
ES02# Elasticsearch术语与部署架构梳理
引言
ES体系化梳理第二篇,从基本概念和术语开始,走查了集群中的节点以及其在ES集群中可扮演的角色,最后走查了常见的集群部署架构。本文主要内容有:
- 基本概念与术语
- 节点角色与集群状态
- 常用集群部署架构
Document: 是es搜索的最小单位,被序列化成json对象存入es。
文档类比关系数据库一条记录
每个文档有一个唯一的ID,类比关系数据库主键ID
json对象由filed构成,filed类比关系数据库column
Index: 索引是文档的容器,一类文档的集合,存储在分片Shard上。
索引类比关系数据库的表
索引的Mapping定义文档字段类型,类比关系数据库的schema
索引的Setting定义数据在分片上的分布
节点: ES实例的java进程,节点名称在启动时通过 -Enode.name指定,每个节点存储集群状态信息。
集群状态包括:所有节点信息、所有的索引及Mapping和Setting信息、分片路由信息
只有master节点可以修改集群状态信息
Data Node:保存分片数据的节点
Coordinating Node:负责接受客户端请求并将请求转发到合适的节点,并负责汇总结果;默认情况下每个节点都会启到Coordinating Node的职责
Hot&Warm Node:由不同配置的Data Node组成,主要为了降低成本,Hot节点使用高配置,Warm节点使用低配置
主分片: 在创建索引时指定主分片,解决数据水平扩容问题。
- 类比kafka的分区,一个分片运行的Lucene的实例
- 在创建索引的时候指定,之后修改需要Reindex
- 分片数与节点数相关,分片数过少影响节点扩容,分片数过多影响查询性能
- 多分片分担写压力,当分片数 > 节点数,新节点加入分片会自动分配
- 分片过多会导致潜在性能,查询需要从多个分片上检索数据,比如:集群总分片控制几万内
- 日志单个分片数据存储大小50G内,搜索类单个分片存储20G内,降低merge/rebalancing耗损资源
副本: 主分片的备份,解决数据高可用问题。
- 类比kafka的副本,副本分片可以动态调整
- 增加副本数除了解决高可用外,可以提高读取性能,同时增加存储成本
1.节点角色
