
Traefik SRE 之使用 Prometheus 进行监控报警

监控系统是谷歌定义的 SRE 核心规则之一,当我们使用 Traefik 作为 Kubernetes 的 Ingress 控制器的时候,我们自然也非常有必要对其进行监控。本文我们将探讨如何使用 Prometheus 和 Grafana 从 Traefik 提供的 metrics 指标中进行监控报警。
安装
首先你需要一个可以访问的 Kubernetes 集群。
部署 Traefik
这里我们使用更加简单的 Helm 方式来安装部署 Traefik。首先使用以下命令将 Traefik 添加到 Helm 的仓库中:
$ helm repo add traefik https://helm.traefik.io/$ helm repo update
然后我们可以在 kube-system 命名空间下来部署最新版本的 Traefik,在我们这个示例中,我们还需要确保在集群中启用了 Prometheus 指标,可以通过给 Helm 传递 --metrics.prometheus=true 标志来实现,这里我们将所有配置都放置到下面的 traefik-values.yaml 文件中:
# traefik-values.yaml# 简单使用 hostPort 模式ports:web:port: 8000hostPort: 80websecure:port: 8443hostPort: 443service:enabled: false# 不暴露 dashboardingressRoute:dashboard:enabled: false# 开启 prometheus 监控指标additionalArguments:--api.debug=true--metrics.prometheus=true# kubeadm 安装的集群默认情况下master是有污点,需要容忍这个污点才可以部署# 这里我们将 traefik 固定在 master 节点tolerations:key: "node-role.kubernetes.io/master"operator: "Equal"effect: "NoSchedule"nodeSelector:: "master1"
直接使用如下所示的命令安装:
