点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
来源:OpenCV中文网
ACCV 2020 会议正在召开,同时官方已经公布了收录其中的 255 篇论文。令人惊喜的是,大会有约一半的论文已开源,今日先来一波 Github 星标前 10 的论文『截至2020 年 11 月 30 日』。
Visual Tracking by TridentAlign and Context Embedding
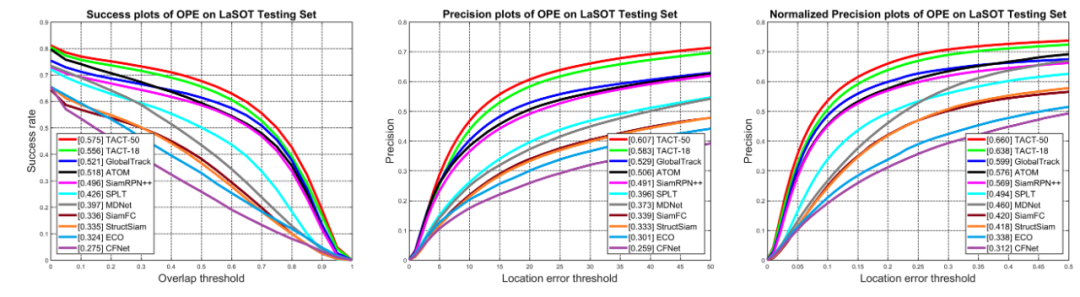
目标对象和具有相似类别干扰物的大规模偏差是视觉跟踪中的一大挑战,在本次工作中,来自韩国首尔大学和中央大学的学者提出全新的 TridentAlign 和上下文嵌入模块,用于基于孪生网络的视觉跟踪。在多个基准数据集上获得的实验结果表明,所提出的跟踪器的性能达到最先进的行列,同时所提出的跟踪器能以实时速度运行。作者 | Janghoon Choi, Junseok Kwon, Kyoung Mu Lee论文 | https://arxiv.org/abs/2007.06887代码 | https://github.com/JanghoonChoi/TACT
Speech2Video Synthesis with 3D Skeleton Regularization and Expressive Body Poses
百度研究员提出一个全新方法:Speech2Video,将给定音频转换为特定人物照片的逼真视频,输出视频具有同步性、逼真以及丰富的身体动态。作者 | Miao Liao, Sibo Zhang, Peng Wang, Hao Zhu, Xinxin Zuo, Ruigang Yang论文 | https://arxiv.org/abs/2007.09198主页 | https://sites.google.com/view/sibozhang/代码 | https://github.com/sibozhang/
Regularizing Meta-Learning via Gradient Dropout
来自加州大学默塞德分校,美国NEC实验室;英伟达;台湾阳明交通大学;谷歌的学者所提出的 DropGrad 方法缓解现有的基于梯度的元学习模型中的过拟合问题,提高跨域少样本分类的性能。
作者 | Hung-Yu Tseng, Yi-Wen Chen, Yi-Hsuan Tsai, Sifei Liu, Yen-Yu Lin, Ming-Hsuan Yang论文 | https://arxiv.org/abs/2004.05859代码 | https://github.com/hytseng0509/
Condensed Movies: Story Based Retrieval with Contextual Embeddings
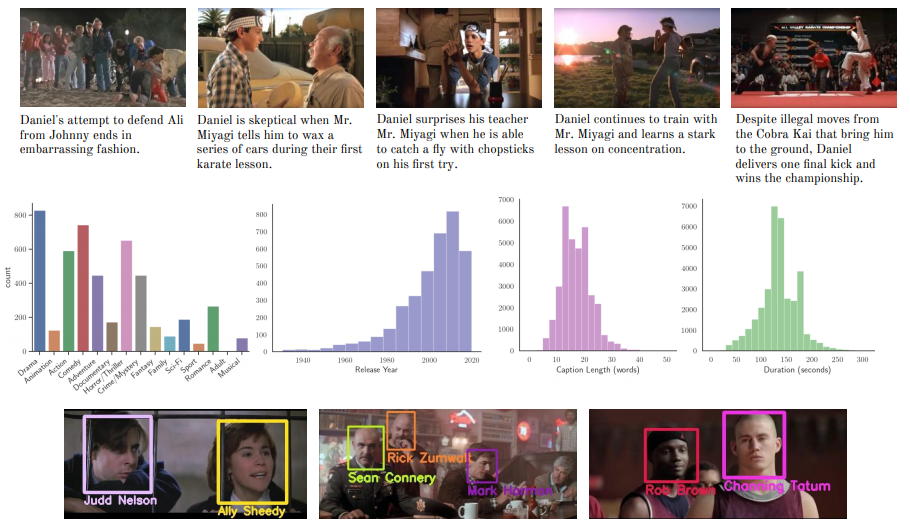
牛津大学 VGG 组学者创建了 Condensed Movies 数据集(CMD),由 3K 多部电影中的关键场景组成:每个关键场景都附有场景的高级语义描述、人物脸部轨迹和电影的元数据。该数据集是可扩展的,从 YouTube 自动获取,任何人都可以免费下载使用。它在电影数量上也比现有的电影数据集大一个数量级;在该数据集上提供了一个文本到视频检索的深度网络基线,将字符、语音和视觉线索结合到一个单一的视频嵌入中;同时该文还展示了如何从其他视频剪辑中添加上下文来提高检索性能。作者 | Max Bain, Arsha Nagrani, Andrew Brown, Andrew Zisserman论文 | https://arxiv.org/abs/2005.04208主页 | https://www.robots.ox.ac.uk/~vgg/research/代码 | https://github.com/m-bain/CondensedMovies
A Sparse Gaussian Approach to Region-Based 6DoF Object Tracking
德国航空航天中心和慕尼黑工业大学学者提出一个全新的、高效的、稀疏的基于区域的 6DoF 目标跟踪方法,只需一个单目 RGB 相机和 3D 目标模型。
在 RBOT 数据集上,所提出算法在跟踪成功率和计算效率方面都以相当大的优势优于最先进的基于区域的方法。
作者 | Manuel Stoiber, Martin Pfanne , Klaus H. Strobl, Rudolph Triebel , Alin Albu-Sch论文 | https://openaccess.thecvf.com/content/ACCV2020/papers/Stoiber_A_Sparse_Gaussian_Approach_to_Region-Based_6DoF_Object_Tracking_ACCV_2020_paper.pdf代码 | https://github.com/DLR-RM/RBGT
TinyGAN: Distilling BigGAN for Conditional Image Generation