Node官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.10/modules-node.html
Elasticsearch7.9通过node.roles配置节点角色,在配置文件elasticsearch.yml设置
| 角色选项 | 说明 |
|---|---|
| master | node.roles: [ master ]:拥有选举权和被选举权 |
| master, voting_only | node.roles: [ master, voting_only ]:只有选举权没有被选举权 |
| data | node.roles: [ data ]:处理与数据相关的操作CRUD、搜索、聚合 |
| data_content | node.roles: [ data_content ]:冷热分层架构,通用节点,CRUD、搜索、聚合 |
| data_hot | node.roles: [ data_hot ]:冷热分层架构,hot节点承担快速读写操作,可以配置为SSD盘 |
| data_warm | node.roles: [ data_warm ]:冷热分层架构,warm节点索引不定期更新,查询频率比热节点低,配置低于热节点 |
| data_cold | node.roles: [ data_cold ]:冷热分层架构,cold节点只存只读索引,低配置节点 |
| ingest | node.roles: [ ingest ]:ingest节点用于对写入和查询的数据进行预处理 |
| Coordinating only node | node.roles: [ ]:协调节点不承担master职责、不保存数据、不预处理;负责接受请求、分发请求、汇总结果 |
备注:生产环境建议一个节点设置单一角色,有利于更好的性能和根据角色定制化配置。
2.集群状态
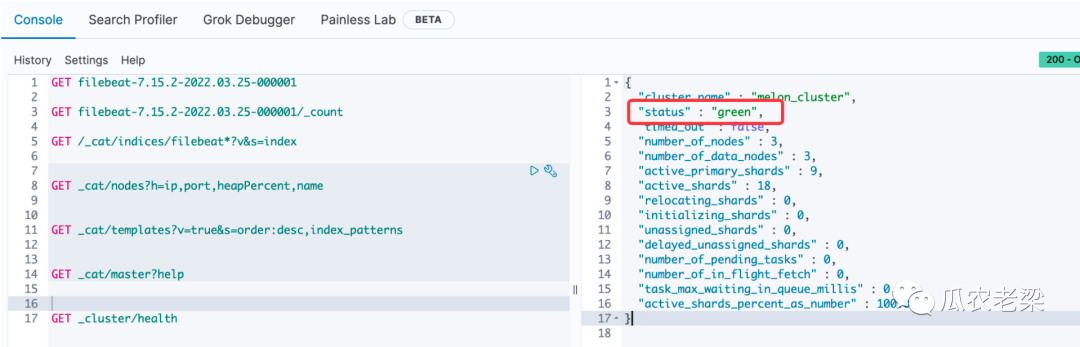
衡量集群健康与否的三种状态:
Green:主分片与副本正常分配
Yellow:主分片全部正常分配,有副本分片未正常分配
Red:有主分片未能正常分配
查看集群状况
官方API文档
// index API
