优雅退出呢?在Kubernetes 中当删掉一个 pod 的时候,理想状况当然是 Kubernetes 从对应的 Service(假如有的话)把这个 pod 摘掉,同时给 pod 发 SIGTERM 信号让 pod 中的各个容器优雅退出就行了。但实际上 pod 有可能犯各种幺蛾子:
已经卡死了,处理不了优雅退出的代码逻辑或需要很久才能处理完成; 优雅退出的逻辑有 BUG,自己死循环了; 代码写得野,根本不理会 SIGTERM;
因此,Kubernetes 的 pod 终止流程中还有一个“最多可以容忍的时间”,即 grace period (在 pod 的 .spec.terminationGracePeriodSeconds 字段中定义),这个值默认是 30 秒,我们在执行 kubectl delete 的时候也可通过 --grace-period 参数显式指定一个优雅退出时间来覆盖 pod 中的配置。而当 grace period 超出之后,Kubernetes 就只能选择 SIGKILL 强制干掉 pod 了。
但是在微服务的场景下,除了把 pod 从 Kubernetes 的 Service 上摘下来以及进程内部的优雅退出之外,我们还必须做一些额外的事情,比如说从 Kubernetes 外部的服务注册中心上反注册,不然可能会出现 pod 已经被删掉,但是注册中心上还留着已删掉 pod 的服务信息,此时有流量进入的话就会出现服务不可用的情况。所以我们在 prestop hook 中定义了一个名为 gracefully_shutdown 的文件来处理 pod 删除后的微服务优雅退出。
spec:
contaienrs:
- name: demo-container
lifecycle:
preStop:
exec:
command: ["/bin/sh","-c","/gracefully_shutdown"]
右侧的发布策略以及本次发布概览在之前的架构设计中已经讲过,这里不在赘述。
2.3.2 开始发布
完成发布配置后,即可开始发布。
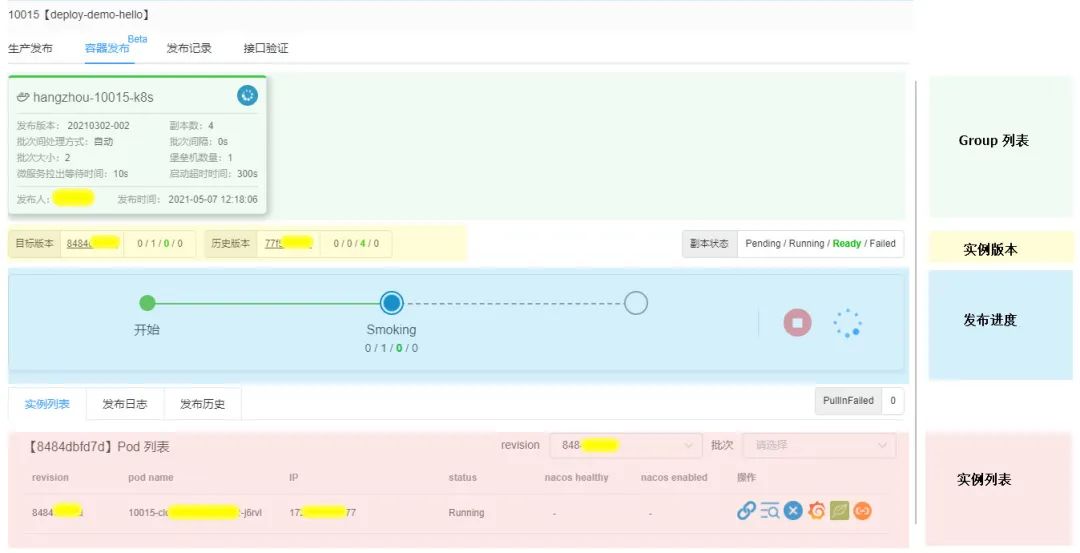
发布进度:展示发布的批次,及各个批次所启动的实例数量和状态。在发布过程中,人工操作的入口也在此区域; 实例列表:展示发布的实例,可以切换实例版本查看各版本的实例; 副本状态:形如 0/1/0/0对应Pending/Running/Ready/Failed四个状态的数量(1个 pod 在发布中),其中Running对应发布中实例数,Ready发布成功实例数,Failed发布失败实例数。
2.3.3 发布过程
一个典型的发布包括“金丝雀批次启动(Smoking)”-“金丝雀批次点火(Baking)”-“滚动发布(Rollout)” 三个阶段。
金丝雀批次启动中(Smoking)

金丝雀批次启动成功,可以验证接口,确认没问题,可将其拉入点火(Baking)

金丝雀批次点火中,实例已接流量,由于此时 DeployFlow 处于暂停状态,开发者可以有充足的时间可观察日志、监控等是否有异常,确认没问题后再触发滚动发布(Rollout)

