
看完这篇AI算法和笔记,跟面试官扯皮没问题了 | 基于深度学习和传统算法的人体姿态估计
共 9147字,需浏览 19分钟
·
2020-09-17 17:55
点击蓝色“AI专栏”关注我哟

关于人类活动规律的研究,必定是计算机视觉领域首要关注的内容。其中,人体姿态估计便是计算机视觉领域现有的热点问题,其主要任务是让机器自动地检测场景中的人“在哪里”和理解人在“干什么”。

除了工作人员很难长时间地保持高度警惕外,长期投入大量的人力来监测小概率发生的事件也不是单位机构提倡的做法。因此,实现视频监控的智能化成为一种互联网时代的必然趋势。但是,实现智能视频监控的前提条件是让机器自动地识别视频图像序列中的人体姿态,从而进一步分析视频图像中人类的行为活动。
烧
人体行为分析理解成为了近几年研究的热点之一。在人体行为分析理解的发展过程中,研究人员攻克了很多技术上的难关,并形成了一些经典算法,但仍有很多尚未解决的问题。从研究的发展趋势来看,人体行为分析的研究正由采用单一特征、单一传感器向采用多特征、多传感器的方向发展。而人体姿态估计作为人体行为识别的一个重要特征,是进行人体行为分析的基础,是人体行为分析领域备受关注的研究方向之一。

烧
目前主流的人体姿态估计算法可以划分为传统方法和基于深度学习的方法。
基于传统方法的人体姿态估计
其缺点是什么?
First,传统方法虽然拥有较高的时间效率,但是由于其提取的特征主要是人工设定的HOG和SHIFT特征,无法充分利用图像信息,导致算法受制于图像中的不同外观、视角、遮挡和固有的几何模糊性。同时,由于部件模型的结构单一,当人体姿态变化较大时,部件模型不能精确地刻画和表达这种形变,同一数据存在多个可行的解,即姿态估计的结果不唯一,导致传统方法适用范围受到很大限制。
Second,另一方面,传统方法很多是基于深度图等数字图像提取姿态特征的算法,但是由于采集深度图像需要使用专业的采集设备,成本较高,所以很难适用于所有的应用场景,而且采集过程需要同步多个视角的深度摄像头以减小遮挡问题带来的影响,导致人体姿态数据的获取过程复杂困难。因此这种传统的基于手工提取特征,并利用部件模型建立特征之间联系的方法大多数是昂贵和低效的。
基于深度学习的人体姿态估计算法
随着大数据时代的到来,深度学习在计算机视觉领域得到了成功的应用。因此,考虑如何将深度学习用于解决人体姿态估计问题,是人体姿态估计领域的学者们继图结构模型后所要探索的另一个重点。早期利用深度学习估计人体姿态的方法,都是通过深度学习网络直接回归出输入图像中关节点的坐标。
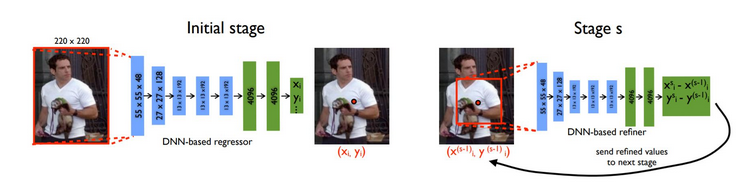
其好处是什么?