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/indices.html
// Get index API
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/indices-get-index.html
// cat API
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/cat.html
查询document总数

1.各角色配置
生产环境架构中每个节点配置单一职责,具体为Master、Data、Ingest、Coordinate的一个,有利于每个角色可以使用不同的机器配置。
- Master 负责集群状态信息管理
- 生产环境通常配置3台
- 低配置(低CPU核数、小内存、低磁盘)
- Data节点负责处理与数据相关的操作
- 高配置(高CPU核数、大内存、SSD盘)
- Ingest节点负责写入和查询的数据进行预处理
- 中配置(高CPU核数、中内存、低磁盘)
- Coordinate节点,通常在es大集群中配置,降低Master和Data Nodes的负载,负责接受请求、分发请求、汇总结果
- 应对客户的未知查询请求,深度聚合可能导致OOM
- 中高配置(中高CPU核数、中高内存、低磁盘)
2.集群部署架构
2.1 水平扩展
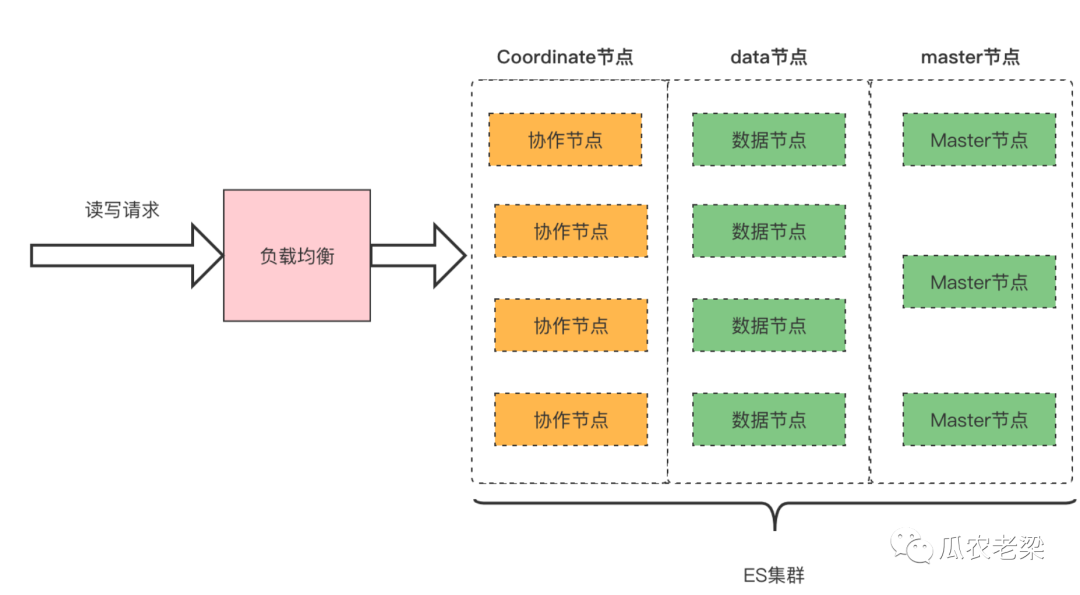
备注:集群中存在大量复杂的查询时,通过增加协作节点提升查询性能。
2.2 读写分离
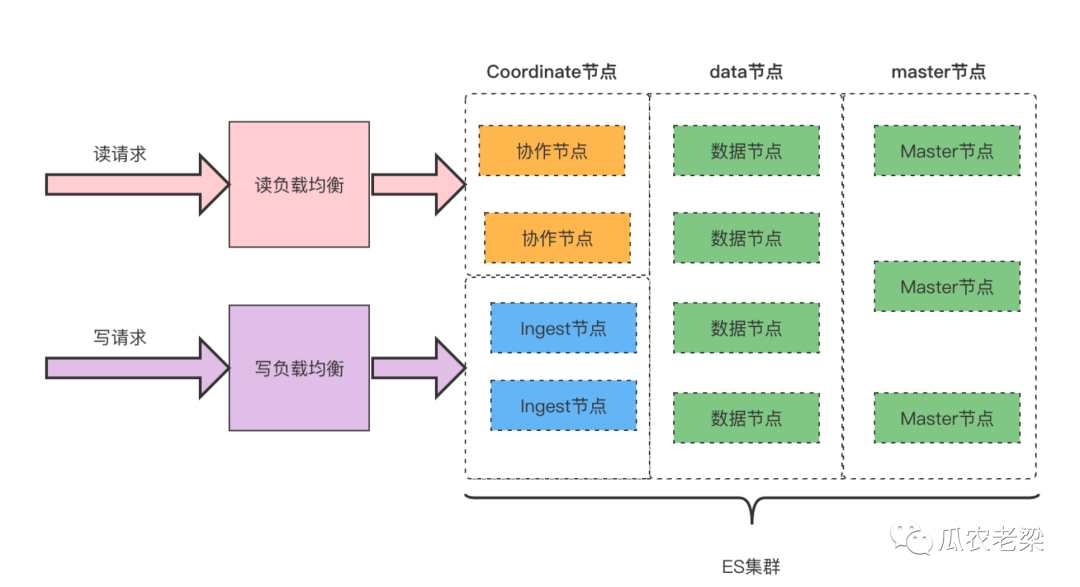
备注:通过配置不同的读写负载均衡,分离读写请求,读请求路由到协作节点,写请求路由到Ingest节点,协作节点和Ingest节点可以水平扩展。
2.3 冷热分离
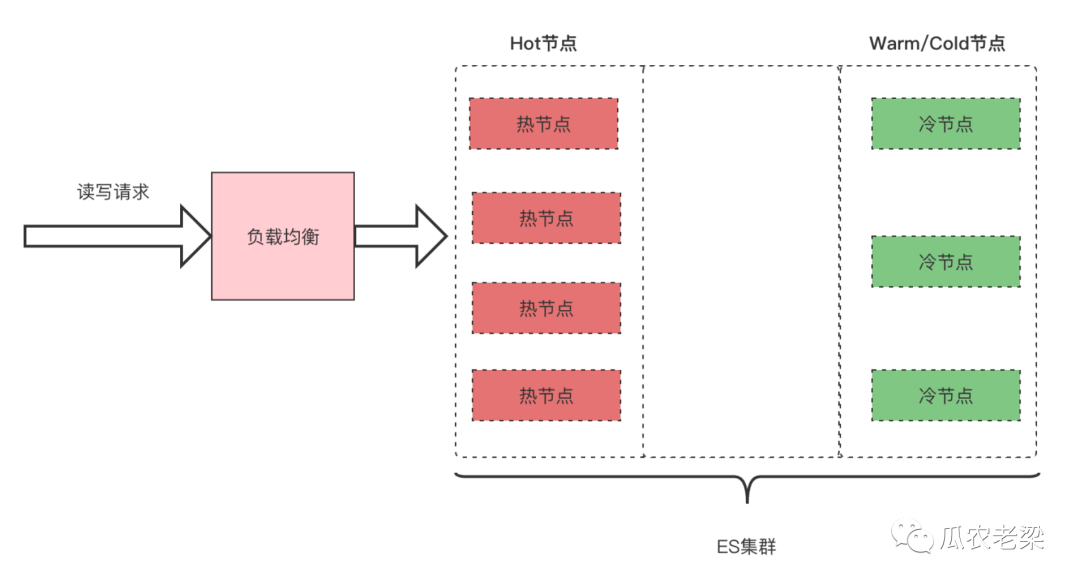
备注:冷热分离架构,Hot节点通过高配置承担更多的读写压力,冷节点承担一定的读请求,常见于日志类使用场景。
2.4 混合部署
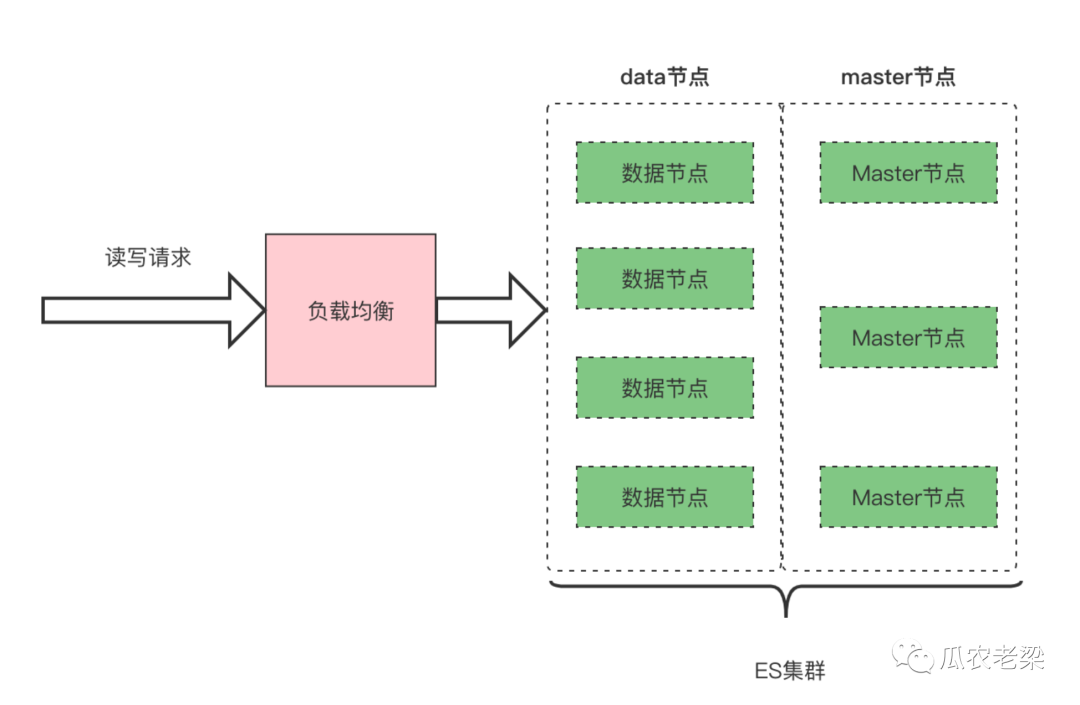
备注:ES集群由data节点和master节点构成,常见于非生产环境以及线上读写均无压力的场景。