滚动发布中,如选择“手动” 模式,每个滚动批次都需要人为触发

滚动发布过程中,可以看到新旧实例的版本数量在交替变化。
发布成功

至此,一次完整的 DeployFlow 流程就走完了,发布到达成功的状态。可以看到每个批次所负责的 pod 数量以及 pod 状态、日志等信息。
2.3.4 指定实例的操作
在实例运行过程中,如果发现实例负载异常或需要重新加载 apollo 配置,就会有重启实例的需求。Kubernetes 本身没有提供重启的操作逻辑,一般通过杀掉一个 pod 来达到重启的效果,但这种方式比较粗暴而且存在安全隐患。Triton 提供了安全的重启策略,会先新增一个 pod 如果该 pod 启动成功成功,再删掉你所指定要重启的 pod,以此来达到安全重启的效果,这就是 Triton 的指定实例重启的功能。
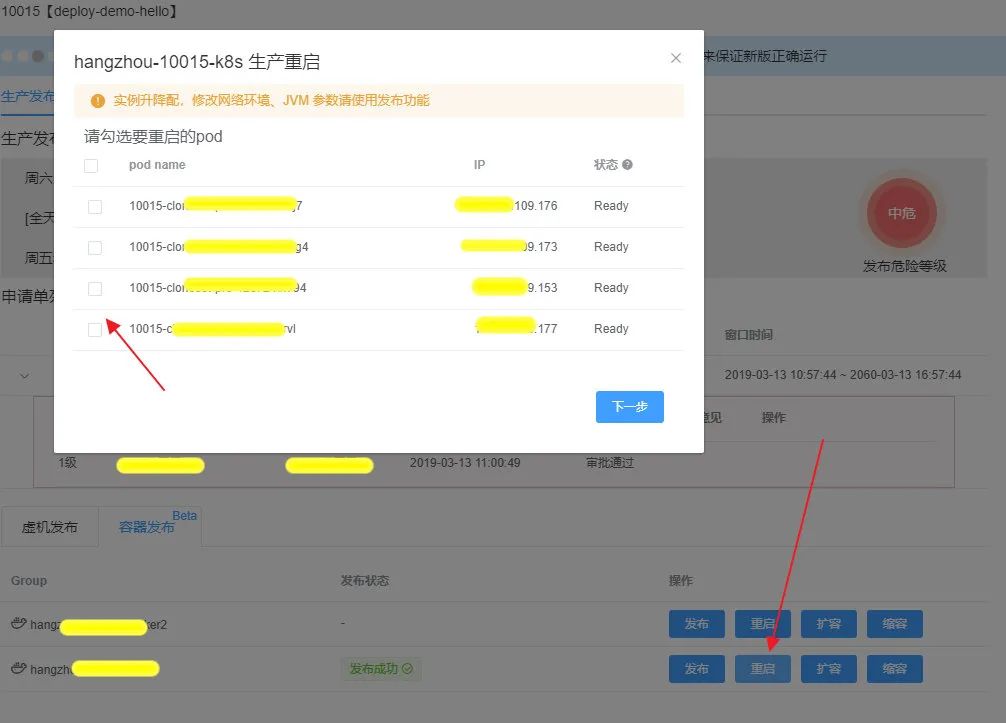
同样的原理,缩容的操作也可以指定想要缩掉的 pod 。
该功能的实现得益于 OpenKruise 中增强型无状态 workload CloneSet 提供的能力,具体的功能描述可以参考 OpenKruise 文档。
上面的内容就是有关 Triton 核心能力的 UI 交互,整个过程力求简洁、清晰,避免给开发者造成额外的理解负担,这为我们容器的接入、推进提供了很大的便捷。
3. 总结与展望
每个公司的容器发布平台都不尽相同,可能会有读者看完说 Triton 封装了太多的 Kubernetes 细节,没有向开发者真正展示原生 Kubenetes 的状态、含义或者理念。其实从一开始,我们的目标就是设计适用于掌门自身研发体系的容器发布系统,减少开发对发布操作的学习成本,从而快速上手以更快地赋能研发流程的迭代,加速业务应用的上线。而简洁清晰的 API 也有利于我们设计出更加简单的用户界面,简单的用户界面又让我们在推广时受益。

上图是 Triton 的一些关键指标,可见 Triton 已经成为 CD 平台的核心能力,在用户需求的迭代中不断进化,不过,现在的 Triton 依然有很大的优化空间,主要有:
掌门有大量的 socket 长连接应用,对于这类应用的容器化,以及容器化后如何发布,还没有清晰的设计方案; Triton 按应用粒度进行发布,不支持跨应用的发布流程编排; 对开发者快速拉起本地测试环境的支持较弱。
我们目前也在进行针对这些优化项的工作。
我们团队负责掌门研发效能平台的建设,服务于掌门所有研发人员。作为掌门研发体系的核心组成部分,致力于保障高质量的交付和研发效率的提升。当前 CD 平台已经在 CI/CD 和监控告警形成闭环,今后我们会沿着需求、设计、开发、构建、验证、发布这个路径进行更广的探索,打造真正的研发效能平台。目前掌门正在进行生产环境容器化的升级,如果你对 Triton 或者 Kunernetes 感兴趣,欢迎加入我们一起打磨生产应用容器化的设计与落地方案。
参考资料
Triton 是希腊神话中海之信使: https://zh.wikipedia.org/wiki/%E7%89%B9%E9%87%8C%E5%90%8C
[2]掌门大规模流水线实践: https://mp.weixin.qq.com/s/DFy_E6qN3hLyStaSand_Dg
[3]CNCF SIG App Delivery: https://docs.google.com/document/d/1gMhRz4vEwiHa3uD8DqFKHGTSxrVJNgkLG2WZWvi9lXo/edit#
[4]OpenKruise: https://openkruise.io/zh-cn/docs/what_is_openkruise.html