$ helm install traefik traefik/traefik -n kube-system -f ./traefik-values.yamlNAME: traefikLAST DEPLOYED: Mon Apr 5 11:49:22 2021NAMESPACE: kube-systemSTATUS: deployedREVISION: 1TEST SUITE: None
由于我们默认没有为 Traefik 的 Dashboard 创建 IngressRoute 对象,这里我们使用 port-forward 来临时访问即可,当然首先需要为 Traefik Dashboard 创建一个 Service:
# traefik-dashboard-service.yamlapiVersion: v1kind: Servicemetadata:name: traefik-dashboardnamespace: kube-systemlabels:: traefik: traefik-dashboardspec:type: ClusterIPports:name: traefikport: 9000targetPort: traefikprotocol: TCPselector:: traefik: traefik
直接创建,然后使用端口转发来访问:
$ kubectl apply -f traefik-dashboard-service.yaml$ kubectl port-forward service/traefik-dashboard 9000:9000 -n kube-systemForwarding from 127.0.0.1:9000 -> 9000Forwarding from [::1]:9000 -> 9000
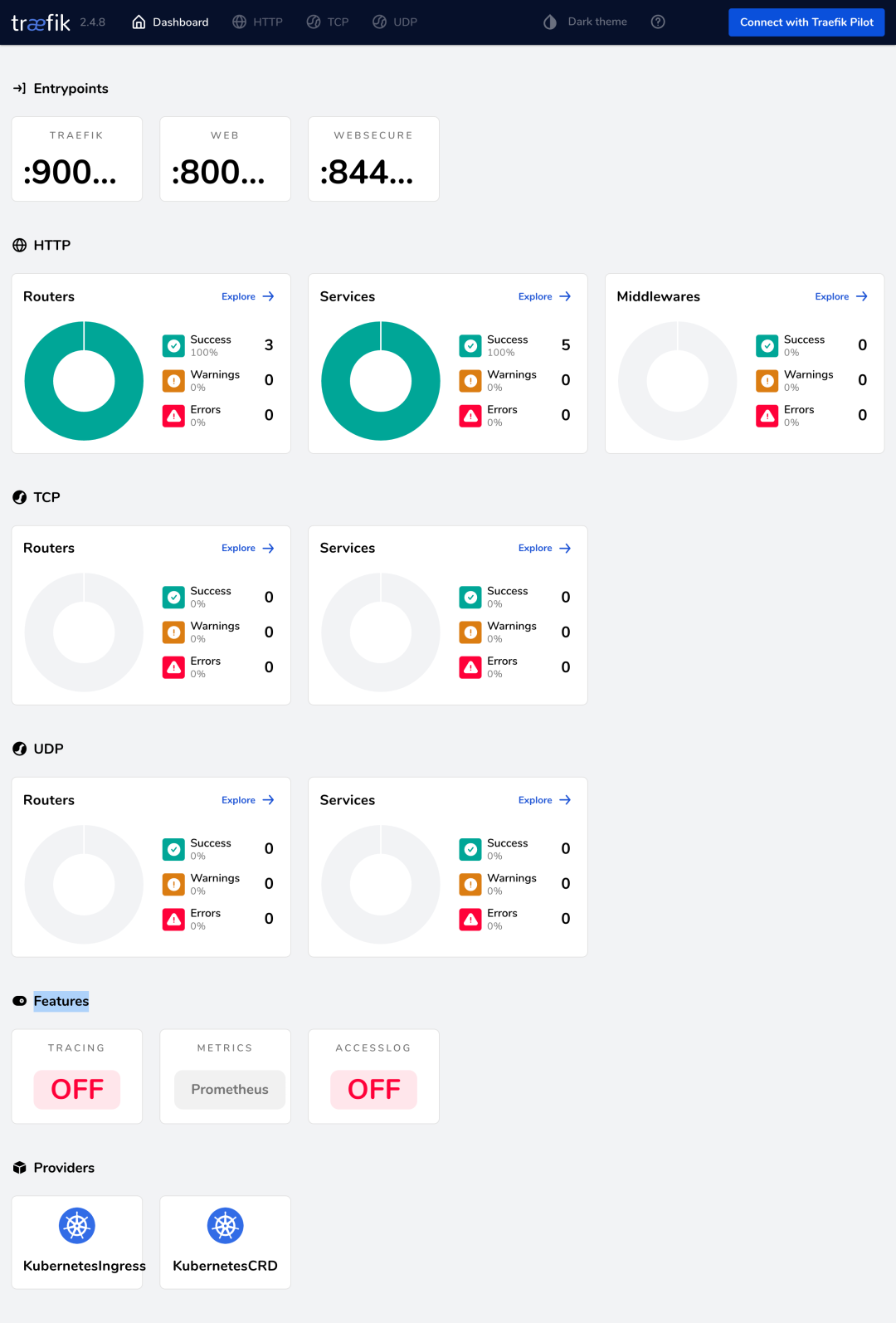