First,相较之下日常生活中的单目摄像头更为常见,虽然其采集的彩色图像容易受到光照等环境因素的影响,但是可以利用神经网络提取出比人工特征更为准确和鲁棒的卷积特征,以预测更为复杂的姿态,所以基于深度学习的人体姿态估计方法得到了深入的研究。
Second,不同于传统方法显式地设计特征提取器和局部探测器,进行深度学习时构建CNN比较容易实现,同时可以设计处理序列问题的CNN模型,例如循环神经网络RNN,通过分析连续多帧图像获得人体姿态的变化规律,进而为人体姿态中各个关节点之间建立更为准确的拓扑结构。
但是,如何在表征人体复杂结构的理论数学模型和提升估计结果的精度上同时取得突破,是人体姿态估计领域一直以来探索的终极目标。因此,人体姿态估计领域在未来的工作中具有较大的研究发展空间。
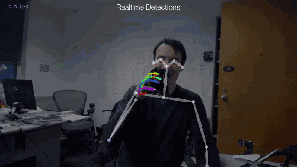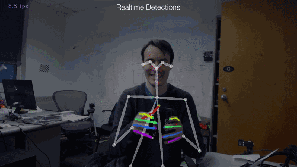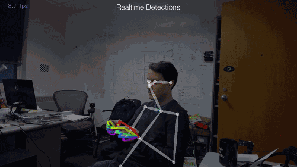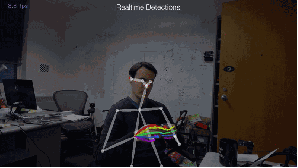
Fig.4: 2D估计
本文站长主要是想谈谈基于深度学习的实时多人姿态估计。主要是拜读了文献7,所以本文站长想谈谈自己通过很多文献的全面阅读后,自己的一些想法和理解,有理解不到位的地方请大家斧正,谢谢。
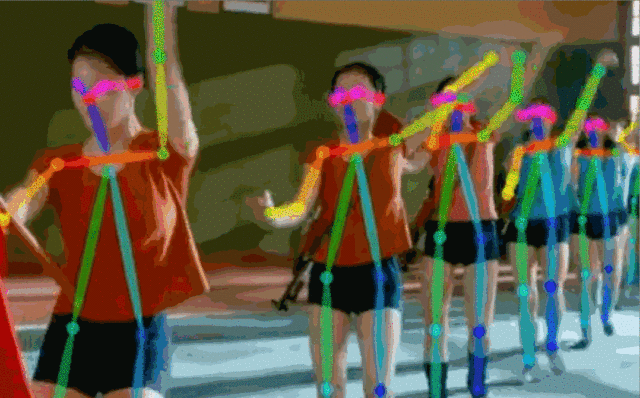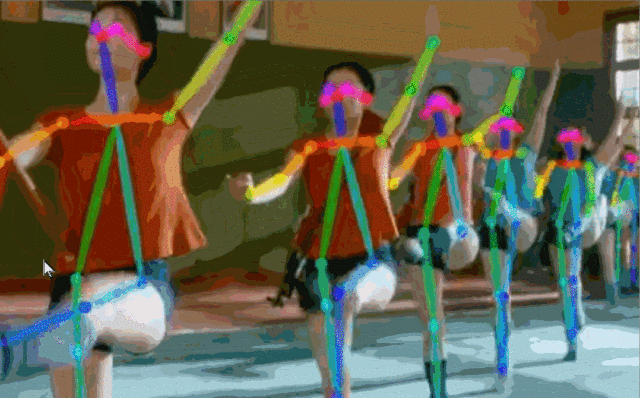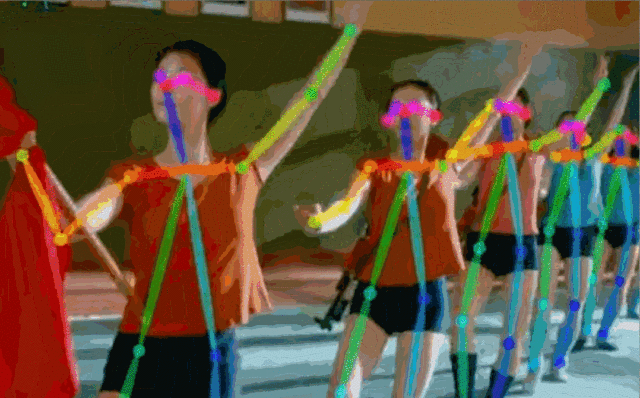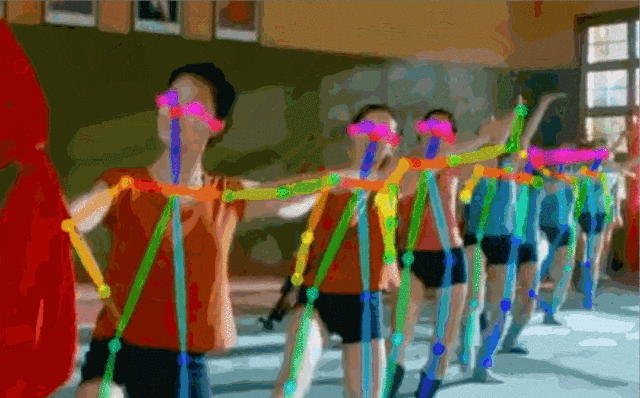