GANs 虽然是生成式图像建模的一种强大方法,但其训练的不稳定性却十分棘手,特别是在大规模的复杂数据集上。近期的 BigGAN 工作显著提高了 ImageNet 的图像生成质量,但它需要一个巨大的模型,因此很难在资源有限的设备上部署。为了减小模型大小,中国台湾中央研究院资讯科学研究所学者提出一种压缩 GAN 的黑盒知识蒸馏框架,突出了稳定高效的训练过程。给定 BigGAN 作为教师网络,设法训练一个小得多的学生网络来模仿它的功能,在生成器的参数减少 16 倍的情况下,在Inception 和 FID 分数上实现了有竞争力的性能。作者 | Ting-Yun Chang, Chi-Jen Lu论文 | https://arxiv.org/abs/2009.13829代码 | https://github.com/terarachang/
Localize to Classify and Classify to Localize: Mutual Guidance in Object Detection来自法国雷恩第一大学,法国南布列塔尼大学,ATERMES公司等的学者对在 predefined anchor boxes 和 ground truth boxes 之间使用 IoU 作为目标检测中 anchor matching 的良好标准提出质疑,并研究了检测过程中涉及的两个子任务(即定位和分类)的相互依赖性。
提出 Mutual Guidance 机制,通过根据一个任务的预测质量为另一个任务分配锚标签,提供锚和目标之间的自适应匹配,反之亦然。在不同的架构和不同的公共数据集上评估了所提出的方法,并与传统的静态锚匹配策略进行了比较。报告的结果显示了这种机制在目标检测中的有效性和通用性。
作者 | Heng Zhang, Elisa Fromont, Sébastien Lefevre, Bruno Avignon论文 | https://arxiv.org/abs/2009.14085代码 | https://github.com/ZHANGHeng19931123/Patch SVDD: Patch-level SVDD for Anomaly Detection and Segmentation
来自韩国首尔大学的学者提出 Patch SVDD 方法,用于图像异常检测和分割的方法。与 Deep SVDD 不同的是,在 patch level 时检查图像,可以定位缺陷。额外的自监督学习提高了检测性能。因此,所提出的方法在MVTec AD工业异常检测数据集上取得SOTA。
作者 | Jihun Yi, Sungroh Yoon论文 | https://arxiv.org/abs/2006.16067代码 | https://github.com/nuclearboy95/Anomaly-Detection-PatchSVDD-PyTorch
DeepSEE: Deep Disentangled Semantic Explorative Extreme Super-Resolution
来自苏黎世联邦理工学院的计算机视觉实验室,作者称 DeepSEE 是第一个利用语义图探索超分辨率的方法,所提出模型大大超越了普通的放大系数,可放大到 32 倍,对人脸的验证证明了高感知质量的结果。作者还指出了一些进一步可研究方向,如在隐风格空间中确定有意义的方向(如年龄、性别、光照度、对比度等),或者将DeepSEE应用到其他领域。作者 | Marcel C. Bühler, Andrés Romero, Radu Timofte 论文 | https://arxiv.org/abs/2004.04433主页 | https://mcbuehler.github.io/DeepSEE/代码 | https://github.com/mcbuehler/DeepSEE
OpenTraj: Assessing Prediction Complexity in Human Trajectories Datasets来自法国雷恩第一大学、伦敦大学学院等的学者在本文中研究的内容是人类轨迹预测(Human Trajectory Prediction (HTP) )数据集的比较,并围绕人类轨迹预测性、轨迹规律性、上下文复杂性这三个概念对不同数据集的复杂度进行了评估。并根据这些指标比较了 HTP 任务中最常见的数据集,以及讨论了对 HTP 算法基准测试的意义。在 Github 上介绍了现有的 HTP 数据集,并提供了加载、可视化和分析数据集的工具。作者 | Javad Amirian, Bingqing Zhang, Francisco Valente Castro, Juan Jose Baldelomar, Jean-Bernard Hayet, Julien Pettre论文 | https://arxiv.org/abs/2010.00890代码 | https://github.com/crowdbotp/OpenTraj
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:leetcode 开源书
在「AI算法与图像处理」公众号后台回复:leetcode,即可下载。每题都 runtime beats 100% 的开源好书,你值得拥有!

在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文