接下来我们就可以通过浏览器 http://localhost:9000/dashboard/(注意 URL 中的尾部斜杠,这是必须的)访问 Traefik Dashboard 了,现在应该可以看到在仪表板的 Features 部分启用了 Prometheus 指标。
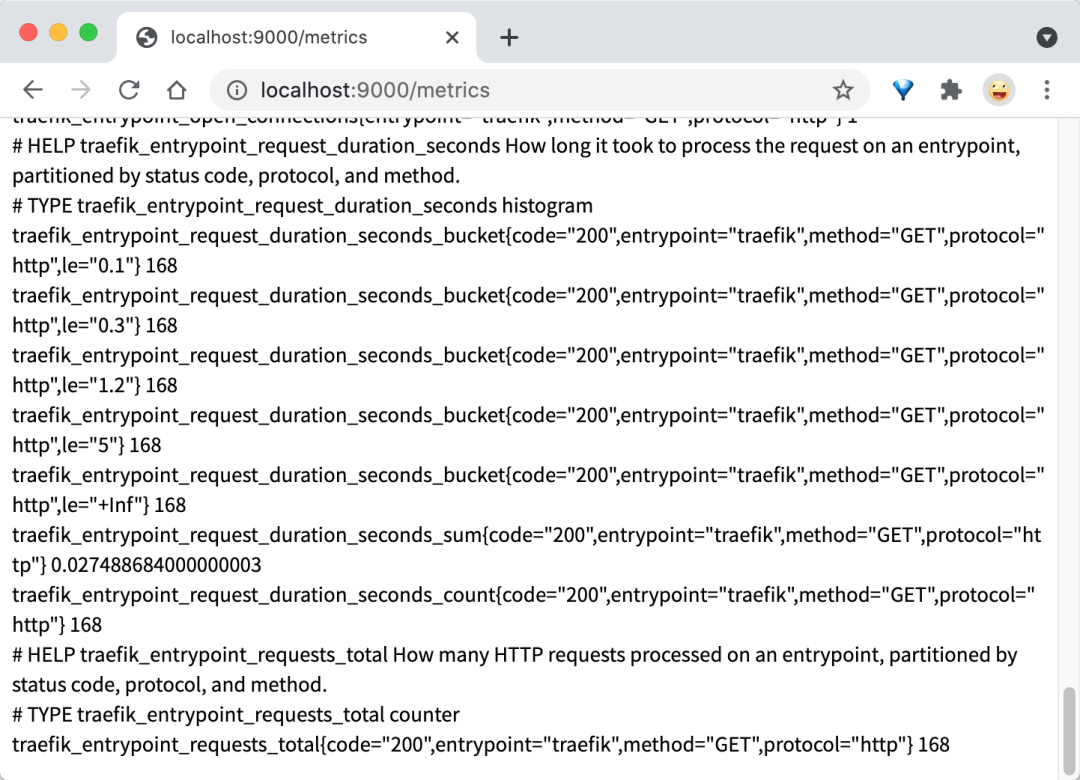
此外我们还可以访问 http://localhost:9000/metrics 端点来查看 Traefik 提供的一些 metrics 指标:
部署 Prometheus Stack
Prometheus 完整的工具链由许多组件组成,如果要完全手动去安装配置需要较长时间,感兴趣的朋友可以参考前面我们的文章相关介绍。同样这里我们直接使用 Prometheus 的 Helm Charts 来部署:
$ helm repo add prometheus-community https://github.com/prometheus-community/helm-charts$ helm repo update
上述资源库提供了许多 Chart,要查看完整的列表,你可以使用搜索命令:
helm search repo prometheus-communitykube-prometheus-stack 这个 Chart,它会部署所需要的相关组件:
$ helm install prometheus-stack prometheus-community/kube-prometheus-stackNAME: prometheus-stackLAST DEPLOYED: Mon Apr 5 12:25:22 2021NAMESPACE: defaultSTATUS: deployedREVISION: 1NOTES:kube-prometheus-stack has been installed. Check its status by running:kubectl --namespace default get pods -l "release=prometheus-stack"Visit https://github.com/prometheus-operator/kube-prometheus for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.