Fig.5: 实时多人估计
自顶向下
自底向上
对于一张输入图像,深度神经网络同时预测出每个骨点的热力图S=(S1,S2,…,SJ)和骨点之间的亲和区域L=(L1,L2,…,LC) 。热力图的峰值为骨点的位置,骨点相互连接构成二分图,亲和区域对图的连接进行稀疏,最后对二分图进行最优化实现多人姿态估计。
网络结构深度解读
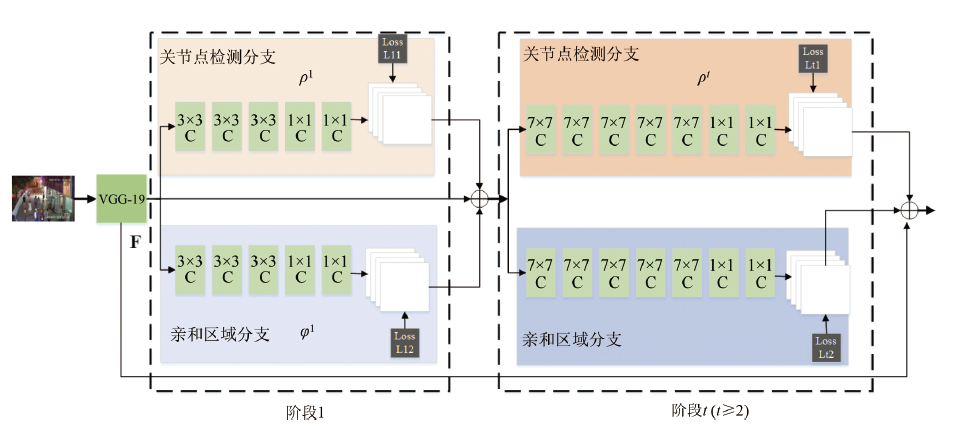
在第一阶段,对于输入特征采用3×3大小的卷积核连续进行三次卷积,之后用1×1 大小的卷积核连续进行三次卷积。
之后的阶段将前一阶段的预测结果和原图像特征F进行融合,作为当前阶段的输入,经过卷积操作分别预测出关节点热力图和关节点的亲缘关系程度(站长自己的理解haha,简单点就是两个关节点的朋友关系的亲密程度呗):
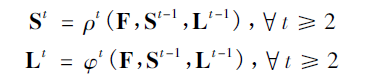
由于关节点热力图和关节点的亲缘关系程度本质有所不同,因此在训练的时候需要分别对关节点位置和亲和区域进行监督,损失函数均采用L2损失。为了避免梯度消失现象发生,在每个阶段的输出都添加损失函数,起到中继监督作用。
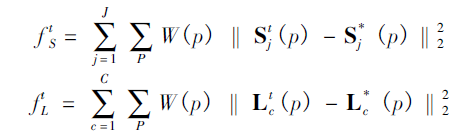
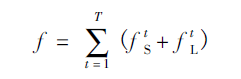
关于
关节点热力图

强调!Attention!