配置 Traefik 监控
Prometheus Operator 提供了 ServiceMonitor 这个 CRD 来配置监控指标的采集,这里我们定义一个如下所示的对象:
# traefik-service-monitor.yamlapiVersion: monitoring.coreos.com/v1kind: ServiceMonitormetadata:name: traefiknamespace: defaultlabels:app: traefikrelease: prometheus-stackspec:jobLabel: traefik-metricsselector:matchLabels:: traefik: traefik-dashboardnamespaceSelector:matchNames:kube-systemendpoints:port: traefikpath: /metrics
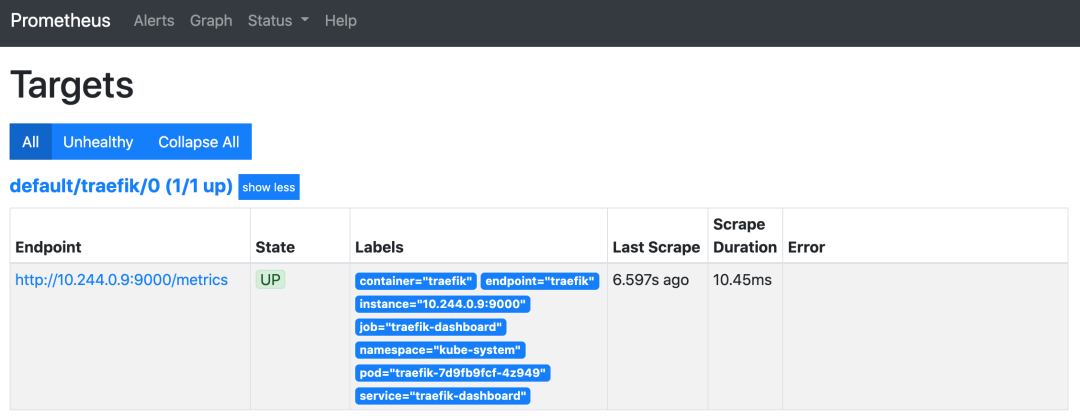
根据上面的配置,Prometheus 将获取 traefik-dashboard 服务的 /metrics 端点。主要注意的是 traefik-dashboard 服务是在 kube-system 命名空间中创建的,而 ServiceMonitor 则部署在默认的 default 命名空间中,所以这里面我们使用了 namespaceSelector 进行命名空间匹配。
kubectl apply -f traefik-service-monitor.yaml接下来我们可以来验证一下 Prometheus 是否已经开始抓取 Traefik 的指标了。
配置 Traefik 报警
接下来我们还可以添加一个报警规则,当条件匹配的时候会触发报警,同样 Prometheus Operator 也提供了一个名为 PrometheusRule 的 CRD 对象来配置报警规则:
# traefik-rules.yamlapiVersion: monitoring.coreos.com/v1kind: PrometheusRulemetadata:annotations:: prometheus-stack: defaultlabels:app: kube-prometheus-stackrelease: prometheus-stackname: traefik-alert-rulesnamespace: defaultspec:groups:name: Traefikrules:alert: TooManyRequestexpr: avg(traefik_entrypoint_open_connections{job="traefik-dashboard",namespace="kube-system"})5for: 1mlabels:severity: critical
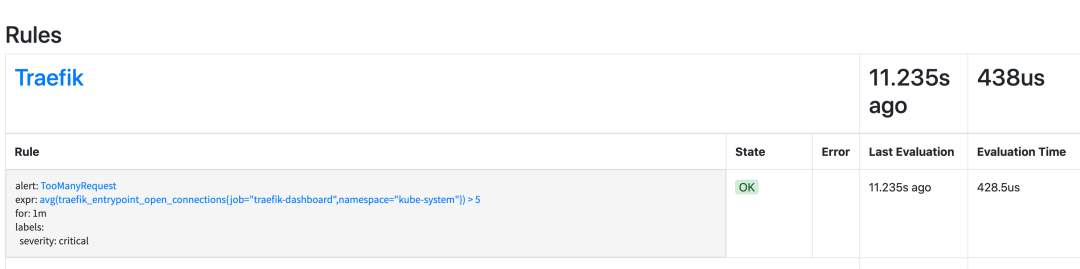
这里我们定义了一个规则:如果1分钟内有超过5个 open connections 机会触发一个 TooManyRequest 报警,直接创建这个对象即可:
kubectl apply -f traefik-rules.yaml创建完成后正常在 Promethues 的 Dashboard 下的 Status > Rules 页面就可以看到对应的报警规则:
Grafana 配置
前面使用 kube-prometheus-stack 这个 Helm Chart 部署的时候就已经部署上了 Grafana,接下来我们可以为 Traefik 的监控指标配置一个 Dashboard,同样首先我们使用端口转发的方式来访问 Grafana:
kubectl port-forward service/rometheus-stack-grafana 10080:80然后访问 Grafana GUI(http://localhost:10080)时,它会要求输入登录名和密码,默认的登录用户名是 admin,密码是 prom-operator,密码可以从名为 prometheus-operator-grafana 的 Kubernetes Secret 对象中获取。