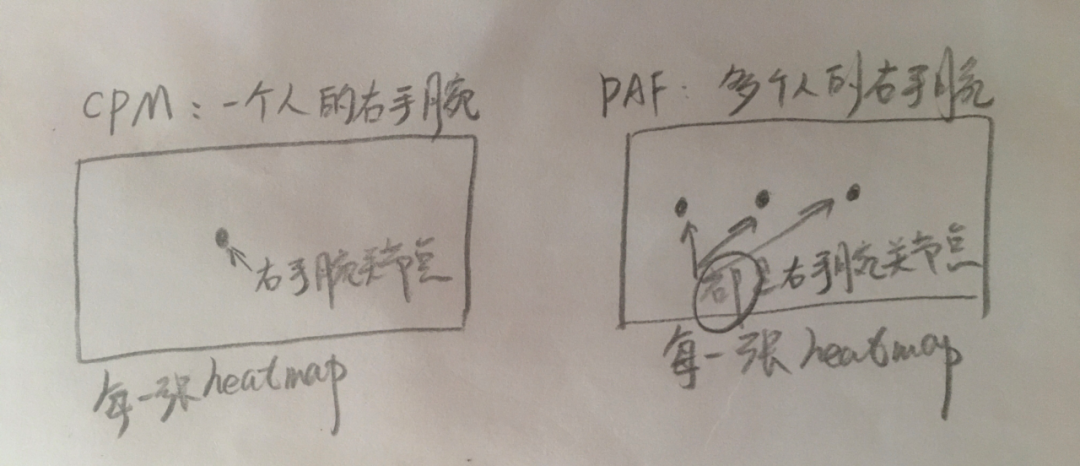
与CPM不同,CPM网络只是针对单个人的Pose,所以它的网络输出的P张置信度图中(假如一个人总共有P个关节点),每一张置信度上只有一个热点,这个热点只是一个人的一个关节点,比如右手腕关节这个关节点。
但如果图片上有多个人,它的第一行网络输出的P张置信度图中(假如单个人总共有P个关节点),每一张置信度上就有多个热点了,比如右手腕关节,假设有K个人,则要有K个右手腕关节点,所以此时这张置信度上就要有K个热点了。
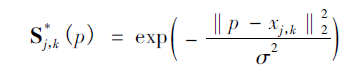
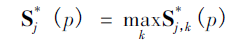
关节点亲和区域

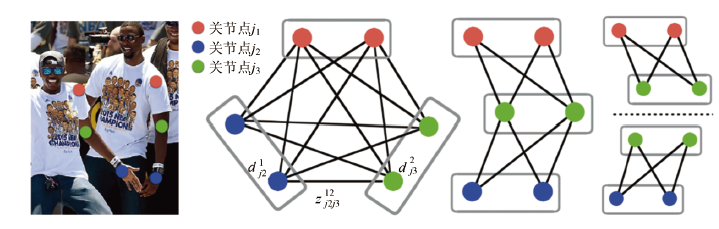
这是这个网络实现关节点检测的关键所在了,上面经过网络推理,得到骨点热力图以及骨点之间的亲和区域,对热力图采取非极大值抑制得到一系列候选骨点。由于多人或者错误检测,对于每一类型的骨点会存在多个候选骨点。这些候选骨点之间的连接构成二分图,每两个骨点之间的连接置信度通过线积分计算得到。为二分图找到最优的稀疏性是NP-Hard 问题。
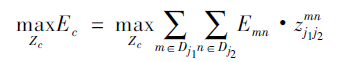
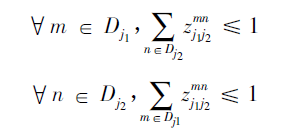
其中Ec为二分图优化之后肢体c的权重,我们要取其中总权重之和最大的;
Zc为所有骨点连接集合Z的子集;
约束条件表示一段肢体最多只存在一条连接边。
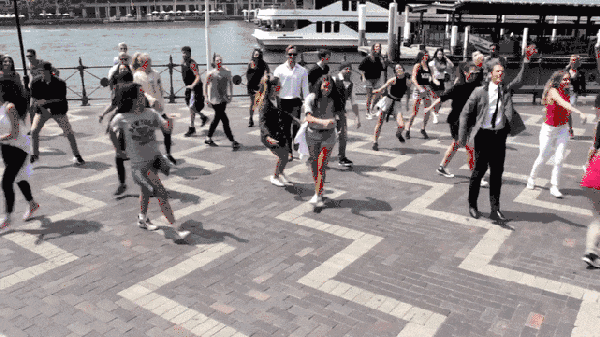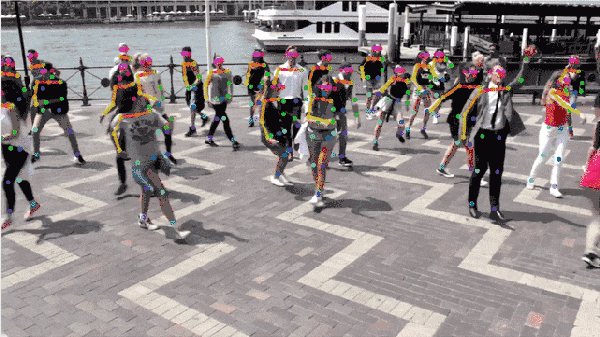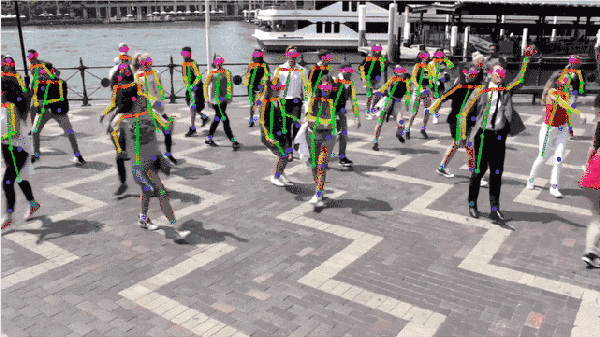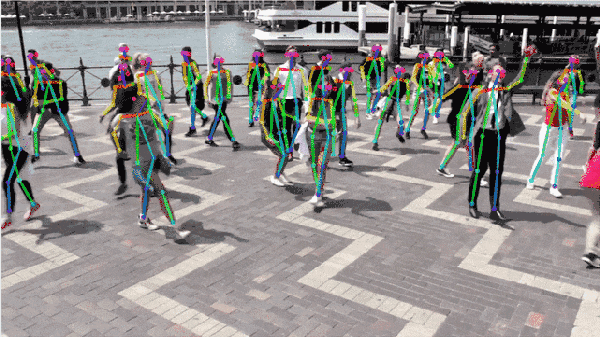
Fig.11: 算法效果
问题分解与简化
首先,如图所示,剔除跨骨点之间的连接构成稀疏二分图,代替全连接二分图; 然后根据肢体将稀疏后的二分图拆解得到图所示的多个简化二分图。
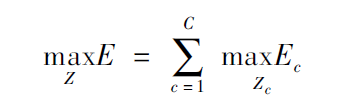
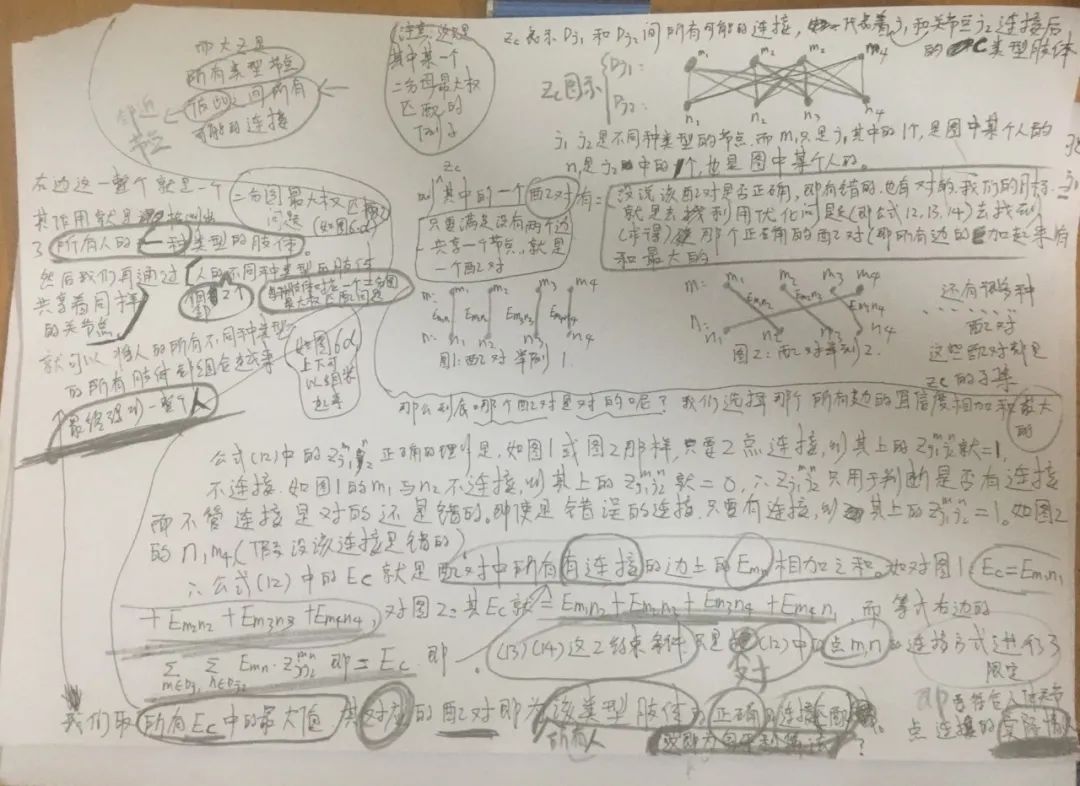
我对这个算法的整体思路做了个笔记,字太丑了orz,大家别见怪haha,道理讲明白理解清楚就行了(要高清原图的可以加站长微信领取哦)
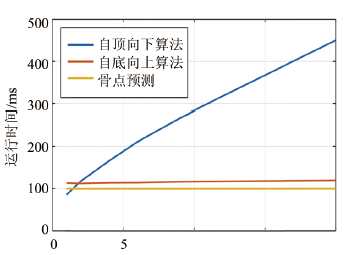
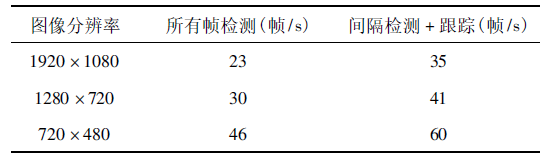
实验所使用的显卡为NVIDIA TITAN XP,CPU为Intel i7-6900K。图像大小为1920× 1080,通过下采样方法额外获得1280 × 720 和720 × 480 两个低分辨率的视频。
首先分析运行效率与人数的关系,在相同视频流和相同分辨情况下,计算自顶向下与自底向上运行时间与人数关系,计算结果如图14所示。由图可知,自顶向下随着人数的增加耗时几乎呈线性增加,而自底向上的运行耗时几乎不随人数增加而递增。卷积神经网络预测关节点的耗时也几乎不随人数增加而增加。因此我所使用的自底向上算法的运行效率不受行人数量的影响,对人数不确定的情况依然可以实时进行多人姿态估计。
站长测试(使用自己乱糟糟的图片才有说服力哈)

能阅读到这里,说明你也是个踏踏实实的做研究的人了。此时,我们娱乐时间到了,让我们来段测试视频放松放松下哈:
六阶段双分支网络结构在关节点预测精度上略高于现有传统的的人体姿态估计算法。本次站长采用的算法利用自底向上的思想,首先预测出所有骨点位置,并将骨点连接形成图结构,通过图优化实现多人体姿态估计。算法运行效率方面,由于网络同时预测出关节点位置和关节点之间的空间关系,为多人姿态估计算法提供更加稀疏的二分图,降低二分图优化复杂度而达到了实时的效果。
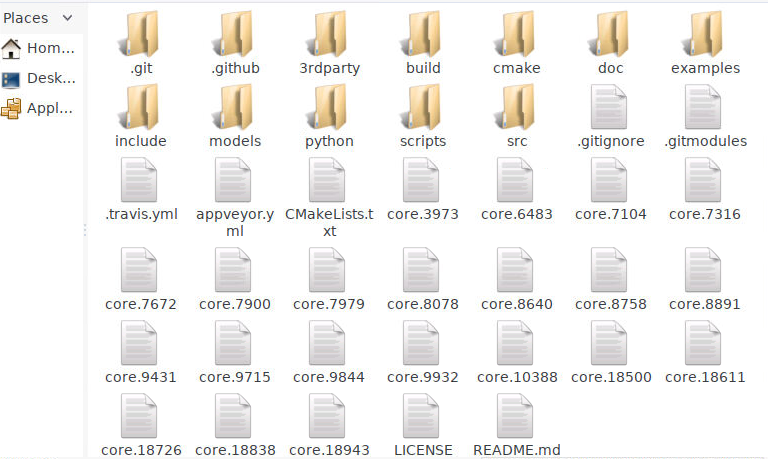
欢迎各位站友关注【AI专栏】加特别宠粉的站长微信交流交流算法哈。图中3rdparty文件夹下主要包含caffe等第三方工具,build文件主要是cmake操作生成的。cmake文件主要包含一系列cmake操作的文件,examples下主要是一些demo案例程序,models主要是训练好的模型。