当然我们可以自己为 Traefik 自定义一个 Dashboard,也可以从 Grafana 的官方社区中导入一个合适的即可,点击左侧导航栏上的四方形图标,导航到 Dashboards > Manage,即可添加仪表盘。
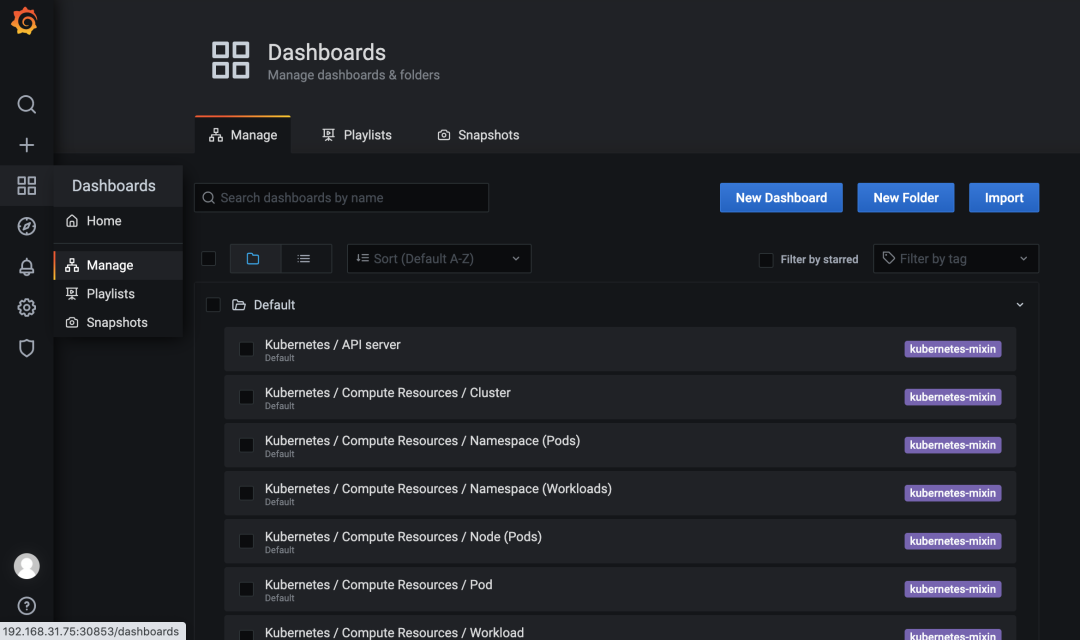
点击右上角的 Import 按钮,输入 11462 作为 Dashboard 的 ID,对应用户 timoreymann 贡献的 Traefik 2 仪表盘。
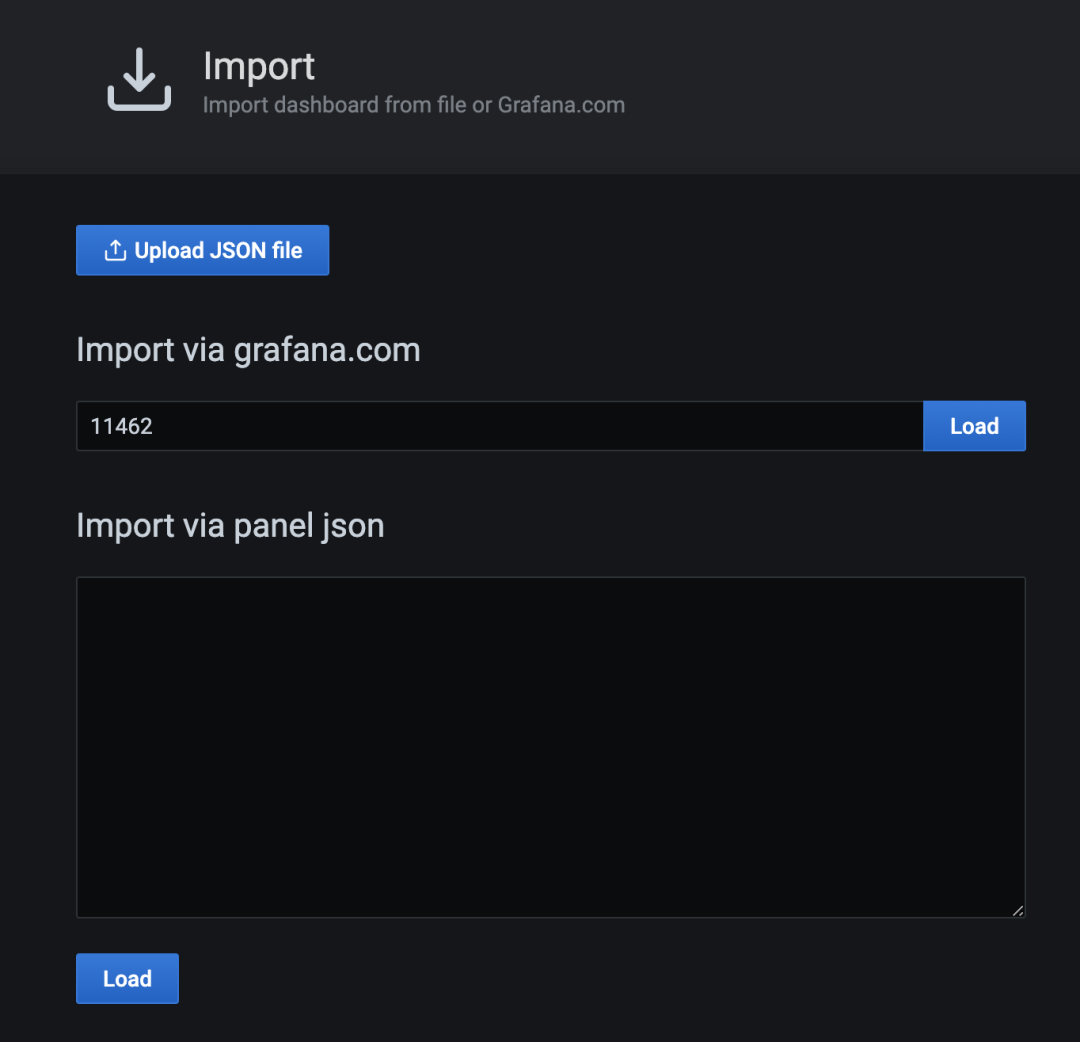
点击 Load 后,你应该看到导入的仪表盘的相关信息。
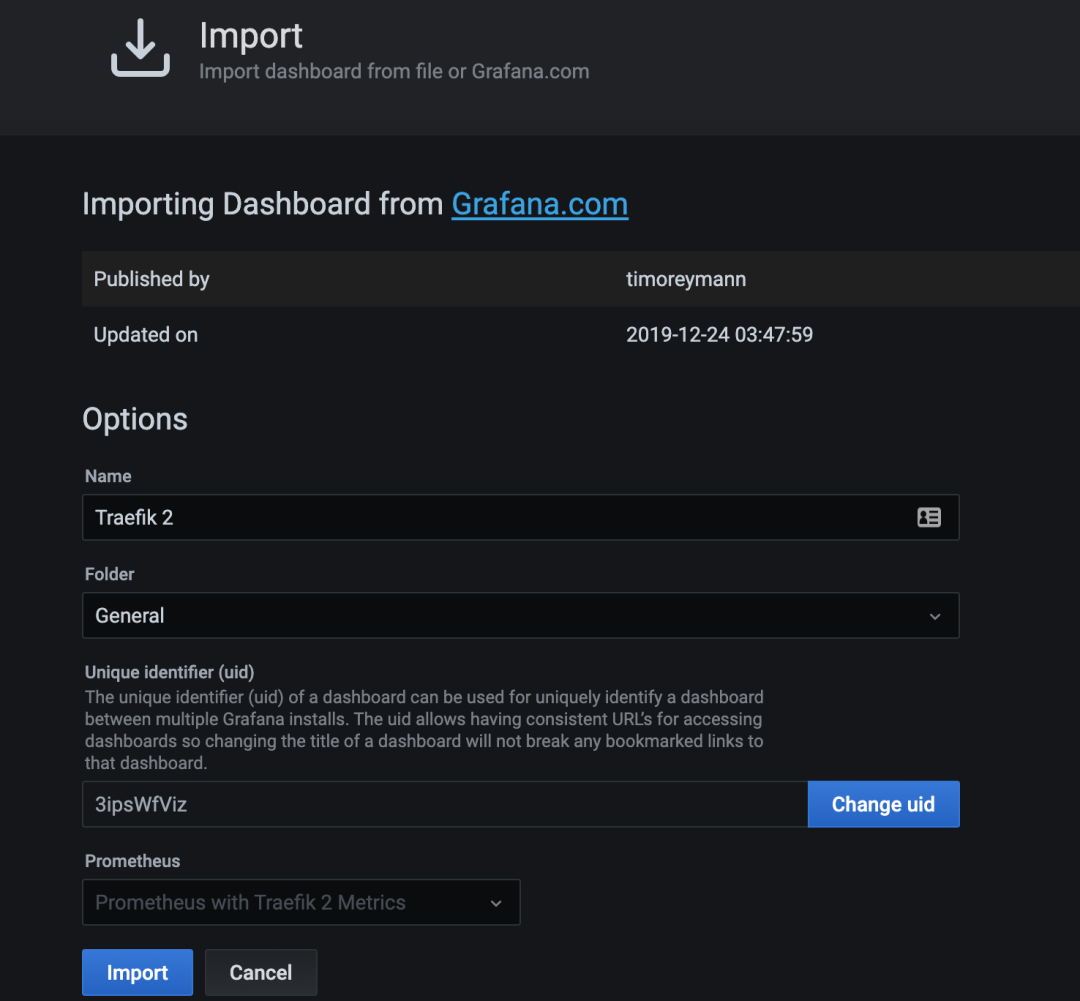
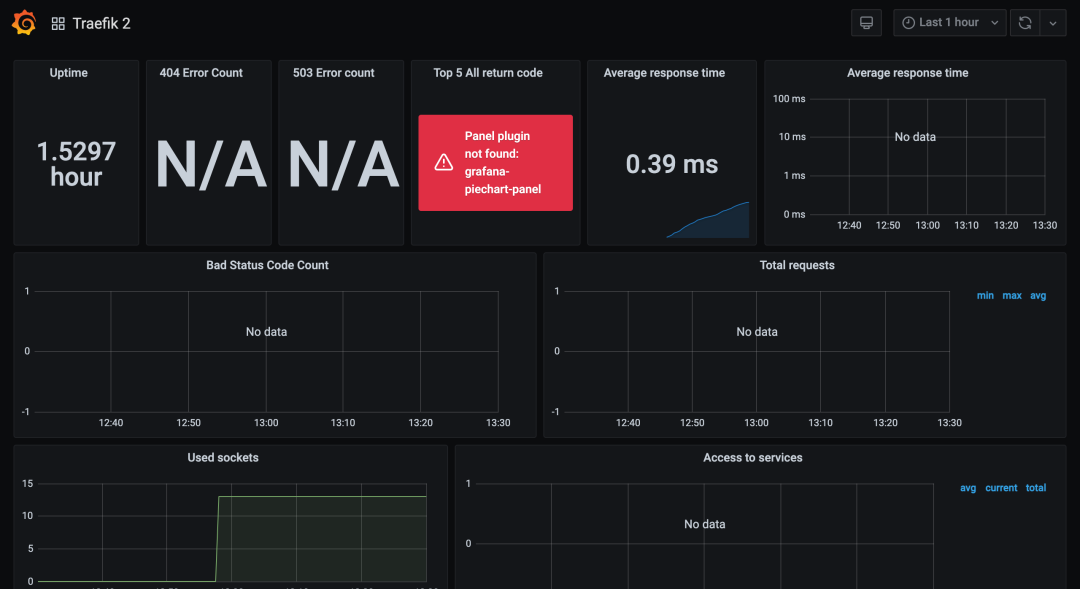
在最下面有一个下拉菜单,选择 Prometheus 数据源,然后点击 Import,即可生成如下所示的 Dashboard。
测试
现在,Traefik 已经开始工作了,并且指标也被 Prometheus 和 Grafana 获取到了,接下来我们需要使用一个应用程序来测试。这里我们部署 HTTPBin 服务,它提供了许多端点,可用于模拟不同类型的用户流量。对应的资源清单文件如下所示:
# httpbin.yamlapiVersion: apps/v1kind: Deploymentmetadata:name: httpbinlabels:app: httpbinspec:replicas: 1selector:matchLabels:app: httpbintemplate:metadata:labels:app: httpbinspec:containers:image: kennethreitz/httpbinname: httpbinports:containerPort: 80---apiVersion: v1kind: Servicemetadata:name: httpbinspec:ports:name: httpport: 8000targetPort: 80selector:app: httpbin---apiVersion: traefik.containo.us/v1alpha1kind: IngressRoutemetadata:name: httpbinspec:entryPoints:webroutes:match: Host(`httpbin.local`)kind: Ruleservices:name: httpbinport: 8000
直接创建上面的资源清单:
kubectl apply -f httpbin.yamldeployment.apps/httpbin createdservice/httpbin createdingressroute.traefik.containo.us/httpbin created
httpbin 路由会匹配 httpbin.local 的主机名,然后将请求转发给 httpbin Service:
$ curl -I http://192.168.31.75 -H "host:httpbin.local"HTTP/1.1 200 OKAccess-Control-Allow-Credentials: trueAccess-Control-Allow-Origin: *Content-Length: 9593Content-Type: text/html; charset=utf-8Date: Mon, 05 Apr 2021 05:43:16 GMTServer: gunicorn/19.9.0
我们这里部署的 Traefik 使用的是 hostPort 模式,固定到 master 节点上面的,这里的 IP 地址 192.168.31.75 就是 master 节点的 IP 地址。
接下来我们使用 ab 来访问 HTTPBin 服务模拟一些流量,这些请求会产生对应的指标,执行以下脚本:
$ ab -c 5 -n 10000 -m PATCH -H "host:httpbin.local" -H "accept: application/json" http://192.168.31.75/patch$ ab -c 5 -n 10000 -m GET -H "host:httpbin.local" -H "accept: application/json" http://192.168.31.75/get$ ab -c 5 -n 10000 -m POST -H "host:httpbin.local" -H "accept: application/json" http://192.168.31.75/post
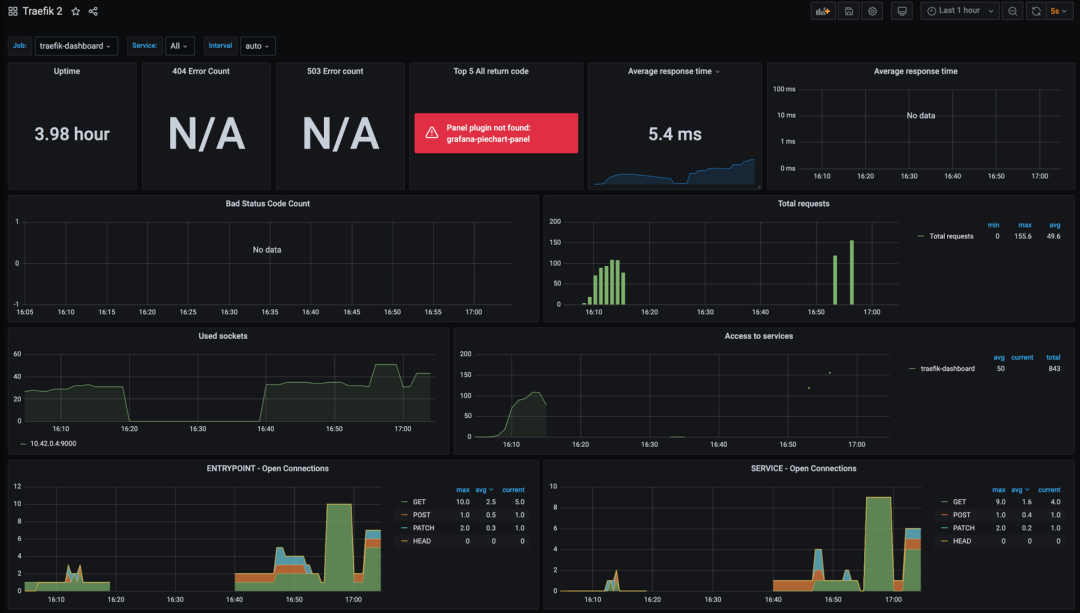
正常一段时间后再去查看 Grafana 的 Dashboard 可以看到显示了更多的信息:
包括:正常运行的时间、平均响应时间、请求总数、基于 HTTP 方法和服务的请求计数等。
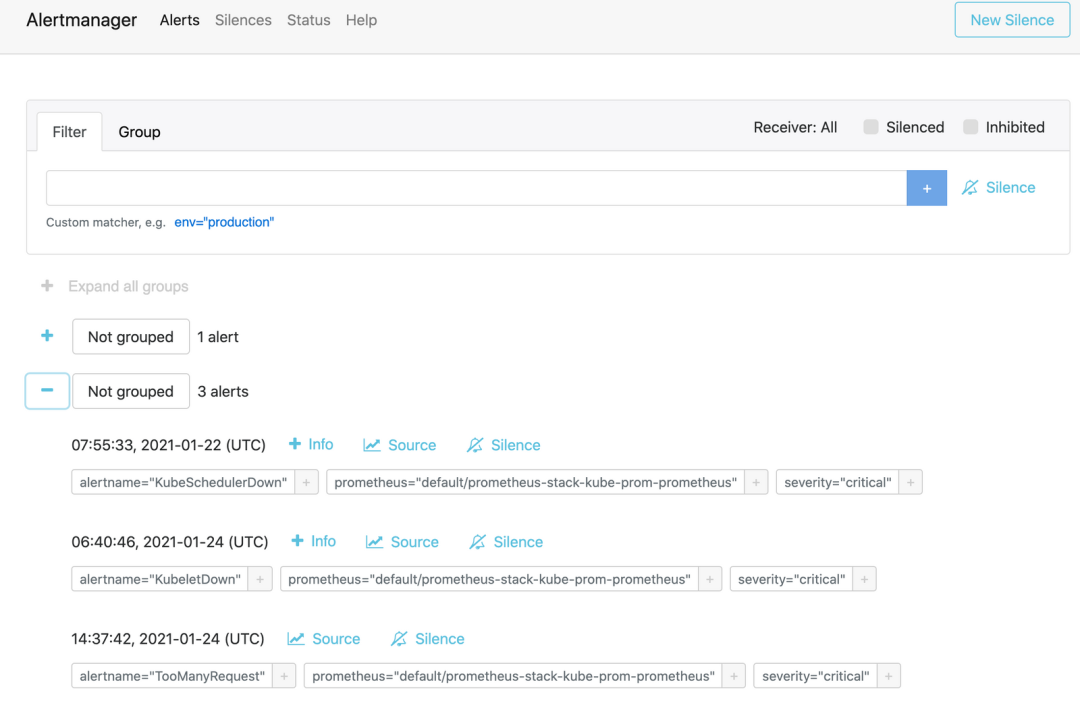
最后,当我们测试应用流量时,Prometheus 可能会触发报警,之前创建的 TooManyRequest 报警将显示在 Alertmanager 仪表板上,然后可以自己根据需要配置接收报警信息的 Receiver 即可。
$ kubectl port-forward service/prometheus-stack-kube-prom-alertmanager 9093:9093Forwarding from 127.0.0.1:9093 -> 9093
总结
在本文中,我们已经看到了将 Traefik 连接到 Prometheus 和 Grafana 以从 Traefik 指标中创建可视化的过程是非常简单的。当熟悉这些工具后,我们也可以根据实际需求创建一些 Dashboard,暴露你的环境的一些关键数据。
接下来将会给大家重点介绍关于 Traefik SRE 技术中的日志收集和 Jaeger 的应用追踪。
K8S 进阶训练营

 点击屏末 | 阅读原文 | 即刻学习
点击屏末 | 阅读原文 | 即刻学习