巨人的肩膀
[1] Qian C, Sun X, Wei Y, et al. Realtime and robust hand trackingfrom depth[C]//Proceedings of the IEEE conference on computer vision and patternrecognition. 2014: 1106-1113.
[2] Joseph Tan D, Cashman T, Taylor J, et al. Fits like a glove: Rapid and reliable hand shape personalization[A]. IEEE Conference on Computer Vision and Pattern Recognition[C], 2016: 5610-5619.
[3] Tang D, Jin Chang H, Tejani A, et al. Latent regression forest:Structured estimation of 3d articulated hand posture[A]. IEEE conference oncomputer vision and pattern recognition[A], 2014: 3786-3793.
[4] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification withdeep convolutional neural networks[A]. Advances in neural informationprocessing systems[C], 2012: 1097-1105.
[5] Zhou E, Cao Z, Yin Q. Naive-Deep Face Recognition: Touching theLimit of LFW Benchmark or Not?[J]. Computer Science, 2015.
[6] Sharp T, Keskin C, Robertson D, et al. Accurate, robust, and flexible real-time hand tracking[A]. Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems. ACM[C], 2015: 3633-3642.
[8] Oberweger M , Wohlhart P , Lepetit V . Hands Deep in Deep Learning for Hand Pose Estimation[J]. ComputerScience, 2015.
唠叨唠叨
CSDN博客:ID:qq_40636639,昵称:AI专栏的站长知乎:AI驿站
站长个人微信
添加站长个人微信即送
500多本程序员必读经典书籍
→ 精选技术资料共享
→ 微信看朋友圈私货
→ 高手如云交流社群
推荐阅读
5T技术资源大放送!包括但不限于:C/C++,Python,Java,PHP,人工智能,单片机,树莓派,等等。请关注并在公众号内回复「1024」,即可免费获取!!
关于交流群
目前站长已经建立多个AI技术细分方向交流群,欢迎各位站友加入本公众号读者群一起和同行交流,目前有双目立体视觉、三维重建、强化学习、分割、SLAM、识别、GAN、算法竞赛、医学影像、副业赚钱交流、计算摄影、春招内推群、秋招内推群等微信群(以后站长会逐渐细分,所以一定要备注好方向!谢谢)。
请扫描下面站长微信拉你入群,请按照格式备注,否则不予通过。添加成功后会根据您的研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
(请务必备注:”研究方向+学校/公司+昵称“,比如:”人脸识别检测+ 上海交大 + 静静“)
长按扫码,申请入群
(添加人数较多,请耐心等待)
关于本公众号
当然是干货资源教程满满吖
关注即可免费领取资源,Goodbye,我们下次见!
关注领取500多本程序员必读经典书籍
最新 AI 干货,我在看 